使用 Azure Machine Learning 建立自訂 AI 模型
複雜的 AI 模型可用性可協助組織大幅減少資料科學專案所需的驚人資源數量。 讓我們來看看組織如何使用 Azure Machine Learning 處理機器學習挑戰和操作。
機器學習挑戰與機器學習作業的需求
維護 AI 解決方案通常需要機器學習生命週期管理來記錄和管理資料、程式碼、模型環境,以及機器學習模型本身。 除了必須針對開發、封裝和部署模型建立程序,以及監視其效能,您有時還得為這些模型重新定型。 而且大部分組織會同時管理生產環境中的多個模型,使得複雜性大幅增加。
若要有效地因應此種複雜性,需要一些最佳做法。 他們著重於跨小組共同作業、自動化和標準化程序,並確保模型可以輕鬆地予以稽核、解釋及重複使用。 為了達成此目的,資料科學小組會依賴機器學習作業方法。 此方法受到 DevOps (開發和作業) 的啟發,這是管理應用程式開發週期作業的業界標準,因為開發人員和資料科學家的困境很類似。
Azure Machine Learning
資料科學家可以從 Microsoft 提供的 Azure Machine Learning 平台來管理和執行機器學習 DevOps,讓機器學習生命週期管理和作業做法變得更容易。 此類工具可協助小組在共用、可稽核且安全的環境中共同作業,讓許多程序可以透過自動化進行最佳化。
機器學習生命週期管理
Azure Machine Learning 支援預先定型和自訂模型的端對端機器學習生命週期管理。 一般生命週期包含下列步驟:資料準備、模型定型、模型封裝、模型驗證、模型部署、模型監視和重新定型。
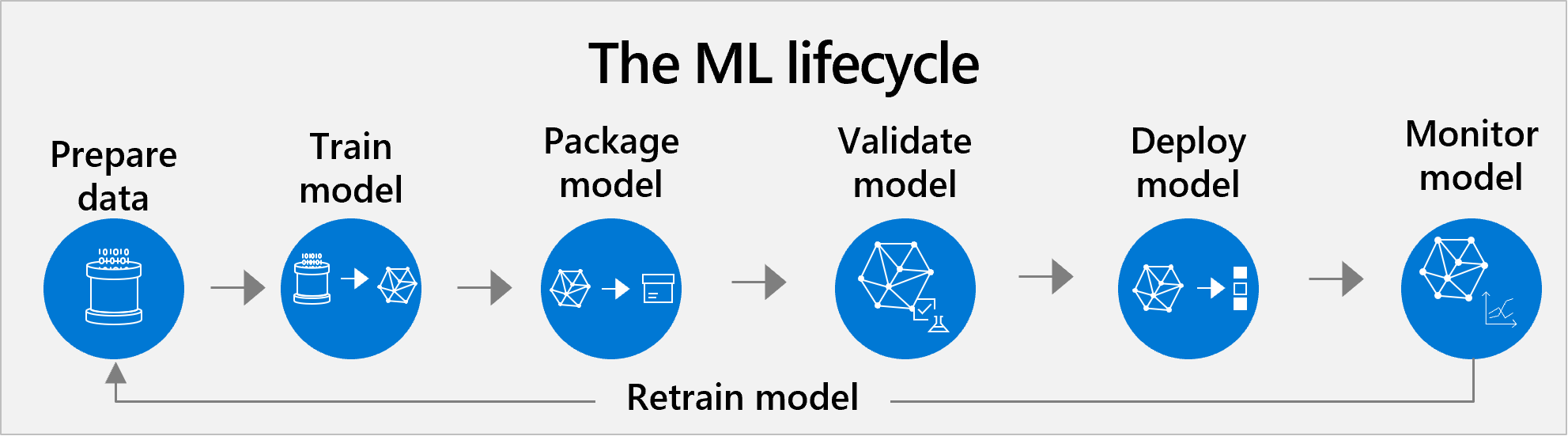
此傳統方法涵蓋了資料科學專案的所有一般步驟。
- 準備資料集。 AI 始於資料。 首先,資料科學家必須準備用來定型模型的資料。 資料準備通常是生命週期中最耗費時間的階段。 此工作包括尋找或建置您自己的資料集並進行清理,以便讓機器能夠輕鬆讀取。 您要確定資料是代表性範例、變數與您目標相關等等。
- 定型和測試。 接下來,資料科學家會將演算法套用至資料,藉此為機器學習模型定型。 然後,資料科學家會使用新的資料進行測試,以檢查其預測的正確性。
- 封裝。 模型無法直接放入應用程式。 其需要經過容器化,因此可以使用其建置使用的所有工具和架構來執行。
- 驗證。 在此階段中,小組會評估模型效能是否能達到其商務目標。 測試可能會傳回足夠的計量,但模型在實際商務案例中使用時可能無法如預期般運作。
- 重複步驟 1-4。 您可能需要花費數百小時來定型,才能找出令人滿意的模型。 開發小組可能會藉由調整定型資料、微調演算法超參數或嘗試不同的演算法來定型許多模型版本。 在理想的情況下,模型會隨著每一輪調整而更加完善。 開發小組最終必須決定哪一個版本的模型最適合商務使用案例。
- Deploy。 最後會部署模型。 部署選項包括:在雲端中、在內部部署伺服器上,以及在相機、IoT 閘道或機械等裝置上。
- 監視及重新定型。 即使模型一開始能夠正常運作,但其必須持續受到監視並重新定型,才能維持相關性與正確性。
注意
整合預先定型的模型並讓模型適應您的業務需求,需要使用不同的工作流程來整合自訂模型。 使用 Azure Machine Learning,您可以使用預先定型的模型,或建置您自己的模型。 選擇哪一種方法需視案例而定。 使用預先定型模型的優點是需要較少的資源,且能更快提供結果。 不過,預建模型會經過定型來解決各種不同的使用案例,因此可能難以滿足非常特定的需求。 在這些情況下,完整的自訂模型可能是較好的想法。 這兩種方法的彈性混用通常比較妥當,且有助於調整規模。 AI 小組可以將預先定型模型用於最簡單的使用案例來節省資源,同時在最困難的案例中投入這些資源以建置自訂 AI 模型。 進一步的反覆項目可以藉由重新定型模型來改善預建模型。
機器學習作業
機器學習作業 (MLOps) 會套用 DevOps (開發和作業) 的方法,以更有效率地管理機器學習生命週期。 藉此,AI 小組將可在所有專案關係人之間進行更靈活、更具生產力的共同作業。 這些共同作業涉及資料科學家、AI 工程師、應用程式開發人員和其他 IT 小組。
MLOps 流程與工具可透過可稽核的共用文件來協助這些小組進行共同作業,且更容易看見工作成果。 MLOps 技術可讓使用者儲存和追蹤所有資源的變更,例如資料、程式碼、模型和其他工具。 這些技術也可以透過自動化、重複性工作流程以及可重複使用的資產來提升效率並加速生命週期。 這些實務做法全都能讓 AI 專案更加靈活且有效率。
Azure Machine Learning 支援下列 MLOps 做法:
模型重現性:表示不同的小組成員可以使用相同的資料集執行模型,並取得類似的結果。 重現性是在生產環境中讓模型結果可以信賴的重要關鍵。 Azure Machine Learning 透過集中管理資產 (例如環境、程式碼、資料集、模型和機器學習管線),支援模型重現性。
模型驗證:在部署模型之前,務必先驗證其效能計量。 您可能會使用各種指標來衡量「最佳」模型。 採用與商務使用案例相關的方式來驗證效能計量,這點非常重要。 Azure Machine Learning 支援使用許多工具來評估模型計量 (例如損失函式和混淆矩陣),進行模型驗證。
模型部署:部署模型時,請務必讓資料科學家和 AI 工程師一起合作,以判斷最佳部署選項。 這些選項包括雲端、內部部署和邊緣裝置 (相機、無人機、機械)。
模型定型:您必須監視並定期重新定型模型,讓模型可以修正效能問題並使用較新的定型資料。 Azure Machine Learning 支援系統化和反覆修正程序,以持續修改並確保模型的精確度。
提示

客戶案例:醫療保健組織使用 Azure Machine Learning 來定型自訂機器學習模型,以預測手術期間發生併發症的可能性。 這些模型是使用大量資料進行定型,包括年齡、種族、吸煙史、身體質量指數和血小板數等因素。 使用這些模型可讓醫療專業人員更好地評估風險,並判斷個別患者的手術選項或生活方式變更建議。 Azure Machine Learning 中負責任的 AI 儀表板可協助說明預測因素,並減輕人口因素的偏差。 最後,預測模型化解決方案有助於降低風險和不確定性,並改善手術結果。 在此閱讀完整的客戶案例:https://aka.ms/azure-ml-customer-story。
提示
花點時間考慮貴組織如何運用資料科學和機器學習專業知識來建置自訂模型。

接下來,讓我們用知識檢定總結所有內容。