減輕潛在危害
判斷基準和測量解決方案所產生的有害輸出之後,您可以採取步驟來減輕潛在損害,以及適當地重新測試修改的系統,並比較基準的損害等級。
風險降低 AI 解決方案中的潛在損害牽涉到分層方法,其中緩和技術可以在四個層級中套用,如下所示:
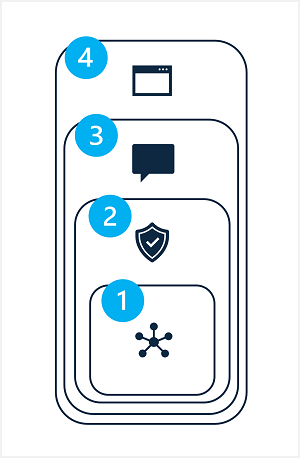
- 模型
- 安全系統
- Metaprompt 和基礎
- 使用者體驗
1:模型層
模型層是由解決方案核心的一或多個衍生 AI 模型所組成。 例如,您的解決方案可能以 GPT-4 之類的模型為基礎來建置。
您可以在模型層套用的緩和措施包括:
- 選取適合使用之解決方案的模型。 例如,雖然 GPT-4 可能是功能強大的多用途模型,但解決方案中只需要分類小型的特定文字輸入,較簡單的模型可能會提供具有較低有害內容產生風險的必要功能。
- 使用您自己的定型資料微調基礎模型,使其產生的回應更可能與您的解決方案案例相關且範圍更是如此。
2:安全系統 層
安全系統層包含平台層級的設定和功能,可協助減輕損害。 例如,Azure AI Studio 包含針對四種潛在傷害(仇恨、性、暴力和自我傷害)的四種潛在傷害(仇恨、性、暴力和自我傷害)分類內容篩選的支援,以根據內容分類為四種嚴重性層級(安全、低、中和高)來抑制提示和回應。
其他安全系統層防護功能可能包括濫用偵測演算法,以判斷解決方案是否受到系統性濫用 (例如透過 Bot 的大量自動化要求),以及警示通知,以快速回應潛在的系統濫用或有害行為。
3: 中繼提示和基礎層
中繼提示和基礎層著重於提交至模型的提示建構。 您可以在這一層套用的損害風險降低技術包括:
- 指定中繼提示或系統輸入,以定義模型的行為參數。
- 套用提示工程,將基礎資料新增至輸入提示,將相關、非共用輸出的可能性最大化。
- 使用擷取增強產生 (RAG) 方法來擷取信任資料來源的內容資料,並將其包含在提示中。
4:使用者體驗層
用戶體驗層包含軟體應用程式,用戶可透過此應用程式與產生 AI 模型和檔案或其他使用者附屬資料互動,以描述解決方案的使用方式給使用者和專案關係人。
設計應用程式使用者介面以限制特定主體或類型的輸入,或套用輸入和輸出驗證,可以降低潛在有害回應的風險。
文件和其他對一般 AI 解決方案的描述,應該適當地了解系統的功能和限制、其所依據的模型,以及可能不一定由您已備妥的防護措施所解決的任何潛在損害。