針對 Linux 或 Windows 上的 Azure 虛擬機器效能進行疑難排解
適用於:✔️ Linux VM ✔️ Windows VM
本文說明透過監視和觀察瓶頸進行虛擬機(VM) 一般效能疑難解答,併為可能發生的問題提供可能的補救。 除了監視之外,您也可以使用 Perfinsights 來提供報告,並提供有關 IO/CPU/記憶體的最佳做法建議和關鍵瓶頸。 Perfinsights 適用於 Azure 中的 Windows 和 Linux VM。
本文將逐步解說如何使用監視來診斷效能瓶頸。
透過 Azure 入口網站 啟用 VM 診斷
若要啟用 VM 診斷:
移至 VM。
在 [監視] 區段中,選取 [診斷設定]。
選取記憶體帳戶,然後選取 [ 啟用來賓層級監視]。


透過 Azure 入口網站 檢視記憶體帳戶計量(適用於非受控磁碟)
對於使用 非受控磁碟的 VM,當我們想要分析 IO 效能時,記憶體是一個非常重要的層。 針對記憶體相關計量,我們需要啟用診斷作為額外步驟:
選取 VM,以識別 VM 所使用的記憶體帳戶(或帳戶):
- 在 Azure 入口網站 中,選取您的 VM。
- 在 [設定] 下,選取 [磁碟],然後尋找儲存磁碟的記憶體帳戶。
- 流覽至記憶體帳戶,然後選取 [計量]。
識別效能瓶頸
一旦完成所需計量的初始設定程式,並在啟用 VM 和相關記憶體帳戶的診斷後,我們可以轉移至分析階段。
存取監視
在 Azure 入口網站 中,選取您想要調查的 Azure VM、選取 [監視] 區段的 [計量],然後選取計量。
![顯示如何開啟 [使用量和估計成本] 頁面的螢幕快照。](media/troubleshoot-performance-virtual-machine-linux-windows/select-monitoring.png#lightbox)
觀察時間軸
若要識別是否有任何資源瓶頸,請檢閱您的數據。 如果您發現您的計算機已正常執行,但已報告效能最近已降級,請檢閱包含報告變更之前效能計量數據的時間範圍、問題期間和之後。
檢查CPU瓶頸
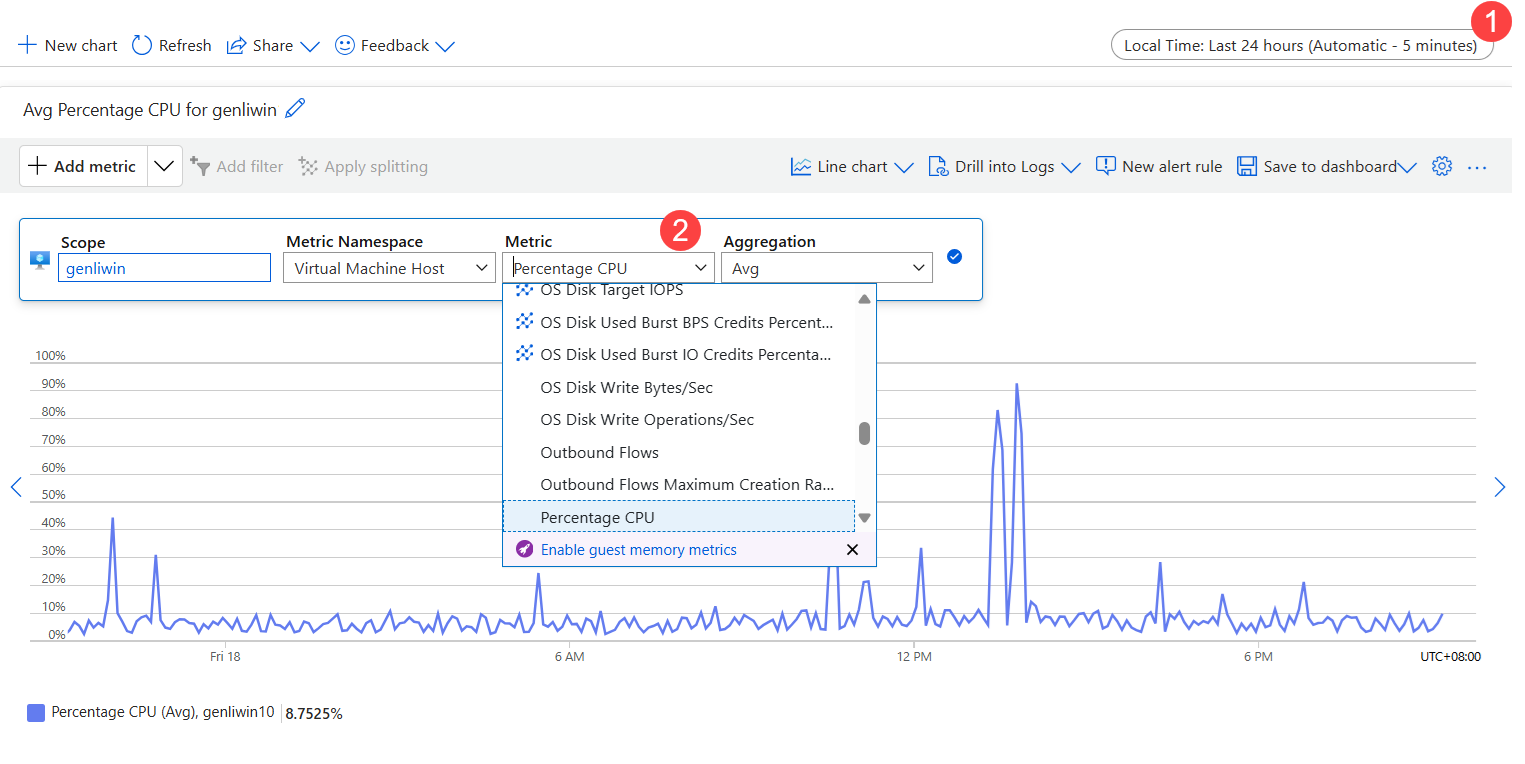
- 設定時間範圍。
- 在 [計量] 中,選取 [CPU 百分比]。
監視CPU效能趨勢
查看效能問題時,請注意趨勢,並了解它們是否會影響您。 在下一節中,我們將使用入口網站的監視圖表來顯示趨勢。 它們也適用於在相同時間週期中交叉參考差異資源行為。 若要自定義圖表,請按兩下 [Azure 監視器資料平臺]。
尖刺 – 尖刺可能與排程的工作/已知事件相關。 如果您可以識別工作,請判斷工作是否在所需的效能層級執行。 如果可接受效能,您可能不需要增加資源。
尖峰和常數 – 通常表示新的工作負載。 如果不是可辨識的工作負載,請在 VM 中啟用監視,以瞭解哪些進程(或進程)會導致行為。 一旦辨識程序之後,判斷耗用量增加是由效率不佳的程式代碼所造成,還是一般耗用量所造成。 如果正常耗用量,請決定進程是否在所需的效能層級運作。
常數 – 判斷您的 VM 是否一律在此層級執行,或是否只在該層級執行,因為已啟用診斷。 如果是,請找出造成問題的處理程式(或進程),並考慮新增更多該資源。
穩步增加 – 不斷增加耗用量通常是效率不佳的程式代碼,或處理更多使用者工作負載的程式。
高 CPU 使用率補救
如果您的應用程式或行程未以最佳方式執行,且 CPU 使用量維持在 95% 以上,您可以執行下列其中一項工作:
- 立即緩解 - 將 VM 的大小提升為具有更多核心的大小
- 了解問題 – 找出應用程式程序,然後據以進行疑難排解。
如果您增加 VM,但 CPU 仍以 95% 的速度執行,那麼,請判斷此設定是否會為可接受層級提供更好的效能或更高的應用程式輸送量。 如果不會,請針對該個別應用程式或程序進行疑難排解。
您可以使用適用於 Windows 或 Linux 的 Perfinsights 來分析哪個程式正在推動 CPU 使用量。
檢查記憶體瓶頸
若要檢視計量:
- 新增區段。
- 新增磚。
- 開啟資源庫。
- 選取 [記憶體使用量] 並拖曳。 當圖格停駐時,以滑鼠右鍵按兩下並選取 [6x4]。
監視記憶體效能趨勢
記憶體使用量會顯示 VM 耗用多少記憶體。 了解趨勢,以及它是否對應到您看到問題的時間。 您應該一律有超過 100 MB 的可用記憶體。
尖峰和常數/常數穩定耗用量 - 高記憶體使用率可能不是效能不良的原因,因為某些應用程式,例如關係資料庫引擎會配置大量的記憶體,而且此使用率可能並不重要。 不過,如果有多個記憶體饑餓的應用程式,您可能會看到記憶體爭用效能不佳,導致修剪和分頁/交換至磁碟。 這種效能不佳通常是應用程式效能影響的明顯原因。
持續增加耗用量 – 可能的應用程式「熱身」,此耗用量在啟動的資料庫引擎中很常見。 不過,它也可能是應用程式中記憶體流失的跡象。 識別應用程式,並瞭解是否預期行為。
頁面或交換檔案使用方式 – 檢查您使用的是 Windows 分頁檔案 (位於 D:) 或 Linux 交換檔案 (位於 上 /dev/sdb) 已大量使用。 如果這些磁碟區上沒有這些檔案,請檢查這些磁碟上的高讀取/寫入。 此問題表示記憶體不足的情況。
高記憶體使用率補救
若要解決高記憶體使用率,請執行下列任何一項工作:
- 針對立即緩解或頁面或交換檔案使用量 - 將 VM 大小增加為一個記憶體,然後監視。
- 了解問題 – 找出應用程式/進程,並針對識別高耗用記憶體應用程式進行疑難解答。
- 如果您知道應用程式,請參閱是否可以限制記憶體配置。
如果升級至較大的 VM 之後,您會發現您仍然持續增加,直到 100%,找出應用程式/程式並進行疑難解答。
您可以使用適用於 Windows 或 Linux 的 Perfinsights 來分析哪些程式正在推動記憶體耗用量。
檢查磁碟瓶頸 (適用於非受控磁碟)
若要檢查 VM 的記憶體子系統,請使用 VM 診斷中的計數器,以及記憶體帳戶診斷來檢查 Azure VM 層級的診斷。
針對 VM 特定的疑難解答,您可以使用適用於 Windows 或 Linux 的 Perfinsights,這有助於分析哪些程式正在推動 IO。
請注意,我們沒有區域備援和 進階儲存體 帳戶的計數器。 針對與這些計數器相關的問題,請提出支援案例。
在監視中檢視記憶體帳戶診斷
若要處理下列專案,請移至入口網站中 VM 的記憶體帳戶:
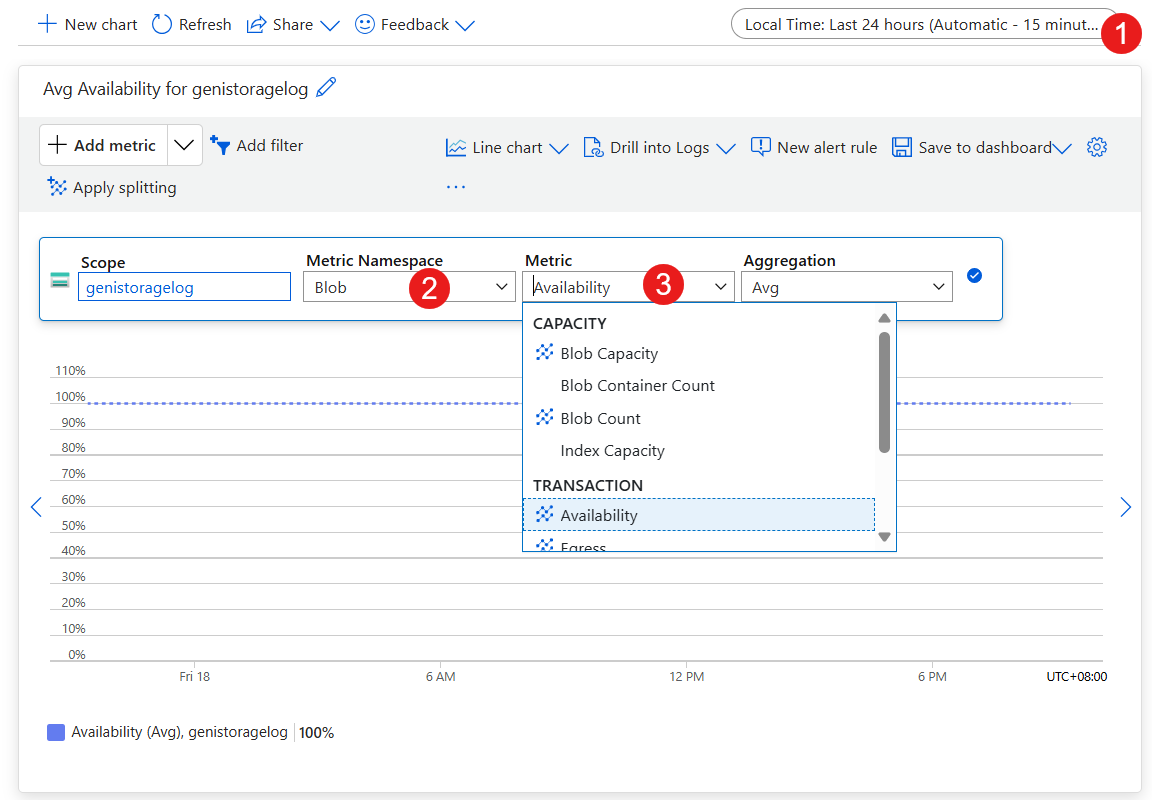
- 設定時間範圍。
- 將計量命名空間設定為 Blob。
- 將 [計量] 設定為 [可用性]。
監視磁碟效能趨勢(僅限標準記憶體)
若要識別記憶體的問題,請查看記憶體帳戶診斷和 VM 診斷中的效能計量。
針對下面的每個檢查,尋找問題在問題的時間範圍內發生時的主要趨勢。
檢查 Azure 記憶體可用性 – 新增記憶體帳戶計量:可用性
如果您看到可用性下降,平臺可能會有問題,請檢查 Azure 狀態。 如果沒有顯示問題,請提出新的支援要求。
檢查 Azure 記憶體逾時 - 新增記憶體帳戶計量
- ClientTimeOutError
- ServerTimeOutError
- AverageE2ELatency
- AverageServerLatency
- TotalRequests
*TimeOutError 計量中的值表示 IO 作業花費的時間太長且逾時。完成後續步驟將有助於找出潛在的原因。
TimeOutErrors 同時增加 AverageServerLatency 可能是平台問題。 在此情況下,提出新的支援要求。
AverageE2ELatency 代表客戶端延遲。 確認應用程式如何執行 IOPS。 尋找增加或持續較高的 TotalRequests 計量。 此計量代表 IOPS。 如果您開始達到記憶體帳戶或單一 VHD 的限制,延遲可能與節流有關。
檢查 Azure 記憶體節流 - 新增記憶體帳戶計量:ThrottlingError
節流的值表示您正在記憶體帳戶層級進行節流,這表示您達到帳戶的 IOPS 限制。 您可以藉由檢查計量 TotalRequests 來判斷您是否達到 IOP 閾值。
請注意,每個 VHD 的限制為 500 IOPS 或 60 個 MBit,但受限於每個記憶體帳戶 20000 IOPS 的累計限制。
使用此計量時,您無法判斷哪些 Blob 造成節流,哪些 Blob 受到節流影響。 不過,您會達到記憶體帳戶的 IOPS 或輸入/輸出限制。
若要識別您是否達到 IOPS 限制,請進入記憶體帳戶診斷並檢查 TotalRequests,查看您是否接近 2 萬個 TotalRequests。 識別模式中的變更、您是否第一次看到限制,或此限制是否在特定時間發生。
使用標準記憶體下的新磁碟供應專案,IOPS 和輸送量限制可能會不同,但標準記憶體帳戶的累積限制是 20000 IOPS(進階記憶體在帳戶或磁碟層級有不同的限制)。 深入瞭解不同的標準記憶體磁碟供應專案和每個磁碟限制:
- Windows 上 VM 磁碟的延展性和效能目標。
參考資料
記憶體帳戶的頻寬是由記憶體帳戶計量:TotalIngress 和 TotalEgress 來測量。 視備援和區域類型而定,您有不同的頻寬閾值:
針對記憶體帳戶備援類型和區域的輸入和輸出限制,檢查 TotalIngress 和 TotalEgress。
檢查連結至 VM 的 VHD 輸送量限制。 新增 VM 計量磁碟讀取和寫入。
標準記憶體下的新磁碟供應專案有不同的 IOPS 和輸送量限制(每個 VHD 不會公開 IOPS)。 查看數據,以瞭解您是否已使用磁碟讀取和寫入,在 VM 層級達到 VHD 的合併輸送量 MB 限制,然後將 VM 記憶體組態優化,以調整超過單一 VHD 限制。 深入瞭解不同的標準記憶體磁碟供應專案和每個磁碟限制:
- Windows 上 VM 磁碟的延展性和效能目標。
高磁碟使用率/延遲補救
減少客戶端延遲並將 VM IO 優化以調整過去的 VHD 限制
減少節流
如果達到記憶體帳戶的上限,請在記憶體帳戶之間重新平衡 VHD。 請參閱 Azure 儲存體 延展性和效能目標。
增加輸送量並減少延遲
如果您有延遲敏感性應用程式且需要高輸送量,請使用DS和GS系列 VM 將 VHD 遷移至 Azure 進階記憶體。
這些文章將討論特定案例:
與我們連絡,以取得說明
如果您有問題或需要相關協助,請建立支援要求,或詢問 Azure community 支援。 您也可以向 Azure 意見反應社群提交產品意見反應。