In diesem Artikel werden die Entwurfsprozesse, Prinzipien und Technologieoptionen für die Erstellung einer sicheren Data Lakehouse-Lösung mit Azure Synapse beschrieben. Wir konzentrieren uns dabei auf die Sicherheitsaspekte und die wichtigsten technischen Entscheidungen.
Apache®, Apache Spark und das Flammenlogo sind entweder eingetragene Marken oder Marken der Apache Software Foundation in den USA und/oder anderen Ländern. Die Verwendung dieser Markierungen impliziert kein Endorsement durch die Apache Software Foundation.
Aufbau
Das folgende Diagramm zeigt die Architektur der Data Lakehouse-Lösung. Diese wurde dafür konzipiert, die Interaktionen zwischen den Diensten zu steuern, um Sicherheitsbedrohungen zu minimieren. Je nach Anforderungen an Funktionalität und Sicherheit können Lösungen unterschiedlich aussehen.

Laden Sie eine Visio-Datei dieser Architektur herunter.
Datenfluss
Das folgende Diagramm zeigt den Dataflow der Lösung:

- Daten werden aus der Datenquelle in die Zielzone hochgeladen, entweder in Azure Blob Storage oder eine von Azure Files bereitgestellte Dateifreigabe. Die Daten werden von einem Batchuploaderprogramm oder -system hochgeladen. Streamingdaten werden mithilfe der Capture-Funktion von Azure Event Hubs erfasst und in Blob-Storage gespeichert. Es können mehrere Datenquellen vorhanden sein. So können beispielsweise verschiedene Fabriken ihre Betriebsdaten hochladen. Informationen zum Sichern des Zugriffs auf Blob-Storage, Dateifreigaben und andere Speicherressourcen finden Sie in den Sicherheitsempfehlungen für Blob Storage und Planung für eine Azure Files-Bereitstellung.
- Die Ankunft der Datendatei veranlasst Azure Data Factory, die Daten zu verarbeiten und im Data Lake in der Kerndatenzone zu speichern. Das Hochladen der Daten in die Kerndatenzone in Azure Data Lake schützt vor Datenexfiltration.
- Azure Data Lake speichert die Rohdaten, die aus verschiedenen Quellen abgerufen werden. Es ist durch Firewallregeln und virtuelle Netzwerke geschützt. Es blockiert jegliche Verbindungsversuche aus dem öffentlichen Internet.
- Die Ankunft von Daten im Data Lake löst die Azure Synapse-Pipeline aus, oder ein zeitbasierter Trigger führt einen Datenverarbeitungsauftrag aus. Apache Spark in Azure Synapse wird aktiviert und führt einen Spark-Auftrag oder ein Spark-Notebook aus. Außerdem wird der Datenverarbeitungsflow im Data Lakehouse orchestriert. Azure Synapse-Pipelines konvertieren Daten aus der Zone „Bronze“ in die Zone „Silver“ und dann in die Zone „Gold“.
- Ein Spark-Auftrag oder -Notebook führt den Datenverarbeitungsauftrag aus. In Spark kann auch ein Datenkuratierungs- oder Machine Learning-Trainingsauftrag ausgeführt werden. Strukturierte Daten in der Zone „Gold“ werden im Delta Lake-Format gespeichert.
- Ein serverloser SQL-Pool erstellt externe Tabellen, die die in Delta Lake gespeicherten Daten verwenden. Der serverlose SQL-Pool bietet eine leistungsstarke und effiziente SQL-Abfrage-Engine und kann herkömmliche SQL-Benutzerkonten oder Microsoft Entra-Benutzerkonten unterstützen.
- Power BI stellt eine Verbindung mit dem serverlosen SQL-Pool her, um die Daten zu visualisieren. Anhand der Daten im Data Lakehouse erstellt Power BI Berichte oder Dashboards.
- Data Analysts und Data Scientists können sich zu folgenden Zwecken bei Azure Synapse Studio registrieren:
- Anreicherung der Daten
- Analyse zum Erzielen von geschäftlichen Erkenntnissen
- Trainieren des Machine Learning-Modells
- Geschäftsanwendungen stellen eine Verbindung mit einem serverlosen SQL-Pool her und verwenden die Daten, um andere Anforderungen des Geschäftsbetriebs zu unterstützen.
- Azure Pipelines führt den CI/CD-Prozess aus, der die Lösung automatisch erstellt, testet und bereitstellt. Dieser Prozess wurde entwickelt, um menschliche Eingriffe während des Bereitstellungsprozesses zu minimieren.
Komponenten
Nachfolgend sind die wichtigsten Komponenten in dieser Data Lakehouse-Lösung aufgeführt:
- Azure Synapse
- Azure Files
- Event Hubs
- Blob Storage
- Azure Data Lake-Speicher
- Azure DevOps
- Power BI
- Data Factory
- Azure Bastion
- Azure Monitor
- Microsoft Defender für Cloud
- Azure Key Vault
Alternativen
- Wenn Sie eine Echtzeitdatenverarbeitung benötigen: Anstatt einzelne Dateien in der Datenzielzone zu speichern, verwenden Sie Apache Structured Streaming, um den Datenstrom von Event Hubs zu empfangen und zu verarbeiten.
- Wenn die Daten eine komplexe Struktur aufweisen und komplexe SQL-Abfragen erfordern, sollten Sie die Daten in einem dedizierten SQL-Pool statt in einem serverlosen SQL-Pool speichern.
- Wenn die Daten viele hierarchische Datenstrukturen enthalten – beispielsweise eine umfangreiche JSON-Struktur – sollten Sie sie eher in Azure Synapse Data Explorer speichern.
Szenariodetails
Azure Synapse Analytics ist eine vielseitige Datenplattform, die Data Warehousing für Unternehmen, Datenanalysen in Echtzeit, Pipelines, Zeitreihen-Datenverarbeitung, maschinelles Lernen und Datengovernance unterstützt. Zu diesem Zweck sind verschiedene Technologien integriert, z. B.:
- Data Warehousing für Unternehmen
- Serverlose SQL-Pools
- Apache Spark
- Pipelines
- Data Explorer
- Funktionen für maschinelles Lernen
- Vereinheitlichte Datengovernance mit Microsoft Purview
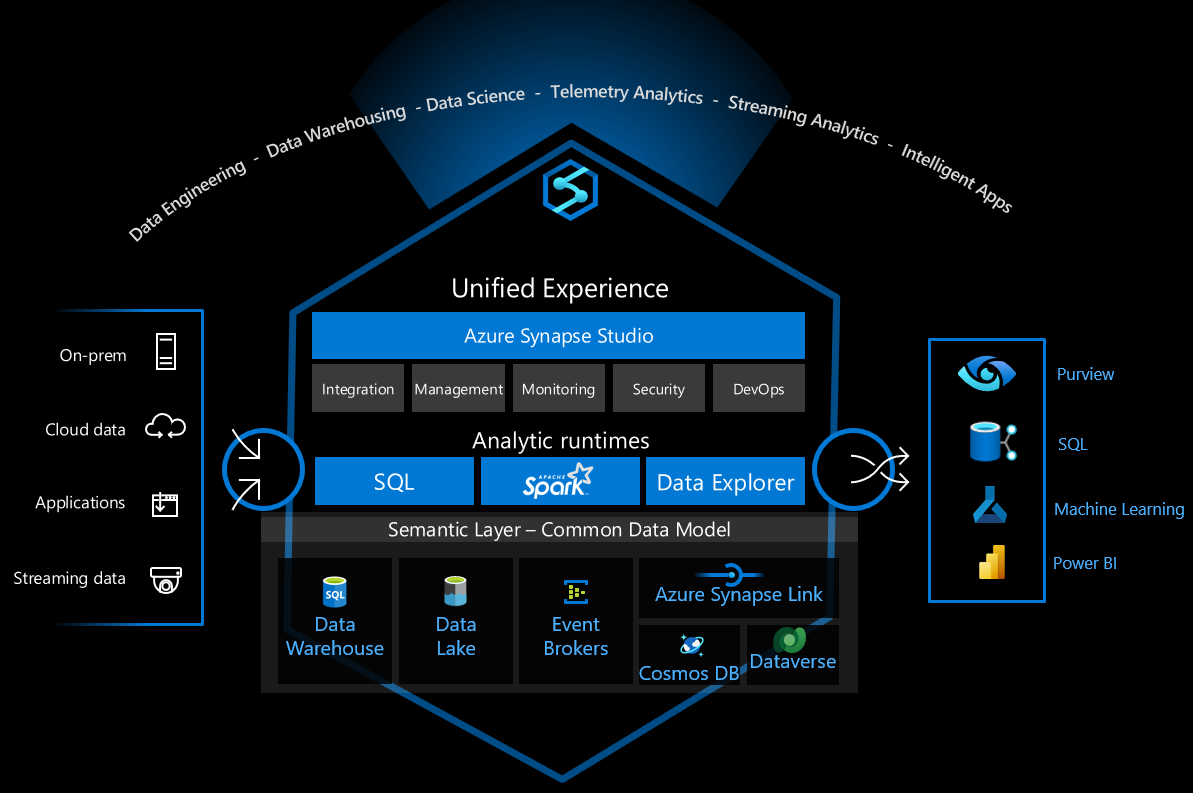
Diese Funktionen eröffnen viele Möglichkeiten, aber es gibt viele technische Optionen, um die Infrastruktur sicher für die sichere Verwendung zu konfigurieren.
In diesem Artikel werden die Entwurfsprozesse, Prinzipien und Technologieoptionen für die Erstellung einer sicheren Data Lakehouse-Lösung mit Azure Synapse beschrieben. Wir konzentrieren uns dabei auf die Sicherheitsaspekte und die wichtigsten technischen Entscheidungen. Die Lösung verwendet die folgenden Azure-Dienste:
- Azure Synapse
- Serverlose SQL-Pools in Azure Synapse
- Apache Spark in Azure Synapse Analytics
- Azure Synapse-Pipelines
- Azure Data Lake
- Azure DevOps.
Ziel ist es, Anleitungen zum Aufbau einer sicheren und kosteneffektiven Data Lakehouse-Plattform für die unternehmensweite Nutzung zu bieten und eine nahtlose und sichere Zusammenarbeit der Technologien zu ermöglichen.
Mögliche Anwendungsfälle
Ein Data Lakehouse ist eine moderne Datenverwaltungsarchitektur, die die Kosteneffizienz, Skalierbarkeit und Flexibilität eines Data Lake mit den Daten- und Transaktionsverwaltungsfunktionen eines Data Warehouse kombiniert. Ein Data Lakehouse kann eine große Menge an Daten verarbeiten und Business Intelligence- und Machine Learning-Szenarien unterstützen. Es kann auch Daten aus verschiedenen Datenstrukturen und Datenquellen verarbeiten. Weitere Informationen finden Sie unter Was ist Databricks Lakehouse?.
Hier einige gängige Anwendungsfälle für die in diesem Artikel beschriebene Lösung:
- Analyse von Telemetriedaten aus dem Internet der Dinge (Internet of Things, IoT)
- Automatisierung intelligenter Fabriken (Fertigung)
- Nachverfolgen von Verbraucheraktivitäten und -verhalten (Einzelhandel)
- Verwalten von Sicherheitsincidents und -ereignissen
- Überwachen von Anwendungsprotokollen und Anwendungsverhalten
- Verarbeitung und Geschäftsanalyse halbstrukturierter Daten
Allgemeines Design
Bei dieser Lösung geht es primär um das Sicherheitsdesign und die Implementierungsverfahren in der Architektur. Serverlose SQL-Pools, Apache Spark in Azure Synapse, Azure Synapse-Pipelines, Data Lake Storage und Power BI sind die wichtigsten Dienste, die zum Implementieren des Data Lakehouse-Musters verwendet werden.
Dies ist die allgemeine Architektur des Lösungsdesigns:

Auswählen des Sicherheitsfokus
Wir haben das Sicherheitsdesign mit dem Tool zur Bedrohungsmodellierung begonnen. Das Tool hat uns bei folgenden Aufgaben geholfen:
- Kommunizieren mit allen am System Beteiligten in Bezug auf potenzielle Risiken
- Definieren der Vertrauensgrenze im System
Basierend auf den Ergebnissen der Bedrohungsmodellierung haben wir die folgenden Sicherheitsbereiche zu unseren Top-Prioritäten gemacht:
- Identitäts- und Zugriffssteuerung
- der Netzwerkschutz
- DevOps-Sicherheit
Wir haben die Sicherheitsfeatures und Infrastrukturänderungen im Hinblick auf einen optimalen Schutz des Systems konzipiert, indem die wesentlichsten Sicherheitsrisiken reduziert werden, die für diese Top-Prioritäten identifiziert wurden.
Ausführliche Informationen zu allen Aspekten, die überprüft und berücksichtigt werden müssen, finden Sie hier:
- Sicherheit in Microsoft Cloud Adoption Framework für Azure
- Zugriffssteuerung
- Ressourcenschutz
- Innovationssicherheit
Plan zum Schutz von Netzwerk und Ressourcen
Eines der wichtigsten Sicherheitsprinzipien im Cloud Adoption Framework ist das Zero Trust-Prinzip: Beim Konzipieren der Sicherheit für Komponenten oder Systeme lässt sich das Risiko verringern, dass Angreifer ihren Zugriff ausweiten, indem davon ausgegangen wird, dass auch andere Ressourcen in der Organisation kompromittiert sind.
Basierend auf dem Ergebnis der Bedrohungsmodellierung übernimmt die Lösung die Zero Trust-Empfehlung für eine Bereitstellung mit Mikrosegmentierung und definiert mehrere Sicherheitsgrenzen. Azure Virtual Network und der Azure Synapse-Schutz von Datenexfiltration sind die wichtigsten Technologien zum Implementieren einer Sicherheitsgrenze, um Datenressourcen und kritische Komponenten zu schützen.
Da Azure Synapse aus mehreren verschiedenen Technologien besteht, ist Folgendes erforderlich:
Identifizieren der Komponenten von Synapse und verwandten Diensten, die im Projekt verwendet werden
Azure Synapse ist eine vielseitige Datenplattform, die viele verschiedene Datenverarbeitungsanforderungen erfüllen kann. Zunächst müssen wir entscheiden, welche Komponenten in Azure Synapse im Projekt verwendet werden, damit wir planen können, wie sie geschützt werden sollen. Außerdem müssen wir bestimmen, welche anderen Dienste mit diesen Azure Synapse-Komponenten kommunizieren.
Die wichtigsten Komponenten in einer Data Lakehouse-Architektur sind diese:
- Serverloses SQL in Azure Synapse
- Apache Spark in Azure Synapse
- Azure Synapse-Pipelines
- Data Lake Storage
- Azure DevOps
Definieren des Kommunikationsverhaltens zwischen den Komponenten gemäß gesetzlicher Vorgaben
Wir müssen das zulässigen Kommunikationsverhalten zwischen den Komponenten definieren. Soll beispielsweise das Spark-Modul direkt mit der dedizierten SQL-Instanz kommunizieren dürfen oder soll die Kommunikation über einen Proxy wie die Azure Synapse-Datenintegrationspipeline oder Data Lake Storage erfolgen?
Basierend auf dem Zero Trust-Prinzip blockieren wir die Kommunikation, wenn es keine geschäftliche Notwendigkeit für die Interaktion gibt. Beispielsweise blockieren wir die direkte Kommunikation eines Spark-Moduls, das sich in einem unbekannten Mandanten befindet, mit Data Lake Storage.
Auswählen der richtigen Sicherheitslösung zum Erzwingen des definierten Kommunikationsverhaltens
In Azure können mehrere Sicherheitstechnologien ein definiertes Kommunikationsverhalten von Diensten erzwingen. In Data Lake Storage können Sie beispielsweise eine Positivliste mit IP-Adressen verwenden, um den Zugriff auf einen Data Lake zu steuern, Sie können aber auch auswählen, welche virtuellen Netzwerke, Azure-Dienste und Ressourceninstanzen zulässig sein sollen. Jede Schutzmethode bietet eine andere Form des Schutzes. Wählen Sie basierend auf Geschäftsanforderungen und Umgebungseinschränkungen eine geeignete Methode aus. Die in dieser Lösung verwendete Konfiguration wird im nächsten Abschnitt beschrieben.
Implementieren von Bedrohungserkennung und erweiterten Verteidigungsmaßnahmen für kritische Ressourcen
Bei kritische Ressourcen ist es am besten, eine Bedrohungserkennung und erweiterte Verteidigungsmaßnahmen zu implementieren. Die Dienste helfen dabei, Bedrohungen zu identifizieren und Warnungen auszulösen, sodass das System Benutzer bei Sicherheitsverletzungen benachrichtigen kann.
Ziehen Sie die folgenden Techniken in Betracht, um Netzwerke und Ressourcen besser zu schützen:
Bereitstellen von Umkreisnetzwerken zum Einrichten von Sicherheitszonen für Datenpipelines
Wenn die Workload einer Datenpipeline Zugriff auf externe Daten und die Datenzielzone erfordert, ist es am besten, ein Umkreisnetzwerk zu implementieren und dies mithilfe einer ETL-Pipeline (Extrahieren, Transformieren, Laden) vom Rest der Umgebung zu trennen.
Aktivieren von Defender für Cloud für alle Speicherkonten
Defender für Cloud löst Sicherheitswarnungen aus, wenn es ungewöhnliche und potenziell schädliche Versuche erkennt, auf Speicherkonten zuzugreifen oder Exploits in diese einzuschleusen. Weitere Informationen finden Sie unter Microsoft Defender für Storage konfigurieren.
Sperren eines Speicherkontos zum Verhindern von böswilligen Löschversuchen oder Konfigurationsänderungen
Weitere Informationen finden Sie unter Anwenden einer Azure Resource Manager-Sperre auf ein Speicherkonto.
Architektur mit Netzwerk- und Ressourcenschutz
In der folgenden Tabelle werden die definierten Kommunikationsverhaltensweisen und Sicherheitstechnologien beschrieben, die für diese Lösung ausgewählt wurden. Die Auswahl basiert auf den Methoden, die im Plan zum Schutz von Netzwerk und Ressourcen erläutert wurden.
| Von (Client) | An (Dienst) | Verhalten | Konfiguration | Notizen | |
|---|---|---|---|---|---|
| Internet | Data Lake Storage | Alle verweigern | Firewallregel – Standardwert „Verweigern“ | Standardwert: „Verweigern“ | Firewallregel – Standardwert „Verweigern“ |
| Azure Synapse-Pipeline/Spark | Data Lake Storage | Zulassen (Instanz) | Virtuelles Netzwerk – verwalteter privater Endpunkt (Data Lake Storage) | ||
| Synapse-SQL | Data Lake Storage | Zulassen (Instanz) | Firewallregel – Ressourceninstanzen (Synapse SQL) | Synapse SQL muss mithilfe verwalteter Identitäten auf Data Lake Storage zugreifen | |
| Azure Pipelines-Agent | Data Lake Storage | Zulassen (Instanz) | Firewallregel – ausgewählte virtuelle Netzwerke Dienstendpunkt – Storage |
Für Integrationstests: Umgehen: „AzureServices“ (Firewallregel) |
|
| Internet | Synapse-Arbeitsbereich | Alle verweigern | Firewallregel | ||
| Azure Pipelines-Agent | Synapse-Arbeitsbereich | Zulassen (Instanz) | Virtuelles Netzwerk – privater Endpunkt | Erfordert drei private Endpunkte (Dev, serverloses SQL und dediziertes SQL) | |
| Verwaltetes virtuelles Synapse-Netzwerk | Internet oder nicht autorisierter Azure-Mandant | Alle verweigern | Virtuelles Netzwerk – Synapse-Datenexfiltrationsschutz | ||
| Synapse-Pipeline/Spark | Key Vault | Zulassen (Instanz) | Virtuelles Netzwerk – verwalteter privater Endpunkt (Key Vault) | Standardwert: „Verweigern“ | |
| Azure Pipelines-Agent | Key Vault | Zulassen (Instanz) | Firewallregel – ausgewählte virtuelle Netzwerke * Dienstendpunkt – Key Vault |
Umgehen: „AzureServices“ (Firewallregel) | |
| Azure-Funktionen | Serverloses SQL in Synapse | Zulassen (Instanz) | Virtuelles Netzwerk – privater Endpunkt (serverloses SQL in Synapse) | ||
| Synapse-Pipeline/Spark | Azure Monitor | Zulassen (Instanz) | Virtuelles Netzwerk – privater Endpunkt (Azure Monitor) |
Der Plan soll beispielsweise Folgendes umfassen:
- Erstellen eines Azure Synapse-Arbeitsbereichs mit einem verwalteten virtuellen Netzwerk
- Sichern von ausgehenden Daten aus Azure Synapse-Arbeitsbereichen durch Verwenden des Datenexfiltrationsschutzes für Azure Synapse-Arbeitsbereiche
- Verwalten der Liste der genehmigten Microsoft Entra-Mandanten für den Azure Synapse-Arbeitsbereich
- Konfigurieren von Netzwerkregeln, um Datenverkehr zum Storage-Konto aus ausgewählten virtuellen Netzwerken zuzulassen – nur Zugriff – und den öffentlichen Netzwerkzugriff zu deaktivieren
- Verwenden von verwalteten privaten Endpunkte, um eine Verbindung zwischen dem von Azure Synapse verwalteten virtuellen Netzwerk und dem Data Lake herzustellen
- Verwenden einer Ressourceninstanz, um Azure Synapse SQL sicher mit dem Data Lake zu verbinden
Überlegungen
Diese Überlegungen bilden die Säulen des Azure Well-Architected Framework, einer Reihe von Leitprinzipien, die Sie zur Verbesserung der Qualität eines Workloads verwenden können. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Sicherheit
Informationen zur Sicherheitssäule des Well-Architected Framework finden Sie unter Sicherheit.
Identität und Zugriffssteuerung
Das System umfasst eine Vielzahl von Komponenten. Jede erfordert eine andere Konfiguration für Identity & Access Management (IAM). Diese Konfigurationen müssen nahtlos ineinandergreifen, um ein optimales Benutzererlebnis bereitzustellen. Daher halten wir uns bei der Implementierung von Identitäts- und Zugriffssteuerung an die folgenden Designrichtlinien.
Auswählen einer Identitätslösung für verschiedene Zugriffssteuerungsebenen
- Es gibt vier verschiedene Identitätslösungen im System.
- SQL-Konto (SQL Server)
- Dienstprinzipal (Microsoft Entra ID)
- Verwaltete Identität (Microsoft Entra ID)
- Benutzerkonto (Microsoft Entra ID)
- Es gibt vier verschiedene Zugriffssteuerungsebenen im System.
- Anwendungszugriffsebene: Wählen Sie die Identitätslösung für AP-Rollen aus.
- Azure Synapse-Datenbank-/Tabellenzugriffsebene: Wählen Sie die Identitätslösung für Rollen in Datenbanken aus.
- Azure Synapse-Zugriffsebene für externe Ressourcen: Wählen Sie die Identitätslösung für den Zugriff auf externe Ressourcen aus.
- Data Lake Storage-Zugriffsebene: Wählen Sie die Identitätslösung für die Steuerung des Dateizugriffs im Speicher aus.

Ein wichtiger Aspekt der Identitäts- und Zugriffssteuerung ist die Auswahl der richtigen Identitätslösung für jede Zugriffssteuerungsebene. In den Sicherheitsdesignprinzipien des Azure Well-Architected Framework wird empfohlen, native Steuerelemente zu verwenden und für Einfachheit zu sorgen. Daher verwendet diese Lösung das Microsoft Entra-Benutzerkonto des Endbenutzers in der Anwendung und den Azure Synapse-Datenbankzugriffsebenen. Sie nutzt die nativen Erstanbieterlösungen für Identity & Access Management (IAM) und ermöglicht eine differenzierte Zugriffssteuerung. Die Azure Synapse-Zugriffsebene für externe Ressourcen und die Data Lake-Zugriffsebene verwenden verwaltete Identitäten in Azure Synapse, um den Autorisierungsprozess zu vereinfachen.
- Es gibt vier verschiedene Identitätslösungen im System.
Einrichten des Zugriffs mit den geringstmöglichen Berechtigungen
Einem Zero Trust-Leitsatz zufolge sollte der Zugriff auf kritische Ressourcen nach den Prinzipien „Just-In-Time“ und „Just Enough Access“ bereitgestellt werden. Informationen dazu, wie Sie die Sicherheit in Zukunft verbessern können, finden Sie unter Microsoft Entra Privileged Identity Management (PIM).
Schützen verknüpfter Dienste
Verknüpfte Dienste definieren die Verbindungsinformationen, die erforderlich sind, damit ein Dienst eine Verbindung mit externen Ressourcen herstellen kann. Es ist wichtig, Konfigurationen verknüpfter Dienste zu sichern.
- Erstellen Sie einen verknüpften Azure Data Lake-Dienst mit Private Link.
- Verwenden Sie verwaltete Identitäten als Authentifizierungsmethode in verknüpften Diensten.
- Verwenden Sie Azure Key Vault, um die Anmeldeinformationen für den Zugriff auf den verknüpften Dienst zu sichern.

Sicherheitsscorebewertung und Bedrohungserkennung
Die Lösung verwendet Microsoft Defender für Cloud, um die Infrastruktursicherheit zu bewerten und Sicherheitsprobleme zu erkennen und so wichtige Informationen zum Sicherheitsstatus des Systems zu erhalten. Microsoft Defender für Cloud ist ein Tool für die Verwaltung des Sicherheitsstatus und den Schutz vor Bedrohungen. Es kann Workloads schützen, die in Azure, Hybridlösungen und anderen Cloudplattformen ausgeführt werden.

Wenn Sie die Defender für Cloud-Seiten im Azure-Portal zum ersten Mal öffnen, aktivieren Sie automatisch den kostenlosen Tarif von Defender for Cloud für Ihre sämtlichen Azure-Abonnements. Wir empfehlen diese Aktivierung dringend, damit Sie eine Bewertung Ihres Cloudsicherheitsstatus sowie entsprechende Empfehlungen erhalten. Microsoft Defender für Cloud stellt Ihren Sicherheitsscore sowie einige Anleitungen zur Verstärkung der Sicherheit für Ihre Abonnements bereit.
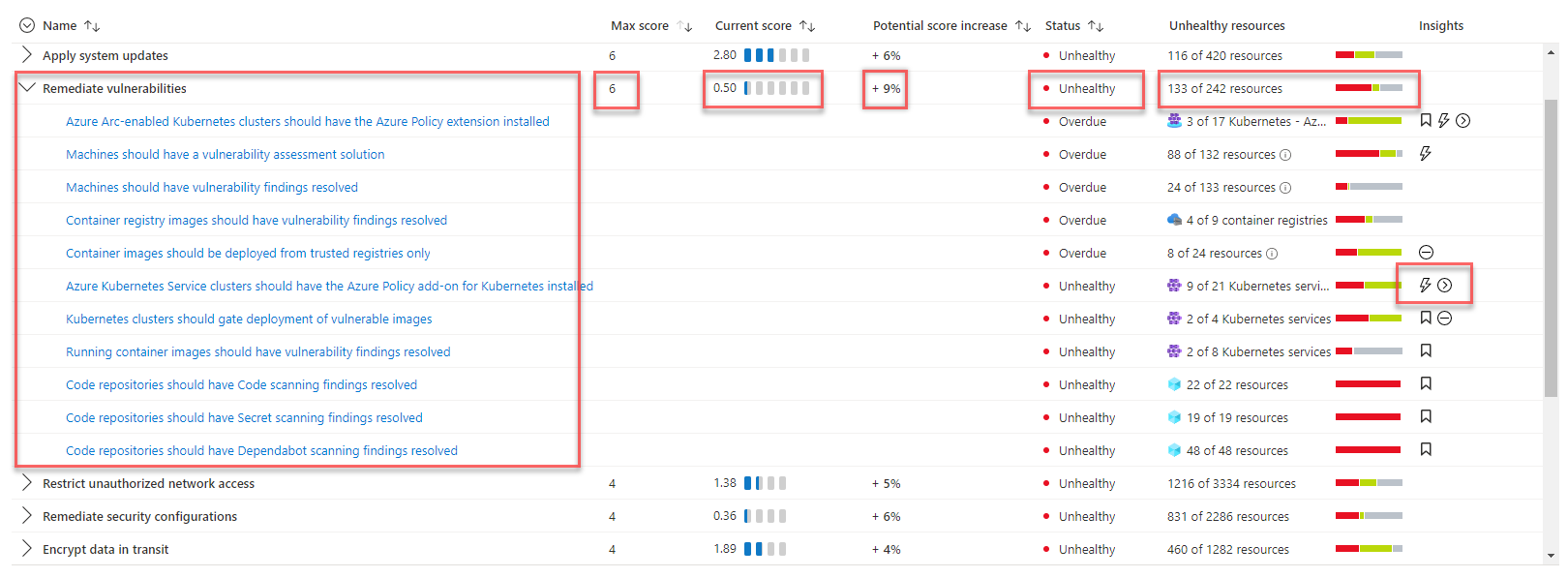
Wenn die Lösung erweiterte Funktionen für Sicherheitsverwaltung und Bedrohungserkennung erfordert – z. B. Erkennung von verdächtigen Aktivitäten und entsprechende Warnung –, können Sie den Cloudworkloadschutz einzeln für verschiedene Ressourcen aktivieren.
Kostenoptimierung
Informationen zur Kostenoptimierungssäule des Well-Architected Framework finden Sie unter Kostenoptimierung.
Wesentliche Vorteil der Data Lakehouse-Lösung sind ihre Kosteneffizienz und ihre skalierbare Architektur. Die meisten Komponenten in der Lösung verwenden eine nutzungsbasierte Abrechnung und lassen sich automatisch skalieren. In dieser Lösung werden alle Daten in Data Lake Storage gespeichert. Sie bezahlen nur für die Datenspeicherung, wenn Sie keine Abfragen ausführen oder Daten verarbeiten.
Die Preise für diese Lösung hängen von der Verwendung der folgenden Schlüsselressourcen ab:
- Serverloses SQL in Azure Synapse: Mit einer nutzungsbasierten Abrechnung zahlen Sie nur für das, was Sie tatsächlich verwenden.
- Apache Spark in Azure Synapse: Mit einer nutzungsbasierten Abrechnung zahlen Sie nur für das, was Sie tatsächlich verwenden.
- Azure Synapse-Pipelines: Mit einer nutzungsbasierten Abrechnung zahlen Sie nur für das, was Sie tatsächlich verwenden.
- Azure Data Lakes: Mit einer nutzungsbasierten Abrechnung zahlen Sie nur für das, was Sie tatsächlich verwenden.
- Power BI: Die Kosten richten sich nach der von Ihnen erworbenen Lizenz.
- Private Link: Mit einer nutzungsbasierten Abrechnung zahlen Sie nur für das, was Sie tatsächlich verwenden.
Verschiedene Sicherheits- und Schutzlösungen weisen verschiedene Kostenmodi auf. Sie sollten die Sicherheitslösung auswählen, die sich am besten für Ihre Kombination aus Geschäftsanforderungen und Lösungskosten eignet.
Sie können den Azure-Preisrechner verwenden, um die Kosten für die Lösung zu schätzen.
Optimaler Betrieb
Informationen zur Operational Excellence-Säule des Well-Architected Framework finden Sie unter Operational Excellence.
Verwenden eines selbst gehosteten Pipeline-Agents für CI/CD-Dienste in einem virtuellen Netzwerk
Der standardmäßige Azure DevOps-Pipeline-Agent unterstützt keine virtuelle Netzwerkkommunikation, da dabei ein sehr umfassender IP-Adressbereich verwendet wird. Diese Lösung implementiert einen selbst gehosteten Azure DevOps-Agent im virtuellen Netzwerk, damit die DevOps-Prozesse reibungslos mit den anderen Diensten in der Lösung kommunizieren können. Die Verbindungszeichenfolgen und Geheimnisse für die Ausführung der CI/CD-Dienste werden in einem unabhängigen Schlüsseltresor gespeichert. Während des Bereitstellungsprozesses greift der selbst gehostete Agent auf den Schlüsseltresor in der Kerndatenzone zu, um Ressourcenkonfigurationen und Geheimnisse zu aktualisieren. Weitere Informationen finden Sie im Dokument Verwenden von separaten Schlüsseltresoren. Diese Lösung verwendet auch VM-Skalierungsgruppen, um sicherzustellen, dass das DevOps-Modul basierend auf der Workload automatisch hoch- und herunterskaliert werden kann.

Implementieren von Überprüfungen der Infrastruktursicherheit und Sicherheitsfeuerproben in der CI/CD-Pipeline
Ein statisches Analysetool zum Überprüfen von IaC-Dateien (Infrastructure-as-Code) kann dabei helfen, Fehlkonfigurationen zu erkennen und zu verhindern, die zu Sicherheits- oder Complianceproblemen führen können. Feuerproben stellen sicher, dass die lebenswichtigen Systemsicherheitsmaßnahmen erfolgreich aktiviert wurden, und schützen so vor Bereitstellungsfehlern.
- Verwenden Sie ein statisches Analysetool zum Überprüfen von IaC-Vorlagen (Infrastructure-as-Code), um Fehlkonfigurationen zu erkennen und zu verhindern, die zu Sicherheits- oder Complianceproblemen führen können. Verwenden Sie Tools wie Checkov oder Terrascan, um Sicherheitsrisiken zu erkennen und zu verhindern.
- Stellen Sie sicher, dass die CD-Pipeline Bereitstellungsfehler ordnungsgemäß behandelt. Alle Bereitstellungsfehler im Zusammenhang mit Sicherheitsfeatures sollten als kritische Fehler behandelt werden. Die Pipeline sollte die fehlerhafte Aktion wiederholen oder die Bereitstellung anhalten.
- Überprüfen Sie die Sicherheitsmaßnahmen in der Bereitstellungspipeline, indem Sie Sicherheitsfeuerproben ausführen. Diese Feuerproben – z. B. die Überprüfung des Konfigurationsstatus von bereitgestellten Ressourcen oder das Ausführen von Testfällen, die kritische Sicherheitsszenarien untersuchen –, können sicherstellen, dass das Sicherheitsdesign wie erwartet funktioniert.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Herman Wu | Senior Software Engineer
Andere Mitwirkende:
- Ian Chen | Principal Software Engineer Lead
- Jose Contreras | Principal Software Engineering
- Roy Chan | Principal Software Engineer Manager
Nächste Schritte
- Azure-Produktdokumentation
- Andere Artikel
- Was ist Azure Synapse Analytics?
- Serverloser SQL-Pool in Azure Synapse Analytics
- Apache Spark in Azure Synapse Analytics
- Pipelines und Aktivitäten in Azure Data Factory und Azure Synapse Analytics
- Was ist Azure Synapse Data Explorer? (Vorschau)
- Machine Learning-Funktionen in Azure Synapse Analytics
- Was ist Microsoft Purview?
- Bessere Zusammenarbeit zwischen Azure Synapse Analytics und Azure Purview
- Einführung in Azure Data Lake Storage Gen2
- Was ist Azure Data Factory?
- Blogreihe zu aktuellen Datenmustern: Data Lakehouse
- Was ist Microsoft Defender für Cloud?
- Data Lakehouse, Data Warehouse und eine moderne Datenplattformarchitektur
- Best Practices für das Organisieren von Azure Synapse-Arbeitsbereichen und Lakehouse
- Grundlegendes zu privaten Endpunkten für Azure Synapse
- Azure Synapse Analytics – neue Erkenntnisse zur Datensicherheit
- Azure-Sicherheitsbaseline für Azure Synapse dedizierten SQL-Pool (früher SQL DW)
- Cloud Network Security 101: Azure-Dienstendpunkte im Vergleich zu privaten Endpunkten
- Einrichten der Zugriffssteuerung für Ihren Azure Synapse-Arbeitsbereich
- Herstellen einer Verbindung mit Azure Synapse Studio mit Azure Private Link-Hubs
- Bereitstellen Ihrer Azure Synapse-Arbeitsbereichartefakte in einem Azure Synapse-Arbeitsbereich in einem verwalteten VNet
- Kontinuierliche Integration und Bereitstellung für einen Azure Synapse Analytics-Arbeitsbereich
- Sicherheitsbewertung in Microsoft Defender für Cloud
- Bewährte Methoden für die Verwendung von Azure Key Vault
- Adatum Corporation-Szenario für Datenverwaltung und -analysen in Azure