Was ist die SQL-Datensynchronisierung für Azure?
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Wichtig
SQL-Datensynchronisierung wird am 30. September 2027 ausgemustert. Erwägen Sie die Migration zu alternativen Datenreplikations-/Synchronisierungslösungen.
SQL-Datensynchronisierung ist ein Dienst, der auf Azure SQL-Datenbank basiert und mit dem Sie die ausgewählten Daten bidirektional über mehrere Datenbanken hinweg synchronisieren können, sowohl lokal als auch in der Cloud.
Azure SQL Managed Instance und Azure Synapse Analytics werden nicht von der Azure SQL-Datensynchronisierung unterstützt.
Übersicht
Grundlage der Datensynchronisierung ist eine Synchronisierungsgruppe. Eine Synchronisierungsgruppe ist eine Gruppe von Datenbanken, die Sie synchronisieren möchten.
Für die Datensynchronisierung wird eine Topologie der Art „Nabe und Speiche“ genutzt, um Daten zu synchronisieren. Sie definieren eine der Datenbanken in der Synchronisierungsgruppe als Hub-Datenbank. Die übrigen Datenbanken sind Mitgliedsdatenbanken. Die Synchronisierung erfolgt nur zwischen dem Hub und den einzelnen Mitgliedern.
- Die Hub-Datenbank muss eine Azure SQL-Datenbank sein.
- Die Mitgliedsdatenbanken können entweder Datenbanken in Azure SQL-Datenbank oder in Instanzen von SQL Server sein.
- Die Synchronisierungs-Metadatendatenbank enthält die Metadaten und das Protokoll für die Datensynchronisierung. Bei der Synchronisierungs-Metadatendatenbank muss es sich um eine Azure SQL-Datenbank handeln, die sich in derselben Region wie die Hub-Datenbank befindet. Die Synchronisierungs-Metadatendatenbank wird vom Kunden erstellt und befindet sich in seinem Besitz. Sie können nur eine Synchronisierungs-Metadatendatenbank pro Region und Abonnement verwenden. Die Datenbank für Synchronisierungsmetadaten kann nicht gelöscht oder umbenannt werden, wenn Synchronisierungsgruppen oder Synchronisierungs-Agents vorhanden sind. Microsoft empfiehlt, eine neue, leere Datenbank als Synchronisierungs-Metadatendatenbank zu erstellen. Durch die Datensynchronisierung werden Tabellen in Datenbanken erstellt und eine häufige Workload ausgeführt.
Hinweis
Wenn Sie eine lokale Datenbank als Mitgliedsdatenbank verwenden, ist es erforderlich, einen lokalen Synchronisierungs-Agent zu installieren und zu konfigurieren.
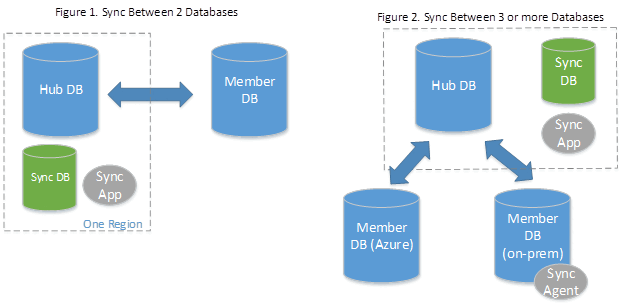
Eine Synchronisierungsgruppe hat die folgenden Eigenschaften:
- Im Synchronisierungsschema wird beschrieben, welche Daten synchronisiert werden.
- Die Synchronisierungsrichtung kann bidirektional oder unidirektional sein. Für die Synchronisierungsrichtung kann also Vom Hub zum Mitglied, Vom Mitglied zum Hub oder beides gelten.
- Mit dem Synchronisierungsintervall wird die Häufigkeit der Synchronisierung angegeben.
- Die Richtlinie zur Konfliktlösung ist eine Richtlinie auf Gruppenebene, die den Typ Hub gewinnt oder Mitglied gewinnt haben kann.
Verwendung
Die Datensynchronisierung ist nützlich, wenn Daten über mehrere Datenbanken in Azure SQL-Datenbank oder SQL Server hinweg auf dem neuesten Stand gehalten werden müssen. Hier sind die wichtigsten Anwendungsfälle für die Datensynchronisierung aufgeführt:
- Synchronisierung von Hybriddaten: Mit Azure SQL-Datensynchronisierung können Sie Daten zwischen Ihren Datenbanken in SQL Server und Azure SQL-Datenbank synchron halten, um Hybridanwendungen zu ermöglichen. Diese Funktionalität spricht unter Umständen Kund*innen an, die eine Umstellung auf die Cloud erwägen und einen Teil ihrer Anwendungen in Azure ausführen möchten.
- Verteilte Anwendungen: In vielen Fällen ist es vorteilhaft, unterschiedliche Workloads auf verschiedene Datenbanken zu verteilen. Wenn Sie beispielsweise über eine große Produktionsdatenbank verfügen, aber gleichzeitig die Berichterstellung oder Analyse für diese Daten durchführen müssen, ist für diese zusätzliche Workload die Verwendung einer zweiten Datenbank hilfreich. Bei diesem Ansatz werden die Auswirkungen auf die Leistung Ihrer Produktionsworkload reduziert. Sie können die Datensynchronisierung nutzen, um diese beiden Datenbanken synchron zu halten.
- Global verteilte Anwendungen: Viele Unternehmen sind in mehreren Regionen und sogar mehreren Ländern/Regionen ansässig. Es ist ratsam, die Daten jeweils in einer Region in der Nähe vorzuhalten, um die Netzwerklatenz zu verringern. Mit der Datensynchronisierung können Sie Datenbanken in den Regionen weltweit synchron halten.
Die Datensynchronisierung ist für folgende Szenarios nicht die beste Lösung:
| Szenario | Einige empfohlene Lösungen |
|---|---|
| Notfallwiederherstellung | Automatisierte Sicherungen in Azure SQL-Datenbank |
| Leseskalierung | Verwenden von schreibgeschützten Replikaten zum Lesen schreibgeschützter Abfrageworkloads |
| ETL (OLTP zu OLAP) | Azure Data Factory oder SQL Server Integration Services |
| Migration von SQL Server zu Azure SQL-Datenbank. Mit der SQL-Datensynchronisierung kann jedoch nach Abschluss der Migration sichergestellt werden, dass Quelle und Ziel synchron bleiben. | Azure Database Migration Service |
Funktionsweise
- Nachverfolgen von Datenänderungen: Bei der Datensynchronisierung werden Änderungen mithilfe von Auslösern für Einfügen, Aktualisieren und Löschen nachverfolgt. Die Änderungen werden in der Benutzerdatenbank in einer Nebentabelle aufgezeichnet. BULK INSERT löst standardmäßig keine Trigger aus. Wenn FIRE_TRIGGERS nicht angegeben ist, werden keine Einfügungstrigger ausgeführt. Fügen Sie die Option FIRE_TRIGGERS hinzu, damit die Datensynchronisierung diese Einfügungen verfolgen kann.
- Synchronisieren von Daten: Für die Datensynchronisierung wird ein Hub-and-Spoke-Modell genutzt. Der Hub wird einzeln mit jedem Mitglied synchronisiert. Änderungen auf dem Hub werden für das Mitglied heruntergeladen, und anschließend werden Änderungen vom Mitglied auf den Hub hochgeladen.
- Beheben von Konflikten: Die Datensynchronisierung bietet zwei Optionen für die Lösung von Konflikten, und zwar Hub gewinnt und Mitglied gewinnt.
- Wenn Sie Hub gewinnt wählen, werden die Änderungen auf dem Mitglied immer durch die Änderungen des Hub überschrieben.
- Bei Auswahl von Mitglied gewinnt werden die Änderungen auf dem Hub durch die Änderungen auf dem Mitglied überschrieben. Falls mehr als ein Mitglied vorhanden ist, hängt der endgültige Wert davon ab, welches Mitglied zuerst synchronisiert wird.
Vergleichen mit der Transaktionsreplikation
| Datensynchronisierung | Transaktionsreplikation | |
|---|---|---|
| Vorteile | – Aktiv/Aktiv-Unterstützung – Bidirektional zwischen lokaler und Azure SQL-Datenbank |
– Niedrigere Latenzzeiten – Transaktionskonsistenz – Wiederverwendung vorhandener Topologie nach der Migration – Unterstützung von Azure SQL Managed Instance |
| Nachteile | – Keine Transaktionskonsistenz – Größere Auswirkung auf die Leistung |
– Keine Veröffentlichung aus Azure SQL-Datenbank – Hohe Wartungskosten |
Private Link für Datensynchronisierung
Hinweis
Der SQL-Datensynchronisierung privaten Link ist anders als der private Azure-Link.
Mit dem neuen Feature für private Verbindungen können Sie einen von einem Dienst verwalteten privaten Endpunkt auswählen, um während des Datensynchronisierungsvorgangs eine sichere Verbindung zwischen dem Synchronisierungsdienst und Ihren Mitglieds-/Hubdatenbanken herzustellen. Ein vom Dienst verwalteter privater Endpunkt ist eine private IP-Adresse in einem bestimmten virtuellen Netzwerk und Subnetz. Bei Datensynchronisierung wird der vom Dienst verwaltete private Endpunkt von Microsoft erstellt und exklusiv vom Dienst Datensynchronisierung für einen bestimmten Synchronisierungsvorgang verwendet.
Lesen Sie vor dem Einrichten der privaten Verbindung die allgemeinen Anforderungen für das Feature.

Hinweis
Sie müssen den vom Dienst verwalteten privaten Endpunkt manuell genehmigen – entweder während der Synchronisierungsgruppenbereitstellung im Azure-Portal auf der Seite Verbindungen mit privatem Endpunkt oder mithilfe von PowerShell.
Erste Schritte
Einrichten der Datensynchronisierung im Azure-Portal
- Tutorial: Einrichten der SQL-Datensynchronisierung zwischen Datenbanken in Azure SQL-Datenbank und SQL Server
- Data Sync Agent – Data Sync Agent für die SQL-Datensynchronisierung
Einrichten der Datensynchronisierung mit PowerShell
- Verwenden von PowerShell zum Synchronisieren von Daten zwischen mehreren Datenbanken in Azure SQL-Datenbank
- Verwenden von PowerShell zum Synchronisieren von Daten zwischen SQL-Datenbank und SQL Server
Einrichten der Datensynchronisierung mit der REST-API
Überprüfen der bewährten Methoden für die Datensynchronisierung
- Best practices for Azure SQL Data Sync (Preview) (Bewährte Methoden für die Azure SQL-Datensynchronisierung-Vorschauversion)
Ist etwas schiefgegangen?
Konsistenz und Leistung
Letztliche Konsistenz
Die Transaktionskonsistenz ist nicht garantiert, da die Datensynchronisierung auf Auslösern basiert. Microsoft gewährleistet, dass alle Änderungen letztlich vorgenommen werden und dass es bei der Datensynchronisierung nicht zu Datenverlusten kommt.
Auswirkungen auf die Leistung
Für die Datensynchronisierung werden Auslöser für Einfügen, Aktualisieren und Löschen verwendet, um Änderungen nachzuverfolgen. In der Benutzerdatenbank werden Nebentabellen für die Änderungsnachverfolgung erstellt. Diese Aktivitäten zur Änderungsnachverfolgung haben Auswirkungen auf Ihre Datenbankworkload. Bewerten Sie Ihre Dienstebene, und aktualisieren Sie sie bei Bedarf.
Das Bereitstellen und Aufheben der Bereitstellung während der Erstellung, Aktualisierung oder Löschung von Synchronisierungsgruppen kann sich ebenfalls auf die Datenbankleistung auswirken.
Anforderungen und Einschränkungen
Allgemeine Anforderungen
- Jede Tabelle muss über einen Primärschlüssel verfügen. Ändern Sie nicht den Wert des Primärschlüssels in einer Zeile. Wenn Sie einen Primärschlüsselwert ändern müssen, können Sie die Zeile löschen und mit dem neuen Wert des Primärschlüssels neu erstellen.
Wichtig
Wenn Sie den Wert eines vorhandenen Primärschlüssels ändern, führt dies zu folgendem fehlerhaften Verhalten:
- Daten zwischen Hub und Mitglied können verloren gehen, auch wenn bei der Synchronisierung kein Problem gemeldet wird.
- Bei der Synchronisierung kann ein Fehler auftreten, weil die Nachverfolgungstabelle aufgrund der Primärschlüsseländerung über eine nicht vorhandene Zeile aus der Quelle verfügt.
Momentaufnahmeisolation muss sowohl für die Synchronisierungsmitglieder als auch den Hub aktiviert sein. Weitere Informationen finden Sie unter Momentaufnahmeisolation in SQL Server.
Damit die private Verbindung für die Datensynchronisierung verwendet werden kann, müssen die Mitglieds- und Hubdatenbanken in Azure (in derselben oder in verschiedenen Regionen) mit demselben Cloudtyp (z. B. beide in der öffentlichen Cloud oder beide in der Government-Cloud) gehostet werden. Außerdem müssen zur Verwendung privater Links
Microsoft.Network-Ressourcenanbieter für die Abonnements registriert werden, die die Hub- und Mitgliedsserver hosten. Schließlich müssen Sie die private Verbindung für Datensynchronisierung während der Synchronisierungskonfiguration im Abschnitt „Verbindungen mit privatem Endpunkt“ im Azure-Portal oder mit PowerShell manuell genehmigen. Weitere Informationen dazu, wie die private Verbindung genehmigt wird, finden Sie unter Tutorial: Einrichten von SQL-Datensynchronisierung zwischen Datenbanken in Azure SQL-Datenbank und SQL Server. Nachdem Sie den vom Dienst verwalteten privaten Endpunkt genehmigt haben, erfolgt die gesamte Kommunikation zwischen dem Synchronisierungsdienst und den Mitglieds-/Hub-Datenbanken über die private Verbindung. Dieses Feature kann auch für vorhandene Synchronisierungsgruppen aktiviert werden.
Allgemeine Einschränkungen
- Eine Tabelle kann keine Identitätsspalte enthalten, die kein Primärschlüssel ist.
- Ein Primärschlüssel kann nicht über die folgenden Datentypen verfügen: sql_variant, binary, varbinary, image, xml.
- Gehen Sie mit Bedacht vor, wenn Sie die folgenden Datentypen als Primärschlüssel verwenden, da nur die Genauigkeit bis auf die Sekunde unterstützt wird: time, datetime, datetime2, datetimeoffset.
- Die Namen von Objekten (Datenbanken, Tabellen und Spalten) dürfen nicht die druckbaren Zeichen Punkt (
.), linke eckige Klammer ([) oder rechte eckige Klammer (]) enthalten. - Ein Tabellenname darf keine druckbaren Zeichen enthalten:
! " # $ % ' ( ) * + -oder Leerzeichen. - Die Microsoft Entra-Authentifizierung (bisher Azure Active Directory) wird nicht unterstützt.
- Gibt es Tabellen, die denselben Namen, aber unterschiedlichen Schemas haben (z. B.
dbo.customersundsales.customers), kann nur eine der Tabellen in der Synchronisierung hinzugefügt werden. - Spalten mit benutzerdefinierten Datentypen werden nicht unterstützt.
- Das Verschieben von Servern zwischen verschiedenen Abonnements wird nicht unterstützt.
- Wenn sich zwei Primärschlüssel nur in Bezug auf die Groß-/Kleinschreibung unterscheiden (z. B.
Fooundfoo), wird dieses Szenario von der Datensynchronisierung nicht unterstützt. - Das Verkürzen von Tabellen wird von der Datensynchronisierung nicht unterstützt (Änderungen werden nicht nachverfolgt).
- Die Verwendung einer Azure SQL Hyperscale-Datenbank als Hubdatenbank oder als Datenbank zum Synchronisieren von Metadaten wird nicht unterstützt. Eine Hyperscale-Datenbank kann jedoch eine Mitgliedsdatenbank in einer Datensynchronisierungstopologie sein.
- Speicheroptimierte Tabellen werden nicht unterstützt.
- Schemaänderungen werden nicht automatisch repliziert. Eine benutzerdefinierte Lösung kann erstellt werden, um die Replikation von Schemaänderungen zu automatisieren.
- Die Datensynchronisierung unterstützt nur die folgenden beiden Indexeigenschaften: Unique, Clustered/Non-Clustered. Andere Indexeigenschaften wie
IGNORE_DUP_KEYoder das FilterprädikatWHEREwerden nicht unterstützt und der Zielindex wird ohne diese Eigenschaften bereitgestellt, auch wenn die Eigenschaften für den Quellindex festgelegt sind. - Eine Datenbank für elastische Aufträge kann nicht als Datenbank für SQL-Datensynchronisierungsmetadaten verwendet werden und umgekehrt.
- SQL-Datensynchronisierung wird für Ledgerdatenbanken nicht unterstützt.
Nicht unterstützte Datentypen
- FileStream
- SQL/CLR UDT
- XMLSchemaCollection (XML unterstützt)
- Cursor, RowVersion, Timestamp, Hierarchyid
Nicht unterstützte Spaltentypen
Mit der Datensynchronisierung können keine schreibgeschützten oder vom System generierten Spalten synchronisiert werden. Beispiel:
- Berechnete Spalten.
- Vom System generierte Spalten für temporale Tabellen
Einschränkungen von Dienst- und Datenbankdimensionen
| Dimensionen | Begrenzung | Problemumgehung |
|---|---|---|
| Maximale Anzahl von Synchronisierungsgruppen, denen eine Datenbank angehören kann | 5 | |
| Maximale Anzahl von Endpunkten einer einzelnen Synchronisierungsgruppe | 30 | |
| Maximale Anzahl von lokalen Endpunkten in einer einzelnen Synchronisierungsgruppe | 5 | Erstellen mehrerer Synchronisierungsgruppen |
| Namen von Datenbanken, Tabellen, Schemas und Spalten | 50 Zeichen pro Name | |
| Tabellen in einer Synchronisierungsgruppe | 500 | Erstellen mehrerer Synchronisierungsgruppen |
| Spalten in einer Tabelle einer Synchronisierungsgruppe | 1000 | |
| Größe von Datenzeilen in einer Tabelle | 24 Mb |
Hinweis
Es können bis zu 30 Endpunkte in einer einzelnen Synchronisierungsgruppe vorhanden sein, wenn es nur eine Synchronisierungsgruppe gibt. Wenn mehr als eine Synchronisierungsgruppe vorhanden ist, darf die Gesamtanzahl der Endpunkte in allen Synchronisierungsgruppen 30 nicht überschreiten. Wenn eine Datenbank mehreren Synchronisierungsgruppen angehört, wird sie als mehrere Endpunkte und nicht als einer gezählt.
Netzwerkanforderungen
Hinweis
Wenn Sie die Synchronisierung für private Verbindungen verwenden, gelten diese Netzwerkanforderungen nicht.
Wenn die Synchronisierungsgruppe eingerichtet ist, muss der Datensynchronisierungsdienst eine Verbindung mit der Hub-Datenbank herstellen. Wenn Sie die Synchronisierungsgruppe einrichten, muss der Azure SQL-Server in seinen Einstellungen für Firewalls and virtual networks die folgende Konfiguration aufweisen:
- Zugriff auf öffentliches Netzwerk verweigern muss auf Aus festgelegt werden.
- Anderen Azure-Diensten und -Ressourcen den Zugriff auf diesen Server gestatten muss auf Ja festgelegt werden, oder Sie müssen IP-Regeln für die vom Datensynchronisationsdienst verwendeten IP-Adressen erstellen.
Nachdem die Synchronisierungsgruppe erstellt und bereitgestellt wurde, können Sie diese Einstellungen deaktivieren. Der Synchronisierungs-Agent stellt eine direkte Verbindung mit der Hub-Datenbank her, und Sie können die Firewall-IP-Regeln oder privaten Endpunkte des Servers verwenden, um dem Agent den Zugriff auf den Hubserver zu gestatten.
Hinweis
Wenn Sie die Schemaeinstellungen der Synchronisierungsgruppe ändern, müssen Sie dem Datensynchronisierungsdienst den Zugriff auf den Server erneut gestatten, damit die Hub-Datenbank erneut bereitgestellt werden kann.
Regionsdatenresidenz
Wenn Sie Daten innerhalb derselben Region synchronisieren, werden bei der SQL-Datensynchronisierung keine Kundendaten außerhalb der Region gespeichert oder verarbeitet, in der die Dienstinstanz bereitgestellt wird. Wenn Sie Daten regionsübergreifend synchronisieren, werden bei der SQL-Datensynchronisierung die Kundendaten in den Regionspaaren repliziert.
Häufig gestellte Fragen zur SQL-Datensynchronisierung
Wie viel kostet der SQL-Datensynchronisierungsdienst?
Für den SQL-Datensynchronisierungsdienst selbst fallen keine Kosten an. Es fallen aber weiterhin Datenübertragungsgebühren für die ein- und ausgehende Datenverschiebung für Ihre SQL-Datenbankinstanz an. Weitere Informationen finden Sie unter Datenübertragungsgebühren.
Welche Regionen werden für die Datensynchronisierung unterstützt?
Die SQL-Datensynchronisierung ist in allen Regionen verfügbar.
Ist ein SQL-Datenbankkonto erforderlich?
Ja. Sie müssen über ein SQL-Datenbank-Konto zum Hosten der Hub-Datenbank verfügen.
Kann ich die Datensynchronisierung verwenden, um Daten ausschließlich für SQL Server-Datenbanken synchronisieren zu lassen?
Nicht direkt. Sie können Daten zwischen SQL Server-Datenbanken jedoch indirekt synchronisieren, indem Sie in Azure eine Hub-Datenbank erstellen und anschließend die lokalen Datenbanken der Synchronisierungsgruppe hinzufügen.
Kann ich Datensynchronisierung konfigurieren, um Datenbanken in Azure SQL-Datenbank zu synchronisieren, die zu unterschiedlichen Abonnements gehören?
Ja. Sie können Synchronisierung zwischen Datenbanken konfigurieren, die zu Ressourcengruppen im Besitz verschiedener Abonnements gehören, auch wenn die Abonnements zu verschiedenen Mandanten gehören.
- Wenn die Abonnements zum gleichen Mandanten gehören und Sie über Berechtigungen für alle Abonnements verfügen, können Sie die Synchronisierungsgruppe im Azure-Portal konfigurieren.
- Andernfalls müssen Sie PowerShell verwenden, um die Mitglieder für die Synchronisierung hinzuzufügen.
Kann ich Datensynchronisierung zum Synchronisieren zwischen Datenbanken in SQL-Datenbank einrichten, die zu verschiedenen Clouds gehören (etwa zur öffentlichen Azure-Cloud und Azure, betrieben von 21Vianet)?
Ja. Sie können Synchronisierung zwischen Datenbanken einrichten, die zu verschiedenen Clouds gehören. Sie müssen PowerShell verwenden, um die Synchronisierungsmitglieder hinzuzufügen, die zu den verschiedenen Abonnements gehören.
Kann ich mithilfe der Datensynchronisierung ein Seeding für Daten aus meiner Produktionsdatenbank in eine leere Datenbank ausführen und die Daten dann synchronisieren?
Ja. Erstellen Sie das Schema in der neuen Datenbank mithilfe eines Skripts manuell, das sich am Original orientiert. Nachdem Sie das Schema erstellt haben, fügen Sie Tabellen einer Synchronisierungsgruppe hinzu, um die Daten zu kopieren und synchron zu halten.
Sollte ich die SQL-Datensynchronisierung nutzen, um meine Datenbanken zu sichern und wiederherzustellen?
Es wird nicht empfohlen, die SQL-Datensynchronisierung zum Erstellen einer Sicherung Ihrer Daten zu verwenden. Sie können keine Sicherung und Wiederherstellung für einen bestimmten Zeitpunkt durchführen, da Synchronisierungen mit der SQL-Datensynchronisierung keine Versionsangaben aufweisen. Zudem werden mit der SQL-Datensynchronisierung keine anderen SQL-Objekte gesichert, z. B. gespeicherte Prozeduren, und es kann kein schneller Wiederherstellungsvorgang durchgeführt werden.
Weitere Informationen zu einer empfohlenen Backup-Technik finden Sie unter Kopieren einer transaktionskonsistenten Kopie einer Datenbank in Azure SQL-Datenbank.
Kann die Datensynchronisierung verschlüsselte Tabellen und Spalten synchronisieren?
- Wenn eine Datenbank Always Encrypted verwendet, können nur die nicht verschlüsselten Tabellen und Spalten synchronisiert werden. Die verschlüsselten Spalten können nicht synchronisiert werden, da die Datensynchronisierung die Daten nicht entschlüsseln kann.
- Wenn eine Spalte die Verschlüsselung auf Spaltenebene (Column-Level Encryption, CLE) verwendet, können Sie die Spalte synchronisieren, sofern die Zeilengröße die maximal zulässige Größe von 24 MB nicht übersteigt. Die Datensynchronisierung behandelt die durch einen Schlüssel verschlüsselte Spalte (CLE) als gewöhnliche Binärdaten. Um die Daten auf anderen Synchronisierungsmitgliedern entschlüsseln zu können, benötigen Sie das gleiche Zertifikat.
Wird die Sortierung für die SQL-Datensynchronisierung unterstützt?
Ja. Für die SQL-Datensynchronisierung wird die Sortierung in den folgenden Szenarien unterstützt:
- Falls sich die gewählten Schematabellen für die Synchronisierung nicht bereits in Ihren Hub- oder Mitgliedsdatenbanken befinden, erstellt der Dienst während der Bereitstellung der Synchronisierungsgruppe durch Sie automatisch die entsprechenden Tabellen und Spalten, und die Sortierungseinstellungen sind in den leeren Zieldatenbanken ausgewählt.
- Wenn die zu synchronisierenden Tabellen bereits sowohl in Ihren Hub-Datenbanken als auch in Ihren Mitgliedsdatenbanken vorhanden sind, müssen für die SQL-Datensynchronisierung die Primärschlüsselspalten die gleiche Sortierung in der Hub- und Mitgliedsdatenbank aufweisen, damit die Synchronisierungsgruppe erfolgreich bereitgestellt werden kann. Für andere Spalten als die Primärschlüsselspalten gelten keine Sortierungseinschränkungen.
Wird der Verbund für die SQL-Datensynchronisierung unterstützt?
Eine Datenbank für den Verbundstamm kann im SQL-Datensynchronisierungsdienst ohne Einschränkungen verwendet werden. Es ist nicht möglich, den Endpunkt der Verbunddatenbank zur aktuellen Version der SQL-Datensynchronisierung hinzuzufügen.
Kann ich die Datensynchronisierung verwenden, um Daten zu synchronisieren, die aus Dynamics 365 unter Verwendung der BYOD-Funktion (Bring Your Own Database) exportiert wurden?
Mit dem BYOD-Feature von Dynamics 365 können Administratoren Datenentitäten aus der Anwendung in ihre eigene Microsoft Azure SQL-Datenbank exportieren. Die Datensynchronisierung kann verwendet werden, um diese Daten mit anderen Datenbanken zu synchronisieren, wenn die Daten mit einem inkrementellen Pushvorgang exportiert werden (vollständige Pushvorgänge werden nicht unterstützt) und Trigger in Zieldatenbank aktivieren auf Ja festgelegt ist.
Wie erstelle ich eine Datensynchronisation in der Failover-Gruppe zur Unterstützung der Notfallwiederherstellung?
- Um sicherzustellen, dass die Datensynchronisierungsvorgänge in der Failoverregion mit der primären Region identisch sind, müssen Sie nach dem Failover die Synchronisierungsgruppe in der Failoverregion mit den gleichen Einstellungen wie die primäre Region manuell neu erstellen.
Zugehöriger Inhalt
Aktualisieren des Schemas einer synchronisierten Datenbank
Müssen Sie das Schema einer Datenbank in einer Synchronisierungsgruppe aktualisieren? Schemaänderungen werden nicht automatisch repliziert. Einige Lösungen finden Sie in den folgenden Artikeln:
- Automatisieren der Replikation von Schemaänderungen mit der SQL-Datensynchronisierung in Azure
- Verwenden von PowerShell zum Aktualisieren des Synchronisierungsschemas in einer bestehenden Synchronisierungsgruppe
Überwachen und Behandeln von Problemen
Wird die SQL-Datensynchronisierung wie erwartet ausgeführt? Informationen zum Überwachen der Aktivität und Behandeln von Problemen finden Sie in den folgenden Artikeln:
- Überwachen der SQL-Datensynchronisierung mit Azure Monitor-Protokollen
- Troubleshoot issues with SQL Data Sync (Preview) (Behandeln von Problemen mit der Azure SQL-Datensynchronisierung-Vorschauversion)
Weitere Informationen zu Azure SQL-Datenbank
Weitere Informationen zu Azure SQL-Datenbank finden Sie in den folgenden Artikeln: