Das Textformat mit Trennzeichen in Azure Data Factory and Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Beachten Sie diesen Artikel, wenn Sie die Textdateien mit Trennzeichen analysieren oder die Daten im Textformat mit Trennzeichen schreiben möchten.
Das Textformat mit Trennzeichen wird für folgende Connectors unterstützt:
- Amazon S3
- Amazon S3 Compatible Storage
- Azure-Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Dateisystem
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste mit Eigenschaften, die vom DelimitedText-Dataset unterstützt werden.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf DelimitedText festgelegt werden. | Ja |
| location | Speicherorteinstellungen der Datei(en) Jeder dateibasierte Connector verfügt unter location über seinen eigenen Speicherorttyp und unterstützte Eigenschaften. |
Ja |
| columnDelimiter | Das Zeichen, das in einer Datei zum Trennen von Spalten verwendet wird. Der Standardwert ist das Komma ,. Wenn das Spaltentrennzeichen als leere Zeichenfolge, d. h. kein Trennzeichen, definiert wurde, wird die gesamte Zeile als eine einzige Spalte betrachtet.Zurzeit wird das Spaltentrennzeichen als leere Zeichenfolge nur für den Zuordnungsdatenfluss unterstützt, aber nicht für die Copy-Aktivität. |
Nein |
| rowDelimiter | Bei der Copy-Aktivität das einzelne Zeichen oder "\r\n", das zur Trennung von Zeilen in einer Datei verwendet wird. Der Standardwert ist einer der folgenden Werte beim Lesen: ["\r\n", "\r", "\n"]; beim Schreiben: "\r\n". "\r\n" wird nur im Kopierbefehl unterstützt. Bei Zuordnungsdatenfluss die einzelnen oder zwei Zeichen, die zum Trennen von Zeilen in einer Datei verwendet werden. Der Standardwert ist einer der folgenden Werte beim Lesen: ["\r\n", "\r", "\n"]; beim Schreiben: "\n". Wenn das Zeilentrennzeichen auf „kein Trennzeichen“ (leere Zeichenfolge) festgelegt wird, muss auch das Spaltentrennzeichen auf „kein Trennzeichen“ (leere Zeichenfolge) festgelegt werden. Dies bedeutet, dass der gesamte Inhalt als Einzelwert behandelt wird. Zurzeit wird das Zeilentrennzeichen als leere Zeichenfolge nur für den Zuordnungsdatenfluss unterstützt, aber nicht für die Kopieraktivität. |
Nein |
| quoteChar | Das einzelne Zeichen, um Spaltenwerte mit Anführungszeichen zu versehen, wenn es ein Spaltentrennzeichen enthält. Der Standardwert ist ein doppeltes Anführungszeichen ". Wenn quoteChar als leere Zeichenfolge definiert ist, bedeutet dies, dass es kein Anführungszeichen gibt und der Spaltenwert nicht in Anführungszeichen gesetzt wird. Außerdem wird escapeChar verwendet, um das Spaltentrennzeichen und sich selbst mit Escapezeichen zu versehen. |
Nein |
| escapeChar | Das einzelne Zeichen zum Escapen von Anführungszeichen innerhalb eines mit Anführungszeichen versehenen Wertes. Der Standardwert ist ein umgekehrter Schrägstrich \ . Wenn escapeChar als leere Zeichenfolge definiert wird, muss auch quoteChar als leere Zeichenfolge festgelegt werden. In diesem Fall ist darauf zu achten, dass die Spaltenwerte keine Trennzeichen enthalten. |
Nein |
| firstRowAsHeader | Gibt an, ob die erste Zeile als Kopfzeile mit Spaltennamen behandelt bzw. zu dieser gemacht werden soll. Zulässige Werte sind true und false (Standard). Wenn der Wert für die erste Zeile als Kopfzeile „false“ lautet, werden bei der Vorschau der Benutzeroberflächendaten und der Ausgabe der Lookup-Aktivität automatisch Spaltennamen als „Prop_{n}“ (beginnend mit 0) generiert. Für die Kopieraktivität ist eine explizite Zuordnung von der Quelle zur Senke erforderlich, Spalten werden nach Ordnungszahl (beginnend mit 1) gesucht, und der Zuordnungsdatenfluss listet und sucht Spalten mit dem Namen „Column_{n}“ (beginnend mit 1). |
Nein |
| nullValue | Gibt eine Zeichenfolgendarstellung von Null-Werten an. Der Standardwert ist eine leere Zeichenfolge. |
Nein |
| encodingName | Der zu Lesen/Schreiben von Testdateien verwendete Codierungstyp. Folgende Werte sind zulässig: "UTF-8","UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Beachten Sie, dass Zuordnungsdatenflüsse keine UTF-7-Codierung unterstützen. Beachten Sie, dass der Zuordnungsdatenfluss keine UTF-8-Codierung mit Bytereihenfolge-Marke (Byte Order Mark, BOM) unterstützt. |
No |
| compressionCodec | Der zum Lesen und Schreiben von Textdateien verwendete Komprimierungscodec. Zulässige Werte sind bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy oder lz4. Standardmäßig erfolgt keine Komprimierung. Hinweis: „snappy“ und „lz4“ werden aktuell nicht von der Copy-Aktivität und „ZipDeflate“, „TarGzip“ und „Tar“ werden aktuell nicht vom Zuordnungsdatenfluss unterstützt. Beachten Sie, dass bei Verwendung der Kopieraktivität zum Dekomprimieren von ZipDeflate-/TarGzip-/Tar-Dateien und zum Schreiben in den dateibasierten Senkendatenspeicher diese Dateien standardmäßig in den Ordner <path specified in dataset>/<folder named as source compressed file>/ extrahiert werden. Verwenden Sie in diesem Fall preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder als Quelle der Kopieraktivität, um zu steuern, ob der Name der komprimierten Dateien als Ordnerstruktur beibehalten werden soll. |
Nein |
| compressionLevel | Das Komprimierungsverhältnis. Zulässige Werte sind Optimal oder Sehr schnell. - Sehr schnell: Der Komprimierungsvorgang wird schnellstmöglich abgeschlossen, auch wenn die resultierende Datei nicht optimal komprimiert ist. - Optimal: Die Daten sollten optimal komprimiert sein, auch wenn der Vorgang eine längere Zeit in Anspruch nimmt. Weitere Informationen finden Sie im Thema Komprimierungsstufe . |
Nein |
Nachfolgend sehen Sie das Beispiel eines DelimitedText-Datasets in Azure Blob Storage:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste mit Eigenschaften, die von der DelimitedText-Quelle und -Senke unterstützt werden.
Durch Trennzeichen getrennter Text als Quelle
Die folgenden Eigenschaften werden im Abschnitt *source* der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf DelimitedTextSource festgelegt werden. | Ja |
| formatSettings | Eine Gruppe von Eigenschaften. Weitere Informationen zu Leseeinstellungen für durch Trennzeichen getrennten Text finden Sie in der Tabelle unten. | Nein |
| storeSettings | Eine Gruppe von Eigenschaften für das Lesen von Daten aus einem Datenspeicher. Jeder dateibasierte Connector verfügt unter storeSettings über eigene unterstützte Leseeinstellungen. |
Nein |
Unterstützte Leseeinstellungen für durch Trennzeichen getrennten Text finden Sie unter formatSettings:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Der Typ von „formatSettings“ muss auf DelimitedTextReadSettings festgelegt werden. | Ja |
| skipLineCount | Gibt an, wie viele nicht leere Zeilen beim Lesen von Daten aus Eingabedateien übersprungen werden sollen. Wenn „skipLineCount“ und „firstRowAsHeader“ gleichzeitig angegeben sind, werden die Zeilen zuerst übersprungen, und anschließend werden die Kopfzeileninformationen aus der Eingabedatei gelesen. |
Nein |
| compressionProperties | Eine Gruppe von Eigenschaften zur Festlegung, wie Daten bei einem bestimmten Komprimierungscodec dekomprimiert werden können. | Nein |
| preserveZipFileNameAsFolder (unter compressionProperties->type als ZipDeflateReadSettings) |
Diese Eigenschaft gilt, wenn das Eingabedataset mit der ZipDeflate-Komprimierung konfiguriert wurde. Sie gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. – Lautet der Wert true (Standard) , schreibt der Dienst die entpackten Dateien in <path specified in dataset>/<folder named as source zip file>/.– Lautet der Wert false, schreibt der Dienst die entpackten Dateien direkt in <path specified in dataset>. Stellen Sie sicher, dass es in unterschiedlichen ZIP-Quelldateien keine doppelten Dateinamen gibt, um Racebedingungen oder unerwartetes Verhalten zu vermeiden. |
Nein |
| preserveCompressionFileNameAsFolder (unter compressionProperties->type als TarGZipReadSettings oder TarReadSettings) |
Gilt, wenn das Eingabedataset mit der Komprimierung TarGzip/Tar konfiguriert wurde. Gibt an, ob der Name der komprimierten Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. – Lautet der Wert true (Standard) , schreibt der Dienst die dekomprimierten Dateien in <path specified in dataset>/<folder named as source compressed file>/. – Lautet der Wert false, schreibt der Dienst die dekomprimierten Dateien direkt in <path specified in dataset>. Stellen Sie sicher, dass es in unterschiedlichen Quelldateien keine doppelten Dateinamen gibt, um Racebedingungen oder unerwartetes Verhalten zu vermeiden. |
Nein |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
Durch Trennzeichen getrennter Text als Senke
Die folgenden Eigenschaften werden im Abschnitt *sink* der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf DelimitedTextSink festgelegt werden. | Ja |
| formatSettings | Eine Gruppe von Eigenschaften. Weitere Informationen zu Schreibeinstellungen für durch Trennzeichen getrennten Text finden Sie in der Tabelle unten. | Nein |
| storeSettings | Eine Gruppe von Eigenschaften für das Schreiben von Daten in einen Datenspeicher. Jeder dateibasierte Connector verfügt unter storeSettings über eigene unterstützte Schreibeinstellungen. |
Nein |
Unterstützte Schreibeinstellungen für durch Trennzeichen getrennten Text finden Sie unter formatSettings:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Der Typ von „formatSettings“ muss auf DelimitedTextWriteSettings festgelegt werden. | Ja |
| fileExtension | Die Dateierweiterung, mit der die Ausgabedateien benannt werden, z. B. .csv, .txt. Es muss angegeben werden, wenn fileName nicht in der Ausgabe des DelimitedText-Datasets angegeben ist. Wenn der Dateiname im Ausgabedataset konfiguriert wurde, wird er als Name für die Senkendatei verwendet, und die Dateierweiterungseinstellung wird ignoriert. |
Ja, wenn kein Dateiname im Ausgabedataset angegeben ist |
| maxRowsPerFile | Wenn Sie Daten in einen Ordner schreiben, können Sie in mehrere Dateien zu schreiben und die maximale Anzahl von Zeilen pro Datei angeben. | Nein |
| fileNamePrefix | Gilt, wenn maxRowsPerFile konfiguriert ist.Geben Sie das Dateinamenpräfix beim Schreiben von Daten in mehrere Dateien an, das zu diesem Muster führt: <fileNamePrefix>_00000.<fileExtension>. Wenn keine Angabe erfolgt, wird das Dateinamenpräfix automatisch generiert. Diese Eigenschaft findet keine Anwendung, wenn die Quelle ein dateibasierter Speicher oder ein Datenspeicher mit aktivierter Partitionsoption ist. |
Nein |
Eigenschaften von Mapping Data Flow
Bei Zuordnungsdatenflüssen können Sie in den folgenden Datenspeichern das Textformat mit Trennzeichen lesen und schreiben: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 und SFTP. Darüber hinaus können Sie das Textformat mit Trennzeichen in Amazon S3 lesen.
Inline-Dataset
Zuordnungsdatenflüsse unterstützen „Inline-Datasets“ als Option zum Definieren Ihrer Quelle und Senke. Ein durch Inline getrenntes Dataset wird direkt in Ihren Quell- und Senkentransformationen definiert und außerhalb des definierten Dataflows nicht freigegeben. Es ist nützlich, um Dataset-Eigenschaften direkt in Ihrem Datenfluss zu parametrisieren und kann von einer verbesserten Leistung von freigegebenen ADF-Datasets profitieren.
Wenn Sie eine große Anzahl von Quellordnern und -dateien lesen, können Sie die Leistung der Erkennung von Datenflussdateien verbessern, indem Sie die Option „Vom Benutzer projiziertes Schema“ im Dialogfeld „Optionen – Projektion | Schema“ aktivieren. Diese Option deaktiviert die standardmäßige automatische Schemaerkennung von ADF und verbessert die Leistung der Dateierkennung erheblich. Bevor Sie diese Option festlegen, müssen Sie die Projektion importieren, damit ADF über ein vorhandenes Schema für die Projektion verfügt. Diese Option funktioniert nicht mit Schemaabweichung.
Quelleigenschaften
In der folgenden Tabelle sind die von einer DelimitedText-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Platzhalterpfade | Alle Dateien, die dem Platzhalterpfad entsprechen, werden verarbeitet. Überschreibt den Ordner und den Dateipfad, die im Dataset festgelegt sind. | nein | String[] | wildcardPaths |
| Partitionsstammpfad | Für partitionierte Dateidaten können Sie einen Partitionsstammpfad eingeben, um partitionierte Ordner als Spalten zu lesen. | nein | String | partitionRootPath |
| Liste mit den Dateien | Gibt an, ob Ihre Quelle auf eine Textdatei verweist, in der die zu verarbeitenden Dateien aufgelistet sind. | nein | true oder false |
fileList |
| Mehrzeilig | Gibt an, ob die Quelldatei Zeilen enthält, die sich über mehrere Zeilen erstrecken. Mehrzeilige Werte müssen in Anführungszeichen gesetzt werden. | nein true oder false |
multiLineRow | |
| Spalte, in der der Dateiname gespeichert wird | Erstellt eine neue Spalte mit dem Namen und Pfad der Quelldatei. | nein | String | rowUrlColumn |
| Nach Abschluss | Löscht oder verschiebt die Dateien nach der Verarbeitung. Dateipfad beginnt mit dem Containerstamm | nein | Löschen: true oder false Verschieben: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Nach der letzten Änderung filtern | Filtern Sie Dateien nach dem Zeitpunkt ihrer letzten Änderung. | nein | Zeitstempel | modifiedAfter modifiedBefore |
| Finden keiner Dateien zulässig | „true“ gibt an, dass kein Fehler ausgelöst wird, wenn keine Dateien gefunden werden. | nein | true oder false |
ignoreNoFilesFound |
| Maximale Spaltenanzahl | Der Standardwert ist 20480. Anpassen dieses Werts, wenn die Spaltennummer über 20480 liegt | nein | Integer | maxColumns |
Hinweis
Die Unterstützung von Datenflussquellen für die Liste der Dateien ist auf 1.024 Einträge in Ihrer Datei beschränkt. Um weitere Dateien einzufügen, verwenden Sie Platzhalter in Ihrer Dateiliste.
Quellbeispiel
Das folgende Bild ist ein Beispiel für eine DelimitedText-Quellkonfiguration bei Zuordnungsdatenflüssen.
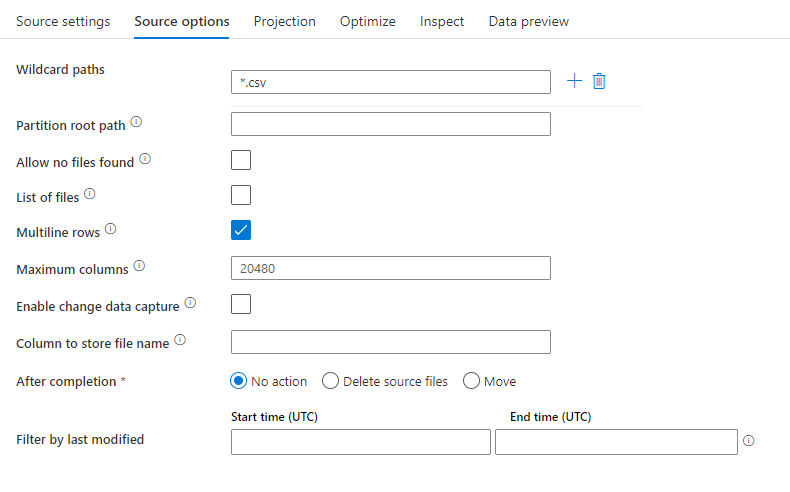
Das zugehörige Datenflussskript ist:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
Hinweis
Datenflussquellen unterstützen eine begrenzte Anzahl von Linux-Platzhaltern, die von Hadoop-Dateisystemen unterstützt werden.
Senkeneigenschaften
In der folgenden Tabelle sind die von einer DelimitedText-Senke unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Einstellungen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Ordner löschen | Wenn der Zielordner vor dem Schreiben gelöscht wird. | nein | true oder false |
truncate |
| Dateinamenoption | Das Namensformat der geschriebenen Daten. Standardmäßig eine Datei pro Partition im Format part-#####-tid-<guid>. |
Nein | Muster: Zeichenfolge Pro Partition: Zeichenfolge[] Dateiname aus Spaltendaten: String Ausgabe in eine einzelne Datei: ['<fileName>'] Ordnername aus Spaltendaten: String |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| Alle in Anführungszeichen | Gibt an, ob alle Werte in Anführungszeichen eingeschlossen werden. | nein | true oder false |
quoteAll |
| Header | Hinzufügen von Kundenheadern zu Ausgabedateien | Nein | [<string array>] |
header |
Senkenbeispiel
Das folgende Bild ist ein Beispiel für eine DelimitedText-Senkenkonfiguration bei Zuordnungsdatenflüssen.
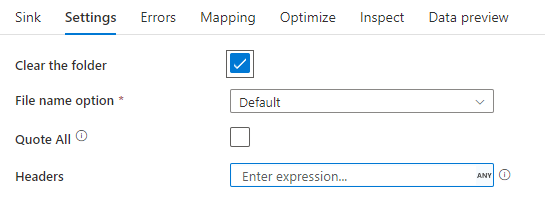
Das zugehörige Datenflussskript ist:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
Verwandte Connectors und Formate
Hier sind einige gängige Connectors und Formate im Zusammenhang mit dem Textformat mit Trennzeichen aufgeführt:
- Azure Blob Storage
- Binärformat
- Dataverse
- Delta-Format
- Excel-Format
- Dateisystem
- FTP
- HTTP
- JSON-Format
- Parquet-Format