Delta-Tabelle: Streaming für Lese- und Schreibvorgänge
Delta Lake ist stark in Spark Structured Streaming über readStream und writeStream integriert. Delta Lake überwindet viele der Einschränkungen, die in der Regel mit Streaming-Systemen und -Dateien verbunden sind, einschließlich:
- Zusammenführen kleiner Dateien, die durch die Erfassung mit geringer Wartezeit entstanden sind
- Beibehalten der „Genau einmal“-Verarbeitung mit mehr als einem Stream (oder gleichzeitigen Batchaufträgen)
- Effizientes Aufdecken, welche Dateien neu sind, wenn Dateien als Quelle für einen Stream verwendet werden
Hinweis
In diesem Artikel wird die Verwendung von Delta Lake-Tabellen als Quellen und Senken für das Streaming beschrieben. Informationen zum Laden von Daten mithilfe von Streamingtabellen in Databricks SQL finden Sie unter Laden von Daten mithilfe von Streamingtabellen in Databricks SQL.
Informationen zu Stream-statischen Verknüpfungen mit Delta Lake finden Sie unter Stream-statischen Verknüpfungen.
Delta-Tabelle als Quelle
Beim strukturierten Streaming werden Delta-Tabellen inkrementell gelesen. Während eine Streamingabfrage für eine Delta-Tabelle aktiv ist, werden neue Datensätze idempotent verarbeitet, wenn neue Tabellenversionen in die Quelltabelle committet werden.
Die folgenden Codebeispiele zeigen das Konfigurieren eines Streaminglesevorgangs mithilfe des Tabellennamens oder des Dateipfads.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Wichtig
Wenn sich das Schema für eine Delta-Tabelle ändert, nachdem ein Streaminglesevorgang für die Tabelle beginnt, dann schlägt die Abfrage fehl. Bei den meisten Schemaänderungen können Sie den Stream neu starten, um Schemakonflikte zu beheben und die Verarbeitung fortzusetzen.
In Databricks Runtime 12.2 LTS und früher können Sie nicht aus einer Delta-Tabelle mit aktivierter Spaltenzuordnung streamen, die eine nicht additive Schemaentwicklung durchlaufen hat, z. B. durch Umbenennen oder Löschen von Spalten. Ausführliche Informationen finden Sie unter Streaming mit Spaltenzuordnung und Schemaänderungen.
Einschränken der Eingaberate
Die folgenden Optionen stehen zur Steuerung von Microbatchs zur Verfügung:
maxFilesPerTrigger: Gibt an, wie viele neue Dateien in jedem Microbatch berücksichtigt werden sollen. Der Standardwert lautet 1000.maxBytesPerTrigger: Gibt an, wie viele Daten in jedem Microbatch verarbeitet werden. Diese Option legt einen „soft max“ fest, was bedeutet, dass ein Batch ungefähr diese Datenmenge verarbeitet und möglicherweise mehr als den Grenzwert verarbeitet, um die Streamingabfrage voranzubringen, wenn die kleinste Eingabeeinheit größer als dieser Grenzwert ist. Dies ist nicht standardmäßig festgelegt.
Wenn Sie maxBytesPerTrigger in Verbindung mit maxFilesPerTrigger verwenden, verarbeitet der Microbatch Daten, bis entweder der Grenzwert maxFilesPerTrigger oder maxBytesPerTrigger erreicht ist.
Hinweis
In Fällen, in denen die Quelltabellentransaktionen aufgrund der logRetentionDuration-Konfiguration bereinigt werden und die Streamingabfrage versucht, diese Versionen zu verarbeiten, kann die Abfrage standardmäßig keinen Datenverlust vermeiden. Sie können die Option failOnDataLoss auf false festlegen, um verlorene Daten zu ignorieren und die Verarbeitung fortzusetzen.
Streamen eines Delta Lake-CDC-Feeds (Change Data Capture)
Im Änderungsdatenfeed von Delta Lake werden Änderungen an einer Delta-Tabelle aufgezeichnet, einschließlich Updates und Löschvorgängen. Wenn der Feed aktiviert ist, können Sie aus einem Änderungsdatenfeed streamen und Logik schreiben, um Einfüge-, Aktualisierungs- und Löschvorgänge in Downstreamtabellen zu verarbeiten. Obwohl sich die Datenausgabe des Änderungsdatenfeeds geringfügig von der beschriebenen Delta-Tabelle unterscheidet, stellt dies eine Lösung für die Weitergabe inkrementeller Änderungen an Downstreamtabellen in einer Medaillon-Architektur dar.
Wichtig
In Databricks Runtime 12.2 LTS und früher können Sie nicht aus dem Änderungsdatenfeed für eine Delta-Tabelle mit aktivierter Spaltenzuordnung streamen, die eine nicht additive Schemaentwicklung durchlaufen hat, z. B. durch Umbenennen oder Löschen von Spalten. Weitere Informationen finden Sie unter Streaming mit Spaltenzuordnung und Schemaänderungen.
Ignorieren von Updates und Löschungen
Strukturiertes Streaming verarbeitet keine Eingabe, die keine Anfügung ist, und löst eine Ausnahme aus, wenn Änderungen an der Tabelle vorgenommen werden, die als Quelle verwendet wird. Es gibt zwei Hauptstrategien für den Umgang mit Änderungen, die nicht automatisch nachgeschaltet propagiert werden können:
- Sie können die Ausgabe und den Prüfpunkt löschen und den Stream von Anfang an neu starten.
- Sie können eine der beiden Optionen festlegen:
ignoreDeletes: Transaktionen ignorieren, die Daten an Partitionsgrenzen löschen.skipChangeCommits: Transaktionen ignorieren, die vorhandene Datensätze löschen oder ändern.skipChangeCommitssubsumiertignoreDeletes.
Hinweis
In Databricks Runtime 12.2 LTS und höher ersetzt skipChangeCommits die veraltete Einstellung ignoreChanges. In Databricks Runtime 11.3 LTS und früher ist ignoreChanges die einzige unterstützte Option.
Die Semantik für ignoreChanges unterscheidet sich sehr stark von skipChangeCommits. Wenn ignoreChanges aktiviert ist, werden neu geschriebene Datendateien in der Quelltabelle nach einem Datenänderungsvorgang wie UPDATE, MERGE INTO, DELETE (innerhalb von Partitionen) oder OVERWRITE erneut ausgegeben. Unveränderte Zeilen werden häufig zusammen mit neuen Zeilen ausgegeben, sodass Downstream-Consumer in der Lage sein müssen, mit Duplikaten umzugehen. Löschungen werden nicht nachgeschaltet propagiert. ignoreChanges subsumiert ignoreDeletes.
skipChangeCommits ignoriert Dateiänderungsvorgänge vollständig. Datendateien, die in der Quelltabelle aufgrund von Datenänderungsvorgängen wie UPDATE, MERGE INTO, DELETE und OVERWRITE neu geschrieben werden, werden vollständig ignoriert. Um Änderungen in Upstream-Quelltabellen widerzuspiegeln, müssen Sie eine separate Logik implementieren, um diese Änderungen weiterzuverbreiten.
Workloads, die mit ignoreChanges konfiguriert sind, werden weiterhin mit bekannter Semantik funktionieren, aber Databricks empfiehlt die Verwendung von skipChangeCommits für alle neuen Workloads. Das Migrieren von Workloads mittels ignoreChanges für skipChangeCommits erfordert Refactoringlogik.
Beispiel
Angenommen, Sie haben eine Tabelle user_events mit den Spalten date, user_email und action, die bis date partitioniert ist. Sie streamen aus der Tabelle user_events und müssen Daten aus dieser Tabelle aufgrund der DSGVO löschen.
Wenn Sie an Partitionsgrenzen löschen (d. h. WHERE befindet sich in einer Partitionsspalte), sind die Dateien bereits nach Wert segmentiert, sodass diese Dateien beim Löschen einfach aus den Metadaten gelöscht werden. Wenn Sie eine gesamte Datenpartition löschen, können Sie Folgendes verwenden:
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Wenn Sie Daten in mehreren Partitionen löschen (in diesem Beispiel filtern nach user_email), verwenden Sie die folgende Syntax:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Wenn Sie eine user_email mit der Anweisung UPDATE aktualisieren, wird die Datei mit der entsprechenden user_email umgeschrieben. Verwenden Sie skipChangeCommits, um die geänderten Datendateien zu ignorieren.
Angeben der Anfangsposition
Sie können die folgenden Optionen verwenden, um den Ausgangspunkt der Delta Lake-Streamingquelle anzugeben, ohne die gesamte Tabelle zu verarbeiten.
startingVersion: Die Delta Lake-Version, ab der gestartet werden soll. Databricks empfiehlt, diese Option für die meisten Workloads wegzulassen. Wird die Option nicht festgelegt, beginnt der Stream mit der neuesten verfügbaren Version, einschließlich einer vollständigen Momentaufnahme der Tabelle zu diesem Zeitpunkt.Wird die Option angegeben, liest der Stream ab der angegebenen Version (einschließlich) alle Änderungen an der Delta-Tabelle. Wenn die angegebene Version nicht mehr verfügbar ist, kann der Stream nicht gestartet werden. Sie können die Commit-Versionen aus der Spalte
versiondes Befehlsverlaufs der DESCRIBE HISTORY abrufen.Um nur die neuesten Änderungen zurückzugeben, geben Sie
latestan.startingTimestamp: Der Zeitstempel, ab dem gestartet werden soll. Alle Tabellenänderungen, die zum oder nach dem Zeitstempel (einschließlich) vorgenommen wurden, werden vom Streamingleser gelesen. Wenn der angegebene Zeitstempel allen Tabellencommits vorangestellt ist, beginnt der Streaminglesevorgang mit dem frühesten verfügbaren Zeitstempel. Eine der folgenden Optionen:- Eine Zeitstempelzeichenfolge. Beispiel:
"2019-01-01T00:00:00.000Z". - Eine Datumszeichenfolge. Beispiel:
"2019-01-01".
- Eine Zeitstempelzeichenfolge. Beispiel:
Sie können nicht beide Optionen gleichzeitig festlegen. Sie werden nur wirksam, wenn eine neue Streamingabfrage gestartet wird. Wenn eine Streamingabfrage gestartet wurde und der Fortschritt im Prüfpunkt aufgezeichnet wurde, werden diese Optionen ignoriert.
Wichtig
Obwohl Sie die Streamingquelle von einer angegebenen Version oder einem angegebenen Zeitstempel starten können, ist das Schema der Streamingquelle immer das neueste Schema der Delta-Tabelle. Sie müssen sicherstellen, dass es nach der angegebenen Version oder dem angegebenen Zeitstempel keine inkompatible Schemaänderung an der Delta-Tabelle gibt. Andernfalls gibt die Streamingquelle möglicherweise falsche Ergebnisse zurück, wenn die Daten mit einem falschen Schema gelesen werden.
Beispiel
Beispiel: Sie haben eine Tabelle user_events. Wenn Sie Änderungen ab Version 5 lesen möchten, verwenden Sie:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Wenn Sie Änderungen ab Version 2018-10-18 lesen möchten, verwenden Sie:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Verarbeiten der Anfangsmomentaufnahme, ohne dass Daten gelöscht werden
Hinweis
Dieses Feature ist in Databricks Runtime 11.3 LTS und höher verfügbar. Dieses Feature befindet sich in der Public Preview.
Wenn eine Deltatabelle als Streamquelle verwendet wird, verarbeitet die Abfrage zunächst alle in der Tabelle vorhandenen Daten. Die Delta-Tabelle in dieser Version wird als Anfangsmomentaufnahme bezeichnet. Standardmäßig werden die Datendateien der Delta-Tabelle danach verarbeitet, welche Datei zuletzt geändert wurde. Der Zeitpunkt der letzten Änderung entspricht jedoch nicht unbedingt der zeitlichen Reihenfolge der Aufzeichnungsereignisse.
In einer zustandsbehafteten Streamingabfrage mit einem definierten Grenzwert kann die Verarbeitung von Dateien nach Änderungszeit dazu führen, dass Datensätze in der falschen Reihenfolge verarbeitet werden. Dies könnte dazu führen, dass Aufzeichnungen als verspätete Ereignisse durch den Grenzwert gelöscht werden.
Sie können das Datenverlustproblem vermeiden, indem Sie die folgende Option aktivieren:
- withEventTimeOrder: Legt fest, ob die Anfangsmomentaufnahme mit Ereigniszeitreihenfolge verarbeitet werden soll.
Wenn die Ereigniszeitreihenfolge aktiviert ist, wird der Ereigniszeitbereich der Anfangsmomentaufnahme in Zeitbuckets unterteilt. Jeder Mikrobatch verarbeitet einen Bereich, indem er die Daten innerhalb des Zeitbereichs filtert. Die Konfigurationsoptionen „maxFilesPerTrigger“ und „maxBytesPerTrigger“ können weiterhin zur Steuerung der Mikrobatchgröße verwendet werden, jedoch aufgrund der Art der Verarbeitung nur annähernd.
Die folgende Grafik zeigt diesen Prozess:
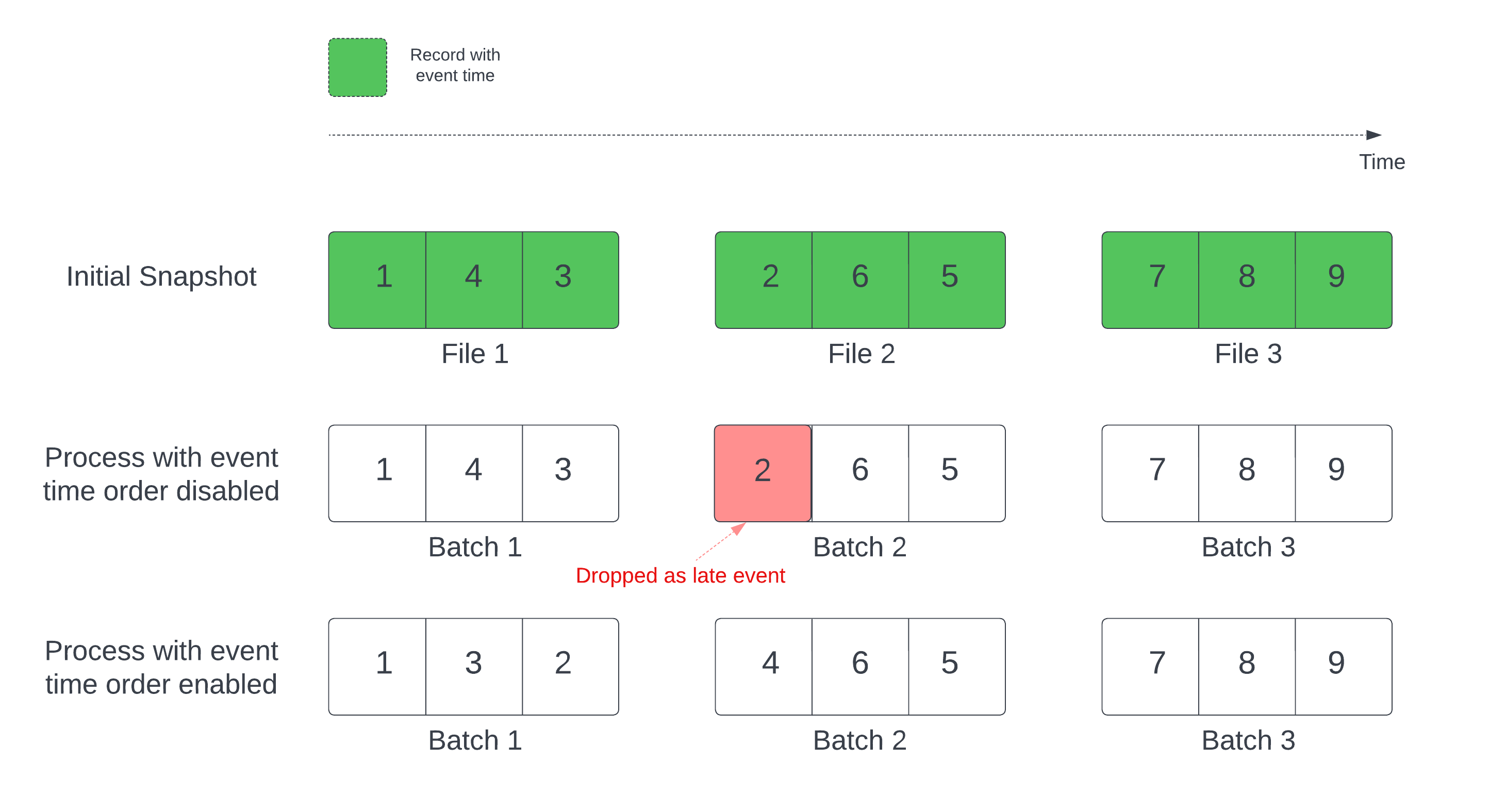
Wichtige Informationen zu diesem Feature:
- Das Datenverlustproblem tritt nur auf, wenn die Delta-Anfangsmomentaufnahme einer zustandsbehafteten Streamingabfrage in der Standardreihenfolge verarbeitet wird.
- Sie können
withEventTimeOrdernicht mehr ändern, sobald die Streamabfrage gestartet wurde, während die Anfangsmomentaufnahme noch verarbeitet wird. Um mit geänderterwithEventTimeOrder-Einstellung neu zu starten, müssen Sie den Prüfpunkt löschen. - Wenn Sie eine Streamabfrage mit aktivierter withEventTimeOrder-Option ausführen, können Sie erst auf eine DBR-Version herabstufen, die diese Funktion nicht unterstützt, wenn die Verarbeitung der Anfangsmomentaufnahme abgeschlossen ist. Wenn Sie ein Downgrade durchführen müssen, können Sie warten, bis die Anfangsmomentaufnahme abgeschlossen ist, oder Sie löschen den Prüfpunkt und starten die Abfrage neu.
- Dieses Feature wird in den folgenden ungewöhnlichen Szenarien nicht unterstützt:
- Die Ereigniszeitspalte ist eine generierte Spalte und es gibt nicht projektive Transformationen zwischen der Delta-Quelle und dem Grenzwert.
- Es gibt einen Grenzwert, der mehr als eine Delta-Quelle in der Streamabfrage hat.
- Bei aktivierter Ereigniszeitreihenfolge kann die Leistung der Delta-Anfangsmomentaufnahme langsamer sein.
- Jeder Mikrobatch überprüft die Anfangsmomentaufnahme, um Daten innerhalb des entsprechenden Ereigniszeitbereichs zu filtern. Für eine schnellere Filterung ist es ratsam, eine Delta-Quellenspalte als Ereigniszeit zu verwenden, so dass Daten übersprungen werden können (Informationen zur Anwendbarkeit finden Sie unter Überspringen von Daten für Delta Lake). Darüber hinaus kann die Tabellenpartitionierung entlang der Ereigniszeitspalte die Verarbeitung weiter beschleunigen. Sie können auf der Spark-Benutzeroberfläche nachsehen, wie viele Delta-Dateien für einen bestimmten Mikrobatch gescannt werden.
Beispiel
Angenommen, Sie haben Tabelle user_events mit der Spalte event_time. Ihre Streamingabfrage ist eine Aggregationsabfrage. Wenn Sie sicherstellen möchten, dass während der Verarbeitung der Anfangsmomentaufnahme keine Daten verloren gehen, können Sie Folgendes verwenden:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Hinweis
Sie können dies auch mit der Spark-Konfiguration auf dem Cluster aktivieren, was dann für alle Streamingabfragen gilt: spark.databricks.delta.withEventTimeOrder.enabled true
Delta-Tabelle als eine Senke
Daten können auch mithilfe von strukturiertem Streaming in eine Delta-Tabelle geschrieben werden. Durch das Delta Lake-Transaktionsprotokoll wird eine Exactly Once-Verarbeitung garantiert, auch wenn parallel andere Datenströme oder Batchabfragen für die Tabelle ausgeführt werden.
Hinweis
Die Delta Lake-Funktion VACUUM entfernt alle Dateien, die nicht von Delta Lake verwaltet werden. Es werden aber alle Verzeichnisse übersprungen, die mit _ beginnen. Sie können Prüfpunkte mit anderen Daten und Metadaten für eine Delta-Tabelle mit einer Verzeichnisstruktur wie z. B. <table-name>/_checkpoints sicher speichern.
metrics
Sie können die Anzahl von Bytes und die Anzahl der Dateien, die noch verarbeitet werden müssen, in einem Streamingabfrageprozess als Metriken numBytesOutstanding und numFilesOutstanding herausfinden. Weitere Metriken umfassen:
numNewListedFiles: Anzahl der Delta Lake-Dateien, die zum Berechnen des Backlogs für diesen Batch aufgelistet wurden.backlogEndOffset: Die Tabellenversion, die zum Berechnen des Backlogs verwendet wird.
Wenn Sie den Stream in einem Notebook ausführen, können Sie diese Metriken auf der Registerkarte Rohdaten im Dashboard für den Fortschritt der Streamingabfrage sehen:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
Anfügemodus
Datenströme werden standardmäßig im Anfügemodus ausgeführt, wodurch der Tabelle neue Datensätze hinzugefügt werden.
Verwenden Sie die toTable Methode beim Streamen in Tabellen, wie im folgenden Beispiel gezeigt:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Vollständiger Modus
Sie können strukturiertes Streaming auch verwenden, um die gesamte Tabelle durch jeden Batch zu ersetzen. Ein Beispiel hierfür ist das Berechnen einer Zusammenfassung mit Aggregation:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
Im vorherigen Beispiel wird kontinuierlich eine Tabelle aktualisiert, die die aggregierte Anzahl von Ereignissen nach Kunden enthält.
Für Anwendungen mit geringeren Latenzanforderungen können Sie Computingressourcen mit einmaligen Auslösern sparen. Verwenden Sie diese, um zusammenfassende Aggregationstabellen nach einem bestimmten Zeitplan zu aktualisieren und nur neue Daten zu verarbeiten, die seit dem letzten Update eingetroffen sind.
Ausführen eines Upsert aus Streamingabfragen mithilfe von foreachBatch
Sie können mithilfe einer Kombination aus merge und foreachBatch komplexe Upserts aus einer Streamingabfrage in eine Delta-Tabelle schreiben. Siehe Verwenden von foreachBatch zum Schreiben in beliebige Datensenken.
Dieses Muster hat viele Anwendungsmöglichkeiten, u. a.:
- Schreiben von Streamingaggregaten im Updatemodus: Dies ist wesentlich effizienter als „Vollständiger Modus“.
- Schreiben eines Datenstroms von Datenbankänderungen in eine Delta-Tabelle: Die Mergeabfrage zum Schreiben von Änderungsdaten kann in
foreachBatchverwendet werden, um einen Datenstrom von Änderungen kontinuierlich auf eine Delta-Tabelle anzuwenden. - Schreiben eines Datenstroms in eine Delta-Tabelle mit Deduplizierung: Die „insert-only“-Mergeabfrage für die Deduplizierung kann in
foreachBatchverwendet werden, um Daten (mit Duplikaten) kontinuierlich in eine Delta-Tabelle mit automatischer Deduplizierung zu schreiben.
Hinweis
- Stellen Sie sicher, dass Ihre
merge-Anweisung inforeachBatchidempotent ist, da Neustarts der Streamingabfrage den Vorgang mehrmals auf denselben Datenbatch anwenden können. - Wenn
mergeinforeachBatchverwendet wird, wird die Eingabedatenrate der Streamingabfrage (überStreamingQueryProgressgemeldet und im Notebook-Ratendiagramm sichtbar) möglicherweise als ein Vielfaches der tatsächlichen Rate gemeldet, mit der Daten an der Quelle generiert werden. Dies liegt daran, weilmergedie Eingabedaten mehrmals liest, wodurch die Eingabemetriken vervielfacht werden. Wenn dies ein Engpass ist, können Sie den Datenrahmen-Batch vormergezwischenspeichern und nachmergeaus dem Zwischenspeicher wieder entfernen.
Im folgenden Beispiel wird veranschaulicht, wie Sie SQL in foreachBatch verwenden können, um diese Aufgabe auszuführen:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Sie können auch die Delta Lake-APIs verwenden, um Streamingupserts durchzuführen, wie im folgenden Beispiel gezeigt:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Idempotente Tabellenschreibvorgänge in foreachBatch
Hinweis
Databricks empfiehlt, für jede Senke, die Sie aktualisieren möchten, einen separaten Streamingschreibvorgang zu konfigurieren. Wenn Sie foreachBatch zum Schreiben in mehrere Tabellen verwenden, werden Schreibvorgänge serialisiert, was die Parallelität reduziert und die Gesamtwartezeit erhöht.
Delta-Tabellen unterstützen die folgenden DataFrameWriter Optionen, um Schreibvorgänge in mehrere Tabellen in foreachBatch idempotent zu erstellen:
txnAppId: Eine eindeutige Zeichenfolge, die Sie bei DataFrame-Schreibvorgang übergeben können. Beispielsweise können Sie die StreamingQuery ID alstxnAppIdverwenden.txnVersion: Eine monoton steigende Zahl, die als Transaktionsversion fungiert.
Delta Lake verwendet die Kombination aus txnAppId und txnVersion, um doppelte Schreibvorgänge zu identifizieren und zu ignorieren.
Wenn ein Batchschreibvorgang mit einem Fehler unterbrochen wird, wird beim erneuten Ausführen des Batches die gleiche Anwendungs- und Batch ID verwendet, wodurch die Laufzeit doppelte Schreibvorgänge ordnungsgemäß identifizieren und ignorieren kann. Application ID (txnAppId) kann eine beliebige vom Benutzer generierte einzigartige Zeichenfolge sein und muss nicht mit der Stream ID verknüpft sein. Siehe Verwenden von foreachBatch zum Schreiben in beliebige Datensenken.
Warnung
Wenn Sie den Streamingprüfpunkt löschen und die Abfrage mit einem neuen Prüfpunkt neu starten, müssen Sie einen anderen txnAppId-Wert angeben. Neue Prüfpunkte beginnen mit der Batch-ID 0. Delta Lake verwendet die Batch-ID und txnAppId als eindeutigen Schlüssel und überspringt Batches mit bereits verwendeten Werten.
Im folgenden Codebeispiel wird dieses Muster veranschaulicht:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}