Tutorial: Erstellen bedarfsgesteuerter Apache Hadoop-Cluster in HDInsight mit Azure Data Factory
In diesem Tutorial erfahren Sie, wie Sie mit Azure Data Factory bedarfsgesteuert einen Apache Hadoop-Cluster in Azure HDInsight erstellen. Sie können dann Datenpipelines in Azure Data Factory verwenden, um Hive-Aufträge ausführen und den Cluster zu löschen. In diesem Tutorial erfahren Sie, wie Sie einen operationalize-Vorgang für die Ausführung eines Big Data-Auftrags ausführen, bei dem die Clustererstellung, Auftragsausführung und Clusterlöschung nach einem Zeitplan erfolgen.
Dieses Tutorial enthält die folgenden Aufgaben:
- Erstellen eines Azure-Speicherkontos
- Verstehen von Azure Data Factory-Aktivitäten
- Erstellen einer Data Factory über das Azure-Portal
- Erstellen von verknüpften Diensten
- Erstellen einer Pipeline
- Auslösen einer Pipeline
- Überwachen einer Pipeline
- Überprüfen der Ausgabe
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Das PowerShell-Az-Modul ist installiert.
Ein Microsoft Entra-Dienstprinzipal. Nachdem Sie den Dienstprinzipal erstellt haben, müssen Sie noch die Anwendungs-ID und den Authentifizierungsschlüssel mithilfe der Anweisungen im verknüpften Artikel abrufen. Sie benötigen sie später in diesem Tutorial. Dieser Dienstprinzipal muss außerdem Mitglied der Rolle Mitwirkender in dem Abonnement oder der Ressourcengruppe sein, in dem bzw. der der Cluster erstellt wird. Anweisungen zum Abrufen der erforderlichen Werte und zum Zuweisen der richtigen Rollen finden Sie unter Erstellen eines Microsoft Entra-Dienstprinzipals.
Erstellen von vorläufigen Azure-Objekten
In diesem Abschnitt erstellen Sie verschiedene Objekte, die für den bei Bedarf erstellten HDInsight-Cluster verwendet werden. Das erstellte Speicherkonto enthält das HiveQL-Beispielskript partitionweblogs.hql, mit dem Sie einen Apache Hive-Beispielauftrag simulieren, der im Cluster ausgeführt wird.
In diesem Abschnitt wird ein Azure PowerShell-Skript verwendet, um das Speicherkonto zu erstellen und die erforderlichen Dateien im Speicherkonto zu kopieren. Das Azure PowerShell-Beispielskript in diesem Abschnitt führt die folgenden Aufgaben aus:
- Meldet sich bei Azure an.
- Erstellt eine Azure-Ressourcengruppe.
- Erstellt ein Azure Storage-Konto.
- Erstellt einen Blobcontainer im Speicherkonto
- Kopiert das HiveQL-Beispielskript (partitionweblogs.hql) in den Blobcontainer. Das Beispielskript ist bereits in einem anderen öffentlichen Blobcontainer verfügbar. Das folgende PowerShell-Skript erstellt eine Kopie dieser Dateien in dem selbst erstellten Azure Storage-Konto.
Erstellen eines Speicherkontos und Kopieren von Dateien
Wichtig
Geben Sie Namen für die Azure-Ressourcengruppe und das Azure-Speicherkonto an, die anhand des Skripts erstellt werden sollen. Notieren Sie den Namen der Ressourcengruppe, den Namen des Speicherkontos und den Speicherkontoschlüssel, die vom Skript ausgegeben werden. Sie benötigen diese Angaben im nächsten Abschnitt.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Überprüfen des Speicherkontos
- Melden Sie sich beim Azure-Portalan.
- Navigieren Sie links zu Alle Dienste>Allgemein>Ressourcengruppen.
- Wählen Sie den Namen der Ressourcengruppe, die Sie im PowerShell-Skript erstellt haben, aus. Verwenden Sie den Filter, wenn zu viele Ressourcengruppen aufgeführt werden.
- In der Ansicht Übersicht sollte eine Ressource aufgeführt sein, sofern Sie die Ressourcengruppe nicht für andere Projekte freigegeben haben. Diese Ressource ist das Speicherkonto mit dem Namen, den Sie zuvor angegeben haben. Wählen Sie den Speicherkontonamen aus.
- Wählen Sie die Kachel Container aus.
- Wählen Sie den Container adfgetstarted aus. Der Ordner
hivescriptswird angezeigt. - Öffnen Sie den Ordner, und überprüfen Sie, ob er die Beispielskriptdatei partitionweblogs.hql enthält.
Verstehen der Azure Data Factory-Aktivität
Azure Data Factory orchestriert und automatisiert das Verschieben und Transformieren von Daten. Azure Data Factory kann einen HDInsight Hadoop-Cluster Just-In-Time erstellen, um einen eingehenden Datenslice zu verarbeiten, und den Cluster löschen, wenn die Verarbeitung abgeschlossen ist.
In Azure Data Factory kann eine Data Factory über mindestens eine Datenpipeline verfügen. Eine Datenpipeline verfügt über mindestens eine Aktivität. Es gibt zwei Arten von Aktivitäten:
- Datenverschiebungsaktivitäten: Sie verwenden Datenverschiebungen zum Verschieben von Daten aus einem Quelldatenspeicher in einen Zieldatenspeicher.
- Datentransformationsaktivitäten. Sie können Datentransformationsaktivitäten verwenden, um Daten zu übertragen und zu verarbeiten. Die HDInsight-Hive-Aktivität ist eine der Transformationsaktivitäten, die von Data Factory unterstützt werden. In diesem Tutorial verwenden Sie die Hive-Transformation.
In diesem Artikel konfigurieren Sie die Hive-Aktivität, um einen HDInsight Hadoop-Cluster bedarfsgesteuert zu erstellen. Folgendes geschieht während der Ausführung der Aktivität zur Verarbeitung von Daten:
Ein HDInsight Hadoop-Cluster wird automatisch Just-In-Time zur Verarbeitung des Slice für Sie erstellt.
Die Eingabedaten werden durch Ausführen des folgenden HiveQL-Skripts im Cluster verarbeitet. In diesem Tutorial führt das HiveQL-Skript, das der Hive-Aktivität zugeordnet ist, die folgenden Aktionen aus:
- Es verwendet die vorhandene Tabelle (hivesampletable) zum Erstellen einer weiteren Tabelle (HiveSampleOut).
- Es füllt die Tabelle HiveSampleOut mit bestimmten Spalten aus der ursprünglichen Tabelle hivesampletable auf.
Der HDInsight Hadoop-Cluster wird gelöscht, sobald die Verarbeitung abgeschlossen ist, und der Cluster befindet sich während der konfigurierten Zeitspanne im Leerlauf (TimeToLive-Einstellung). Wenn der nächste Datenslice zur Verarbeitung innerhalb dieser TimeToLive-Leerlaufzeit verfügbar ist, wird der gleiche Cluster wie für die Verarbeitung des Slice verwendet.
Erstellen einer Data Factory
Melden Sie sich beim Azure-Portal an.
Navigieren Sie im Menü auf der linken Seite zu
+ Create a resource>Analytics>Data Factory.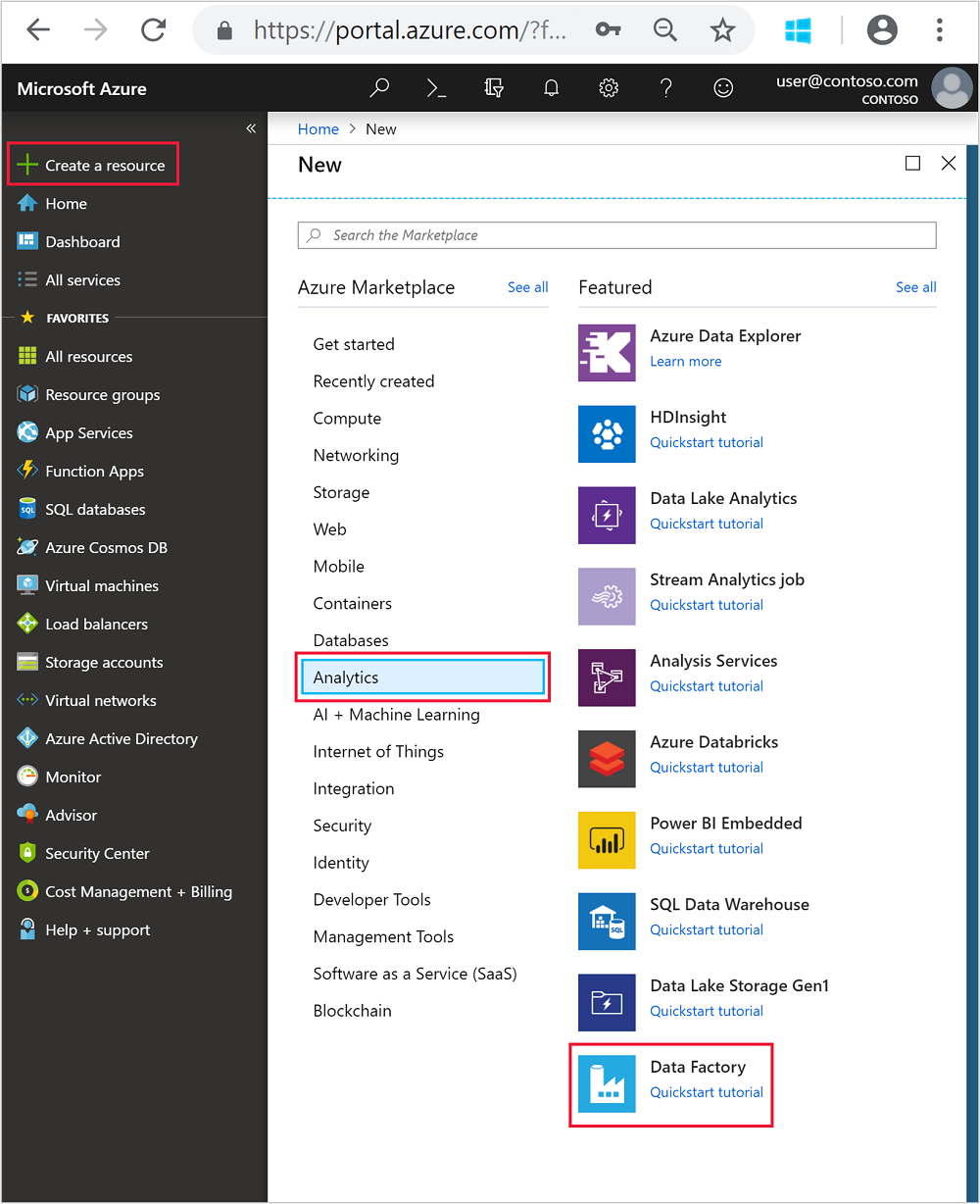
Geben Sie die folgenden Werte für die Kachel Neue Data Factory ein oder wählen Sie sie aus:
Eigenschaft Wert Name Geben Sie einen Namen für die Data Factory ein. Dieser Name muss global eindeutig sein. Version V2 beibehalten. Subscription Wählen Sie Ihr Azure-Abonnement. Resource group Wählen Sie die Ressourcengruppe aus, die Sie mit dem PowerShell-Skript erstellt haben. Standort Der Standort wird automatisch auf die Region festgelegt, die Sie beim Erstellen der Ressourcengruppe zuvor angegeben haben. Für dieses Tutorial wird der Standort auf USA, Osten festgelegt. Git aktivieren Deaktivieren Sie dieses Kontrollkästchen. 
Klicken Sie auf Erstellen. Das Erstellen einer Data Factory kann zwischen 2 und 4 Minuten dauern.
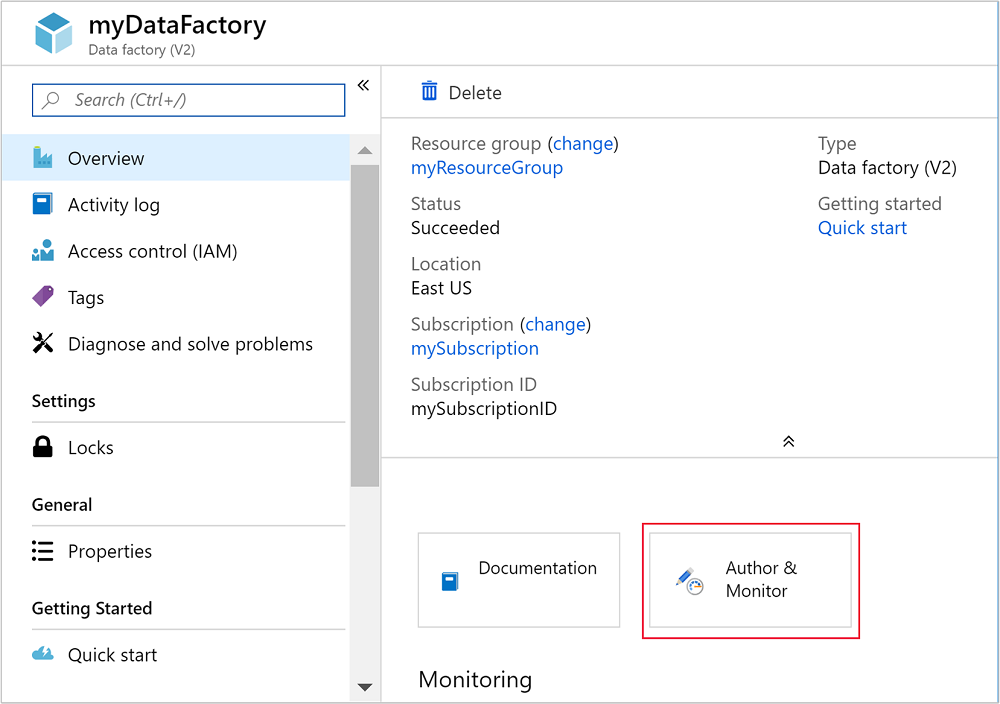
Nachdem die Data Factory erstellt wurde, erhalten Sie die Benachrichtigung Bereitstellung erfolgreich mit einer Schaltfläche Zu Ressource wechseln. Klicken Sie auf Zu Ressource wechseln, um die Data Factory-Standardansicht zu öffnen.
Wählen Sie Erstellen und überwachen aus, um das Azure Data Factory-Portal für das Erstellen und Überwachen zu starten.
Erstellen von verknüpften Diensten
In diesem Abschnitt erstellen Sie zwei verknüpfte Dienste in Ihrer Data Factory.
- Einen verknüpften Azure Storage-Dienst, der ein Azure-Speicherkonto mit der Data Factory verknüpft. Dieser Speicher wird vom bedarfsgesteuerten HDInsight-Cluster verwendet. Außerdem enthält er das Hive-Skript, das im Cluster ausgeführt wird.
- Einen bedarfsgesteuerten verknüpften HDInsight-Dienst. Azure Data Factory erstellt automatisch einen HDInsight-Cluster und führt das Hive-Skript aus. Anschließend wird der HDInsight-Cluster gelöscht, nachdem er sich für einen vorkonfigurierten Zeitraum im Leerlauf befunden hat.
Erstellen eines verknüpften Azure Storage-Diensts
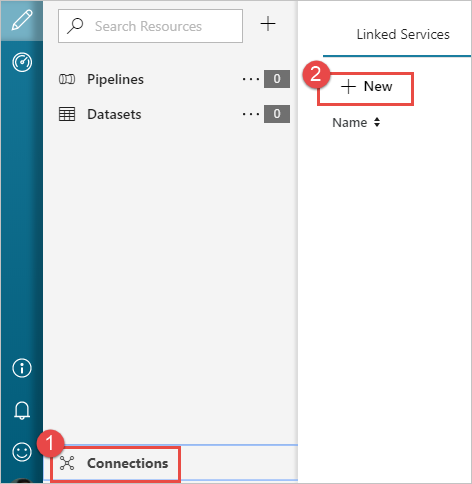
Wählen Sie im linken Bereich auf der Seite Erste Schritte das Symbol Autor aus.

Wählen Sie links unten im Fenster die Option Verbindungen und dann + Neu aus.
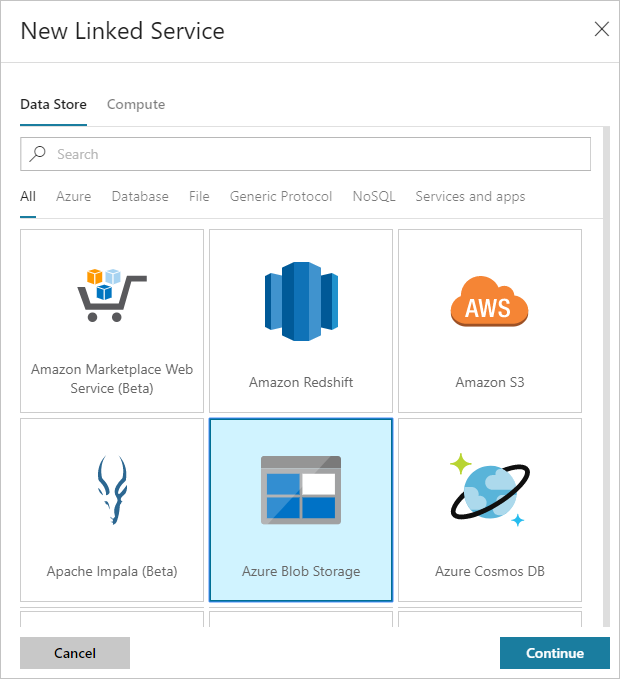
Wählen Sie im Dialogfeld Neuer verknüpfter Dienst die Option Azure Blob Storage und dann Weiter aus.
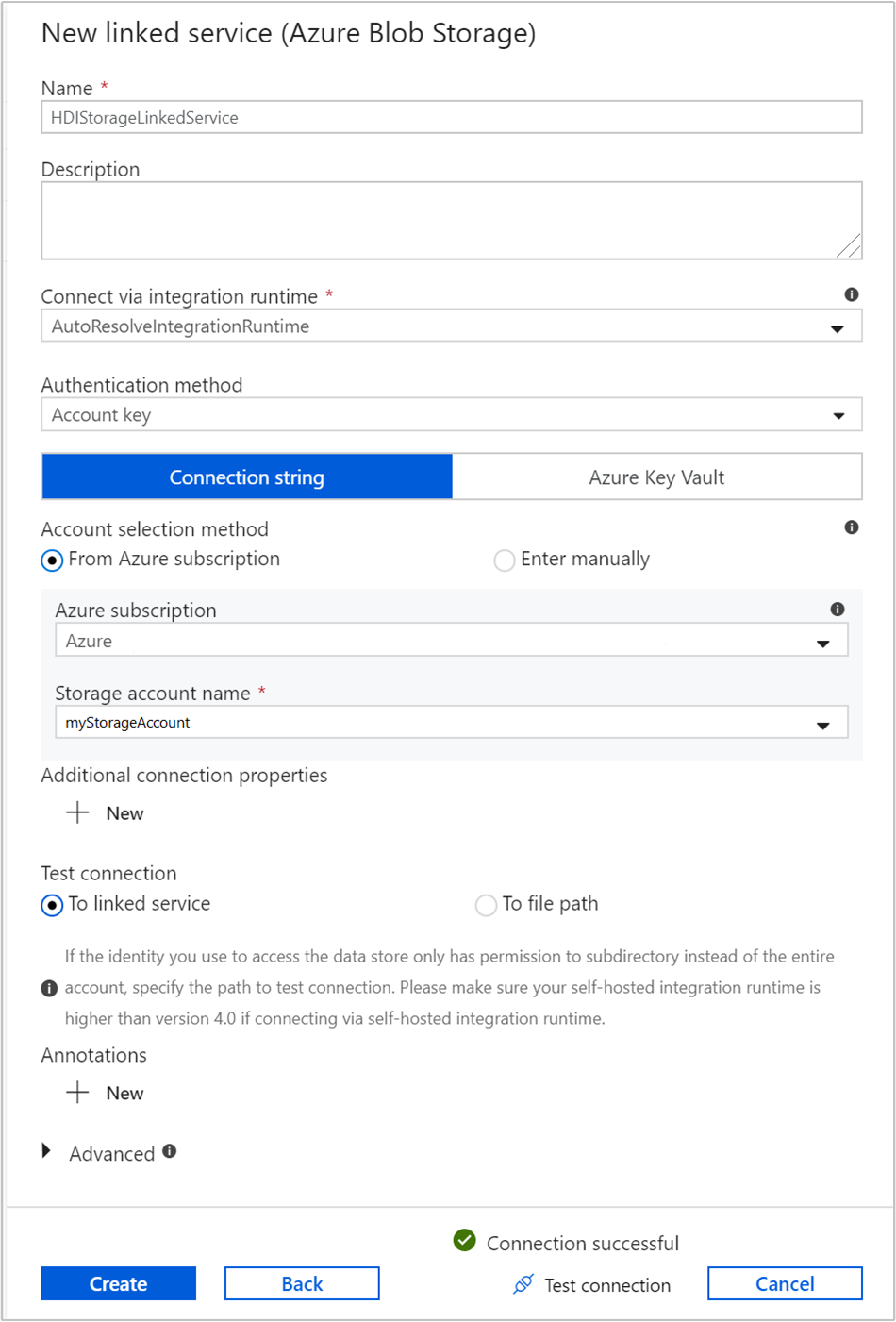
Stellen Sie die folgenden Werte für den mit Speicher verknüpften Dienst bereit:
Eigenschaft Wert Name Geben Sie HDIStorageLinkedServiceein.Azure-Abonnement Wählen Sie in der Dropdownliste Ihr Abonnement aus. Speicherkontoname Wählen Sie das Azure Storage-Konto aus, das Sie als Teil des PowerShell-Skripts erstellt haben. Wählen Sie Verbindung testen aus. War der Test erfolgreich, wählen Sie Erstellen aus.
Erstellen eines bedarfsgesteuerten verknüpften HDInsight-Diensts
Wählen Sie erneut die Schaltfläche + Neu, um einen weiteren verknüpften Dienst zu erstellen.
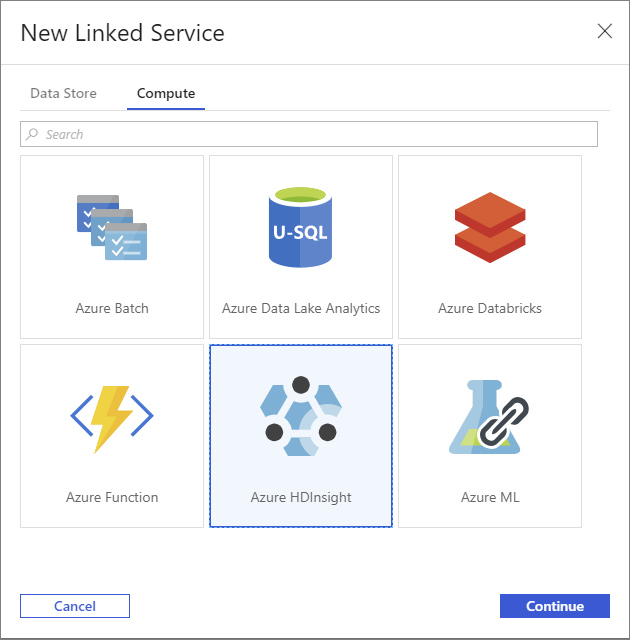
Wählen Sie im Fenster Neuer verknüpfter Dienst die Registerkarte Compute aus.
Wählen Sie Azure HDInsight und dann Weiter aus.
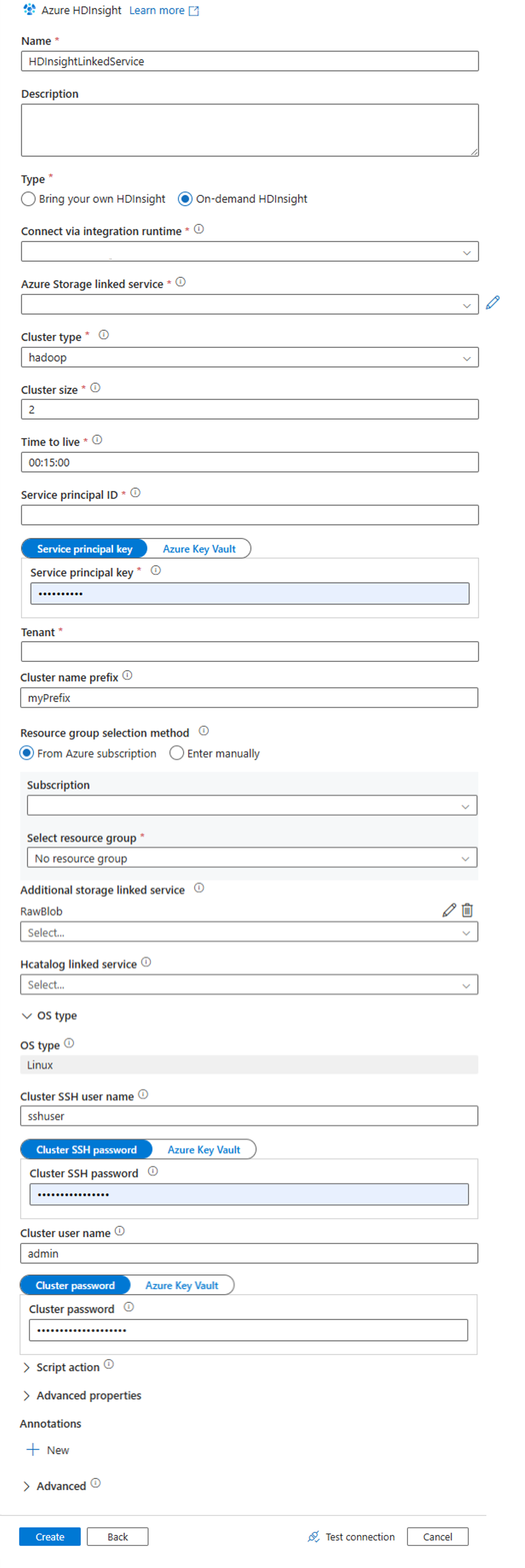
Geben Sie im Fenster Neuer verknüpfter Dienst die folgenden Werte ein, und belassen Sie für die restlichen Optionen die Standardwerte:
Eigenschaft Wert Name Geben Sie HDInsightLinkedServiceein.type Wählen Sie HDInsight bedarfsgesteuert aus. Mit Azure-Speicher verknüpfter Dienst Wählen Sie HDIStorageLinkedServiceaus.Clustertyp Wählen Sie hadoop aus. Gültigkeitsdauer Geben Sie an, wie lange der HDInsight-Cluster verfügbar sein soll, bevor er automatisch gelöscht wird. Dienstprinzipal-ID Geben Sie die Anwendungs-ID des Microsoft Entra-Dienstprinzipals an, den Sie zur Vorbereitung erstellt haben. Dienstprinzipalschlüssel Geben Sie den Authentifizierungsschlüssel für den Microsoft Entra-Dienstprinzipal an. Clusternamenspräfix Geben Sie einen Wert an, der allen von der Data Factory erstellten Clustertypen vorangestellt wird. Subscription Wählen Sie in der Dropdownliste Ihr Abonnement aus. Auswählen der Ressourcengruppe Wählen Sie die Ressourcengruppe, die Sie zuvor mit dem PowerShell-Skript erstellt haben, aus. Betriebssystemtyp/SSH-Benutzername für den Cluster Geben Sie einen SSH-Benutzernamen ein, üblicherweise sshuser.Betriebssystemtyp/SSH-Kennwort für den Cluster Geben Sie ein Kennwort für den SSH-Benutzer an. Betriebssystemtyp/Benutzername für den Cluster Geben Sie einen Clusterbenutzernamen ein, üblicherweise admin.Betriebssystemtyp/Clusterkennwort Stellen Sie ein Kennwort für den Clusterbenutzer bereit. Klicken Sie anschließend auf Erstellen.
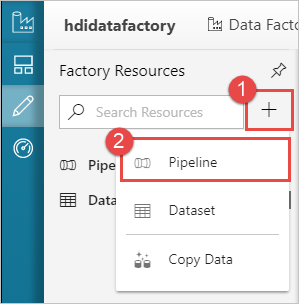
Erstellen einer Pipeline
Klicken Sie auf die Schaltfläche + (Plus) und dann auf Pipeline.
Erweitern Sie in der Toolbox Aktivitäten die Option HDInsight, und ziehen Sie die Aktivität Hive auf die Oberfläche des Pipeline-Designers. Geben Sie auf der Registerkarte Allgemein einen Namen für die Aktivität an.
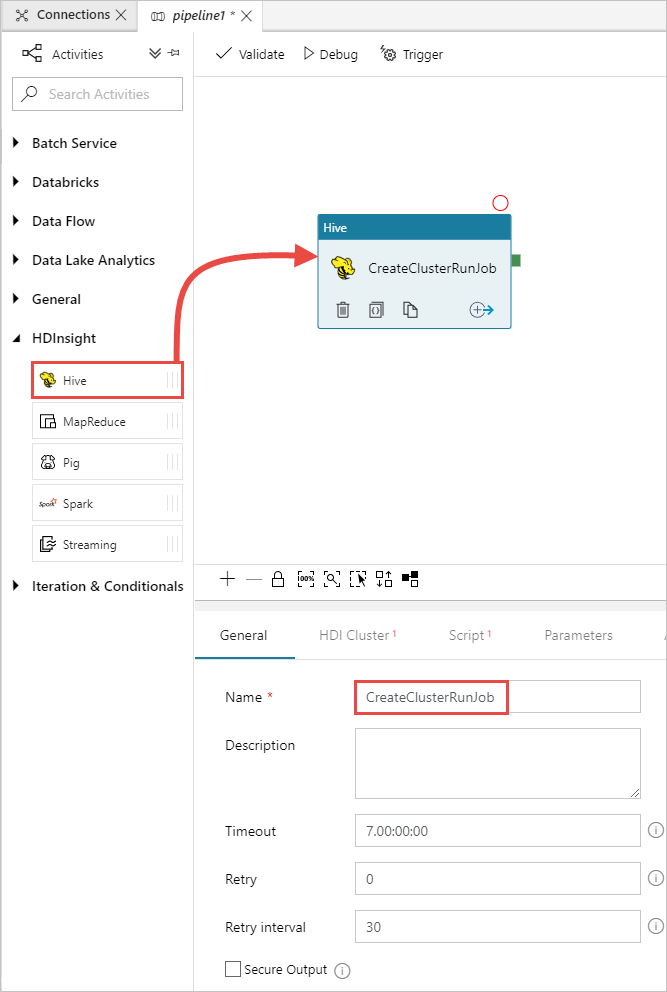
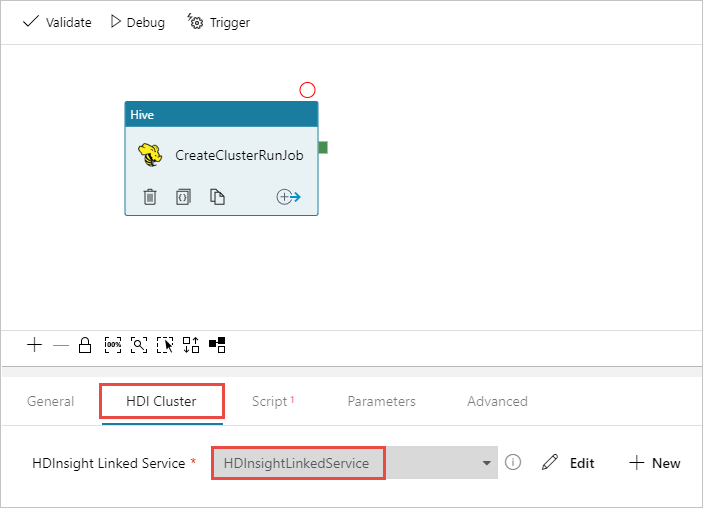
Stellen Sie sicher, dass die Hive-Aktivität ausgewählt ist, und wählen Sie die Registerkarte HDI-Cluster aus. Wählen Sie in der Dropdownliste Verknüpfter HDInsight-Dienst den verknüpften Dienst HDInsightLinkedService aus, den Sie zuvor für HDInsight erstellt haben.
Wählen Sie die Registerkarte Skript aus, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Mit dem Skript verknüpfter Dienst die Option HDIStorageLinkedService aus der Dropdownliste aus. Dieser Wert ist der zuvor erstellte mit Storage verknüpfte Dienst.
Wählen Sie für Dateipfad die Option Storage durchsuchen aus, und navigieren Sie zum Speicherort des Hive-Beispielskripts. Wenn Sie zuvor das PowerShell-Skript ausgeführt haben, sollte dieser Speicherort
adfgetstarted/hivescripts/partitionweblogs.hqllauten.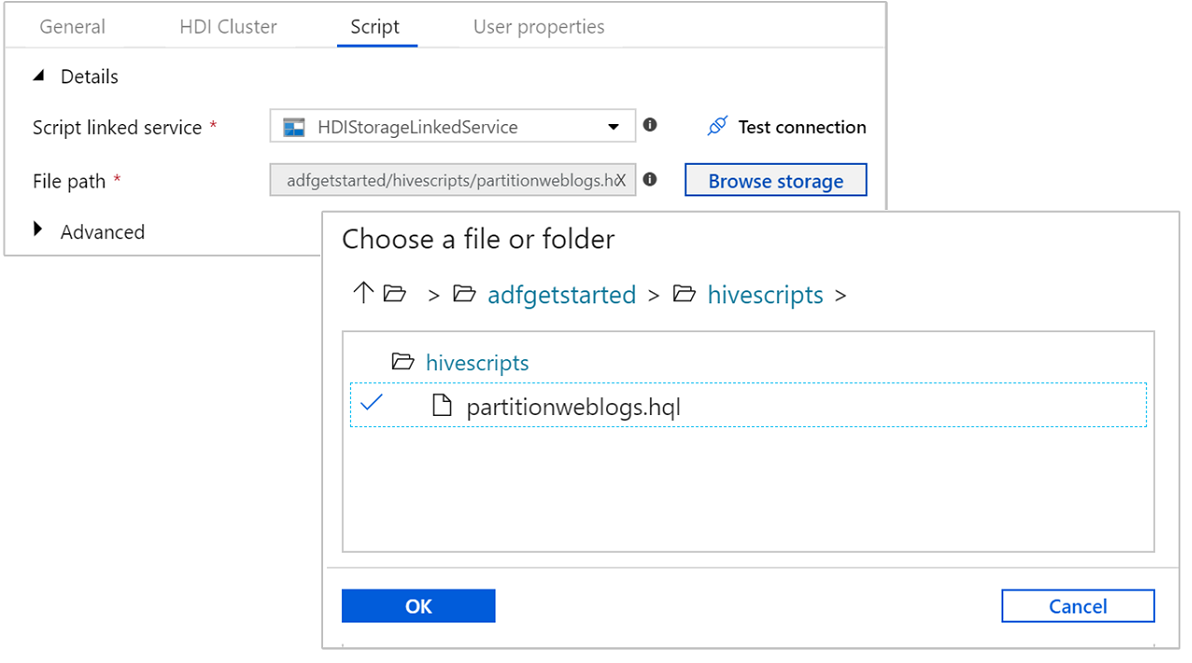
Wählen Sie unter Erweitert>Parameter die Option
Auto-fill from scriptaus. Diese Option sucht alle Parameter im Hive-Skript, die zur Laufzeit Werte erfordern.Fügen Sie im Textfeld Wert den vorhandenen Ordner im Format
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/hinzu. Der Pfad berücksichtigt die Groß- und Kleinschreibung. In diesem Pfad wird die Ausgabe des Skripts gespeichert. Das Schemawasbsist erforderlich, da für Speicherkonten die Option „Sichere Übertragung erforderlich“ nun standardmäßig aktiviert ist.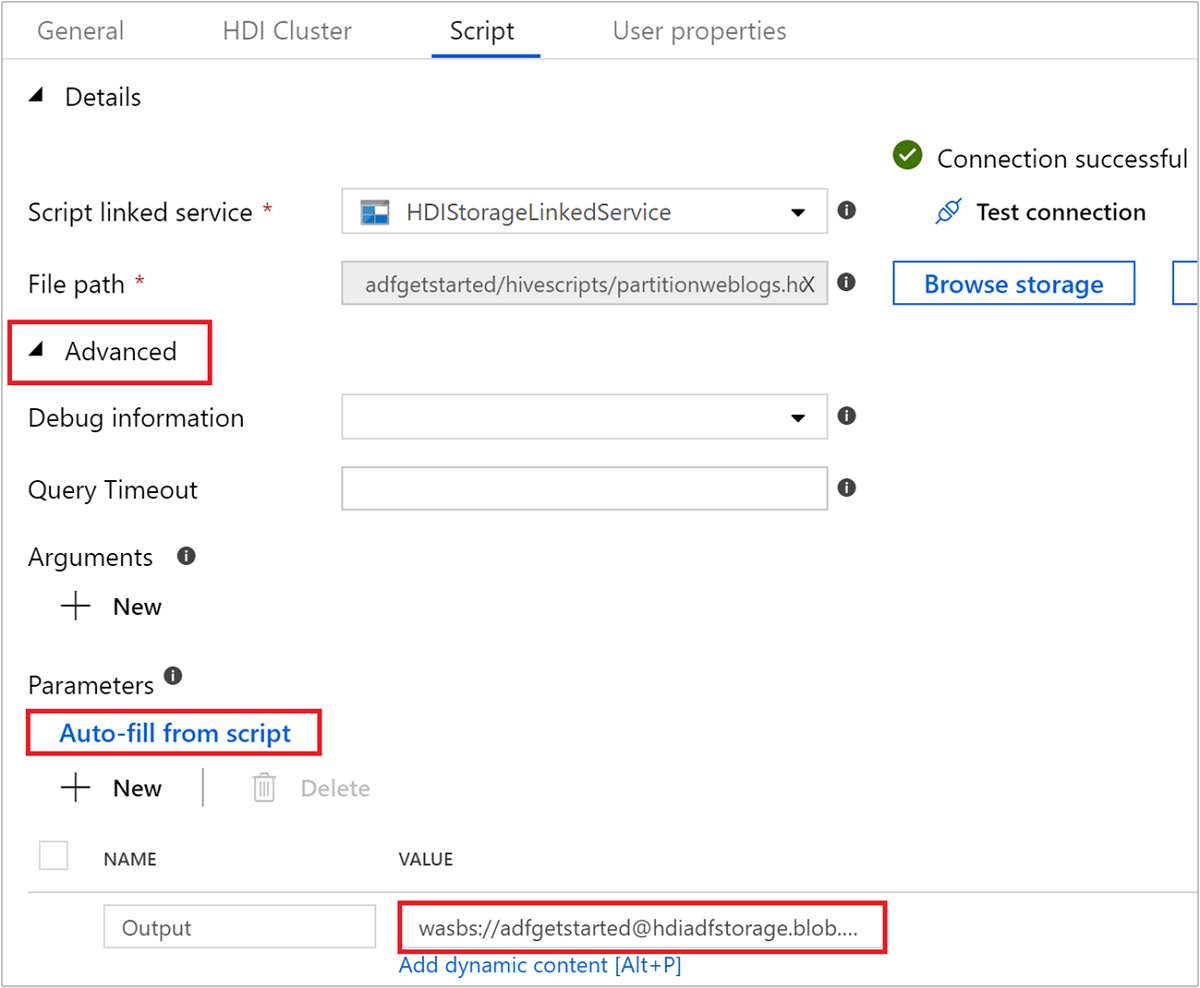
Wählen Sie Überprüfen aus, um die Pipeline zu überprüfen. Wählen Sie die Schaltfläche >> (Pfeil nach rechts), um das Überprüfungsfenster zu schließen.
Wählen Sie abschließend Alle veröffentlichen aus, um die Artefakte in Azure Data Factory zu veröffentlichen.
Auslösen einer Pipeline
Wählen Sie auf der Designeroberfläche auf der Symbolleiste Auslöser hinzufügen>Jetzt auslösen aus.
Wählen Sie in der eingeblendeten Seitenleiste OK aus.
Überwachen einer Pipeline
Wechseln Sie im linken Bereich zur Registerkarte Überwachen. In der Liste mit den Pipelineausführungen wird eine Pipelineausführung angezeigt. Beachten Sie den Status der Ausführung in der Spalte Status.
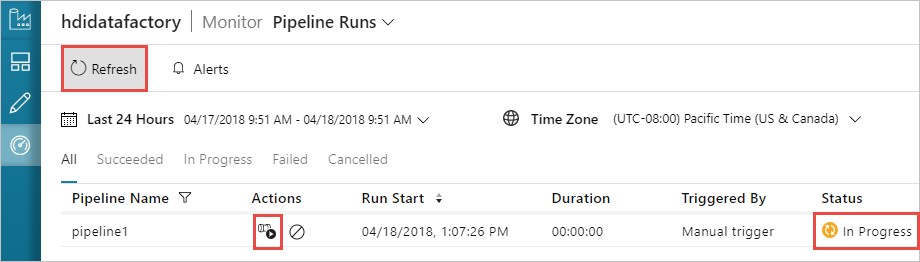
Wählen Sie zum Aktualisieren des Status die Option Aktualisieren.
Sie können auch das Symbol View Activity Runs (Aktivitätsausführungen anzeigen) auswählen, um die mit der Pipelineausführung verknüpfte Aktivitätsausführung anzuzeigen. Da die von Ihnen erstellte Pipeline nur eine einzelne Aktivität enthält, wird im Screenshot nur eine Aktivitätsausführung angezeigt. Um wieder in die vorherige Ansicht zu wechseln, wählen Sie oben auf der Seite Pipelines aus.
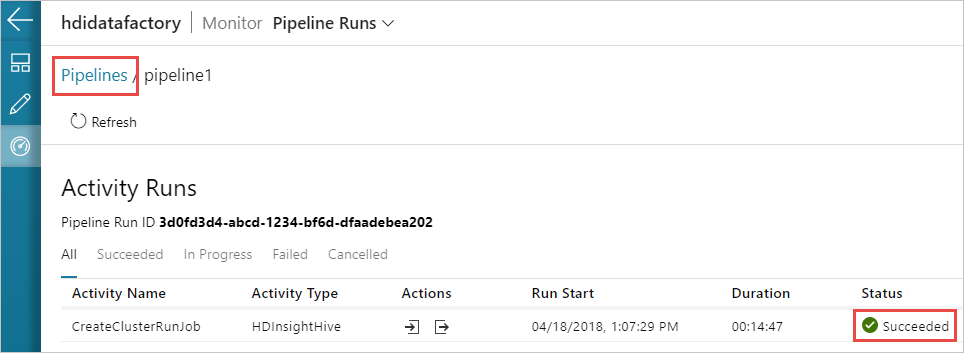
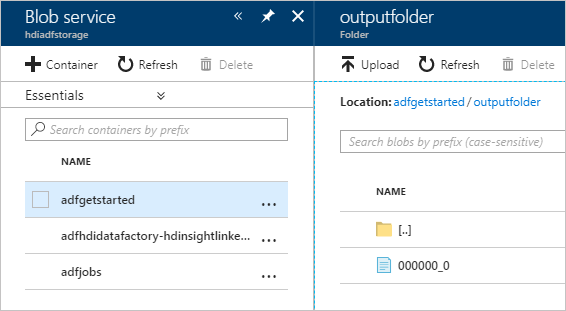
Überprüfen der Ausgabe
Um die Ausgabe zu überprüfen, navigieren Sie im Azure-Portal zu dem Speicherkonto, das Sie für dieses Tutorial verwendet haben. Die folgenden Ordner und Container sollten angezeigt werden:
Sie sehen, dass adfgerstarted/outputfolder die Ausgabe des Hive-Skripts enthält, das als Teil der Pipeline ausgeführt wurde.
Sie sehen den Container adfhdidatafactory-<Name-des-verknüpften-Diensts>-<Zeitstempel>. Dieser Container ist der Standardspeicherort des HDInsight-Clusters, der als Teil der Pipelineausführung erstellt wurde.
Der Container adfjobs enthält die Protokolle des Azure Data Factory-Auftrags.
Bereinigen von Ressourcen
Bei einer bedarfsgesteuerten HDInsight-Clustererstellung müssen Sie den HDInsight-Cluster nicht explizit löschen. Der Cluster wird gemäß der Konfiguration, die Sie beim Erstellen der Pipeline bereitgestellt haben, gelöscht. Auch nachdem der Cluster gelöscht wurde, bleiben die mit dem Cluster verbundenen Speicherkonten vorhanden. Dieses Verhalten ist beabsichtigt, damit Ihre Daten intakt bleiben. Wenn Sie die Daten nicht beibehalten möchten, können Sie jedoch das erstellte Speicherkonto löschen.
Alternativ können Sie die gesamte Ressourcengruppe löschen, die Sie für dieses Tutorial erstellt haben. Dadurch werden das Speicherkonto und die Azure Data Factory-Instanz gelöscht, die Sie erstellt haben.
Löschen der Ressourcengruppe
Melden Sie sich beim Azure-Portalan.
Wählen Sie im linken Bereich Ressourcengruppen aus.
Wählen Sie den Namen der Ressourcengruppe, die Sie im PowerShell-Skript erstellt haben, aus. Verwenden Sie den Filter, wenn zu viele Ressourcengruppen aufgeführt werden. Daraufhin wird die Ressourcengruppe geöffnet.
Auf der Kachel Ressourcen sollten das Standardspeicherkonto und die Data Factory aufgeführt sein, wenn Sie die Ressourcengruppe nicht für andere Projekte freigegeben haben.
Wählen Sie die Option Ressourcengruppe löschen. Auf diese Weise werden das Speicherkonto und die Daten im Speicherkonto gelöscht.
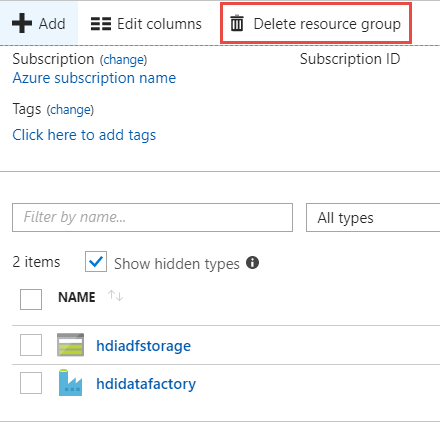
Geben Sie den Namen der Ressourcengruppe ein, um den Löschvorgang zu bestätigen, und wählen Sie dann Löschen aus.
Nächste Schritte
In diesem Artikel haben Sie gelernt, wie Sie bedarfsgesteuert mit Azure Data Factory einen HDInsight-Cluster erstellen und Apache Hive-Aufträge ausführen. Fahren Sie mit dem nächsten Artikel fort, um zu erfahren, wie Sie HDInsight-Cluster mit einer benutzerdefinierten Konfiguration erstellen.