Verstehen und Anpassen von Stream Analytics-Streamingeinheiten
Verstehen von Streamingeinheit und Streamingknoten
Streamingeinheiten stellen die Computeressourcen dar, die zur Ausführung eines Stream Analytics-Auftrags ausgewählt werden. Je höher die Anzahl von Streamingeinheiten ist, desto mehr CPU- und Arbeitsspeicherressourcen werden Ihrem Auftrag zugeordnet. Mit dieser Kapazität können Sie sich auf die Abfragelogik konzentrieren. Zudem wird der Bedarf zur Verwaltung der Hardware abstrahiert, um Ihren Stream Analytics-Auftrag rechtzeitig auszuführen.
Azure Stream Analytics unterstützt zwei Streamingeinheitsstrukturen: SU V1 (veraltet) und SU V2 (empfohlen).
Das SU V1-Modell ist das ursprüngliche Angebot von ASA, bei dem alle sechs SUs einem einzelnen Streamingknoten für einen Auftrag entsprechen. Aufträge können auch mit 1 und 3 SUs ausgeführt werden, die dann mit Bruchteilen von Streamingknoten übereinstimmen. Die Skalierung erfolgt bei Überschreiten von 6 SU-Aufträgen in Inkrementen von 6 auf 12, 18, 24 und mehr, indem weitere Streamingknoten hinzugefügt werden, die verteilte Computingressourcen bereitstellen.
Das SU V2-Modell (empfohlen) ist eine vereinfachte Struktur mit günstigen Preisen für dieselben Computeressourcen. Im SU V2-Modell entspricht 1 SU V2 einem Streamingknoten für Ihren Auftrag. 2 SU V2 entsprechen 2, 3 entsprechen 3 usw. Aufträge mit 1/3 und 2/3 SU V2 sind auch mit einem Streamingknoten verfügbar, aber nur mit einem Bruchteil der Computeressourcen. Die 1/3- und 2/3-SU V2-Aufträge bieten eine kostengünstige Option für Workloads, die eine kleinere Skalierung erfordern.
Die zugrunde liegende Computeleistung für V1- und V2-Streamingeinheiten entspricht Folgendem:
Informationen zu SU-Preisen finden Sie auf der Seite mit den Azure Stream Analytics-Preisen.
Verstehen der Konvertierung von Streamingeinheiten und deren Anwendung
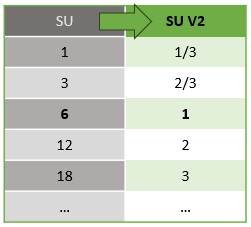
Es gibt eine automatische Konvertierung von Streamingeinheiten, die von der REST-API-Ebene in die Benutzeroberfläche (Azure Portal und Visual Studio Code) erfolgt. Sie werden diese Konvertierung im Aktivitätsprotokoll feststellen, wobei SU-Werte anders als die Werte auf der Benutzeroberfläche angezeigt werden. Dies ist entwurfsbedingt und der Grund dafür, dass REST-API-Felder auf ganzzahlige Werte beschränkt sind und ASA-Aufträge Bruchknoten unterstützen (1/3 und 2/3 Streaming Units). Die Benutzeroberfläche von ASA zeigt Knotenwerte 1/3, 2/3, 1, 2, 3, ... usw., während das Back-End (Aktivitätsprotokolle, REST-API-Ebene) dieselben Werte mit 10 multipliziert mit 3, 7, 10, 20, 30 anzeigt.
| Standard | Standard V2 (Benutzeroberfläche) | Standard V2 (Back-End wie Protokolle, Rest-API usw.) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Auf diese Weise können wir die gleiche Granularität vermitteln und den Dezimalpunkt auf der API-Ebene für V2 SKUs zu beseitigen. Diese Konvertierung erfolgt automatisch und hat keine Auswirkungen auf die Leistung Ihres Auftrags.
Verstehen von Verbrauch und Arbeitsspeicherauslastung
Um eine Streamingverarbeitung mit geringer Latenz zu erreichen, führen Azure Stream Analytics-Aufträge (ASA) die gesamte Verarbeitung im Arbeitsspeicher durch. Wenn nicht genügend Arbeitsspeicher vorhanden ist, tritt beim Streamingauftrag ein Fehler auf. Daher ist es bei einem Produktionsauftrag wichtig, die Ressourcennutzung eines Streamingauftrags zu überwachen und sicherzustellen, dass genügend Ressourcen zugewiesen werden, um die Aufträge rund um die Uhr auszuführen.
Die Nutzungsmetrik der Streamingeinheit in Prozent, die von 0 % bis 100 % reicht, zeigt die Arbeitsspeichernutzung Ihrer Workload auf. Bei einem Streamingauftrag mit minimalem Ressourcenbedarf liegt die Metrik in der Regel zwischen 10 % und 20 %. Wenn die prozentuale Nutzung der Streamingeinheiten hoch (über 80 Prozent) ist oder Eingabeereignisse in den Rückstand geraten (auch mit einer niedrigen prozentualen Nutzung der Streamingeinheit, da die CPU-Auslastung nicht angezeigt wird), benötigt Ihr Workload wahrscheinlich mehr Computeressourcen, sodass Sie die Anzahl der Streamingeinheiten erhöhen müssen. Die Metrik für die Streamingeinheit sollte am besten immer unter 80 % liegen, damit gelegentliche Spitzen verarbeitet werden können. Für den Fall einer größeren Anzahl von Workloads und Streamingeinheiten können Sie auch eine 80-Prozent-Warnung für die Metrik der Nutzung der Streamingeinheiten einrichten. Außerdem können Sie mithilfe der Metriken zur Verzögerung des Wasserzeichens und den im Backlog erfassten Ereignissen ermitteln, ob eine Auswirkung vorliegt.
Konfigurieren von Stream Analytics-Streamingeinheiten (SUs)
Melden Sie sich beim Azure-Portal an.
Suchen Sie in der Liste der Ressourcen nach dem zu skalierenden Stream Analytics-Auftrag, und öffnen Sie ihn anschließend.
Wählen Sie auf der Auftragsseite unter der Überschrift Konfigurieren die Option Skalieren aus. Beim Erstellen eines Auftrags ist „1“ die Standardanzahl von SUs.
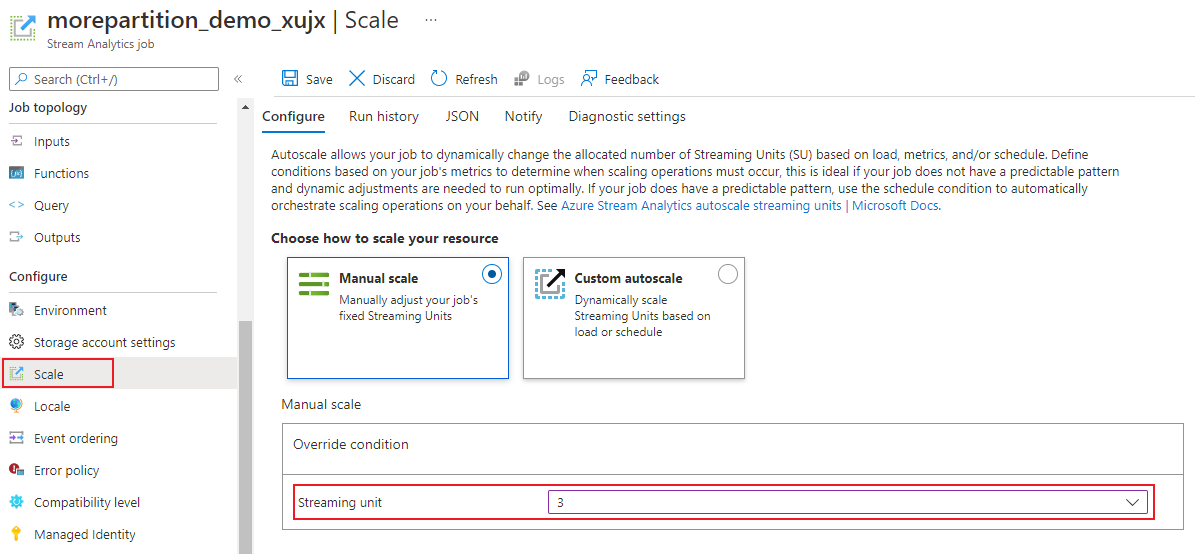
Wählen Sie die SU-Option in der Dropdownliste aus, um die SUs für den Auftrag festzulegen. Beachten Sie, dass Sie auf einen spezifischen SU-Bereich beschränkt sind.
Sie können die Anzahl der Ihrem Auftrag zugeordneten SUs während dessen Ausführung ändern. Möglicherweise sind Sie auf die Auswahl aus einer Reihe von SU-Werten beschränkt, wenn der Auftrag ausgeführt wird, wenn Ihr Auftrag eine nicht partitionierte Ausgabe verwendet oder über eine mehrstufige Abfrage mit unterschiedlichen PARTITION BY-Werten verfügt.
Überwachen der Auftragsleistung
Mit dem Azure-Portal können Sie die leistungsbezogenen Metriken eines Auftrags verfolgen. Weitere Informationen zu den Details dieser Aufgaben finden Sie unter Azure Stream Analytics-Auftragsmetriken. Weitere Informationen zur Metriküberwachung im Portal finden Sie unter Überwachen von Stream Analytics-Auftrag mit Azure-Portal.
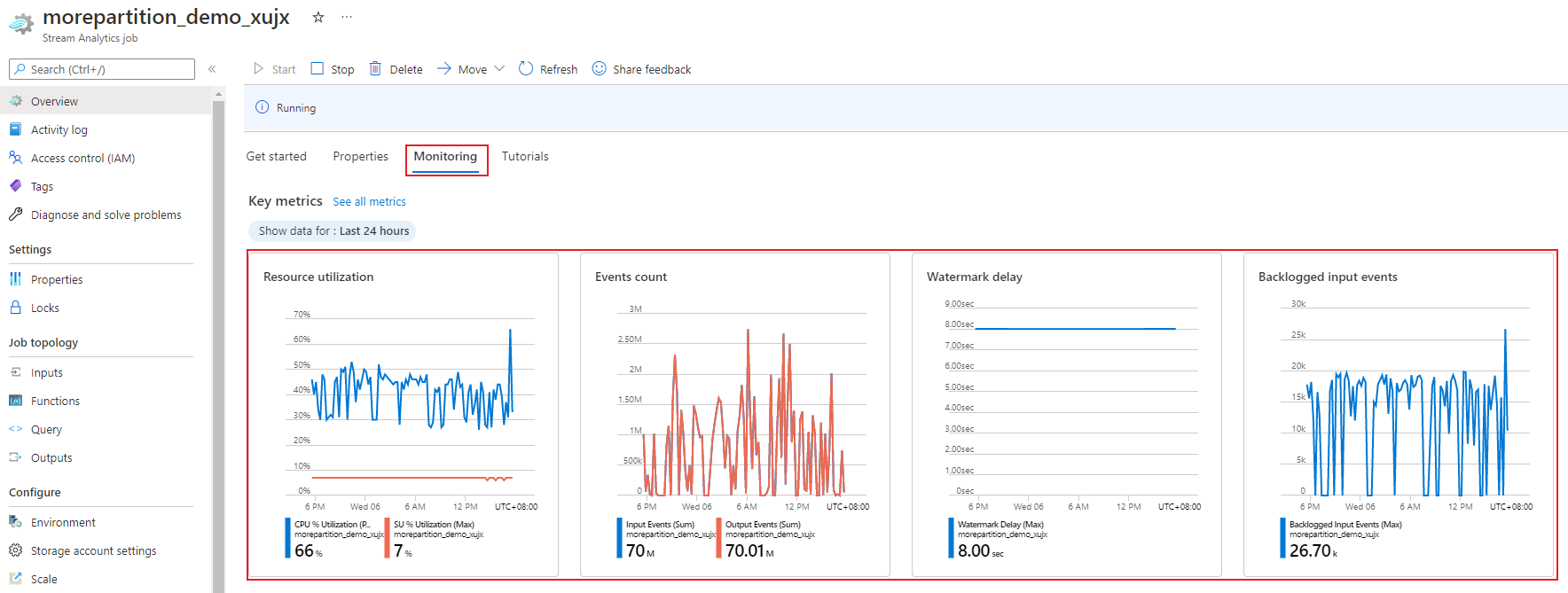
Berechnen Sie den erwarteten Durchsatz der Workload. Für den Fall, dass der Durchsatz kleiner als erwartet ist, optimieren Sie die Eingabepartition und die Abfrage, und fügen Sie dem Auftrag zusätzliche SUs hinzu.
Wie viele Premium-Streamingeinheiten sind für einen Auftrag erforderlich?
Die benötigte Anzahl an Premium-Streamingeinheiten für einen bestimmten Auftrag hängt von der Partitionskonfiguration für die Eingaben und der Abfrage ab, die für den Auftrag definiert ist. Auf der Seite Skalieren können Sie die richtige Anzahl von SUs festlegen. Es wird empfohlen, mehr Premium-Streamingeinheiten als erforderlich zuzuweisen. Die Stream Analytics-Verarbeitungs-Engine führt zu einer niedrigeren Latenz und einem höheren Durchsatz. Dabei wird zusätzlicher Speicherplatz beansprucht.
Im Allgemeinen wird empfohlen, für Abfragen, die PARTITION BY nicht verwenden, mit 1 SU V2 zu beginnen. Ermitteln Sie dann die optimale Anzahl mittels Trial-and-Error-Methode. Dabei ändern Sie die Anzahl der SUs, nachdem Sie eine repräsentative Datenmenge übertragen und die Metrik „Speichereinheitnutzung in %“ überprüft haben. Die Höchstzahl der von einem Stream Analytics-Auftrag verwendbaren Streamingeinheiten hängt von der Anzahl an Schritten in der für den Auftrag definierten Abfrage und der Anzahl an Partitionen für die einzelnen Schritte ab. Weitere Informationen zu diesen Grenzwerten finden Sie hier.
Weitere Informationen über die Auswahl der richtigen Anzahl von SUs finden Sie auf folgender Seite: Skalieren von Azure Stream Analytics-Aufträgen zur Erhöhung des Durchsatzes bei der Streamingdatenverarbeitung.
Hinweis
Die benötigte SU-Anzahl für einen bestimmten Auftrag hängt von der Partitionskonfiguration für die Eingaben und der für den Auftrag definierten Abfrage ab. Sie können die für Ihr Kontingent maximal festgelegte Anzahl von SUs für einen Auftrag auswählen. Informationen zum Azure Stream Analytics-Abonnementkontingent finden Sie unter Stream Analytics-Grenzwerte. Wenn Sie die SUs für Ihre Abonnements über dieses Kontingent hinaus erhöhen möchten, wenden Sie sich an den Microsoft-Support. Gültige Werte für SUs pro Auftrag sind 1/3, 2/3, 1, 2, 3 usw.
Faktoren für die Erhöhung der SU-Nutzung in %
Temporale (zeitlich orientierte) Abfrageelemente sind die Kerngruppe der zustandsbehafteten Operatoren, die von Stream Analytics bereitgestellt werden. Stream Analytics verwaltet den Zustand dieser Vorgänge intern im Auftrag des Benutzers durch Verwaltung des Speicherverbrauchs, Prüfpunktausführung für höhere Resilienz und Zustandswiederherstellung bei Dienstupgrades. Auch wenn Stream Analytics die Zustände vollständig verwaltet, sollte der Benutzer einige Empfehlungen zu bewährten Methoden berücksichtigen.
Beachten Sie, dass ein Auftrag mit komplexer Abfragelogik eine hohe prozentuelle Auslastung der SUs aufweisen kann, wenn er nicht kontinuierlich Eingabeereignisse empfängt. Dies kann nach einer plötzlichen Spitze bei den Eingabe- und Ausgabeereignissen auftreten. Möglicherweise wird der Zustand des Auftrags im Arbeitsspeicher weiterhin beibehalten, wenn die Abfrage komplex ist.
Die Speichereinheitnutzung in % kann für einen kurzen Zeitraum plötzlich auf 0 fallen, bevor wieder die erwartete Ebene erreicht wird. Dies geschieht aufgrund von vorübergehenden Fehlern oder durch vom System initiierte Upgrades. Wenn Sie die Anzahl der Streamingeinheiten für einen Auftrag erhöhen, wird die Speichereinheitennutzung in Prozent möglicherweise nicht verringert, wenn Ihre Abfrage nicht vollständig parallel verläuft.
Verwenden Sie zum Vergleichen der Auslastung über einen bestimmten Zeitraum Metriken zu Ereignisraten. Die Metriken „InputEvents“ und „OutputEvents“ zeigen die Anzahl der gelesenen und verarbeiteten Ereignisse. Es gibt auch Metriken, die die Anzahl von Fehlerereignissen (etwa von Deserialisierungsfehlern) angeben. Wenn die Anzahl von Ereignissen pro Zeiteinheit zunimmt, steigt in den meisten Fällen die Auslastung der Speichereinheiten (in Prozent).
Zustandsbehaftete Abfragelogik in temporalen Elementen
Eine einzigartige Funktion eines Azure Stream Analytics-Auftrags besteht darin, eine zustandsbehaftete Verarbeitung wie etwa Aggregate, temporale Verknüpfungen und temporale Analysefunktionen im Fenstermodus auszuführen. Die einzelnen Operatoren enthalten Zustandsinformationen. Die maximale Fenstergröße für diese Abfrageelemente beträgt sieben Tage.
Der Begriff der temporalen Fenster kommt in mehreren Stream Analytics-Abfrageelementen vor:
Fensteraggregate: GROUP BY von rollierenden, springenden und gleitenden Fenstern
Temporale Joins: JOIN mit DATEDIFF-Funktion
Temporale Analysefunktionen: ISFIRST, LAST und LAG mit LIMIT DURATION
Die folgenden Faktoren beeinflussen den belegten Arbeitsspeicher (Teil der Metrik „Streamingeinheit“) von Stream Analytics-Aufträgen:
Aggregate im Fenstermodus
Der belegte Arbeitsspeicher (Zustandsgröße) für ein Aggregat im Fenstermodus ist nicht immer direkt proportional zur Fenstergröße. Der belegte Arbeitsspeicher verhält sich stattdessen proportional zur Kardinalität der Daten oder der Anzahl der Gruppen in jedem Zeitfenster.
Beispiel: In der folgenden Abfrage ist die mit clusterid verknüpfte Zahl die Kardinalität der Abfrage.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Zum Beheben von Problemen, die durch hohe Kardinalität in der vorherigen Abfrage verursacht wurden, können Sie Ereignisse an den von clusterid partitionierten Event Hub senden und die Abfrage aufskalieren, indem Sie dem System die separate Verarbeitung aller Eingangspartitionen durch PARTITION BY ermöglichen. Dies wird im folgenden Beispiel gezeigt:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
Nach dem Partitionieren der Abfrage wird sie auf mehrere Knoten verteilt. Infolgedessen verringert sich die Anzahl eingehender clusterid-Werte auf den einzelnen Knoten, wodurch wiederum die Kardinalität des GROUP BY-Operators reduziert wird.
Event Hub-Partitionen sollten durch den Gruppierungsschlüssel partitioniert werden, um die Notwendigkeit eines Reduzierungsschritts zu vermeiden. Weitere Informationen finden Sie unter Übersicht über Event Hubs.
Temporale Joins
Der belegte Arbeitsspeicher (Zustandsgröße) eines temporalen Joins verhält sich proportional zur Anzahl der Ereignisse im zeitlichen Spielraum des Joins, der die Ereigniseingangsrate multipliziert mit der Größe des Spielraums darstellt. Anders ausgedrückt: Der durch Joins belegte Arbeitsspeicher ist proportional zum DateDiff-Zeitbereich multipliziert mit der durchschnittlichen Ereignisrate.
Die Anzahl nicht abgeglichener Ereignisse im Verknüpfungsvorgang wirkt sich auf die Arbeitsspeichernutzung für die Abfrage aus. Mit der folgenden Abfrage werden die Anzeigenaufrufe ermittelt, die Klicks generieren:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
In diesem Beispiel kann es sein, dass viele Anzeigen angezeigt werden, aber nur wenige Benutzer auf diese klicken, und alle Ereignisse müssen im Zeitfenster bleiben. Der belegte Arbeitsspeicher ist proportional zu Fenstergröße und Ereignisrate.
Um dies zu beheben, senden Sie Ereignisse an den durch die Verknüpfungsschlüssel (in diesem Fall IDs) partitionierten Event Hub, und skalieren Sie die Abfrage auf, indem Sie dem System die separate Verarbeitung jeder Eingangspartition mit PARTITION BY ermöglichen, wie im Folgenden gezeigt wird:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
Nach dem Partitionieren der Abfrage wird sie auf mehrere Knoten verteilt. Infolgedessen verringert sich die Anzahl eingehender Ereignisse auf den einzelnen Knoten, wodurch wiederum die Größe des Zustands im Verknüpfungsfenster reduziert wird.
Temporale Analysefunktionen
Der belegte Arbeitsspeicher (Zustandsgröße) einer temporalen Analysefunktion verhält sich proportional zu der mit der Dauer multiplizierten Ereignisrate. Der durch Analysefunktionen belegte Arbeitsspeicher verhält sich nicht proportional zur Fenstergröße, sondern zur Partitionsanzahl in jedem Zeitfenster.
Die Wiederherstellung weist Ähnlichkeiten mit der temporalen Verknüpfung auf. Sie können die Abfrage durch PARTITION BY horizontal hochskalieren.
Puffer für Ereignisse in falscher Reihenfolge
Benutzer können die Größe eines Puffers für Ereignisse in falscher Reihenfolge im Konfigurationsbereich „Ereignisreihenfolge“ konfigurieren. Der Puffer wird verwendet, um Eingaben für die Dauer des Fensters zu speichern und neu anzuordnen. Die Größe des Puffers verhält sich proportional zu der mit der Größe des Fensters für Ereignisse in falscher Reihenfolge multiplizierten Ereigniseingangsrate. Die Standardfenstergröße beträgt 0.
Um einen Überlauf des Puffers in einer anderen Reihenfolge zu beheben, skalieren Sie die Abfrage mit PARTITION BY horizontal hoch. Nach dem Partitionieren der Abfrage wird sie auf mehrere Knoten verteilt. Infolgedessen verringert sich die Anzahl eingehender Ereignisse auf den einzelnen Knoten, wodurch wiederum die Größe der Ereignisse in jedem Neuanordnungspuffer reduziert wird.
Anzahl von Eingabepartitionen
Jede Eingabepartition einer Auftragseingabe weist einen Puffer auf. Je größer die Anzahl der Eingabepartitionen, desto mehr Ressourcen verbraucht der Auftrag. Für jede Streamingeinheit kann Azure Stream Analytics ungefähr 7 MB/s der Eingabe verarbeiten. Daher können Sie eine Optimierung vornehmen, indem Sie die Anzahl der Stream Analytics-Streamingeinheiten an die Anzahl von Partitionen in Ihrem Event Hub anpassen.
In der Regel ist ein Auftrag, der mit 1/3 Streamingeinheit konfiguriert ist, für einen Event Hub mit zwei Partitionen (d. h. der Mindestanzahl für einen Event Hub) ausreichend. Wenn der Event Hub eine größere Anzahl von Partitionen aufweist, verbraucht Ihr Stream Analytics-Auftrag mehr Ressourcen, nutzt jedoch nicht zwingend den zusätzlichen vom Event Hub bereitgestellten Durchsatz.
Für einen Auftrag mit 1 V2-Streamingeinheiten benötigen Sie eventuell 4 oder 8 Partitionen vom Event Hub. Verwalten Sie jedoch nicht zu viele nicht benötigte Partitionen, da dies zu einem übermäßigen Ressourceneinsatz führt. Beispiel: Ein Event Hub mit mindestens 16 Partitionen in einem Stream Analytics-Auftrag mit 1 Streamingeinheit.
Verweisdaten
Die Verweisdaten in ASA werden zur schnellen Suche in den Speicher geladen. Bei der aktuellen Implementierung wird bei jedem Verknüpfungsvorgang mit Verweisdaten eine Kopie der Verweisdaten im Speicher beibehalten, auch wenn Sie dieselben Verweisdaten mehrmals verknüpfen müssen. Bei Abfragen mit PARTITION BY behält jede Partition eine Kopie der Verweisdaten bei, sodass die Partitionen vollständig entkoppelt sind. Durch den Multiplikationseffekt kann die Speicherverwendung schnell in die Höhe schießen, wenn Sie Verweisdaten mehrmals mit mehreren Partitionen verknüpfen.
Verwenden von UDF-Funktionen
Wenn Sie eine UDF-Funktion hinzufügen, lädt Azure Stream Analytics die JavaScript-Laufzeit in den Arbeitsspeicher. Dies wirkt sich auf die Speichereinheitnutzung in % aus.
Nächste Schritte
- Erstellen von parallelisierbaren Abfragen in Azure Stream Analytics
- Skalieren von Azure Stream Analytics-Aufträgen zur Erhöhung des Durchsatzes
- Azure Stream Analytics-Auftragsmetriken
- Dimensionen von Azure Stream Analytics-Auftragsmetriken
- Überwachen von Stream Analytics-Auftrag mit Azure-Portal
- Analysieren der Stream Analytics Auftragsleistung mit Metrikendimensionen
- Verstehen und Anpassen von Streamingeinheiten