OCR-Aktionen
Power Automate ermöglicht Benutzern das Lesen, Extrahieren und Verwalten von Daten in Dateien durch optische Zeichenerkennung (OCR).
Um eine OCR-Engine zu erstellen und Text aus Bildern und Dokumenten zu extrahieren, verwenden Sie die Aktion Text mit OCR extrahieren. Im folgenden Beispiel wird Text aus dem gesamten angegebenen Bild extrahiert.
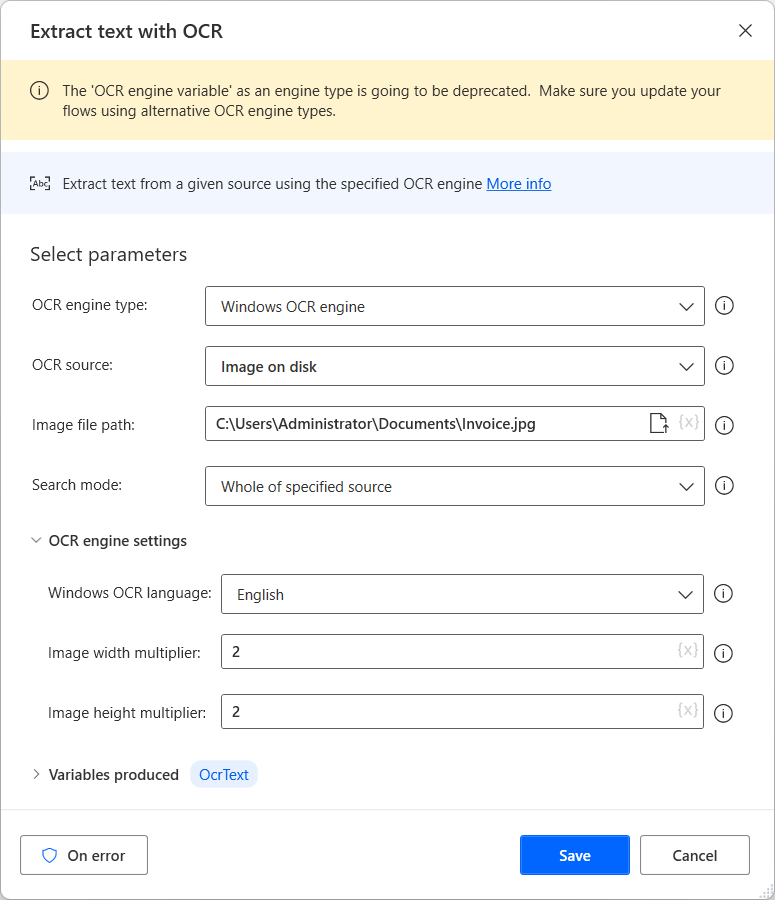
Alle OCR-Aktionen können eine neue OCR-Engine-Variable erstellen oder eine vorhandene verwenden. Sie können vorhandene OCR-Engine-Variablen in jeder Aktion verwenden, die OCR-Funktionalitäten bietet.
Power Automate unterstützt die Windows-OCR- und die Tesseract-Engine. Um die ausgewählte OCR-Engine zu konfigurieren, navigieren Sie zu den OCR-Moduleinstellungen der passenden Aktion. Zu den verfügbaren Optionen gehören die Sprache und die Multiplikatoren für die Bildbreite und -höhe.
Notiz
- Alle verfügbaren OCR-Engines sind in Power Automate vorinstalliert und arbeiten lokal, ohne sich mit der Cloud zu verbinden. Möglicherweise müssen Sie jedoch Sprachpakete oder Datendateien herunterladen, um Texte in bestimmten Sprachen zu extrahieren.
- Bildmultiplikatoren erhöhen die Bildgröße, um die Suche und Textextraktion effektiver zu gestalten. Wenn Sie Werte größer als 3 festlegen, erhalten Sie eventuell fehlerhafte Ergebnisse.
Die Windows-OCR-Engine verwenden
Die Standard-OCR-Engine in Power Automate ist die Windows OCR-Engine. Um Texte mit der Windows OCR-Engine zu extrahieren, müssen Sie das entsprechende Sprachpaket für die Sprache installieren, die Sie extrahieren möchten.
Wenn das entsprechende Sprachpaket nicht installiert ist, gibt Power Automate einen Fehler aus und fordert Sie auf, es zu installieren. Weitere Informationen zum Herunterladen und Installieren von Sprachpaketen finden Sie unter Sprachpakete für Windows.
Nach der Installation des entsprechenden Sprachpakets erweitern Sie die OCR-Engine-Einstellungen der OCR-Aktion und wählen die gewünschte Sprache aus. Die OCR-Engine von Windows unterstützt 25 Sprachen, darunter Chinesisch (vereinfacht und traditionell), Tschechisch, Dänisch, Niederländisch, Englisch, Finnisch, Französisch, Deutsch, Griechisch, Ungarisch, Italienisch, Japanisch, Koreanisch, Norwegisch, Polnisch, Portugiesisch, Rumänisch, Russisch, Serbisch (kyrillisch und lateinisch), Slowakisch, Spanisch, Schwedisch und Türkisch.
Die Tesseract OCR-Engine verwenden
Notiz
Um die Tesseract-OCR-Engine zu verwenden, stellen Sie sicher, dass die CPU des Geräts den AVX2-Befehlssatz unterstützt.
Neben der Windows OCR-Engine unterstützt Power Automate auch die Tesseract-Engine. Diese Engine kann ohne weitere Konfiguration Text in fünf Sprachen extrahieren: Englisch, Deutsch, Spanisch, Französisch und Italienisch.
Um Text in einer Sprache außerhalb der genannten Liste zu extrahieren, aktivieren Sie die Option Andere Sprachen verwenden in den OCR-Engine-Einstellungen der OCR-Aktion. Wenn diese Option aktiviert ist, zeigt die Aktion zwei weitere Einstellungen an: Abkürzung der Sprache und Sprachdatenpfad.
Das Feld Sprachkürzel zeigt den Modul an, nach welcher Sprache während OCR gesucht werden soll. Das Feld Sprachdatenpfad enthält die Sprachdatendateien (.traineddata), die zum Trainieren der OCR-Engine verwendet werden. Die Sprachdateien für alle verfügbaren Sprachen finden Sie in diesem GitHub Repository.
Sie können die Tesseract-Engine auch verwenden, um Text aus mehrsprachigen Dokumenten zu extrahieren. Weitere Informationen zum Extrahieren von Text aus mehrsprachigen Dokumenten finden Sie unter OCR für mehrsprachige Dokumente durchführen.
Wenn Text auf dem Bildschirm (OCR)
Kennzeichnet den Beginn eines bedingten Aktionsblocks, je nachdem, ob ein bestimmter Text mithilfe von OCR auf dem Bildschirm erscheint oder nicht.
Eingabeparameter
| Argument | Optional | Akzeptiert | Standardwert | Beschreibung des Dataflows |
|---|---|---|---|---|
| If text | n/v | Existiert, Existiert nicht | Vorhanden | Legt fest, ob geprüft werden soll, ob der Text in der zu analysierenden Quelle existiert oder nicht |
| Typ der OCR-Engine | Keine | Windows OCR-Engine, Tesseract-Engine, OCR-Engine variabel | OCR-Engine variabel | Der Typ der zu verwendenden OCR-Engine. Wählen Sie eine vorkonfigurierte OCR-Engine oder legen Sie eine neue fest. |
| OCR-Engine-Variable | Nein | OCREngineObject | Das Modul, das für den OCR-Vorgang verwendet werden soll | |
| Text to find | Nein | Textwert | Der Text, der in der angegebenen Quelle gesucht werden soll | |
| Is regular expression | n/v | Boolescher Wert | Nein | Gibt an, ob ein regulärer Ausdruck zum Suchen des angegebenen Texts verwendet werden soll |
| Search for text on | n/v | Gesamter Bildschirm, Fenster im Vordergrund | Ganzer Bildschirm | Gibt an, ob der angegebene Text auf dem gesamten sichtbaren Bildschirm oder nur im Vordergrundfenster gesucht werden soll |
| Search mode | NICHT ZUTREFFEND | Gesamtes der angegebenen Quelle, nur bestimmter Teilbereich, Teilbereich relativ zum Bild | Ganze angegebene Quelle | Gibt an, ob der gesamte Bildschirm (oder das Fenster) oder ein eingeschränkter Teilabschnitt gescannt werden soll |
| Bilder | Nein | Liste der Bilder | Die Bilder, die den Teilabschnitt (im Verhältnis zur oberen linken Ecke des Bilds) angeben, um nach dem angegebenen Text zu suchen | |
| X1 | Ja | Numerischer Wert | Die Anfangs-X-Koordinate des Teilabschnitts, in dem nach dem angegebenen Text gesucht werden soll | |
| Tolerance | Ja | Numerischer Wert | 10 | Gibt an, in welchem Umfang sich die gesuchten Bilder von dem ursprünglich ausgewählten Bild unterscheiden können |
| Y1 | Ja | Numerischer Wert | Die Anfangs-Y-Koordinate des Teilabschnitts, in dem nach dem angegebenen Text gesucht werden soll | |
| X1 | Ja | Numerischer Wert | Die Anfangs-X-Koordinate des Teilabschnitts im Verhältnis zum angegebenen Bild, in dem nach dem angegebenen Text gesucht werden soll | |
| X2 | Ja | Numerischer Wert | Die End-X-Koordinate des Teilabschnitts, in dem nach dem angegebenen Text gesucht werden soll | |
| Y1 | Ja | Numerischer Wert | Die Anfangs-Y-Koordinate des Teilabschnitts im Verhältnis zum angegebenen Bild, in dem nach dem angegebenen Text gesucht werden soll | |
| Y2 | Ja | Numerischer Wert | Die End-Y-Koordinate des Teilabschnitts, in dem nach dem angegebenen Text gesucht werden soll | |
| X2 | Ja | Numerischer Wert | Die End-X-Koordinate des Teilabschnitts im Verhältnis zum angegebenen Bild, in dem nach dem angegebenen Text gesucht werden soll | |
| Y2 | Ja | Numerischer Wert | Die End-Y-Koordinate des Unterbereichs relativ zum angegebenen Bild, um nach dem gelieferten Text zu scannen | |
| Windows OCR-Sprache | NICHT ZUTREFFEND | Chinesisch (vereinfacht), Chinesisch (traditionell), Tschechisch, Dänisch, Niederländisch, Englisch, Finnisch, Französisch, Deutsch, Griechisch, Ungarisch, Italienisch, Japanisch, Koreanisch, Norwegisch, Polnisch, Portugiesisch, Rumänisch, Russisch, Serbisch (kyrillisch), Serbisch (lateinisch), Slowakisch, Spanisch, Schwedisch, Türkisch | Englisch | Die Sprache des Textes, die von der Windows OCR-Engine erkannt wird |
| Andere Sprache verwenden | NICHT ZUTREFFEND | Boolescher Wert | Falsch | Legt fest, ob eine Sprache verwendet werden soll, die nicht im Feld 'Tesseract-Sprache' angegeben ist |
| Tesseract Sprache | NICHT ZUTREFFEND | Englisch, Deutsch, Spanisch, Französisch, Italienisch | Englisch | Die Sprache des Textes, den die Tesseract-Engine erkennt |
| Abkürzung der Sprache | Nein | Textwert | Die Tesseract-Abkürzung der zu verwendenden Sprache. Wenn die Daten zum Beispiel „eng.traineddata“ sind, legen Sie diesen Parameter auf „eng“ fest | |
| Sprache Datenpfad | Nein | Text Wert | Der Pfad des Ordners, der die Tesseract-Daten der angegebenen Sprache enthält | |
| Multiplikator für die Bildbreite | Keine | Numerischer Wert | 1 | Der Breitenmultiplikator des Bildes |
| Multiplikator für die Bildhöhe | Nein | Numerischer Wert | 1 | Der Höhenmultiplikator des Bildes |
| Algorithmus für den Bildabgleich | NICHT ZUTREFFEND | Standard, Erweitert | Grundlegend | Welcher Bildalgorithmus soll bei der Suche nach Bildern verwendet werden |
Notiz
- Das Modul von Power Automate für reguläre Ausdrücke ist .NET. Weitere Informationen zu regulären Ausdrücken finden Sie in Sprache für reguläre Ausdrücke – Kurzübersicht.
- Die Option OCR-Engine-Variable soll außer Betrieb genommen werden.
Erzeugte Variablen
| Argument | Type | Beschreibung des Dataflows |
|---|---|---|
| StandortOfTextFoundX | Numerischer Wert | Die X-Koordinate des Punkts, an dem der Text auf dem Bildschirm erscheint. Wenn die Suche im Vordergrundfenster durchgeführt wird, ist die zurückgegebene Koordinate relativ zur linken oberen Ecke des Fensters |
| LocationOfTextFoundY | Numerischer Wert | Die X-Koordinate des Punkts, an dem der Text auf dem Bildschirm erscheint. Wenn die Suche im Vordergrundfenster durchgeführt wird, ist die zurückgegebene Koordinate relativ zur linken oberen Ecke des Fensters |
Ausnahmen
| Ausnahme | Beschreibung des Dataflows |
|---|---|
| Kann nicht überprüfen, ob Text im nicht-interaktiven Modus vorhanden ist | Gibt an, dass es nicht möglich ist, den Text auf dem Bildschirm zu überprüfen, wenn er sich im nicht-interaktiven Modus befindet |
| Invalid subregion coordinates | Gibt an, dass die Koordinaten des angegebenen Teilabschnitts ungültig sind |
| Failed to analyze text with OCR | Gibt an, dass beim Analysieren des Texts mit OCR ein Fehler aufgetreten ist |
| Die OCR-Engine konnte nicht erstellt werden | Zeigt an, dass beim Erstellen der OCR-Engine ein Fehler aufgetreten ist |
| Der Datenpfadordner ist nicht vorhanden | Zeigt an, dass der für die Sprachdaten angegebene Ordner nicht existiert |
| Das ausgewählte Windows Sprachpaket ist nicht auf dem Rechner installiert | Zeigt an, dass das ausgewählte Windows Sprachpaket nicht auf dem Computer installiert ist |
| OCR-Engine nicht aktiv | Zeigt an, dass die OCR-Engine nicht aktiv ist |
Warten Sie, bis der Text auf dem Bildschirm angezeigt wird (OCR)
Warten Sie, bis ein bestimmter Text auf dem Bildschirm, im Vordergrundfenster oder in Bezug zu einem Bild auf dem Bildschirm bzw. im Vordergrundfenster mithilfe von OCR angezeigt/ausgeblendet wird.
Eingabeparameter
| Argument | Optional | Akzeptiert | Standardwert | Beschreibung des Dataflows |
|---|---|---|---|---|
| Wait for text to | n/v | Erscheinen, Verschwinden | Anzeigen | Legt fest, ob auf das Erscheinen oder Verschwinden des Textes gewartet werden soll |
| Typ der OCR-Engine | Keine | Windows OCR-Engine, Tesseract-Engine, OCR-Engine variabel | OCR-Engine variabel | Der Typ der zu verwendenden OCR-Engine. Wählen Sie eine vorkonfigurierte OCR-Engine oder legen Sie eine neue fest. |
| OCR-Engine-Variable | Nein | OCREngineObject | Das Modul, das für den OCR-Vorgang verwendet werden soll | |
| Text to find | Nein | Textwert | Der Text, der in der angegebenen Quelle gesucht werden soll | |
| Is regular expression | n/v | Boolescher Wert | Nein | Gibt an, ob ein regulärer Ausdruck zum Suchen des angegebenen Texts verwendet werden soll |
| Search for text on | n/v | Gesamter Bildschirm, Fenster im Vordergrund | Ganzer Bildschirm | Gibt an, ob der angegebene Text auf dem gesamten sichtbaren Bildschirm oder nur im Vordergrundfenster gesucht werden soll |
| Search mode | NICHT ZUTREFFEND | Gesamtes der angegebenen Quelle, nur bestimmter Teilbereich, Teilbereich relativ zum Bild | Ganze angegebene Quelle | Gibt an, ob der gesamte Bildschirm (oder das Fenster) oder ein eingeschränkter Teilabschnitt gescannt werden soll |
| Bilder | Nein | Liste der Bilder | Die Bilder, die den Teilabschnitt (im Verhältnis zur oberen linken Ecke des Bilds) angeben, um nach dem angegebenen Text zu suchen | |
| X1 | Ja | Numerischer Wert | Die Anfangs-X-Koordinate des Teilabschnitts, in dem nach dem angegebenen Text gesucht werden soll | |
| Tolerance | Ja | Numerischer Wert | 10 | Gibt an, in welchem Umfang sich die gesuchten Bilder von dem ursprünglich ausgewählten Bild unterscheiden können |
| Y1 | Ja | Numerischer Wert | Die Anfangs-Y-Koordinate des Teilabschnitts, in dem nach dem angegebenen Text gesucht werden soll | |
| X1 | Ja | Numerischer Wert | Die Anfangs-X-Koordinate des Teilabschnitts im Verhältnis zum angegebenen Bild, in dem nach dem angegebenen Text gesucht werden soll | |
| X2 | Ja | Numerischer Wert | Die End-X-Koordinate des Teilabschnitts, in dem nach dem angegebenen Text gesucht werden soll | |
| Y1 | Ja | Numerischer Wert | Die Anfangs-Y-Koordinate des Teilabschnitts im Verhältnis zum angegebenen Bild, in dem nach dem angegebenen Text gesucht werden soll | |
| Y2 | Ja | Numerischer Wert | Die End-Y-Koordinate des Teilabschnitts, in dem nach dem angegebenen Text gesucht werden soll | |
| X2 | Ja | Numerischer Wert | Die End-X-Koordinate des Teilabschnitts im Verhältnis zum angegebenen Bild, in dem nach dem angegebenen Text gesucht werden soll | |
| Y2 | Ja | Numerischer Wert | Die End-Y-Koordinate des Unterbereichs relativ zum angegebenen Bild, um nach dem gelieferten Text zu scannen | |
| Windows OCR-Sprache | NICHT ZUTREFFEND | Chinesisch (vereinfacht), Chinesisch (traditionell), Tschechisch, Dänisch, Niederländisch, Englisch, Finnisch, Französisch, Deutsch, Griechisch, Ungarisch, Italienisch, Japanisch, Koreanisch, Norwegisch, Polnisch, Portugiesisch, Rumänisch, Russisch, Serbisch (kyrillisch), Serbisch (lateinisch), Slowakisch, Spanisch, Schwedisch, Türkisch | Englisch | Die Sprache des Textes, die von der Windows OCR-Engine erkannt wird |
| Andere Sprache verwenden | NICHT ZUTREFFEND | Boolescher Wert | Falsch | Legt fest, ob eine Sprache verwendet werden soll, die nicht im Feld 'Tesseract-Sprache' angegeben ist |
| Tesseract Sprache | NICHT ZUTREFFEND | Englisch, Deutsch, Spanisch, Französisch, Italienisch | Englisch | Die Sprache des Textes, den die Tesseract-Engine erkennt |
| Abkürzung der Sprache | Nein | Textwert | Die Tesseract-Abkürzung der zu verwendenden Sprache. Wenn die Daten zum Beispiel „eng.traineddata“ sind, legen Sie diesen Parameter auf „eng“ fest | |
| Sprache Datenpfad | Nein | Text Wert | Der Pfad des Ordners, der die Tesseract-Daten der angegebenen Sprache enthält | |
| Multiplikator für die Bildbreite | Keine | Numerischer Wert | 1 | Der Breitenmultiplikator des Bildes |
| Multiplikator für die Bildhöhe | Nein | Numerischer Wert | 1 | Der Höhenmultiplikator des Bildes |
| Algorithmus für den Bildabgleich | NICHT ZUTREFFEND | Standard, Erweitert | Standard | Welcher Bildalgorithmus soll bei der Suche nach Bildern verwendet werden |
| Fehlschlag mit Zeitüberschreitungsfehler | NICHT ZUTREFFEND | Boolescher Wert | Falsch | Geben Sie an, ob die Aktion auf unbestimmte Zeit warten oder nach einer festgelegten Zeitspanne fehlschlagen soll |
Notiz
- Das Modul von Power Automate für reguläre Ausdrücke ist .NET. Weitere Informationen zu regulären Ausdrücken finden Sie in Sprache für reguläre Ausdrücke – Kurzübersicht.
- Die Option OCR-Engine-Variable soll außer Betrieb genommen werden.
Erzeugte Variablen
| Argument | Type | Beschreibung des Dataflows |
|---|---|---|
| StandortOfTextFoundX | Numerischer Wert | Die X-Koordinate des Punkts, an dem der Text auf dem Bildschirm erscheint. Wenn die Suche im Vordergrundfenster durchgeführt wird, ist die zurückgegebene Koordinate relativ zur linken oberen Ecke des Fensters |
| LocationOfTextFoundY | Numerischer Wert | Die X-Koordinate des Punkts, an dem der Text auf dem Bildschirm erscheint. Wenn die Suche im Vordergrundfenster durchgeführt wird, ist die zurückgegebene Koordinate relativ zur linken oberen Ecke des Fensters |
Ausnahmen
| Ausnahme | Beschreibung des Dataflows |
|---|---|
| Kann nicht überprüfen, ob Text im nicht-interaktiven Modus vorhanden ist | Gibt an, dass es nicht möglich ist, den Text auf dem Bildschirm zu überprüfen, wenn er sich im nicht-interaktiven Modus befindet |
| Invalid subregion coordinates | Gibt an, dass die Koordinaten des angegebenen Teilabschnitts ungültig sind |
| Failed to analyze text with OCR | Gibt an, dass beim Analysieren des Texts mit OCR ein Fehler aufgetreten ist |
| Die OCR-Engine konnte nicht erstellt werden | Zeigt an, dass beim Erstellen der OCR-Engine ein Fehler aufgetreten ist |
| Der Datenpfadordner ist nicht vorhanden | Zeigt an, dass der für die Sprachdaten angegebene Ordner nicht existiert |
| Das ausgewählte Windows Sprachpaket ist nicht auf dem Rechner installiert | Zeigt an, dass das ausgewählte Windows Sprachpaket nicht auf dem Computer installiert ist |
| OCR-Engine nicht aktiv | Zeigt an, dass die OCR-Engine nicht aktiv ist |
| Timeout-Fehler | Zeigt an, dass die Aktion nach einer festgelegten Zeitspanne fehlgeschlagen ist |
Text mit OCR extrahieren
Extrahieren Sie Text aus einer bestimmten Quelle mithilfe der angegebenen OCR-Engine.
Eingabeparameter
| Argument | Optional | Akzeptiert | Standardwert | Beschreibung des Dataflows |
|---|---|---|---|---|
| OCR-Engine | Keine | Windows OCR-Engine, Tesseract-Engine, OCR-Engine variabel | OCR-Engine variabel | Der Typ der zu verwendenden OCR-Engine. Wählen Sie eine vorkonfigurierte OCR-Engine oder legen Sie eine neue fest |
| OCR-Engine-Variable | Nein | OCREngineObject | Die Engine, die für den OCR-Vorgang verwendet werden soll | |
| OCR source | n/v | Bildschirm, Vordergrundfenster, Bild auf Festplatte | Bildschirm | Die Quelle des Bilds, auf dem der OCR-Vorgang ausgeführt werden soll |
| Image file path | Nein | Datei | Der Pfad des Bilds, auf dem der OCR-Vorgang ausgeführt werden soll | |
| Search mode | n/v | Gesamtes der angegebenen Quelle, nur bestimmter Teilbereich, Teilbereich relativ zum Bild | Ganze angegebene Quelle | Der ausgewählte Modus des OCR-Vorgangs |
| Bild | Nein | Liste der Bilder | Das Bild in Bezug zum angegebenen Bild, das zur Eingrenzung des Scans auf einen Teilabschnitt verwendet werden soll | |
| Tolerance | Ja | Numerischer Wert | 10 | Gibt an, in welchem Umfang sich das gesuchte Bild von dem ursprünglich ausgewählten Bild unterscheiden kann |
| X1 | Ja | Numerischer Wert | Die Anfangs-X-Koordinate des Teilabschnitts, auf den der Scan eingegrenzt werden soll | |
| X2 | Ja | Numerischer Wert | Die End-X-Koordinate des Teilabschnitts, auf den der Scan eingegrenzt werden soll | |
| Y1 | Ja | Numerischer Wert | Die Anfangs-Y-Koordinate des Teilabschnitts, auf den der Scan eingegrenzt werden soll | |
| Y2 | Ja | Numerischer Wert | Die Y-Endkoordinate des Teilbereichs, um den Scan einzugrenzen | |
| Windows OCR-Sprache | NICHT ZUTREFFEND | Chinesisch (vereinfacht), Chinesisch (traditionell), Tschechisch, Dänisch, Niederländisch, Englisch, Finnisch, Französisch, Deutsch, Griechisch, Ungarisch, Italienisch, Japanisch, Koreanisch, Norwegisch, Polnisch, Portugiesisch, Rumänisch, Russisch, Serbisch (kyrillisch), Serbisch (lateinisch), Slowakisch, Spanisch, Schwedisch, Türkisch | Englisch | Die Sprache des Textes, die von der Windows OCR-Engine erkannt wird |
| Andere Sprache verwenden | NICHT ZUTREFFEND | Boolescher Wert | Falsch | Legt fest, ob eine Sprache verwendet werden soll, die nicht im Feld 'Tesseract-Sprache' angegeben ist |
| Tesseract Sprache | NICHT ZUTREFFEND | Englisch, Deutsch, Spanisch, Französisch, Italienisch | Englisch | Die Sprache des Textes, den die Tesseract-Engine erkennt |
| Abkürzung der Sprache | Nein | Textwert | Die Tesseract-Abkürzung der zu verwendenden Sprache. Wenn die Daten zum Beispiel „eng.traineddata“ sind, legen Sie diesen Parameter auf „eng“ fest | |
| Sprache Datenpfad | Nein | Text Wert | Der Pfad des Ordners, der die Tesseract-Daten der angegebenen Sprache enthält | |
| Multiplikator für die Bildbreite | Keine | Numerischer Wert | 1 | Der Breitenmultiplikator des Bildes |
| Multiplikator für die Bildhöhe | Nein | Numerischer Wert | 1 | Der Höhenmultiplikator des Bildes |
| Warten, bis das Bild angezeigt wird | NICHT ZUTREFFEND | Boolescher Wert | Wahr | Gibt an, ob gewartet werden soll, bis das Bild auf dem Bildschirm oder im Vordergrundfenster erscheint |
| Zeitüberschreitung | Nein | Numerischer Wert | 5 | Gibt die Wartezeit für den Abschluss des Vorgangs an, bevor die Aktion fehlschlägt |
| Algorithmus für den Bildabgleich | NICHT ZUTREFFEND | Standard, Erweitert | Grundlegend | Welcher Bildalgorithmus soll bei der Suche nach Bildern verwendet werden |
Notiz
Die Option OCR-Engine-Variable soll außer Betrieb genommen werden.
Erzeugte Variablen
| Argument | Type | Beschreibung des Dataflows |
|---|---|---|
| OcrText | Text Wert | Das Ergebnis nach der Textextraktion |
Ausnahmen
| Ausnahme | Beschreibung |
|---|---|
| Fehler beim Extrahieren des Texts mit OCR | Gibt an, dass beim Extrahieren des Texts mit OCR aus der angegebenen Quelle ein Fehler aufgetreten ist |
| Bilddatei wurde nicht gefunden | Gibt an, dass die Datei unter dem angegebenen Pfad nicht vorhanden ist |
| Landmark-Image nicht gefunden | Zeigt an, dass das Bild der Landmarke nicht vorhanden ist |
| Text kann im nicht-interaktiven Modus nicht vom Bildschirm abgerufen werden | Zeigt an, dass es im nicht-interaktiven Modus nicht möglich ist, Text vom Bildschirm abzurufen |
| Die OCR-Engine konnte nicht erstellt werden | Zeigt an, dass beim Erstellen der OCR-Engine ein Fehler aufgetreten ist |
| Der Datenpfadordner ist nicht vorhanden | Zeigt an, dass der für die Sprachdaten angegebene Ordner nicht existiert |
| Das ausgewählte Windows Sprachpaket ist nicht auf dem Rechner installiert | Zeigt an, dass das ausgewählte Windows Sprachpaket nicht auf dem Computer installiert ist |
| OCR-Engine nicht aktiv | Zeigt an, dass die OCR-Engine nicht aktiv ist |