Systemeigenes GPU-Zaunobjekt
Dieser Artikel beschreibt das GPU-Zaunsynchronisierungsobjekt, das bei der GPU-zu-GPU-Synchronisierung in Phase 2 der GPU-Hardwareplanung verwendet werden kann. Dieses Feature wird ab Windows 11, Version 24H2 (WDDM 3.2) unterstützt. Grafiktreiberentwickler sollten mit WDDM 2.0 und GPU-Hardwareplanungsphase 1 vertraut sein.
WDDM 2.xs überwachtes Zaunsynchronisierungsobjekt
Das überwachte Zaunsynchronisierungsobjekt von WDDM 2.x unterstützt die folgenden Vorgänge:
- Die CPU wartet auf einen überwachten Zaunwert, entweder durch:
- Abfragen mit einer virtuellen CPU-Adresse (VA).
- Warten Sie eine Blockierung in Dxgkrnl , die signalisiert wird, wenn die CPU den neuen überwachten Zaunwert beobachtet.
- CPU-Signal eines überwachten Werts.
- GPU-Signal eines überwachten Werts durch Schreiben in die überwachte Zaun GPU VA und Auslösen eines überwachten Zauns, der signalisiert wird, um die CPU über die Wertaktualisierung zu benachrichtigen.
Was nicht unterstützt wurde, war eine systemeigene On-the-GPU-Wartezeit auf einen überwachten Zaunwert. Stattdessen funktioniert die gpu des Betriebssystems, die vom gewarteten Wert der CPU abhängt. Sie hat diese Arbeit nur für die GPU freigegeben, wenn der Wert signalisiert wird.
GPU Native Zaunsynchronisierungsobjekt hinzugefügt
Ab WDDM 3.2 wurde das überwachte Zaunobjekt erweitert, um die folgenden hinzugefügten Features zu unterstützen:
- GPU wartet auf einen überwachten Zaunwert, was eine leistungsstarke Engine-zu-Engine-Synchronisierung ohne einen CPU-Roundtrips ermöglicht.
- Benachrichtigung über bedingten Interrupt nur für GPU-Zaunsignale mit CPU-Waitern. Dieses Feature ermöglicht erhebliche Leistungseinsparungen, indem die CPU einen Energiesparzustand erhält, wenn alle GPU-Arbeit in die Warteschlange gestellt wird.
- Zaunwertspeicher im lokalen GPU-Speicher (im Gegensatz zum Systemspeicher).
GPU natives Zaun-Synchronisierungsobjektdesign
Das folgende Diagramm veranschaulicht die grundlegende Architektur eines systemeigenen GPU-Zaunobjekts, wobei sich der Fokus auf den Synchronisierungsobjektstatus befindet, der zwischen der CPU und der GPU gemeinsam genutzt wird.
: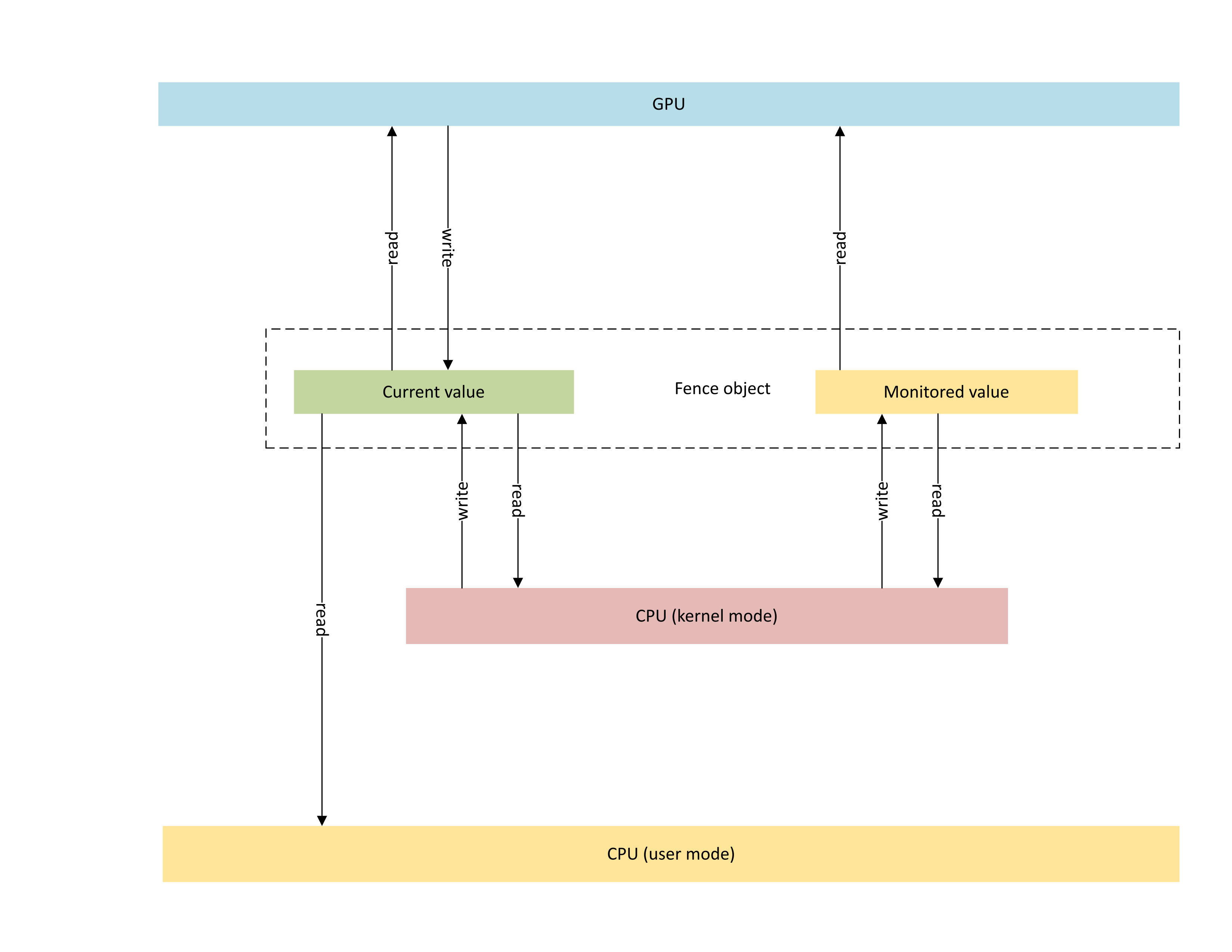
Das Diagramm enthält zwei Standard Komponenten:
Aktueller Wert (in diesem Artikel als CurrentValue bezeichnet). Dieser Speicherspeicherort enthält den aktuell signalisierten 64-Bit-Zaunwert. CurrentValue ist sowohl der CPU zugeordnet als auch zugänglich (schreibbar aus dem Kernelmodus, lesbar vom Benutzer- und Kernelmodus) und GPU (lesbar und schreibbar mithilfe der virtuellen GPU-Adresse). CurrentValue erfordert 64-Bit-Schreibvorgänge, um atomisch sowohl von der CPU als auch vom GPU-Standpunkt zu sein. Das heißt, Aktualisierungen der hohen und niedrigen 32 Bits können nicht abgerissen werden und sollten gleichzeitig sichtbar sein. Dieses Konzept ist bereits im bestehenden überwachten Zaunobjekt vorhanden.
Überwachter Wert (in diesem Artikel als MonitoredValue bezeichnet). Dieser Speicherspeicherort enthält den am wenigsten von der CPU subtrahierten Wert (1). MonitoredValue ist sowohl der CPU zugeordnet als auch zugänglich (lesbar und schreibbar aus dem Kernelmodus, kein Benutzermoduszugriff) und GPU (lesbar mit GPU VA, kein Schreibzugriff). Das Betriebssystem verwaltet die Liste der ausstehenden CPU-Waiter für ein bestimmtes Fence-Objekt und aktualisiert MonitoredValue, wenn Waiter hinzugefügt und entfernt werden. Wenn keine ausstehenden Waiter vorhanden sind, wird der Wert auf UINT64_MAX festgelegt. Dieses Konzept ist neu beim nativen GPU Zaun-Synchronisierungsobjekt.
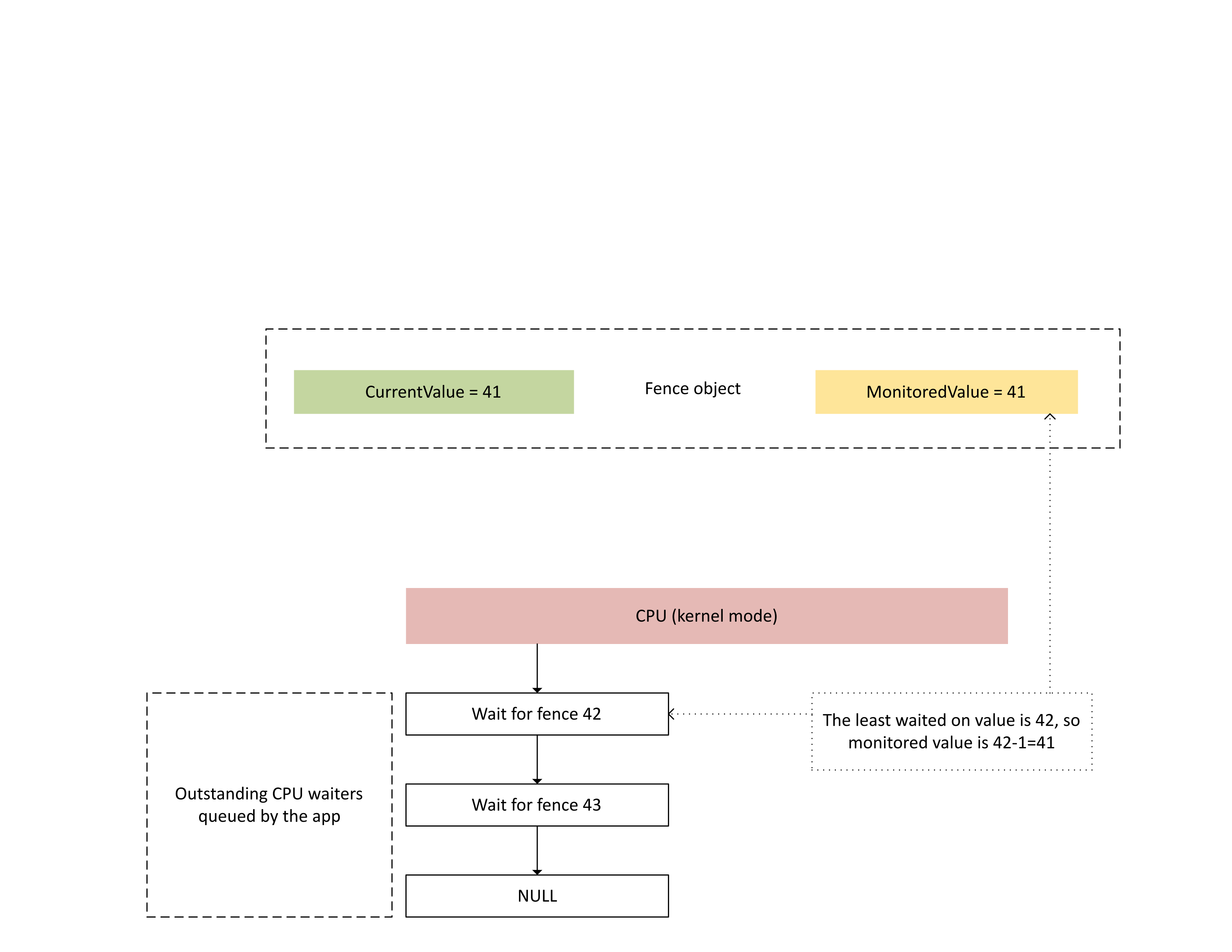
Das nächste Diagramm veranschaulicht, wie Dxgkrnl herausragende CPU-Waiters auf einem bestimmten überwachten Zaunwert verfolgt. Außerdem wird der festgelegte überwachte Zaunwert zu einem bestimmten Zeitpunkt angezeigt. CurrentValue und MonitoredValue sind beide 41, was folgendes bedeutet:
- Die GPU hat alle Aufgaben bis zum Zaunwert 41 abgeschlossen.
- Die CPU wartet nicht auf einen Zaunwert, der kleiner oder gleich 41 ist.
:
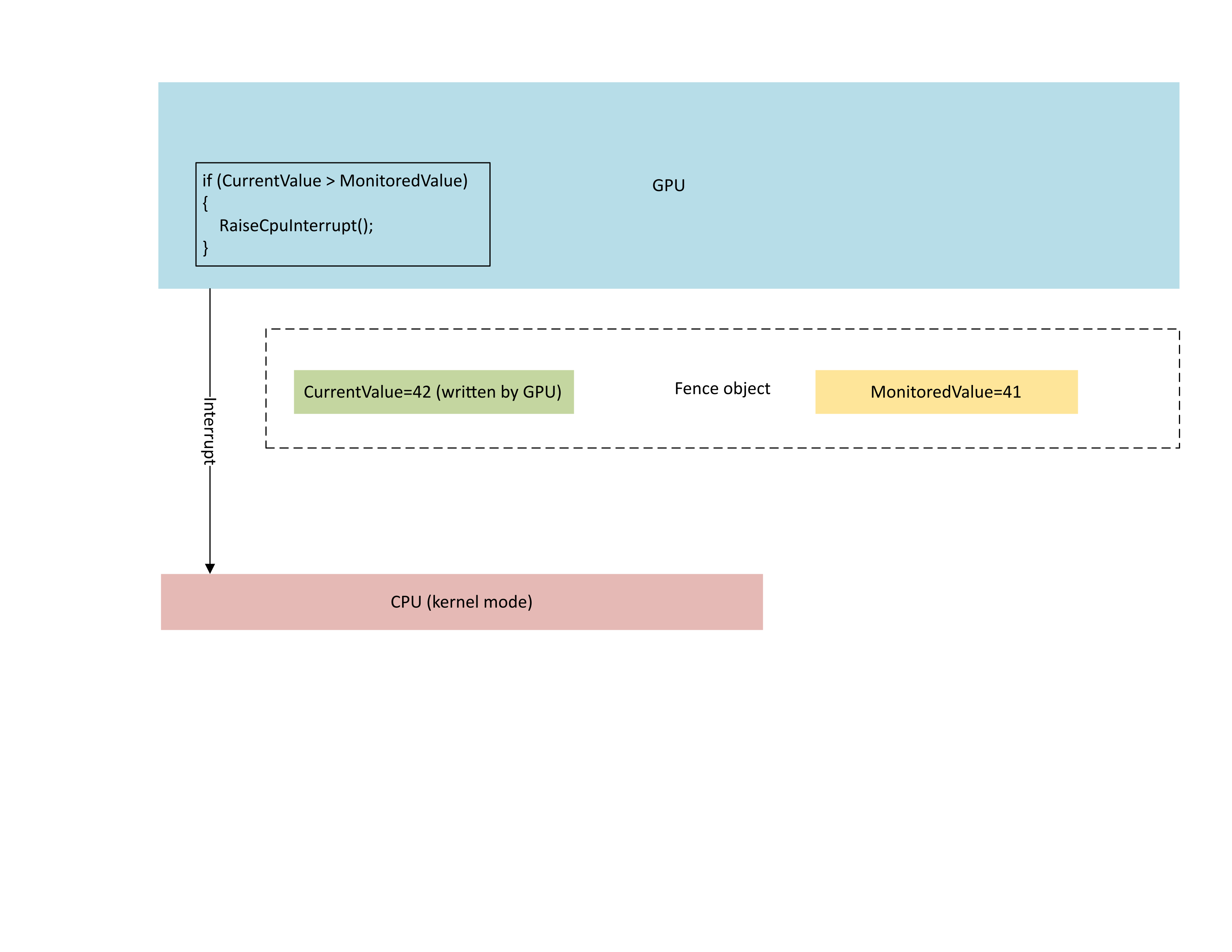
Das folgende Diagramm zeigt, dass der Kontextverwaltungsprozessor (CMP) der GPU bedingt einen CPU-Interrupt auslöst, wenn der neue Zaunwert größer als der überwachte Wert ist. Eine solche Unterbrechung bedeutet, dass es ausstehende CPU-Waiter gibt, die mit dem neu geschriebenen Wert zufrieden sein können.
:
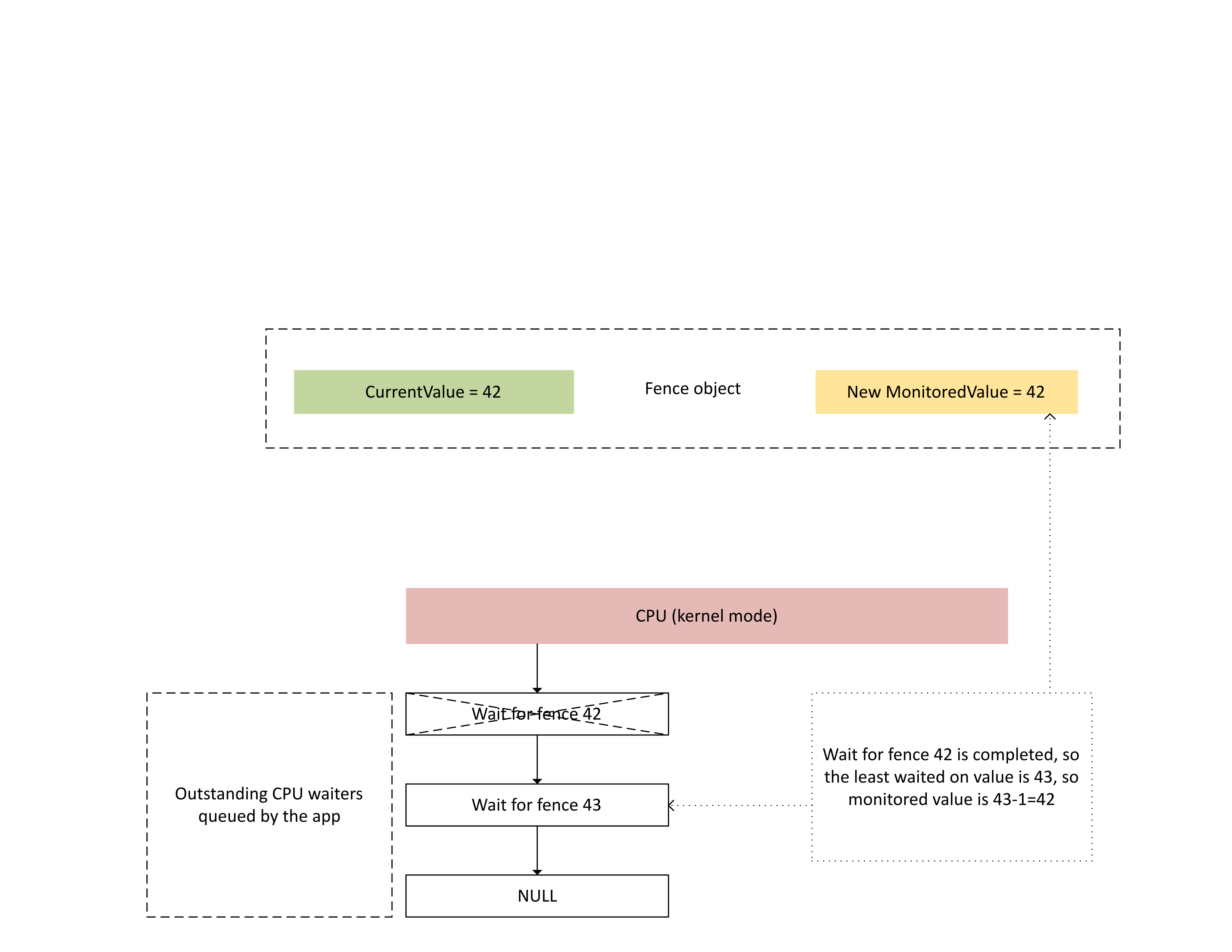
Wenn die CPU diesen Interrupt verarbeitet, führt Dxgkrnl die folgenden Aktionen aus, wie im nächsten Diagramm dargestellt:
- Es entsperrt CPU-Waiter, die mit dem neu geschriebenen Zaun zufrieden waren.
- Er wechselt zum überwachten Wert, um dem am wenigsten ausstehenden Wert zu entsprechen, der von 1 subtrahiert wurde.
:
Physischer Speicher für aktuelle und überwachte Zaunwerte
Für ein bestimmtes Zaunobjekt werden CurrentValue und MonitoredValue an separaten Orten gespeichert.
Zaunobjekte, die nicht freigabefähig sind, haben Zaunwertspeicher für verschiedene Zaunobjekte innerhalb desselben Prozesses, der auf derselben Speicherseite verpackt ist. Die Werte werden gemäß den stride-Werten gepackt, die in den in den nativen Zaun-KMD-Kappen angegeben sind, die weiter unten in diesem Artikel beschrieben werden.
Zaunobjekte, die gemeinsam genutzt werden können, weisen ihre aktuellen und überwachten Werte auf Speicherseiten auf, die nicht mit anderen Zaunobjekten geteilt werden.
Aktueller Wert
Der aktuelle Wert kann sich entweder im Systemspeicher oder im lokalen GPU-Speicher befinden, je nach dem durch D3DDDI_NATIVEFENCE_TYPE angegebenen Zauntyp.
Der aktuelle Wert für adapterübergreifende Zäune befindet sich immer im Systemspeicher.
Wenn der aktuelle Wert im Systemspeicher gespeichert ist, wird speicher aus dem internen Systemspeicherpool zugewiesen.
Wenn der aktuelle Wert im lokalen Speicher gespeichert ist, wird Speicher aus Speichersegmenten zugewiesen, die der in D3DKMDT_FENCESTORAGESURFACEDATA angegebene Treiber hat.
Überwachter Wert
Der überwachte Wert kann je nach D3DDDI_NATIVEFENCE_TYPE auch im system- oder GPU-lokalen Speicher gespeichert werden.
Wenn der überwachte Wert im Systemspeicher gespeichert wird, weist das Betriebssystem Speicher aus dem internen Systemspeicherpool zu.
Wenn der überwachte Wert im lokalen Speicher gespeichert wird, weist das Betriebssystem Speicher aus Speichersegmenten zu, die der in D3DKMDT_FENCESTORAGESURFACEDATA angegebene Treiber hat.
Wenn sich die CPU-Wartezeitbedingungen des Betriebssystems ändern, ruft er den DxgkDdiUpdateMonitoredValues-Rückruf von KMD auf, kmD anzuweisen, den überwachten Wert auf einen angegebenen Wert zu aktualisieren.
Synchronisierungsprobleme
Der zuvor beschriebene Mechanismus verfügt über eine inhärente Racebedingung zwischen CPU und GPU liest und schreibt den aktuellen Wert und den überwachten Wert. Wenn keine besondere Sorgfalt durchgeführt wird, können die folgenden Probleme auftreten:
- Die GPU konnte einen veralteten MonitoredValue lesen und einen Interrupt nicht wie erwartet von der CPU auslösen.
- Ein GPU-Modul könnte einen neueren CurrentValue schreiben, während sich der CMP in der Mitte der Entscheidung für die Unterbrechungsbedingung befindet. Dieser neuere CurrentValue löst die Unterbrechung möglicherweise nicht wie erwartet aus oder ist möglicherweise nicht für die CPU sichtbar, da er den aktuellen Wert abruft.
Synchronisierung innerhalb der GPU zwischen dem Modul und CMP
Aus Effizienzgründen implementieren viele diskrete GPUs die überwachte Zaunsignalsemantik mithilfe des Schattenzustands, der sich im lokalen Speicher der GPU befindet:
Das GPU-Modul, das den Befehlspufferdatenstrom ausführt und bedingt ein Hardwaresignal an den CMP anhebt.
Der GPU-CMP, der entscheidet, ob ein CPU-Interrupt ausgelöst werden soll.
In diesem Fall muss der CMP Speicherzugriff mit dem GPU-Modul synchronisieren, das den Speicherschreibvorgang in den Zaunwert durchführt. Insbesondere sollte der Vorgang der Aktualisierung eines Schattens MonitoredValue aus sicht des CMP sortiert werden:
- Schreiben Sie einen neuen MonitoredValue (Schatten-GPU-Speicher).
- Führen Sie eine Speicherbarriere aus, um den Speicherzugriff mit dem GPU-Modul zu synchronisieren.
- CurrentValue lesen:
- Wenn CurrentValue>MonitoredValue ausgeführt wird, lösen Sie eine CPU-Unterbrechung aus.
- Wenn CurrentValue<= MonitoredValue, lösen Sie die CPU-Unterbrechung nicht aus.
Damit diese Racebedingung ordnungsgemäß aufgelöst werden kann, ist es zwingend erforderlich, dass die Speicherbarriere in Schritt 2 ordnungsgemäß funktioniert. Es darf kein ausstehender Speicherschreibvorgang in CurrentValue in Schritt 3 vorhanden sein, der von einem Befehl stammt, der das MonitoringValue-Update in Schritt 1 nicht gesehen hat. Diese Situation würde einen Interrupt generieren, wenn der in Schritt 3 geschriebene Zaun größer als der in Schritt 1 aktualisierte Wert war.
Synchronisierung zwischen GPU und CPU
Die CPU muss Aktualisierungen von MonitoredValue durchführen und die Lesevorgänge von CurrentValue auf eine Weise durchführen, die keine Unterbrechungsbenachrichtigung für In-Flight-Signale verliert.
- Das Betriebssystem muss MonitoredValue ändern, wenn dem System ein neuer CPU-Waiter hinzugefügt wird oder ein vorhandener CPU-Waiter eingestellt wird.
- Das Betriebssystem ruft DxgkDdiUpdateMonitoredValues auf, um die GPU über einen neuen überwachten Wert zu benachrichtigen.
- DxgkDdiUpdateMonitoredValue wird auf der Unterbrechungsebene des Geräts ausgeführt und wird somit mit der überwachten, signalisierten Unterbrechungs-Dienstroutine (ISR) synchronisiert.
- DxgkDdiUpdateMonitoredValue muss sicherstellen, dass nach dem Zurückgeben von CurrentValue der von jedem Prozessorkern gelesene CurrentValue vom GPU-CMP geschrieben wurde, nachdem der neue MonitoredValue beobachtet wurde.
- Nach der Rückgabe von DxgkDdiUpdateMonitoredValue ändert das Betriebssystem CurrentValue und erfüllt alle Waiter, die vom neuen CurrentValue aufgehoben werden.
Es ist vollkommen akzeptabel, dass die CPU einen neueren CurrentValue beobachtet als der von der GPU verwendete, um zu entscheiden, ob die Unterbrechung erhöht werden soll. Diese Situation würde gelegentlich zu einer Unterbrechungsbenachrichtigung führen, die keine Waiter entsperrt. Was nicht akzeptabel ist, ist, dass die CPU keine Unterbrechungsbenachrichtigung für das zuletzt überwachte CurrentValue empfängt, d.h. CurrentValue>MonitoredValue.)
Abfragen der Aktivierung der systemeigenen Zaunfunktion im Betriebssystem
Treiber müssen abfragen, ob das systemeigene Zaunfeature während der Treiberinitialisierung im Betriebssystem aktiviert ist. Ab WDDM 3.2 verwendet das Betriebssystem die hinzugefügte IsFeatureEnabled-Schnittstelle , um zu steuern, ob bestimmte Features aktiviert sind, einschließlich der systemeigenen Zaunfunktion.
Daher muss KMD die IsFeatureEnabled-Schnittstelle implementieren. Die KMD-Implementierung muss abfragen, ob das Betriebssystem die DXGK_FEATURE_NATIVE_FENCE-Funktion aktiviert hat, bevor die Unterstützung für systemeigene Zaune in DXGK_VIDSCHCAPS angezeigt wird. Das Betriebssystem schlägt die Adapterinitialisierung fehl, wenn KMD die systemeigene Zaununterstützung ankünbt, wenn das Feature vom Betriebssystem nicht aktiviert wurde.
Weitere Informationen zur Featureaktivierungsschnittstelle finden Sie unter "Abfragen von WDDM-Featureunterstützung und -aktivierung".
DDIs zum Abfragen der systemeigenen Zaunfunktionsaktivierung
Die folgenden Schnittstellen werden für einen KMD eingeführt, um abzufragen, ob das Betriebssystem das systemeigene Zaunfeature aktiviert hat:
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
Das Betriebssystem implementiert die hinzugefügte DXGKCB_FEATURE_NATIVEFENCE_CAPS_1-Schnittstellentabelle für Version 1 von DXGK_FEATURE_NATIVE_FENCE. KMD muss diese Featureschnittstellentabelle abfragen, um die Funktionen des Betriebssystems zu ermitteln. In zukünftigen Betriebssystemversionen kann das Betriebssystem zukünftige Versionen dieser Schnittstellentabelle einführen, wobei die Unterstützung für neue Funktionen erläutert wird.
Beispieltreibercode für die Abfrageunterstützung
Im folgenden Beispielcode wird gezeigt, wie Treiber die DXGK_FEATURE_NATIVE_FENCE-Funktion in der DXGK_FEATURE_INTERFACE Schnittstelle zum Abfragen der Unterstützung verwenden sollen.
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
Nativen Zaunfunktionen
Die folgenden Schnittstellen werden aktualisiert oder eingeführt, um systemeigene Zaunkappen abzufragen:
Das Feld NativeGpuFence wird DXGK_VIDSCHCAPS hinzugefügt. Wenn das Betriebssystem die Funktion DXGK_FEATURE_NATIVE_FENCE aktiviert hat, kann der Treiber während der Adapterinitialisierung die Unterstützung für die native GPU-Fence-Funktionalität deklarieren, indem er das Bit DXGK_VIDSCHCAPS::NativeGpuFence auf 1 setzt.
DXGKQAITYPE_NATIVE_FENCE_CAPS wird DXGK_QUERYADAPTERINFOTYPE hinzugefügt.
Dxgkrnl macht dieses Feature über die hinzugefügte entsprechende D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported-Struktur /Bit für den Benutzermodus verfügbar.
KMTQAITYPE_WDDM_3_1_CAPS wird zu KMTQUERYADAPTERINFOTYPE hinzugefügt.
Die folgenden Entitäten werden für einen KMD hinzugefügt, um die Unterstützungsfunktionen für die systemeigene GPU-Zaunfunktion anzugeben.
Die DXGK_NATIVE_FENCE_CAPS-Struktur beschreibt die systemeigenen Zaunfunktionen der GPU. Wenn KMD das Bit MapToGpuSystemProcess dieser Struktur setzt, weist es das Betriebssystem an, einen virtuellen GPU-Adressraum des Systemprozesses für die CMP-Verwendung zu reservieren und in diesem Adressraum GPU-VA-Zuordnungen für die systemeigenen Zäune CurrentValue und MonitoredValue zu erstellen. Diese GPU-VAs werden später zum Callback zur Zaunerstellung von KMDDXGKARG_CREATENATIVEFENCE,::CurrentValueSystemProcessGpuVa und MonitoredValueSystemProcessGpuVaübergeben.
KMD gibt seine ausgefüllteDXGK_NATIVE_FENCE_CAPS Struktur zurück, wenn seine Funktion DxgkDdiQueryAdapterInfo mit dem hinzugefügten Abfrageadapter-Infotyp DXGKQAITYPE_NATIVE_FENCE_CAPS aufgerufen wird.
KMD-DDIs zum Erstellen, Öffnen, Schließen und Zerstören eines nativen Zaunobjekts
Die folgenden KMD-implementierten DDIs werden eingeführt, um ein systemeigenes Zaunobjekt zu erstellen, zu öffnen, zu schließen und zu zerstören. Dxgkrnl ruft diese DDIs im Namen von Benutzermoduskomponenten auf. Dxgkrnl ruft sie nur auf, wenn das DXGK_FEATURE_NATIVE_FENCE-Feature vom Betriebssystem aktiviert wurde .
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
Die folgenden DDIs wurden aktualisiert, um systemeigene Zaunobjekte zu unterstützen:
Die folgenden Mitglieder wurden DRIVER_INITIALIZATION_DATA hinzugefügt. Treiber, die native GPU-Zaunobjekte unterstützen, sollten die Funktionen implementieren und Dxgkrnl über diese Struktur mit Zeigern darauf bereitstellen.
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (hinzugefügt in WDDM 3.1)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (hinzugefügt in WDDM 3.1)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (hinzugefügt in WDDM 3.2)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (hinzugefügt in WDDM 3.2)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (hinzugefügt in WDDM 3.2)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (hinzugefügt in WDDM 3.2)
Globale und lokale Handles für gemeinsam genutzte Zaune
Stellen Sie sich vor, Prozess A erstellt einen gemeinsamen nativen Zaun und Prozess B später öffnet diesen Zaun.
Wenn Prozess A den gemeinsam genutzten nativen Zaun erstellt, ruftDxgkrnl DxgkDdiCreateNativeFence mit dem Adaptertreiber-Handle auf, auf dem dieser Zaun erstellt wird. Der in hGlobalNativeFence erstellte und zurückgegebene Zaun-Handle ist der globale Zaun-Handle.
Dxgkrnl folgt anschließend mit einem Aufruf von DxgkDdiOpenNativeFence, um das spezifische lokale Handle von A (hLocalNativeFenceA) zu öffnen.
Wenn Prozess B denselben gemeinsam genutzten nativen Zaun öffnet, ruft Dxgkrnl DxgkDdiOpenNativeFence auf, um einen Prozess-B-spezifischen lokalen Handle (hLocalNativeFenceB) zu öffnen.
Wenn Prozess A seine gemeinsam genutzte native Fence-Instanz zerstört, erkennt Dxgkrnl, dass noch ein ausstehender Verweis auf diesen globalen Zaun vorhanden ist, und ruft daher nur DxgkDdiCloseNativeFence(hLocalNativeFenceA) auf, damit der Treiber die Prozess-A-spezifischen Strukturen bereinigt. Das hGlobalNativeFence-Handle ist noch vorhanden.
Wenn Prozess B seine Fence-Instanz zerstört, ruft Dxgkrnl DxgkDdiCloseNativeFence(hLocalNativeFenceB) auf und dann DxgkDdiDestroyNativeFence(hGlobalNativeFence) auf, um KMD die Zerstörung seiner globalen Fence-Daten zu ermöglichen.
GPU VA-Zuordnungen im Adressraum des Pagingprozesses für die CMP-Verwendung
Die KMD legt die DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess-Begrenzung auf Hardware fest, für die systemeigene GPU-GPU-VAs ebenfalls dem Adressraum des GPU-Pagingprozesses zugeordnet werden müssen. Ein gesetztes Bit MapToGpuSystemProcess weist das Betriebssystem an, GPU-VA-Zuordnungen im Adressraum des Paging-Prozesses für den CurrentValue und MonitoredValue des nativen Zauns zur Verwendung durch den CMP zu erstellen. Diese GPU-VAs werden später an DxgkDdiCreateNativeFence als DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa und MonitoredValueSystemProcessGpuVa übergeben.
D3DKMT-Kernel-APIs zum Erstellen, Öffnen und Zerstören von systemeigenen Zaunen
Die folgenden D3DKMT-Kernelmodus-APIs werden eingeführt, um ein natives Zaunobjekt zu erstellen und zu öffnen.
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl ruft die vorhandene D3DKMTDestroySynchronizationObject-Funktion auf, um ein vorhandenes systemeigenes Zaunobjekt zu schließen und zu zerstören (frei).
Unterstützungsstrukturen und Enumerationen, die eingeführt oder aktualisiert werden, umfassen:
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
DDI zur Unterstützung der Platzierung von systemeigenen Zaunwerten im lokalen Speicher
Die folgenden DDIs wurden hinzugefügt oder geändert, um die Platzierung systemeigener Zaunwerte im lokalen Speicher zu unterstützen:
Die D3DKMDT_FENCESTORAGESURFACEDATA Struktur wird hinzugefügt.
Der systemeigene Zaun MonitoredValue und CurrentValue des systemeigenen Zauntyps D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU können im lokalen Gerätespeicher platziert werden. Dazu fordert das Betriebssystem den Treiber auf, Speichersegmente anzugeben, in denen der Zaunspeicher platziert werden soll. DxgkDdiGetStandardAllocation wird erweitert, um solche Informationen bereitzustellen.
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE wird DXGKARG_GETSTANDARDALLOCATIONDRIVERDATA hinzugefügt.
Angeben eines systemeigenen Statuszauns für Hardwarewarteschlangen
Das folgende Update wird eingeführt, um ein natives Hardwarewarteschlangenstatus-Zaunobjekt anzugeben:
Für die Anrufe von NativeProgressFence wird ein DxgkDdiCreateHwQueue-Flag hinzugefügt..
- Auf unterstützten Systemen aktualisiert das Betriebssystem den Statuszaun der Hardwarewarteschlange auf einen systemeigenen Zaun. Wenn das Betriebssystem NativeProgressFence festlegt, zeigt es KMD an, dass der Handle DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence auf den Treiber-Handle eines nativen GPU-Fence-Objekts verweist, das zuvor mit DxgkDdiCreateNativeFence erstellt wurde.
Nativer Zaun signalisierte Unterbrechung
Die folgenden Änderungen werden am Unterbrechungsmechanismus vorgenommen, um einen systemeigenen, signalisierten Interrupt zu unterstützen:
Die DXGK_INTERRUPT_TYPE Enumeration wird aktualisiert, um einen DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED Interrupttyp zu haben.
Die DXGKARGCB_NOTIFY_INTERRUPT_DATA-Struktur wird aktualisiert, um eine NativeFenceSignaled-Struktur einzuschließen, um einen systemeigenen Signalunterbruch zu kennzeichnen.
NativeFenceSignaled wird verwendet, um das Betriebssystem darüber zu informieren, dass eine Reihe systemeigener GPU-Objekte, die von der CPU überwacht werden, auf einem GPU-Modul signalisiert wurden. Wenn die GPU die genaue Teilmenge von Objekten mit aktiven CPU-Waitern ermitteln kann, übergibt sie diese Teilmenge über pSignaledNativeFenceArray. Die Handles in diesem Array müssen gültige hGlobalNativeFence Handles sein, die Dxgkrnl in DxgkDdiCreateNativeFence an KDM übergeben hat. Das Übergeben eines Handles an ein zerstörtes natives Zaunobjekt führt zu einer Fehlerüberprüfung.
Die DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS Struktur wird aktualisiert, um ein EvaluateLegacyMonitoredFences-Element einzuschließen .
Die GPU kann unter den folgenden Bedingungen ein NULL pSignaledNativeFenceArray übergeben:
- Die GPU kann die genaue Teilmenge von Objekten mit aktiven CPU-Waitern nicht ermitteln.
- Mehrere Signalunterbrechungen werden zusammen reduziert, sodass es schwierig ist, den signalierten Satz mit aktiven Waitern zu ermitteln.
Ein NULL-Wert weist das Betriebssystem an, alle ausstehenden nativen GPU-Zaunobjekt-Waiter zu scannen.
Der Vertrag zwischen Betriebssystem und Treiber lautet: Wenn das Betriebssystem über einen aktiven CPU-Waiter (wie von MonitoredValue ausgedrückt) verfügt und das GPU-Modul das Objekt auf den Wert signalisiert hat, der eine CPU-Unterbrechung erfordert, muss die GPU eine der folgenden Aktionen ausführen:
- Fügen Sie diesen nativen Zaun-Handle in das pSignaledNativeFenceArray ein.
- Auslösen eines NativeFenceSignaled unterbricht mit einem NULL pSignaledNativeFenceArray.
Wenn KMD diesen Interrupt mit einem NULL pSignaledNativeFenceArray auslöst, überprüft Dxgkrnl standardmäßig nur alle ausstehenden nativen Zaun-Waiter und scannt keine älteren überwachten Zaun-Waiter. Auf Hardware, die nicht zwischen den älteren DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED und DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED unterscheiden kann, kann das KMD immer nur den eingeführten Interrupt DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED mit pSignaledNativeFenceArray = NULL und EvaluateLegacyMonitoredFences = 1 auslösen, was dem Betriebssystem anzeigt, dass alle Waiter (Legacy Monitored Fence Waiter & Native Fence Waiter) gescannt werden sollen.
Anweisen von KMD zum Aktualisieren von Batches von Werten
Die folgende Schnittstelle wird eingeführt, um KMD anzuweisen, einen Batch aktueller oder überwachter Werte zu aktualisieren:
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
Systemübergreifende Zäune
Das Betriebssystem muss das Erstellen systemübergreifender Zäune unterstützen, da vorhandene DX12-Apps überwachte Zäune erstellen und verwenden. Wenn zugrunde liegende Warteschlangen und Planungen für diese Apps auf die Übermittlung im Benutzermodus umgestellt werden, müssen ihre überwachten Zäune auch auf systemeigene Zäune umgestellt werden (Benutzermoduswarteschlangen können überwachte Zäune nicht unterstützen).
Es muss ein adapterübergreifender Zaun mit dem Typ D3DDDI_NATIVEFENCE_TYPE_DEFAULT erstellt werden. Andernfalls schlägt D3DKMTCreateNativeFence fehl.
Alle GPUs verwenden dieselbe Kopie des CurrentValue-Speichers , die immer im Systemspeicher zugeordnet ist. Wenn die Laufzeit einen systemübergreifenden Adapterzaun auf GPU1 erstellt und auf GPU2 öffnet, verweisen die GPU VA-Zuordnungen auf beide GPUs auf denselben physischen CurrentValue-Speicher .
Jede GPU erhält eine eigene Kopie von MonitoredValue. Daher kann der MonitoredValue im Systemspeicher oder im lokalen Speicher zugeordnet werden.
Systemübergreifende Zäune müssen die Bedingung auflösen, in der GPU1 auf einen systemeigenen Zaun wartet, den GPU2 signalisiert. Heute gibt es kein Konzept von GPU-zu-GPU-Signalen; Daher löst das Betriebssystem diese Bedingung explizit durch Signalisieren von GPU1 aus der CPU auf. Diese Signalisierung erfolgt durch Festlegen von MonitoredValue für den adapterübergreifenden Zaun auf 0 für die Lebensdauer. Wenn GPU2 dann den nativen Zaun signalisiert, löst es auch einen CPU-Interrupt aus, wodurch Dxgkrnl CurrentValue auf GPU1 aktualisieren (mit DxgkDdiUpdateCurrentValuesFromCpu mit dem Flag NotificationOnly nd alle ausstehenden CPU/GPU-Waiter dieser GPU entsperren kann.
Obwohl MonitoredValue immer 0 für systemeigene Adapterzäune ist, profitieren Wartezeiten und Signale, die auf derselben GPU übermittelt werden, immer noch von schnellerer GPU-Synchronisierung. Der Leistungsvorteil reduzierter CPU-Interrupts geht jedoch verloren, da CPU-Unterbrechungen bedingungslos ausgelöst werden, auch wenn es keine CPU-Waiter oder Waiter auf der anderen GPU gab. Dieser Kompromiss wird gemacht, um die Design- und Implementierungskosten des systemübergreifenden Zauns einfach zu halten.
Das Betriebssystem unterstützt das Szenario, in dem ein systemeigenes Zaunobjekt auf GPU1 erstellt und auf GPU2 geöffnet wird, in dem GPU1 das Feature unterstützt und GPU2 nicht. Das Zaunobjekt wird als regulärer MonitoredFence auf GPU2 geöffnet.
Das Betriebssystem unterstützt das Szenario, in dem ein reguläres überwachtes Zaunobjekt auf GPU1 erstellt und als systemeigener Zaun auf GPU2 geöffnet wird, der das Feature unterstützt. Das Zaunobjekt wird als nativer Zaun auf GPU2 geöffnet.
Adapterübergreifender Wait/Signal-Kombinationen
Die Tabellen in den folgenden Unterabschnitten weisen ein Beispiel für ein iGPU- und dGPU-System auf und listen die verschiedenen Konfigurationen auf, die für systemeigene Zaunwartewait-/Signale aus der CPU/GPU möglich sind. Die folgenden beiden Fälle werden berücksichtigt:
- Beide GPUs unterstützen native Zäune.
- Die iGPU unterstützt keine nativen Zäune, aber die dGPU unterstützt native Zäune.
Das zweite Szenario ähnelt auch dem Fall, in dem beide GPUs native Zäune unterstützen, aber native Zaun-Warte-/Signal wird an eine Kernelmoduswarteschlange auf der iGPU übermittelt.
Die Tabellen sollten gelesen werden, indem ein Warte- und Signalpaar aus den Spalten ausgewählt wird, zum Beispiel WaitFromGPU – SignalFromGPU oder WaitFromGPU – SignalFromCPU usw.
Szenario 1
In Szenario 1 unterstützen sowohl dGPU als auch iGPU native Zäune.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| UMD fügt eine Wartezeit auf hfence CurrentValue == 10 Anweisung im Befehlspuffer ein | Laufzeitaufrufe D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch verfolgt dieses Synchronisierungsobjekt in seiner nativen Zaun-CPU-Warteliste | |||
| UMD fügt eine schreibgeschützte hFence CurrentValue = 10 Signalanweisung in den Befehlspuffer ein. | Laufzeitaufrufe D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch empfängt einen systemeigenen Zaun signalisiert ISR, wenn CurrentValue geschrieben wird (weil MonitoredValue == 0 immer) | VidSch ruft DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) auf | ||
| VidSch verteilt das Signal (hFence, 10) an die iGPU | VidSch verteilt das Signal (hFence, 10) an die iGPU | ||
| VidSch empfängt das verteilte Signal und ruft DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) auf | VidSch empfängt das verteilte Signal und ruft DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) auf | ||
| KMD überprüft die Ausführungsliste erneut, um die Blockierung des HW-Kanals auf hFence aufzuheben. | VidSch entsperrt die CPU-Wartebedingung durch Signalisieren des KEVENT |
Szenario 2a
In Szenario 2a unterstützt die iGPU keine nativen Zäune, sondern die dGPU. An der iGPU wird eine Wait übermittelt, und auf der dGPU wird ein Signal übermittelt.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| Runtime calls D3DKMTWaitForSynchronizationObjectFromGpu | Laufzeitaufrufe D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch verfolgt dieses Synchronisierungsobjekt in seiner überwachten Zaunwarteliste | VidSch verfolgt dieses Synchronisierungsobjekt in seinem überwachten Zaun CPU Waiter List Head | ||
| UMD fügt eine schreibgeschützte hFence CurrentValue = 10 Signalanweisung in den Befehlspuffer ein | Laufzeitaufrufe D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch empfängt NativeFenceSignaledISR, wenn CurrentValue geschrieben wird (weil MV == 0 immer) | VidSch ruft DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) auf | ||
| VidSch verteilt das Signal (hFence, 10) an die iGPU | VidSch verteilt das Signal (hFence, 10) an die iGPU | ||
| VidSch empfängt das verteilte Signal und beobachtet neuen Zaunwert. | VidSch empfängt das verteilte Signal und beobachtet neuen Zaunwert. | ||
| VidSch scannt seine überwachte Zaunwarteliste und entsperrt Softwarekontexte | VidSch scannt den überwachten Zaun CPU Waiter List Head und entsperrt CPU-Wartezeit durch Signalisieren des KEVENT |
Szenario 2b
In Szenario 2b bleibt die native Zaun-Unterstützung gleich (iGPU unterstützt sie nicht, dGPU schon). Dieses Mal wird ein Signal an die iGPU und eine Wartezeit an die dGPU übermittelt.
| iGPU SignalFromGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGPU (hFence, 10) | dGPU WaitFromCPU (hFence, 10) |
|---|---|---|---|
| UMD fügt eine Wartezeit auf hfence CurrentValue == 10 Anweisung im Befehlspuffer ein | Laufzeitaufrufe D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch verfolgt dieses Synchronisierungsobjekt in seiner nativen Zaun-CPU-Warteliste | |||
| UMD ruft D3DKMTSignalSynchronizationObjectFromGpu auf | UMD ruft D3DKMTSignalSynchronizationObjectFromCpu auf | ||
| Wenn sich das Paket an der Spitze des Softwarekontexts befindet, aktualisiert VidSch den Zaunwert direkt von der CPU. | VidSch aktualisiert den Zaunwert direkt von der CPU | ||
| VidSch verteilt das Signal (hFence, 10) an die dGPU | VidSch verteilt das Signal (hFence, 10) an die dGPU | ||
| VidSch empfängt das verteilte Signal und ruft DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) auf | VidSch empfängt das verteilte Signal und ruft DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) auf | ||
| KMD überprüft die Ausführungsliste erneut, um die Blockierung des HW-Kanals auf hFence aufzuheben. | VidSch entsperrt die CPU-Wartebedingung durch Signalisieren des KEVENT |
Zukünftiges GPU-zu-GPU-Kreuzadaptersignal
Wie in Synchronisierungsproblemen beschrieben, verlieren wir bei systemübergreifenden Zäunen stromsparend, da ein CPU-Interrupt bedingungslos ausgelöst wird.
In einer zukünftigen Version wird das Betriebssystem eine Infrastruktur entwickeln, die es einem GPU-Signal auf einer GPU ermöglicht, andere GPUs zu unterbrechen, indem es in einen gemeinsamen Türklingelspeicher schreibt, wodurch andere GPUs aufgeweckt werden, ihre Run-Liste verarbeiten und bereite HW-Warteschlangen entsperren können.
Die Herausforderung für diese Arbeit besteht in der Gestaltung:
- Die gemeinsame Türglocken-Erinnerung.
- Eine intelligente Nutzlast oder ein Handle, den eine GPU an die Türklingel schreiben kann, damit andere GPUs bestimmen können, welcher Zaun signalisiert wurde, sodass nur eine Teilmenge der HWQueues gescannt werden kann.
Mit einem solchen Kreuzadapter-Signal wäre es für GPUs möglicherweise sogar möglich, dieselbe Kopie des nativen Zaun-Speichers gemeinsam zu nutzen (eine Cross-Adapter-Zuweisung im linearen Format, ähnlich den Kreuzadapter-Scan-Out-Zuweisungen), aus der alle GPUs lesen und in die sie schreiben.
Systemeigenes Zaunprotokollpufferdesign
Bei nativen Zäunen und der Übermittlung im Benutzermodus hat Dxgkrnl keine Sichtbarkeit, wenn systemeigene GPU wartet und Signale, die von UMD abgefragt werden, für eine bestimmte HWQueue entsperrt werden. Mit nativen Zäunen könnte ein überwachter Zaun signalisierter Interrupt für einen bestimmten Zaun unterdrückt werden.
:
Eine Möglichkeit, die Zaunvorgänge wie in diesem GPUView-Image dargestellt neu zu erstellen, ist erforderlich. Die dunklen rosa Kästchen sind Signale und hell rosa Kästchen werden gewartet sind waits. Jedes Feld beginnt, als der Vorgang auf der CPU an Dxgkrnl übermittelt wurde, und endet, wenn Dxgkrnl den Vorgang auf der CPU beendet. Auf diese Weise können wir die gesamte Lebensdauer eines Befehls untersuchen.
Auf hoher Ebene sind also die zu protokollierenden Bedingungen pro HWQueue:
| Bedingung | Bedeutung |
|---|---|
| FENCE_WAIT_QUEUED | CPU-Zeitstempel, wenn die UMD eine GPU-Wait-Anweisung in die Befehlswarteschlange einfügt |
| FENCE_SIGNAL_QUEUED | CPU-Zeitstempel, wenn die UMD eine GPU-Signalanweisung in die Befehlswarteschlange einfügt |
| FENCE_SIGNAL_EXECUTED | GPU-Zeitstempel, wenn ein Signalbefehl auf GPU für eine HWQueue ausgeführt wird |
| FENCE_WAIT_UNBLOCKED | GPU-Zeitstempel, wenn eine Wartebedingung für GPU erfüllt ist und die HWQueue entblockt wird |
Systemeigene Zaunprotokollpuffer-DDIs
Die folgenden DDI, Strukturen und Enumerationen werden eingeführt, um systemeigene Zaunprotokollpuffer zu unterstützen:
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- Ein Protokollpuffer, der einen Header und ein Array von Protokolleinträgen enthält. Der Header gibt an, ob die Einträge für eine Wartezeit oder ein Signal gelten, und jeder Eintrag identifiziert den Typ des Vorgangs (ausgeführt oder entsperrt):
Das Protokollpufferdesign ist für systemeigene Zaun- und Benutzermodus-Übermittlungswarteschlangen gedacht, bei denen die Protokollpuffernutzlast vom GPU-Modul/CMP ohne Beteiligung von Dxgkrnl oder KMD geschrieben wird. Daher fügt UMD beim Generieren des Warte-/Signalbefehlspuffers eine Anweisung ein, wobei die GPU die Protokollpuffernutzlast in den Protokollpuffereintrag bei der Ausführung schreibt. Bei der Übermittlung im Nicht-Benutzermodus (d. h. Kernelmoduswarteschlangen) handelt es sich bei den Warte- und Signalen um Softwarebefehle innerhalb von Dxgkrnl, sodass wir bereits die Zeitstempel und andere Details dieser Vorgänge kennen und keine Hardware/KMD zum Aktualisieren des Protokollpuffers benötigen. Für solche Kernelmoduswarteschlangen erstellt Dxgkrnl keinen Protokollpuffer.
Protokollpuffermechanismus
Dxgkrnl weist zwei dedizierte 4-KB-Protokollpuffer pro HWQueue zu.
- Eine für die Protokollierung-Waits.
- Eines zum Protokollieren von Signalen.
Diese Protokollpuffer verfügen über Zuordnungen für die Kernelmodus CPU VA (LogBufferCpuVa), eine GPU VA im Prozessadressraum (LogBufferGpuVa) und die CMP VA (LogBufferSystemProcessGpuVa), sodass sie kmD, das GPU-Modul und CMP lesen/schreiben können. Dxgkrnl ruft DxgkDdiSetNativeFenceLogBuffer zweimal auf: : einmal, um den Protokollpuffer für die Protokollierung zu warten und einmal festzulegen, um den Protokollpuffer für Protokollierungssignale festzulegen.
Unmittelbar nachdem UMD eine systemeigene Zaunwait- oder Signalanweisung in die Befehlsliste eingefügt hat, fügt sie auch einen Befehl ein, der die GPU anweist, eine Payload bei einem bestimmten Eintrag in den Protokollpuffer zu schreiben.
Nachdem das GPU-Modul den Zaunvorgang ausgeführt hat, wird die UMD-Anweisung zum Schreiben einer Payload in einen bestimmten Eintrag in den Protokollpuffer angezeigt. Darüber hinaus schreibt die GPU auch den aktuellen FenceEndGpuTimestamp in diesen Protokollpuffereintrag.
Während die UMD nicht auf den GPU-Barrierefreiheitsprotokollpuffer zugreifen kann, steuert sie den Fortschritt des Protokollpuffers. Das heißt, UMD ermittelt den nächsten freien Eintrag zum Beschreiben (sofern vorhanden) und programmiert die GPU mit dieser Information. Wenn die GPU in den Protokollpuffer schreibt, erhöht sie den FirstFreeEntryIndex-Wert im Protokollheader. UMD muss sicherstellen, dass Schreibvorgänge in Protokolleinträge monoton steigen.
Nehmen Sie das folgende Szenario als Beispiel:
- Es gibt zwei HWQueues, HWQueueA und HWQueueB mit entsprechenden Zaunprotokollpuffern mit GPU-VAs von FenceLogA und FenceLogB. HWQueueA ist dem Protokollpuffer für Protokollierungswartezeiten zugeordnet, und HWQueueB ist dem Protokollpuffer für Protokollierungssignale zugeordnet.
- Es gibt ein systemeigenes Zaunobjekt mit einem Benutzermodus-D3DKMT_HANDLE von FenceF.
- Eine CPU-Wait auf FenceF für Wert V1 ist in der Warteschlange HWQueueA zum Zeitpunkt CPUT1. Wenn UMD den Befehlspuffer erstellt, wird ein Befehl eingefügt, der die GPU anweist, die Payload zu protokollieren: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED).
- Ein GPU-Signal an FenceF mit dem Wert V1 wird in die Warteschlange HWQueueB zum Zeitpunkt CPUT2 eingereiht. Wenn UMD den Befehlspuffer erstellt, wird ein Befehl eingefügt, der die GPU anweist, die Payload zu protokollieren: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED).
Nachdem der GPU-Scheduler das GPU-Signal auf HWQueueB zur GPU-Zeit GPUT1 ausgeführt hat, liest er die UMD-Payload und protokolliert das Ereignis im vom Betriebssystem bereitgestellten Zaunprotokoll für HWQueueB:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
Nachdem der GPU-Scheduler feststellt, dass HWQueueA zur GPU-Zeit GPUT2 entsperrt ist, liest er die UMD-Nutzlast und protokolliert das Ereignis im vom Betriebssystem bereitgestellten Fence-Protokoll für HWQueueA:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl kann einen Protokollpuffer zerstören und neu erstellen. Jedes Mal, wenn dies geschieht, ruft es DxgkDdiSetNativeFenceLogBuffer auf, um KMD über den neuen Standort zu informieren.
CPU-Zeitstempel von Zaunwarteschlangenvorgängen
Es gibt wenig Vorteile, um das UMD-Protokoll zu diesen CPU-Zeitstempeln zu machen, da:
- Eine Befehlsliste mehrere Minuten vor der GPU-Ausführung eines Befehlspuffers aufgezeichnet werden kann, der die Befehlsliste enthält.
- Diese mehrere Minuten mit anderen Synchronisierungsobjekten, die sich im gleichen Befehlspuffer befinden, nicht ordnungsgemäß ausgeführt werden können.
Es gibt Kosten für die Einbeziehung der CPU-Zeitstempel in UMD-Anweisungen zum GPU-geschriebenen Protokollpuffer, sodass CPU-Zeitstempel nicht in die Protokolleintragsnutzlast einbezogen werden.
Stattdessen kann die Laufzeit oder UMD ein systemeigenes ETW-Ereignis mit Zaunwarteschlange mit dem CPU-Zeitstempel ausgeben, wenn eine Befehlsliste aufgezeichnet wird. Tools können somit eine Zeitleiste von Zaunwarteschlangen- und abgeschlossenen Ereignissen erstellen, indem der CPU-Zeitstempel aus diesem neuen Ereignis und dem GPU-Zeitstempel aus dem Protokollpuffereintrag kombiniert wird.
Reihenfolge der Vorgänge auf GPU beim Signalisieren oder Aufheben der Blockierung eines Zauns
Die UMD muss sicherstellen, dass sie die folgende Reihenfolge Standard, wenn sie eine Befehlsliste erstellt, in der die GPU angewiesen wird, einen Zaun zu signalisieren/zu entsperren:
- Schreiben Sie den neuen Zaunwert in den GPU VA/CMP VA.
- Schreiben Sie die Protokollüayload in den entsprechenden Protokollpuffer GPU VA/CMP VA.
- Erhöhen Sie bei Bedarf einen durch einen nativen Zaun signalisierten Interrupt.
Diese Reihenfolge der Vorgänge stellt sicher, dass Dxgkrnl die neuesten Protokolleinträge sieht, wenn der Interrupt an das Betriebssystem ausgelöst wird.
Protokollpufferüberschreibung ist zulässig
Die GPU kann den Protokollpuffer überschreiben, indem Einträge überschrieben werden, die noch nicht vom Betriebssystem angezeigt werden. Dies geschieht durch inkrementieren des WraparoundCount.
Wenn das Betriebssystem das Protokoll schließlich liest, kann es erkennen, dass ein Überschreiben aufgetreten ist, indem der neue WraparoundCount-Wert im Protokollheader mit seinem zwischengespeicherten Wert verglichen wird. Wenn ein Überschreiben aufgetreten ist, weist das Betriebssystem die folgenden Fallbackoptionen auf:
- Zum Aufheben der Blockierung von Zäunen, wenn ein Überschreiben auftritt, überprüft das Betriebssystem alle Zäune und bestimmt, welche Waiters entsperrt wurden.
- Wenn die Ablaufverfolgung aktiviert wurde, kann das Betriebssystem eine Kennzeichnung in der Ablaufverfolgung ausgeben, um einen Benutzer darüber zu informieren, dass Ereignisse verloren gegangen sind. Wenn die Ablaufverfolgung aktiviert ist, erhöht das Betriebssystem zunächst die Größe des Protokollpuffers, um Überschreibungen an erster Stelle zu verhindern.
Es ist nicht erforderlich, dass UMD die Unterstützung des Rückdrucks implementiert, während die Protokollpuffereinträge ausgeführt werden.
Leerer oder wiederholter Protokollpuffer-Zeitstempel
In gängigen Fällen erwartet Dxgkrnl, dass Zeitstempel in Protokolleinträgen monotonisch steigen. Es gibt jedoch Szenarien, in denen die Zeitstempel der nachfolgenden Protokolleinträge null oder identisch mit vorherigen Protokolleinträgen sind.
In einem Szenario mit verknüpften Displayadaptern kann z. B. einer der verketteten Adapter in der LDA den Zaunschreibvorgang überspringen. In diesem Fall weist der Protokollpuffereintrag einen Nullzeitstempel auf. Dxgkrnl behandelt einen solchen Fall. Dxgkrnl erwartet jedoch nie, dass der Zeitstempel eines angegebenen Protokolleintrags kleiner als der des vorherigen Protokolleintrags ist. Das heißt, Zeitstempel können niemals rückwärts gehen.
Synchrones Aktualisieren des systemeigenen Zaunprotokolls
GPU-Schreibvorgänge zum Aktualisieren des Zaunwerts und des entsprechenden Protokollpuffers müssen sicherstellen, dass Schreibvorgänge vollständig vor CPU-Lesevorgängen verteilt werden. Diese Anforderung erfordert die Verwendung von Speicherbarrieren. Zum Beispiel:
- Signalzaun(N): Schreiben Sie N als neuen aktuellen Wert.
- Schreiben des LOG-Eintrags einschließlich GPU-Zeitstempel
- MemoryBarrier
- Inkrementierung FirstFreeEntryIndex
- MemoryBarrier
- Überwachter Zaununterbruch (N): Lesen Sie die Adresse "M", und vergleichen Sie den Wert mit N , um zu entscheiden, ob der CPU-Interrupt bereitgestellt wird.
Es ist zu teuer, zwei Barrieren für jedes GPU-Signal einzufügen, insbesondere, wenn die bedingte Unterbrechungsprüfung nicht erfüllt ist und kein CPU-Interrupt erforderlich ist. Daher verschiebt das Design die Kosten für das Einfügen einer der Speicherbarrieren von der GPU (Produzent) auf die CPU (Consumer). Dxgkrnl ruft die eingeführte Funktion DxgkDdiUpdateNativeFenceLogs auf, um KMD zu veranlassen, ausstehende Schreibvorgänge des nativen Fence-Protokolls bei Bedarf synchron zu leeren (ähnlich wie DxgkddiUpdateflipqueuelog für das Leeren des HW-Flip-Queue-Protokolls eingeführt wurde). for HW flip queue log flush).
Für GPU-Vorgänge:
- Signalzaun(N): Schreiben Sie N als neuen aktuellen Wert.
- Schreiben des LOG-Eintrags einschließlich des GPU-Zeitstempels
- Inkrementierung FirstFreeEntryIndex
- MemoryBarrier => Stellt sicher, dass FirstFreeEntryIndex vollständig verteilt wird.
- Überwachter Zaununterbruch (N): Lesen Sie die Adresse "M", und vergleichen Sie den Wert mit N , um zu entscheiden, ob der Interrupt bereitgestellt wird.
Für CPU-Vorgänge:
In Dxgkrnls systemeigenem Zaun signalisierter Interrupthandler (DISPATCH_IRQL):
- Für jedes HWQueue-Protokoll: FirstFreeEntryIndexlesen und ermitteln, ob neue Einträge geschrieben werden.
- Für jedes HWQueue-Protokoll mit neuen Einträgen: Rufen Sie DxgkDdiUpdateNativeFenceLogs auf, und stellen Sie die Kernelhandles für diese HWQueues bereit. In diesem DDI fügt KMD eine Speicherbarriere für jede angegebene HWQueue ein, wodurch sichergestellt wird, dass alle Protokolleintragsschreibvorgänge zugesichert werden.
- Dxgkrnl liest Protokolleinträge, um die Zeitstempelpayload zu extrahieren.
Solange also die Hardware nach dem Schreiben in FirstFreeEntryIndex eine Speicherbarriere einfügt, ruft Dxgkrnl immer den DDI von KMD auf, wodurch KMD eine Speicherbarriere einfügen kann, bevor Dxgkrnl Protokolleinträge liest.
Zukünftige Hardwareanforderungen
Die meiste Hardware der aktuellen Generation unterstützt möglicherweise nur das Schreiben des Kernel-Handles des Fence-Objekts, das sie im nativen, vom Fence signalisierten Interrupt signalisiert hat. Dieser Entwurf wird weiter oben in nativen Zaun signalisiert interrupt beschrieben. In diesem Fall behandelt Dxgkrnl die Interruptnutzlast wie folgt:
- Das Betriebssystem führt einen Lesevorgang (potenziell über PCI) des Zaunwerts aus.
- Wenn dem Betriebssystem bekannt ist, welcher Zaun signalisiert wurde und welcher Zaunwert vorliegt, weckt es CPU-Waiter, die auf diesen Zaun/Wert warten.
- Separat überprüft das Betriebssystem für das übergeordnete Gerät dieses Zauns die Protokollpuffer aller HWQueues. Das Betriebssystem liest dann die letzten geschriebenen Protokollpuffereinträge, um zu bestimmen, welche HWQueue das Signal ausgeführt hat, und extrahiert die entsprechende Zeitstempelnutzlast. Dieser Ansatz könnte einige Zaunwerte über PCI redundant lesen.
Auf zukünftigen Plattformen bevorzugt Dxgkrnl den Erhalt eines Arrays von Kernel-HwQueue-Handles im nativen, vom Fence signalisierten Interrupt. Mit diesem Ansatz kann das Betriebssystem folgendes erreichen:
- Lesen Sie die neuesten Protokollpuffereinträge für diese HwQueue. Das Benutzergerät ist dem Interrupthandler nicht bekannt. Daher muss dieses HwQueue-Handle ein Kernelhandle sein.
- Scannen Sie den Protokollpuffer nach Protokolleinträgen, die angeben, welche Zäune signalisiert wurden, und welche Werte. Durch das Lesen nur des Protokollpuffers wird ein einzelnes Lesen über PCI sichergestellt, anstatt redundante Zaunwerte und den Protokollpuffer lesen zu müssen. Diese Optimierung ist erfolgreich, solange der Protokollpuffer nicht überlaufen wurde (Ablegen von Einträgen, die dxgkrnl nie gelesen haben ).
- Wenn das Betriebssystem erkennt, dass der Protokollpuffer überschrieben wurde, fällt er auf den nicht optimierten Pfad zurück, der den Livewert jedes Zauns liest, der demselben Gerät gehört. Die Leistung ist proportional zur Anzahl der Zäune im Besitz des Geräts. Wenn sich der Zaunwert im Videospeicher befindet, sind diese Lesevorgänge über PCI hinweg zwischengespeichert.
- Wenn das Betriebssystem weiß, welche Zäune signalisiert wurden und welche Zaunwerte vorliegen, weckt es CPU-Waiter, die auf diese Zäune/Werte warten.
Optimierter nativer Zaun-Signal-Interrupt
Zusätzlich zu den in Nativer Zaun signalisierte Unterbrechung beschriebenen Änderungen wird zur Unterstützung des optimierten Ansatzes auch die folgende Änderung vorgenommen:
- Die Obergrenze für OptimizedNativeFenceSignaledInterrupt wird zu DXGK_VIDSCHCAPS hinzugefügt.
Wenn dies von der Hardware unterstützt wird, sollte die GPU statt eines Arrays mit signalisierten Fence-Handles nur den KMD-Handle der HWQueue erwähnen, die beim Auslösen des Interrupts ausgeführt wurde. Dxgkrnl scannt den Zaunprotokollpuffer für diese HWQueue und liest alle Zaunvorgänge, die seit der letzten Aktualisierung von der GPU abgeschlossen wurden, und entsperrt alle entsprechenden CPU-Waiter. Wenn die GPU nicht ermitteln konnte, welche Teilmenge von Zäunen signalisiert wurde, sollte sie einen NULL HWQueue-Handle angeben. Wenn Dxgkrnl einen NULL-HWQueue-Handle sieht, fällt es zurück, um den Protokollpuffer aller HWQueues auf diesem Modul zu überprüfen, um zu bestimmen, welche Zäune signalisiert wurden.
Unterstützung für diese Optimierung ist optional; KMD sollte die DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt Obergrenze festlegen, wenn sie von der Hardware unterstützt wird. Wenn die Obergrenze OptimizedNativeFenceSignaledInterruptnicht festgelegt ist, sollte die GPU/KMD dem verhalten folgen, das in Nativer Zaun signalisierter Interrupt beschrieben wird.
Beispiel für einen optimierten Systemzaun signalisierter Interrupt
HWQueueA: GPU-Signal zu Zaun F1, Wert V1 -> Schreiben in Protokollpuffereintrag E1 -> kein Interrupt erforderlich
HWQueueA: GPU-Signal zu Zaun F1, Wert V2 -> Schreiben in Protokollpuffereintrag E2 -> kein Interrupt erforderlich
HWQueueA: GPU-Signal zu Zaun F2, Wert V3 -> Schreiben in Protokollpuffereintrag E3 -> kein Interrupt erforderlich
HWQueueA: GPU-Signal zu Zaun F2, Wert V3 -> Schreiben in Protokollpuffereintrag E4 -> kein Interrupt erforderlich
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl liest den Protokollpuffer für HWQueueA. Es liest Protokollwinträgw E1, E2, E3 und E4 um signalisierte Zäune F1 @ Wert V1, F1 @ Wert V2, F2 @ Wert V3 und F2 @ Wert V3 zu beobachten, und entsperrt alle Waiter, die auf diese Zäune und Werte warten.
Optionale und obligatorische Protokollierung
Unterstützung für systemeigene Zaunprotokollierung für DXGK_NATIVE_FENCE_LOG_TYPE_WAITS und DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS ist obligatorisch.
In Zukunft können andere Protokollierungstypen nur hinzugefügt werden, wenn Tools wie GPUView ausführliche ETW-Protokollierung im Betriebssystem aktivieren. Das Betriebssystem muss sowohl UMD als auch KMD darüber informieren, wann ausführliche Protokollierung aktiviert und deaktiviert ist, damit die Protokollierung dieser ausführlichen Ereignisse selektiv aktiviert ist.