Step 2. Deploy POC to collect stakeholder feedback
At the end of this step, you will have deployed the Agent Evaluation Review App which allows your stakeholders to test and provide feedback on your POC. Detailed logs from your stakeholder’s usage and their feedback will flow to Delta Tables in your Lakehouse.
Requirements
- Complete Step 1. Clone code repository and create compute steps
- Data from Prerequisite: Gather requirements is available in your Lakehouse inside a Unity Catalog volume.
See the GitHub repository for the sample code in this section.
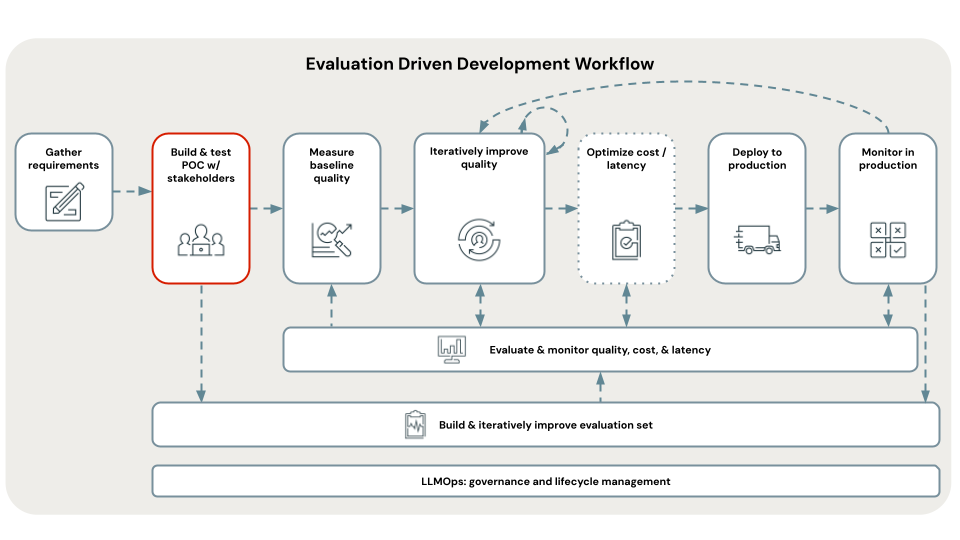
Proof of concept RAG application
The first step in evaluation-driven development is to build a proof of concept (POC). A POC offers the following benefits:
- Provides a directional view on the feasibility of your use case with RAG
- Allows collecting initial feedback from stakeholders, which in turn enables you to create the first version of your Evaluation Set
- Establishes a baseline measurement of quality to start to iterate from
Databricks recommends building your POC using the simplest RAG architecture and Databricks recommended defaults for each parameter.
This recommendation is because there are hundreds of possible combinations of parameters that you can tune within your RAG application. You can easily spend weeks tuning these, but if you do so before you can systematically evaluate your RAG, you end up in what is referred to as a POC doom loop–iterating on settings, but with no way to objectively know if you made an improvement—all while your stakeholders sit around impatiently waiting to review.
The POC templates in this tutorial are designed with quality iteration in mind. They are parameterized based on what the Databricks research team has shown are important to tune in order to improve RAG quality. These templates are not “3 lines of code that magically make a RAG”, but are a well-structured RAG application that can be tuned for quality in the following steps of an evaluation-driven development workflow.
This enables you to quickly deploy a POC, but transition quickly to quality iteration without needing to rewrite your code.
Below is the technical architecture of the POC application:
Note
By default, the POC uses the open source models available on Mosaic AI Foundation Model Serving. However, because the POC uses Mosaic AI Model Serving, which supports any foundation model, using a different model is easy - simply configure that model in Model Serving and then replace the embedding_endpoint_name and llm_endpoint_name in the 00_config notebook.
- Follow Provisioned throughput Foundation Model APIs for other open source models available in the Databricks Marketplace.
- Follow Create_OpenAI_External_Model notebook or External models in Mosaic AI Model Serving for supported third party hosted models such as Azure OpenAI, OpenAI, Cohere, Anthropic and Google Gemini.
Steps to deploy a POC to collect feedback
The following steps show how to run and deploy a POC generative AI application. After you deploy you get a URL to the review app that you can share with stakeholders to collect feedback.
Open the POC code folder within A_POC_app based on your type of data:
- For PDF files, use the pdf_uc_volume.
- For Powerpoint files, use the pptx_uc_volume.
- For DOCX files, use the docx_uc_volume.
- JSON files with text, markdown, HTML content and metadata, use the json_uc_volume
If your data doesn’t meet one of the above requirements, you can customize the parsing function (
parser_udf) within02_poc_data_pipelinein the above POC directories to work with your file types.Inside the POC folder, you see the following notebooks:
Note
These notebooks are relative to the specific POC you’ve chosen. For example, if you see a reference to
00_configand you’ve chosenpdf_uc_volume, you can find the relevant00_confignotebook at A_POC_app/pdf_uc_volume/00_config.Optionally, review the default parameters.
Open the
00_confignotebook within the POC directory you chose above to view the POC’s applications default parameters for the data pipeline and RAG chain.Important
The Databricks recommended default parameters are not intended to be perfect, but are a place to start. The next steps of this workflow guide you through iterating on these parameters.
Validate the configuration.
Run the
01_validate_configto check that your configuration is valid and all resources are available. Therag_chain_config.yamlfile appears in your directory, which is used to deploy the application.Run the data pipeline.
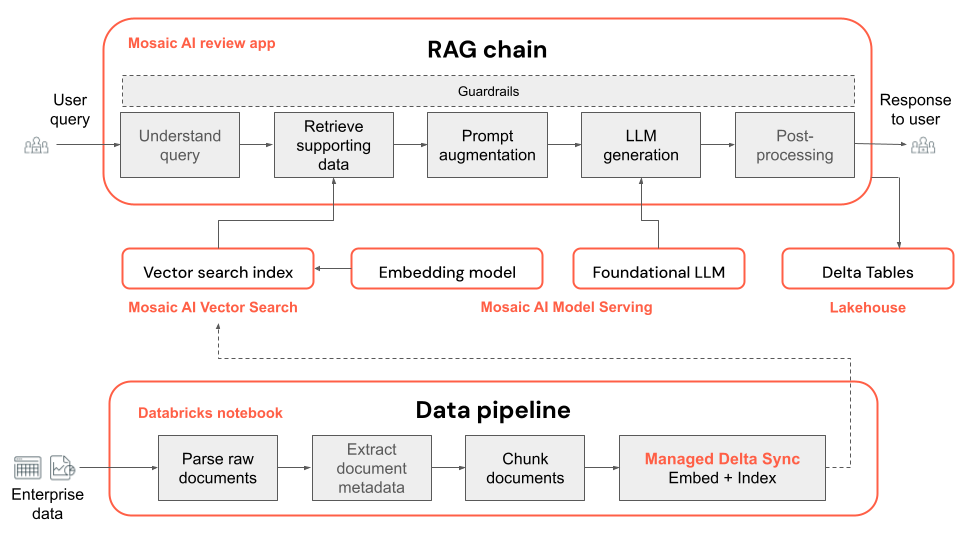
The POC data pipeline is a Databricks notebook based on Apache Spark. Open the
02_poc_data_pipelinenotebook and press Run All to run the pipeline. The pipeline does the following:- Loads the raw documents from the UC Volume
- Parses each document, saving the results to a Delta Table
- Chunks each document, saving the results to a Delta Table
- Embeds the documents and create a Vector Index using Mosaic AI Vector Search
Metadata, like output tables and configuration, about the data pipeline are logged to MLflow:
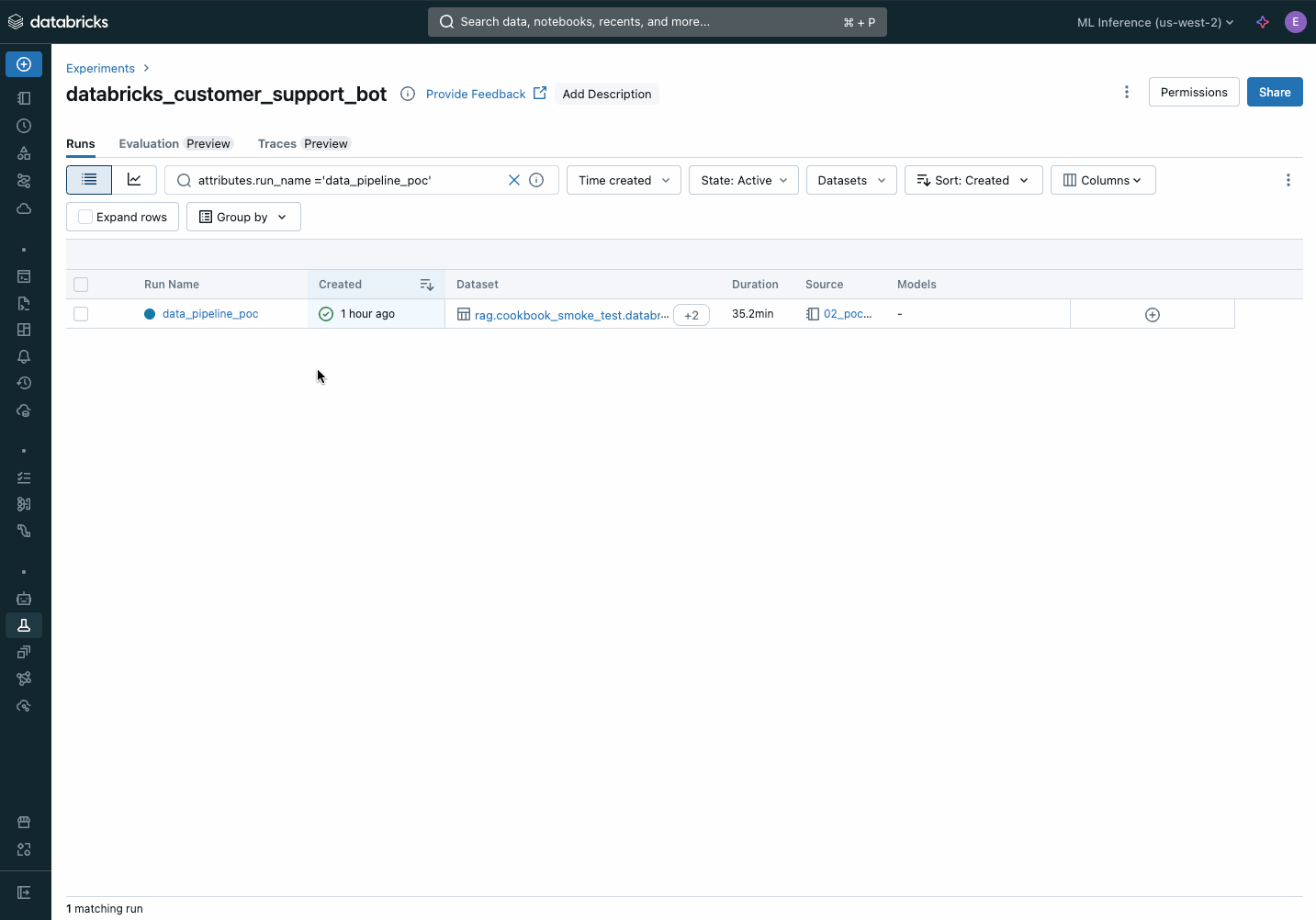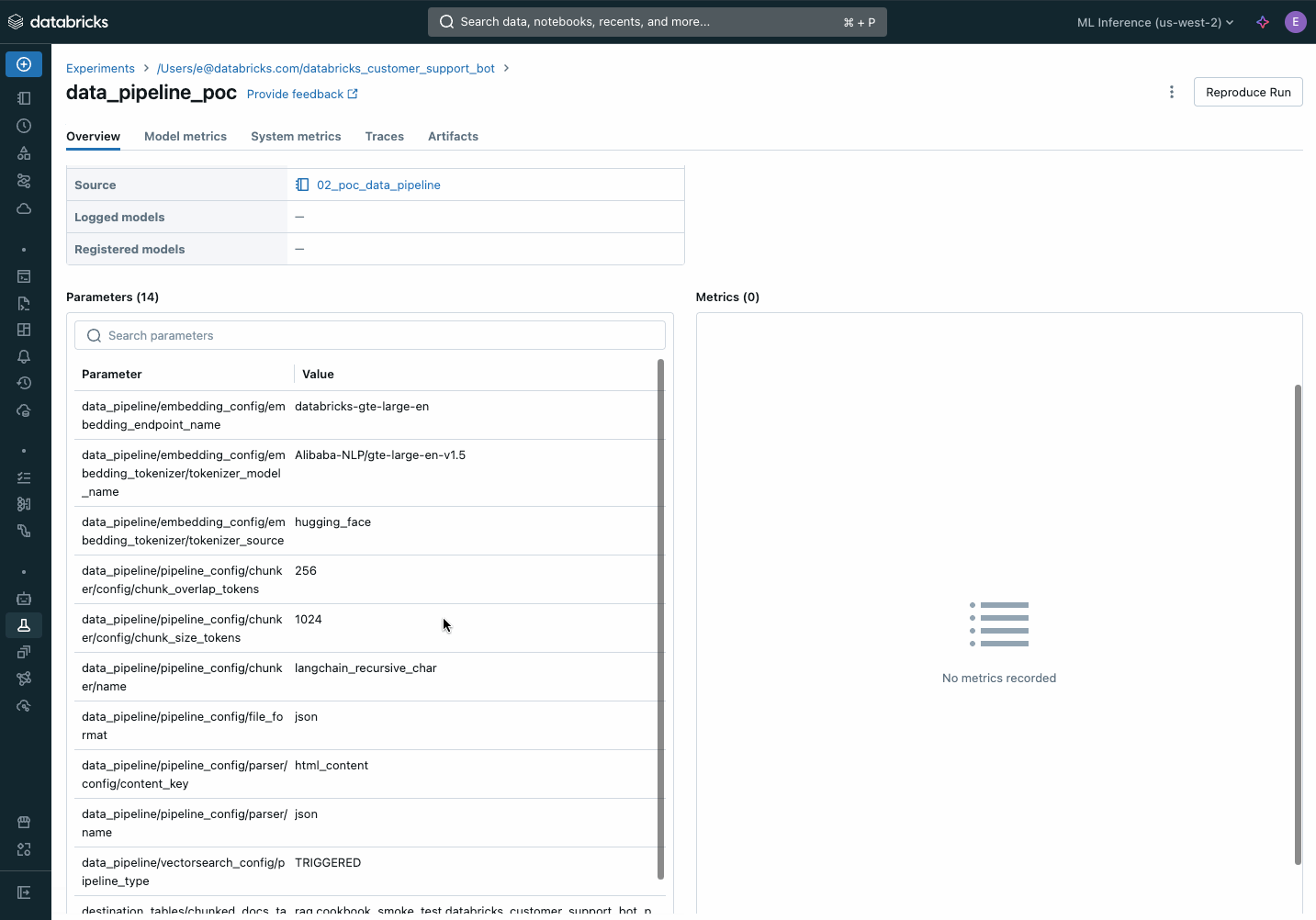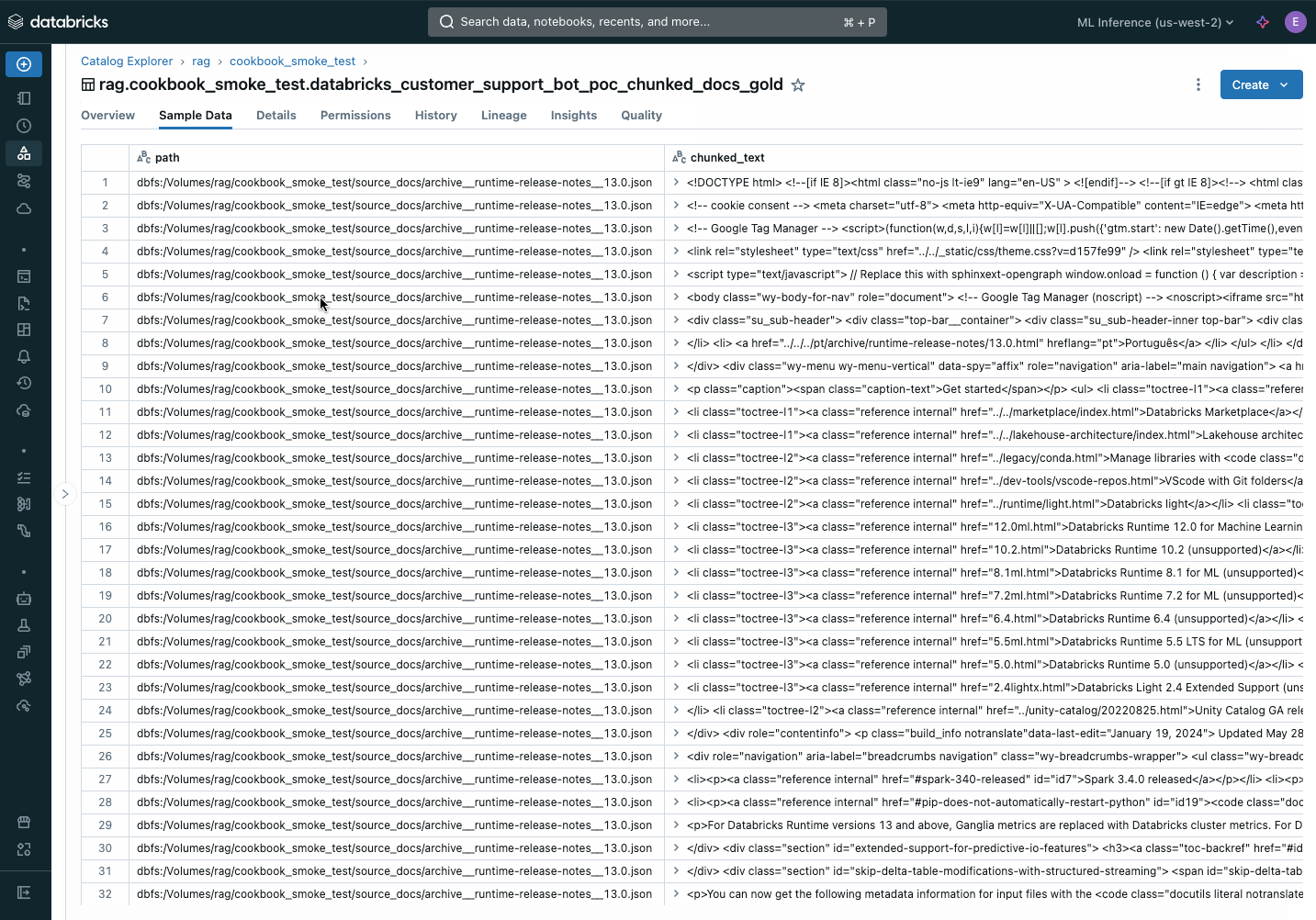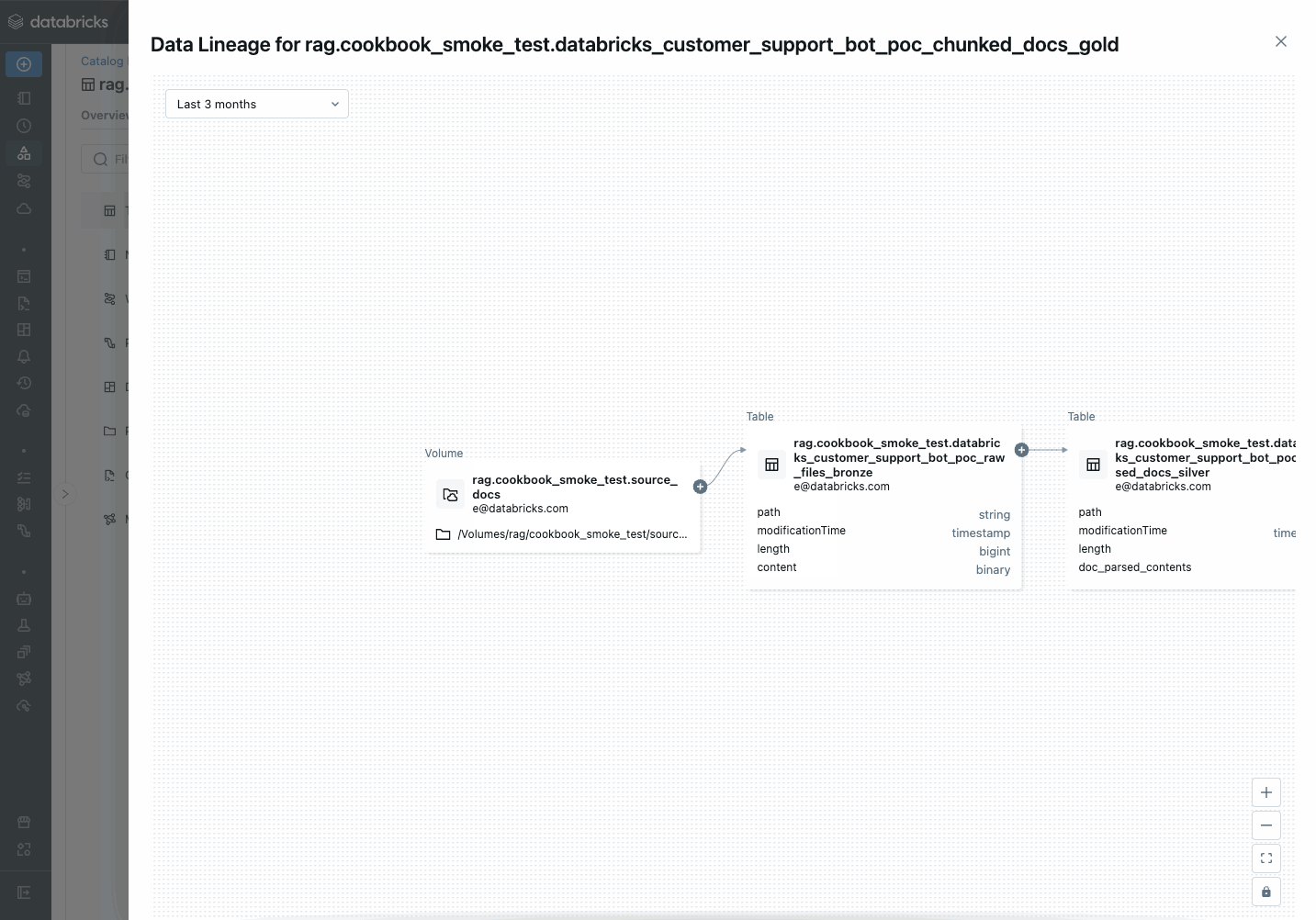
You can inspect the outputs by looking for links to the Delta Tables or vector indexes output near the bottom of the notebook:
Vector index: https://<your-workspace-url>.databricks.com/explore/data/<uc-catalog>/<uc-schema>/<app-name>_poc_chunked_docs_gold_index Output tables: Bronze Delta Table w/ raw files: https://<your-workspace-url>.databricks.com/explore/data/<uc-catalog>/<uc-schema>/<app-name>__poc_raw_files_bronze Silver Delta Table w/ parsed files: https://<your-workspace-url>.databricks.com/explore/data/<uc-catalog>/<uc-schema>/<app-name>__poc_parsed_docs_silver Gold Delta Table w/ chunked files: https://<your-workspace-url>.databricks.com/explore/data/<uc-catalog>/<uc-schema>/<app-name>__poc_chunked_docs_goldDeploy the POC chain to the Review App.
The default POC chain is a multi-turn conversation RAG chain built using LangChain.
Note
The POC Chain uses MLflow code-based logging. To understand more about code-based logging, see Log and register AI agents.
Open the
03_deploy_poc_to_review_appnotebookRun each cell of the notebook.
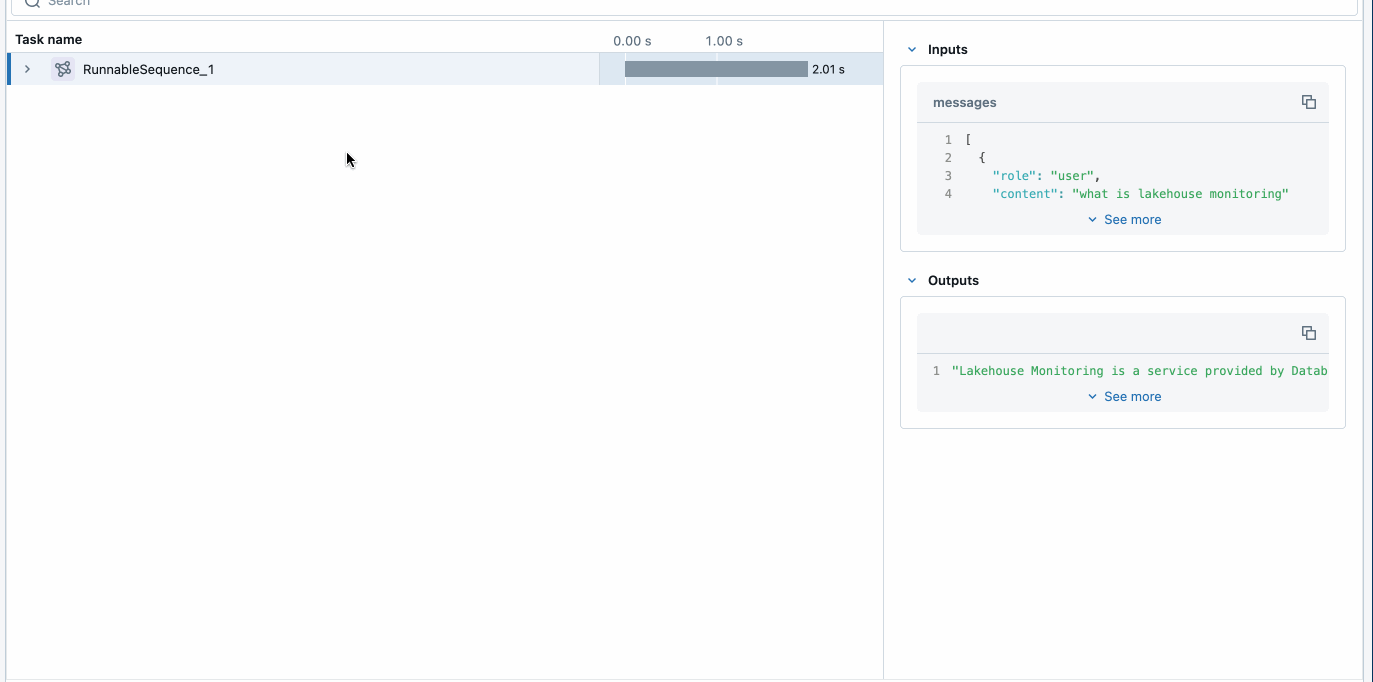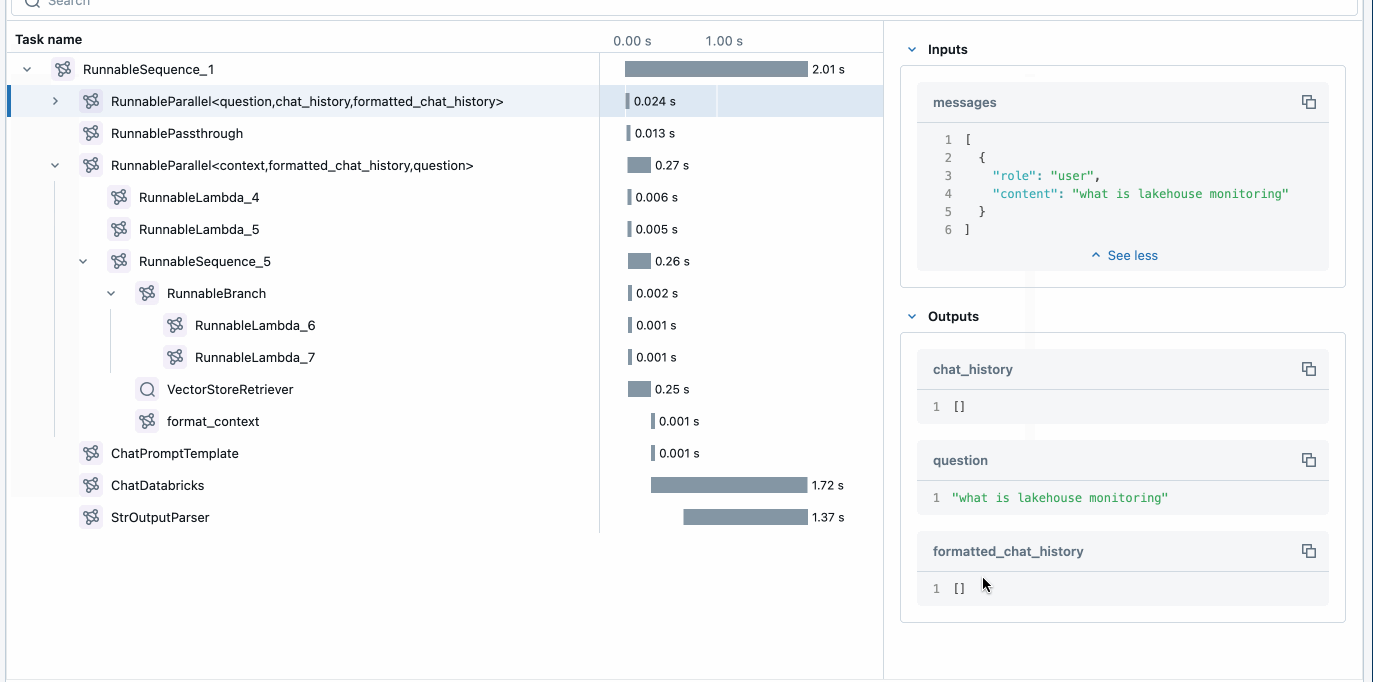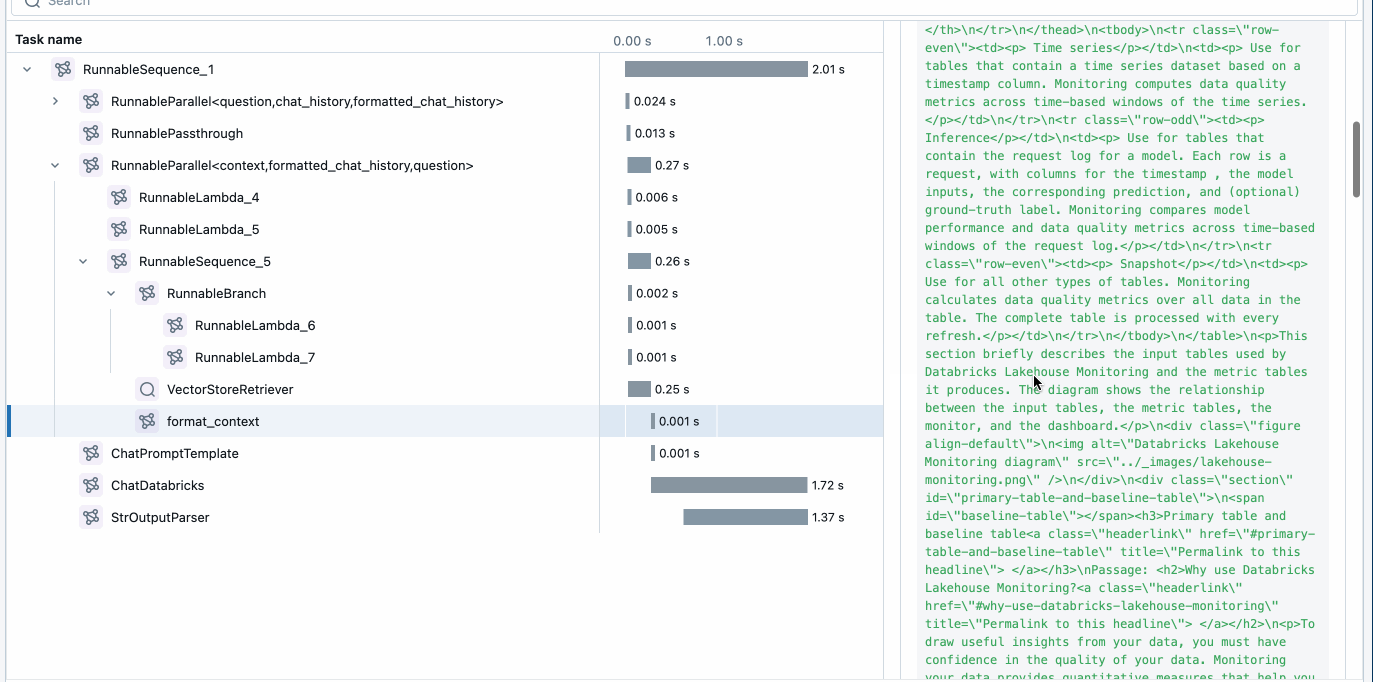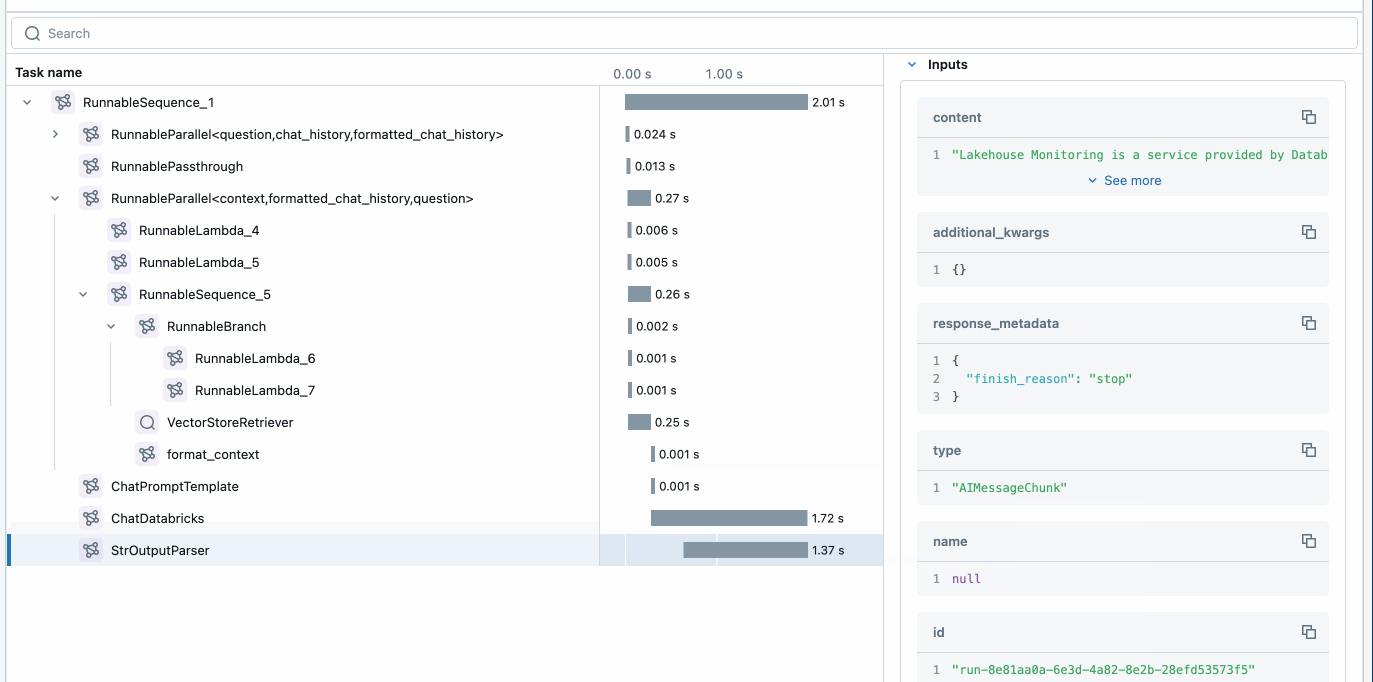
The MLflow trace shows you how the POC application works. Adjust the input question to one that is relevant to your use case, and re-run the cell to “vibe check” the application.
Modify the default instructions to be relevant to your use case. These are displayed in the Review App.
instructions_to_reviewer = f"""## Instructions for Testing the {RAG_APP_NAME}'s Initial Proof of Concept (PoC) Your inputs are invaluable for the development team. By providing detailed feedback and corrections, you help us fix issues and improve the overall quality of the application. We rely on your expertise to identify any gaps or areas needing enhancement. 1. **Variety of Questions**: - Please try a wide range of questions that you anticipate the end users of the application will ask. This helps us ensure the application can handle the expected queries effectively. 2. **Feedback on Answers**: - After asking each question, use the feedback widgets provided to review the answer given by the application. - If you think the answer is incorrect or could be improved, please use "Edit Answer" to correct it. Your corrections will enable our team to refine the application's accuracy. 3. **Review of Returned Documents**: - Carefully review each document that the system returns in response to your question. - Use the thumbs up/down feature to indicate whether the document was relevant to the question asked. A thumbs up signifies relevance, while a thumbs down indicates the document was not useful. Thank you for your time and effort in testing {RAG_APP_NAME}. Your contributions are essential to delivering a high-quality product to our end users.""" print(instructions_to_reviewer)Run the deployment cell to get a link to the Review App.
Review App URL: https://<your-workspace-url>.databricks.com/ml/review/<uc-catalog>.<uc-schema>.<uc-model-name>/<uc-model-version>
Grant individual users permissions to access the Review App.
You can grant access to non-Databricks users by following the steps in Set up permissions to use the review app.
Test the Review App by asking a few questions yourself and providing feedback.
Note
MLflow Traces and the user’s feedback from the Review App appear in Delta Tables in the catalog schema you have configured. Logs can take up to 2 hours to appear in these Delta Tables.
Share the Review App with stakeholders
You can now share your POC RAG application with your stakeholders to get their feedback.
Important
Databricks suggests distributing your POC to at least three stakeholders and having them each ask 10 - 20 questions. It is important to have multiple stakeholders test your POC so you can have a diverse set of perspectives to include in your evaluation set.
Next step
Continue with Step 3. Curate an Evaluation Set from stakeholder feedback.