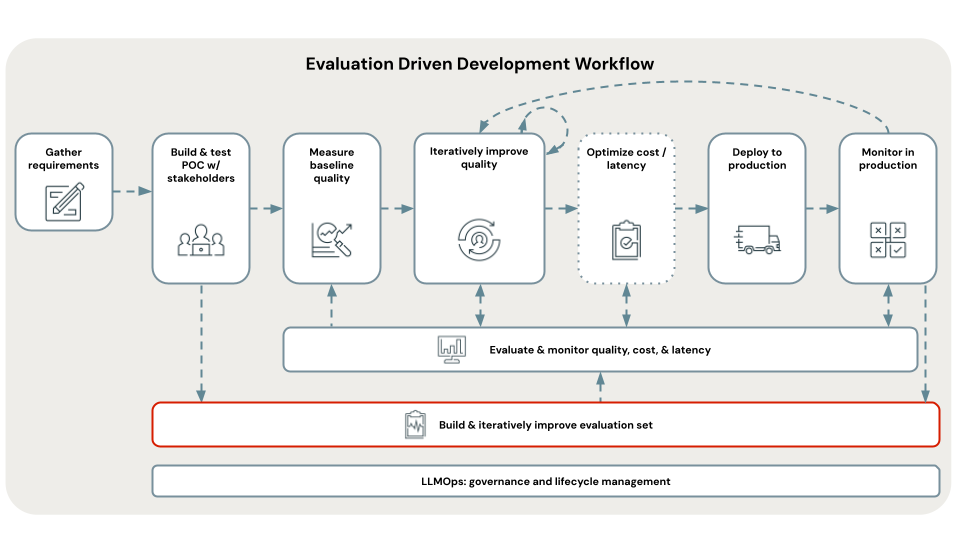
Step 3. Curate an Evaluation Set from stakeholder feedback
See the GitHub repository for the sample code in this section.
Expected time: 10 - 60 minutes. Time varies based on the quality of the responses provided by your stakeholders. If the responses are messy or contain lots of irrelevant queries, you will need to spend more time filtering and cleaning the data.
Overview and expected outcome
This step will bootstrap an evaluation set with the feedback that stakeholders have provided by using the Review App. Note that you can bootstrap an evaluation set with just questions, so even if your stakeholders only chatted with the app vs. providing feedback, you can follow this step.
For the schema of the Agent Evaluation evaluation set, see Agent Evaluation input schema. The fields in this schema are referenced in the rest of this section.
At the end of this step, you will have an Evaluation Set that contains the following:
- Requests with a thumbs-up 👍:
request: as entered by the user.expected_response: Response as edited by the user. If the user did not edit the response, the response generated by the model.
- Requests with a thumbs-down 👎:
request: as entered by the user.expected_response: Response as edited by the user. If the user did not edit the response, the response is null.
- Requests with no feedback (no thumbs-up 👍 or thumbs-down 👎)
request: as entered by the user.
For all requests, if the user selects thumbs-up 👍 for a chunk from the retrieved_context, the doc_uri of that chunk is included in expected_retrieved_context for the question.
Important
Databricks recommends that your evaluation set contain at least 30 questions to get started. Read the evaluation set deep dive to learn more about what a “good” evaluation set is.
Requirements
- Stakeholders have used your POC and provided feedback.
- All requirements from previous steps.
Instructions
- Open the 04_create_evaluation_set notebook and click Run all.
- Inspect the evaluation set to understand the data that is included. You need to validate that your evaluation set contains a representative and challenging set of questions. Adjust the evaluation set as required.
- By default, your evaluation set is saved to the Delta table configured in
EVALUATION_SET_FQNin the 00_global_config notebook.
Next step
Now that you have an evaluation set, use it to evaluate the POC app’s quality, cost, and latency. See Step 4. Evaluate the POC’s quality.