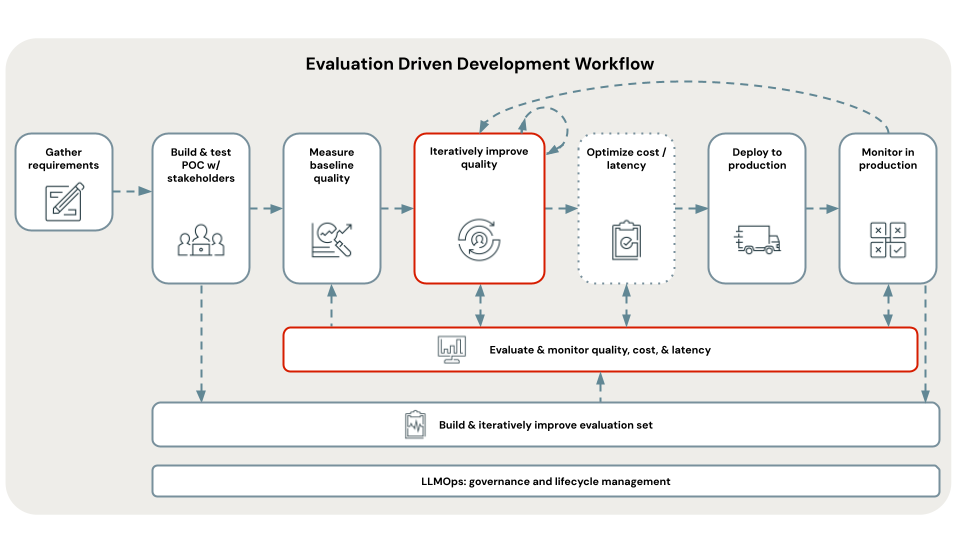
Step 5. Identify the root cause of quality issues
See the GitHub repository for the sample code in this section.
Expected time: 60 minutes.
Requirements
- Evaluation results for the POC are available in MLflow. If you followed Step 4. Evaluate the POC’s quality, the results are available in MLflow.
- All requirements from previous steps.
Overview
The most likely root causes of quality issues are the retrieval and generation steps. To determine where to focus first, use the output of the Mosaic AI Agent Evaluation LLM judges that you ran in the previous step to identify the most frequent root cause that impacts your app’s quality.
Each row your evaluation set is tagged as follows:
- Overall assessment: Pass or fail.
- Root cause:
Improve RetrievalorImprove Generation. - Root cause rationale: A brief description of why the root cause was selected.
Instructions
The approach depends on if your evaluation set contains the ground-truth responses to your questions. These responses are stored in expected_response. If you have expected_response available, use the table Root cause analysis if ground truth is available. Otherwise, use the table Root cause analysis if ground truth is not available.
- Open the B_quality_iteration/01_root_cause_quality_issues notebook.
- Run the cells that are relevant to your use case e.g., if you do or don’t have expected_response
- Review the output tables to determine the most frequent root cause in your application
- For each root cause, follow the steps below to further debug and identify potential fixes:
Root cause analysis if ground truth is available
Note
If you have human labeled ground-truth for which document should be retrieved for each question, you can optionally substitute retrieval/llm_judged/chunk_relevance/precision/average with the score for retrieval/ground_truth/document_recall/average.
| Chunk relevance precision | Groundedness | Correctness | Relevance to query | Issue summary | Root cause | Overall rating |
|---|---|---|---|---|---|---|
| <50% | Fail | Fail | Fail | Retrieval is poor. | Improve Retrieval |
Fail |
| <50% | Fail | Fail | Pass | LLM generates relevant response, but retrieval is poor. For example, the LLM ignores retrieval and uses its training knowledge to answer. | Improve Retrieval |
Fail |
| <50% | Fail | Pass | Pass or fail | Retrieval quality is poor, but LLM gets the answer correct regardless. | Improve Retrieval |
Fail |
| <50% | Pass | Fail | Fail | Response is grounded in retrieval, but retrieval is poor. | Improve Retrieval |
Fail |
| <50% | Pass | Fail | Pass | Relevant response grounded in the retrieved context, but retrieval may not be related to the expected answer. | Improve Retrieval |
Fail |
| <50% | Pass | Pass | Pass or fail | Retrieval finds enough information for the LLM to correctly answer. | None | Pass |
| >50% | Fail | Fail | Pass or fail | Hallucination. | Improve Generation |
Fail |
| >50% | Fail | Pass | Pass or fail | Hallucination, correct but generates details not in context. | Improve Generation |
Fail |
| >50% | Pass | Fail | Fail | Good retrieval, but the LLM does not provide a relevant response. | Improve Generation |
Fail |
| >50% | Pass | Fail | Pass | Good retrieval and relevant response, but not correct. | Improve Generation |
Fail |
| >50% | Pass | Pass | Pass | No issues. | None | Pass |
Root cause analysis if ground truth is not available
| Chunk relevance precision | Groundedness | Relevance to query | Issue summary | Root cause | Overall rating |
|---|---|---|---|---|---|
| <50% | Fail | Fail | Retrieval quality is poor. | Improve Retrieval |
Fail |
| <50% | Fail | Pass | Retrieval quality is poor. | Improve Retrieval |
Fail |
| <50% | Pass | Fail | Response is grounded in retrieval, but retrieval is poor. | Improve Retrieval |
Fail |
| <50% | Pass | Pass | Relevant response grounded in the retrieved context and relevant, but retrieval is poor. | Improve Retrieval |
Pass |
| >50% | Fail | Fail | Hallucination. | Improve Generation |
Fail |
| >50% | Fail | Pass | Hallucination. | Improve Generation |
Fail |
| >50% | Pass | Fail | Good retrieval and grounded, but LLM does not provide a relevant response. | Improve Generation |
Fail |
| >50% | Pass | Pass | Good retrieval and relevant response. Collect ground-truth to know if the answer is correct. | None | Pass |
Next step
See the following pages to debug the issues you identified:
- Step 5 (retrieval). How to debug retrieval quality
- Step 5 (generation). How to debug generation quality