Cette architecture fournit une aide pour la conception d’une charge de travail stratégique sur Azure. Il utilise des fonctionnalités natives cloud pour optimiser la fiabilité et l’efficacité opérationnelle. Il applique la méthodologie de conception pour les charges de travail stratégiques Well-Architected à une application accessible sur Internet, où la charge de travail est accessible sur un point de terminaison public et ne nécessite pas de connectivité réseau privée à d’autres ressources d’entreprise.
Important
 Les conseils sont soutenus par une implémentation d’exemple de production qui présente le développement d’applications critiques sur Azure. Cette implémentation peut être utilisée comme base pour un développement de solution supplémentaire dans votre première étape vers la production.
Les conseils sont soutenus par une implémentation d’exemple de production qui présente le développement d’applications critiques sur Azure. Cette implémentation peut être utilisée comme base pour un développement de solution supplémentaire dans votre première étape vers la production.
Niveau de fiabilité
La fiabilité est un concept relatif et pour qu’une charge de travail soit fiable, elle doit refléter les besoins métier qui l’entourent, y compris les objectifs de niveau de service (SLO) et les contrats de niveau de service (SLA) pour capturer le pourcentage de temps où l’application doit être disponible.
Cette architecture cible un SLO de 99,99 %, ce qui correspond à un temps d’arrêt annuel autorisé de 52 minutes et 35 secondes. Toutes les décisions de conception englobantes sont donc destinées à accomplir ce SLO cible.
Conseil
Pour définir un SLO réaliste, il est important de comprendre les objectifs de fiabilité de tous les composants Azure et d’autres facteurs dans l’étendue de l’architecture. Pour plus d’informations, consultez Recommandations pour définir des objectifs de fiabilité. Ces chiffres individuels doivent être agrégés pour déterminer un SLO composite qui doit être aligné avec les objectifs de la charge de travail.
Reportez-vous aux charges de travail stratégiques Well-Architected : conception pour les exigences métier.
Stratégies de conception
De nombreux facteurs peuvent affecter la fiabilité d’une application, comme la possibilité de récupérer à partir d’une défaillance, d’une disponibilité régionale, d’une efficacité de déploiement et d’une sécurité. Cette architecture applique un ensemble de stratégies de conception globales destinées à résoudre ces facteurs et à garantir que le niveau de fiabilité cible est atteint.
Redondance dans les couches
Déployez sur plusieurs régions dans un modèle actif-actif. L’application est distribuée dans deux régions Azure ou plus qui gèrent le trafic utilisateur actif.
Utilisez des zones de disponibilité pour tous les services considérés afin de maximiser la disponibilité au sein d'une même région Azure, en répartissant les composants entre des centres de données physiquement séparés à l'intérieur d'une région.
Choisissez les ressources qui prennent en charge la distribution globale.
Reportez-vous aux charges de travail stratégiques Well-Architected : distribution globale.
Empreintes de déploiement
Déployez un tampon régional en tant qu’unité d’échelle où un ensemble logique de ressources peut être provisionné indépendamment pour maintenir les changements de la demande. Chaque tampon applique également plusieurs unités d’échelle imbriquées, telles que les API front-end et les processeurs d’arrière-plan sur lesquels on peut effectuer un scale-in indépendamment.
Reportez-vous aux charges de travail stratégiques Well-Architected : architecture d’unité d’échelle.
Déploiements fiables et reproductibles
Appliquez le principe de l’infrastructure en tant que code (IaC) à l’aide de technologies comme Terraform pour fournir une gestion de versions et une approche opérationnelle standardisée pour les composants d’infrastructure.
Implémentez des pipelines de déploiement bleu/vert sans temps d’arrêt. Les pipelines de génération et de mise en production doivent être entièrement automatisés pour déployer des empreintes en tant qu’unité opérationnelle unique, à l’aide de déploiements bleu/vert avec validation continue appliquée.
Appliquez la cohérence de l’environnement dans tous les environnements considérés, avec le même code de pipeline de déploiement dans les environnements de production et de préproduction. Cela élimine les risques associés au déploiement et aux variations de processus entre les environnements.
Disposez d’une validation continue en intégrant des tests automatisés dans le cadre des processus DevOps, y compris les tests de charge synchronisés et de chaos, pour valider entièrement l’intégrité du code d’application et de l’infrastructure sous-jacente.
Reportez-vous aux charges de travail stratégiques Well-Architected : déploiement et test.
Insights opérationnels
Disposez d’espaces de travail fédérés pour les données d’observabilité. Les données de surveillance des ressources globales et des ressources régionales sont stockées indépendamment. Un magasin d’observabilité centralisé n’est pas recommandé pour éviter un point de défaillance unique. L’interrogation entre espaces de travail est utilisée pour obtenir un récepteur de données unifié et un volet unique de verre pour les opérations.
Construisez un modèle d’intégrité en couches qui mappe l’intégrité de l’application à un modèle de lumière du trafic pour la contextualisation. Les scores d’intégrité sont calculés pour chaque composant individuel, puis agrégés au niveau du flux utilisateur et combinés à des exigences clés non fonctionnelles, telles que les coefficients pour quantifier l’intégrité de l’application.
Reportez-vous aux charges de travail stratégiques Well-Architected : modélisation de la santé.
Architecture

*Téléchargez un fichier Visio de cette architecture.
Les composants de cette architecture peuvent être classés de manière générale de cette manière. Pour obtenir de la documentation sur les services Azure, consultez Ressources associées.
Ressources globales
Les ressources globales ont une longue durée de vie et partagent la durée de vie du système. Ils ont la capacité d’être disponibles globalement dans le contexte d’un modèle de déploiement multirégion.
Voici les considérations générales relatives aux composants. Pour plus d’informations sur les décisions, consultez Ressources globales.
Équilibreur de charge global
Un équilibreur de charge global est essentiel pour le routage fiable du trafic vers les déploiements régionaux avec un certain niveau de garantie en fonction de la disponibilité des services principaux dans une région. De plus, ce composant doit avoir la capacité d’inspecter le trafic d’entrée, par exemple via le pare-feu d’applications web.
Azure Front Door est utilisé comme point d’entrée global pour tout le trafic HTTP(S) du client entrant, avec des fonctionnalités Web Application Firewall (WAF) appliquées au trafic d’entrée de couche 7 sécurisé. Il utilise TCP Anycast pour optimiser le routage à l’aide du réseau principal Microsoft et permet un basculement transparent en cas d’intégrité régionale dégradée. Le routage dépend des sondes d’intégrité personnalisées qui vérifient la chaleur composite des ressources régionales clés. Azure Front Door fournit également un réseau de distribution de contenu intégré (CDN) pour mettre en cache des ressources statiques pour le composant web.
Une autre option est Traffic Manager, qui est un équilibreur de charge basé sur DNS 4. Toutefois, l’échec n’est pas transparent pour tous les clients, car la propagation DNS doit se produire.
Reportez-vous aux charges de travail stratégiques Well-Architected : routage du trafic global.
Base de données
Tous les états liés à la charge de travail sont stockés dans une base de données externe, Azure Cosmos DB for NoSQL. Cette option a été choisie, car elle a le jeu de fonctionnalités nécessaire pour le réglage des performances et de la fiabilité, tant sur les côtés client que serveur. Il est vivement recommandé que le compte dispose d’une écriture multimaître activée.
Notes
Bien qu’une configuration d’écriture multirégion représente la norme d’or pour la fiabilité, il existe un compromis significatif sur les coûts, qui doit être pris en compte correctement.
Le compte est répliqué sur chaque tampon régional et dispose également d’une redondance zonale activée. En outre, la mise à l’échelle automatique est activée au niveau du conteneur afin que les conteneurs mettez automatiquement à l’échelle le débit provisionné selon les besoins.
Pour plus d’informations, consultez Plateforme de données pour les charges de travail stratégiques.
Reportez-vous aux charges de travail stratégiques Well-Architected : magasin de données multi-écriture distribué à l’échelle mondiale.
Registre de conteneurs
Azure Container Registry est utilisé pour stocker toutes les images conteneur. Il dispose de fonctionnalités de géoréplication qui permettent aux ressources de fonctionner comme un registre unique, servant plusieurs régions avec des registres régionaux multimaître.
En tant que mesure de sécurité, autorisez uniquement l’accès aux entités requises et authentifiez cet accès. Par exemple, dans l’implémentation, l’accès administrateur est désactivé. Ainsi, le cluster de calcul peut extraire des images uniquement avec les attributions de rôles Microsoft Entra.
Reportez-vous aux charges de travail stratégiques Well-Architected : registre de conteneurs.
Ressources régionales
Les ressources régionales sont approvisionnées dans le cadre d’un tampon de déploiement dans une seule région Azure. Ces ressources ne partagent rien avec les ressources d’une autre région. Elles peuvent être supprimées ou répliquées indépendamment dans des régions supplémentaires. Toutefois, ils partagent les ressources globales entre elles.
Dans cette architecture, un pipeline de déploiement unifié déploie un tampon avec ces ressources.
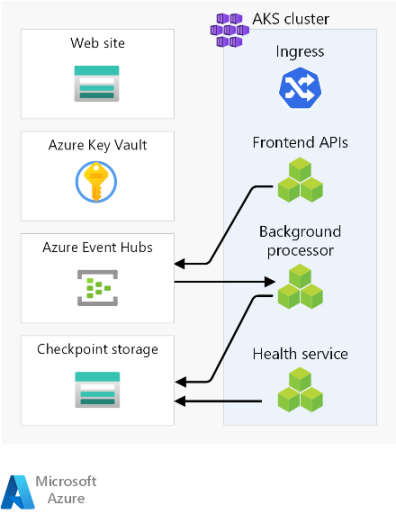
Voici les considérations générales relatives aux composants. Pour plus d’informations sur les décisions, consultez Ressources d’empreinte régionales.
Serveur frontal
Cette architecture utilise une application monopage (SPA) qui envoie des demandes aux services principaux. Un avantage est que le calcul nécessaire pour l’expérience de site web est déchargé sur le client au lieu de vos serveurs. Le SPA est hébergé en tant que site web statique dans un compte stockage Azure.
Un autre choix est Azure Static Web Apps, qui introduit d’autres points à prendre en considération comme la façon dont les certificats sont exposés, la connectivité à un équilibreur de charge global et d’autres facteurs.
Le contenu statique est généralement mis en cache dans un magasin proche du client, à l’aide d’un réseau de distribution de contenu (CDN), afin que les données puissent être servies rapidement sans communiquer directement avec les serveurs principaux. Il s’agit d’un moyen rentable d’augmenter la fiabilité et de réduire la latence du réseau. Dans cette architecture, les fonctionnalités intégrées CDN d’Azure Front Door sont utilisées pour mettre en cache le contenu du site web statique sur le réseau de périphérie.
Cluster de calcul
Le calcul principal exécute une application composée de trois microservices et est sans état. Par conséquent, la conteneurisation est une stratégie appropriée pour héberger l’application. Azure Kubernetes Service (AKS) a été choisi, car il répond à la plupart des exigences métier et Kubernetes est largement adopté dans de nombreuses industries. AKS prend en charge les topologies avancées d’extensibilité et de déploiement. Le niveau SLA de temps d’activité AKS est fortement recommandé pour l’hébergement d’applications stratégiques, car il fournit des garanties de disponibilité pour le plan de contrôle Kubernetes.
Azure propose d’autres services de calcul comme Azure Functions et Azure App Services. Ces options déchargent des responsabilités de gestion supplémentaires sur Azure au coût de la flexibilité et de la densité.
Notes
Évitez de stocker l’état sur le cluster de calcul, en gardant à l’esprit la nature éphémère des empreintes. Autant que possible, conservez l’état dans une base de données externe pour maintenir la mise à l’échelle et les opérations de récupération légères. Par exemple, dans AKS, les pods changent fréquemment. L’attachement de l’état aux pods ajoute la charge de cohérence des données.
Reportez-vous aux charges de travail stratégiques Well-Architected : orchestration de conteneurs et Kubernetes.
Répartiteur de messages régional
Pour optimiser les performances et maintenir la réactivité pendant les pics de charge, la conception utilise la messagerie asynchrone pour gérer les flux système intensifs. Comme une demande est rapidement renvoyée vers les API front-end, la requête est également mise en file d’attente dans un répartiteur de messages. Ces messages sont ensuite consommés par un service principal qui, par exemple, gère une opération d’écriture dans une base de données.
L’intégralité de l’empreinte est sans état, sauf à certains points, comme ce répartiteur de messages. Les données sont en file d’attente dans la répartiteur pour une courte durée. Le répartiteur de messages doit garantir au moins une fois la remise. Cela signifie que les messages sont dans la file d’attente si le répartiteur devient indisponible une fois le service restauré. Toutefois, il incombe au consommateur de déterminer si ces messages ont toujours besoin de traitement. La file d’attente est vidée une fois le message traité et stocké dans une base de données globale.
Dans cette conception, Azure Event Hubs est utilisé. Un compte stockage Azure supplémentaire est approvisionné pour le point de contrôle. Event Hubs est le choix recommandé pour les cas d’usage nécessitant un débit élevé comme la diffusion en continu d’événements.
Pour les cas d’utilisation nécessitant des garanties de message supplémentaires, Azure Service Bus est recommandé. Il permet des validations en deux phases avec un curseur côté client, ainsi que des fonctionnalités telles qu’une file d’attente de lettres mortes intégrée et des fonctionnalités de déduplication.
Pour plus d’informations, consultez Services de messagerie pour les charges de travail stratégiques.
Reportez-vous aux charges de travail stratégiques Well-Architected : architecture basée sur des événements à faible couplage.
Magasin secret régional
Chaque tampon possède son propre Key Vault Azure qui stocke les secrets et la configuration. Il existe des secrets courants tels que les chaînes de connexion à la base de données globale, mais il existe également des informations uniques à un tampon unique, comme la chaîne de connexion Event Hubs. En outre, les ressources indépendantes évitent un point de défaillance unique.
Reportez-vous aux charges de travail stratégiques Well-Architected : protection de l’intégrité des données.
Pipeline de déploiement
Les pipelines de build et de mise en production pour une application critique doivent être entièrement automatisés. C’est pourquoi aucune action ne devrait être effectuée manuellement. Cette conception illustre des pipelines entièrement automatisés qui déploient un tampon validé de manière cohérente chaque fois. Une autre approche consiste à déployer uniquement des mises à jour propagées sur un tampon existant.
Référentiel du code source
GitHub est utilisé pour le contrôle de code source, fournissant une plateforme git hautement disponible pour la collaboration sur le code d’application et le code d’infrastructure.
Implémentation de pipelines d’intégration continue/de livraison continue (CI/CD)
Les pipelines automatisés sont nécessaires pour créer, tester et déployer une charge de travail stratégique dans les environnements de préproduction et de production. Azure Pipelines est choisi en fonction de son ensemble d’outils enrichi qui peut cibler Azure et d’autres plateformes cloud.
Un autre choix est GitHub Actions pour les pipelines CI/CD. L’avantage ajouté est que le code source et le pipeline peuvent être colocalisés. Toutefois, Azure Pipelines a été choisi en raison des fonctionnalités CD plus riches.
Reportez-vous aux charges de travail stratégiques Well-Architected : processus DevOps.
Agents de build
Les agents de build hébergés par Microsoft sont utilisés par cette implémentation pour réduire la complexité et la surcharge de gestion. Les agents auto-hébergés peuvent être utilisés pour les scénarios nécessitant une posture de sécurité renforcée.
Notes
L’utilisation d’agents auto-hébergés est illustrée dans l’implémentation de référence stratégique - Connectée .
Ressources d’observabilité
Les données opérationnelles provenant de l’application et de l’infrastructure doivent être disponibles pour permettre des opérations efficaces et optimiser la fiabilité. Cette référence fournit une base de référence pour atteindre l’observabilité globale d’une application.
Récepteur de données unifié
- Azure Log Analytics est utilisé comme récepteur unifié pour stocker les journaux et les métriques pour tous les composants d’application et d’infrastructure.
- Azure Application Insights est utilisé comme outil APM (Application Performance Management) pour collecter toutes les données de supervision des applications et les stocker directement dans Log Analytics.

Les données de surveillance des ressources globales et des ressources régionales sont stockées indépendamment. Un magasin d’observabilité centralisé n’est pas recommandé pour éviter un point de défaillance unique. L’interrogation entre espaces de travail est utilisée pour obtenir un seul volet de verre.
Dans cette architecture, la surveillance des ressources au sein d’une région doit être indépendante de l’empreinte elle-même, car si vous décomposez un tampon, vous souhaitez toujours conserver l’observabilité. Chaque tampon régional possède son propre Application Insights dédié et espace de travail Log Analytics. Les ressources sont approvisionnées par région, mais elles ont dépassé les empreintes.
De même, les données provenant de services partagés tels que Azure Front Door, Azure Cosmos DB et Container Registry sont stockées dans une instance dédiée de l’espace de travail Log Analytics.
Archivage et analyse des données
Les données opérationnelles qui ne sont pas requises pour les opérations actives sont exportées de Log Analytics vers les comptes de stockage Azure à des fins de conservation et pour fournir une source analytique pour AIOps, qui peut être appliquée pour optimiser le modèle d’intégrité de l’application et les procédures opérationnelles.
Reportez-vous aux charges de travail stratégiques Well-Architected : actions prédictives et opérations d’IA.
Flux de requête et de processeur
Cette image montre le flux de requête et de processeur d’arrière-plan de l’implémentation de référence.

La description de ce flux se trouve dans les sections suivantes.
Flux de demande de site web
Une demande pour l’interface utilisateur web est envoyée à un équilibreur de charge global. Pour cette architecture, l’équilibreur de charge global est Azure Front Door.
Les règles WAF sont évaluées. Les règles WAF affectent positivement la fiabilité du système en se protégeant contre diverses attaques telles que l’écriture de scripts intersite (XSS) et l’injection de SQL. Azure Front Door retourne une erreur au demandeur si une règle WAF est violée et que le traitement s’arrête. S’il n’y a pas de règles WAF violées, Azure Front Door continue de traiter.
Azure Front Door utilise des règles de routage pour déterminer le pool principal auquel transférer une demande. Comment les demandes sont mises en correspondance avec une règle de routage. Dans cette implémentation de référence, les règles de routage permettent à Azure Front Door d’acheminer les demandes d’interface utilisateur et d’API front-end vers différentes ressources principales. Dans ce cas, le modèle « /* » correspond à la règle de routage de l’interface utilisateur. Cette règle route la requête vers un pool principal qui contient des comptes de stockage avec des sites web statiques qui hébergent l’application monopage (SPA). Azure Front Door utilise la priorité et le poids attribués aux back-ends du pool pour sélectionner le serveur principal pour acheminer la requête. Méthodes de routage du trafic vers l’origine. Azure Front Door utilise des sondes d’intégrité pour s’assurer que les requêtes ne sont pas routées vers les back-ends qui ne sont pas sains. Le SPA est servi à partir du compte de stockage sélectionné avec un site web statique.
Notes
Les termes pools principaux et back-ends dans Azure Front Door Classic sont appelés groupes d’origine et origines dans Azure Front Door Standard ou niveaux Premium.
Le SPA effectue un appel d’API à l’hôte frontal Azure Front Door. Le modèle de l’URL de requête d’API est « /api/* ».
Flux de requête d’API front-end
Les règles WAF sont évaluées comme à l’étape 2.
Azure Front Door correspond à la requête à la règle de routage d’API par le modèle « /api/* ». La règle de routage d’API route la requête vers un pool principal qui contient les adresses IP publiques pour les contrôleurs d’entrée NGINX qui savent comment acheminer les requêtes vers le service approprié dans Azure Kubernetes Service (AKS). Comme avant, Azure Front Door utilise la priorité et le poids attribués aux back-ends pour sélectionner le serveur principal de contrôleur d’entrée NGINX correct.
Pour les requêtes GET, l’API front-end effectue des opérations de lecture sur une base de données. Pour cette implémentation de référence, la base de données est une instance Azure Cosmos DB globale. Azure Cosmos DB dispose de plusieurs fonctionnalités qui facilitent la configuration d’une charge de travail stratégique, notamment la possibilité de configurer facilement des régions à plusieurs écritures, ce qui permet un basculement automatique pour les lectures et les écritures dans les régions secondaires. L’API utilise le Kit de développement logiciel (SDK) client configuré avec une logique de nouvelle tentative pour communiquer avec Azure Cosmos DB. Le SDK détermine l’ordre optimal des régions de base de données disponibles Azure Cosmos DB à communiquer en fonction du paramètre ApplicationRegion.
Pour les requêtes POST ou PUT, l’API front-end effectue des écritures dans un répartiteur de messages. Dans l’implémentation de référence, le répartiteur de messages est Azure Event Hubs. Vous pouvez choisir Service Bus alternativement. Un gestionnaire lit ultérieurement les messages du répartiteur de messages et effectue les écritures requises dans Azure Cosmos DB. L’API utilise le Kit de développement logiciel (SDK) client pour effectuer des écritures. Le client peut être configuré pour les nouvelles tentatives.
Flux du processeur en arrière-plan
Les processeurs en arrière-plan traitent les messages du répartiteur de messages. Les processeurs en arrière-plan utilisent le Kit de développement logiciel (SDK) client pour effectuer des lectures. Le client peut être configuré pour les nouvelles tentatives.
Les processeurs en arrière-plan effectuent les opérations d’écriture appropriées sur l’instance globale d’Azure Cosmos DB. Les processeurs en arrière-plan utilisent le Kit de développement logiciel (SDK) client configuré avec une nouvelle tentative pour se connecter à Azure Cosmos DB. La liste des régions préférées du client peut être configurée avec plusieurs régions. Dans ce cas, en cas d’échec d’une écriture, la nouvelle tentative est effectuée dans la région préférée suivante.
Zones de conception
Nous vous suggérons d’explorer ces domaines de conception pour obtenir des recommandations et des bonnes pratiques lors de la définition de votre architecture stratégique.
| Zone de conception | Description |
|---|---|
| Conception des applications | Modèles de conception qui permettent la mise à l’échelle et la gestion des erreurs. |
| Plateforme d’application | Choix et atténuations de l’infrastructure pour les cas d’échec potentiels. |
| Plateforme de données | Choix dans les technologies de magasin de données, informés en évaluant les caractéristiques requises en termes de volume, de vélocité, de variété et de véracité. |
| Réseau et connectivité | Considérations relatives au réseau pour le routage du trafic entrant vers des empreintes. |
| Modélisation de l’intégrité | Considérations relatives à l’observabilité par le biais de l’analyse de l’impact client en corrélation avec la surveillance afin de déterminer l’intégrité globale de l’application. |
| Déploiement et test | Stratégies pour les pipelines CI/CD et les considérations d’automatisation, avec des scénarios de test incorporés, tels que des tests de charge synchronisés et des tests d’injection de défaillances (chaos). |
| Sécurité | Atténuation des vecteurs d’attaque par le biais du modèle Microsoft Confiance nulle. |
| Procédures opérationnelles | Processus liés au déploiement, à la gestion des clés, à la mise à jour corrective et aux mises à jour. |
** Indique les considérations relatives à la zone de conception spécifiques à cette architecture.
Ressources associées
Pour obtenir de la documentation sur les services Azure utilisés dans cette architecture, consultez ces articles.
- Azure Front Door
- Azure Cosmos DB
- Azure Container Registry
- Azure Log Analytics
- Azure Key Vault
- Azure Service Bus
- Azure Kubernetes Service
- Azure Application Insights
- Azure Event Hubs
- Stockage Blob Azure
Déployer cette architecture
Déployez l’implémentation de référence pour obtenir une compréhension complète des ressources considérées, notamment la façon dont elles sont opérationnelles dans un contexte stratégique. Il contient un guide de déploiement destiné à illustrer une approche orientée solution pour le développement d’applications stratégiques sur Azure.
Étapes suivantes
Si vous souhaitez étendre l’architecture de référence avec des contrôles réseau sur le trafic d’entrée et de sortie, considérez cette architecture.