Vue d’ensemble de l’indexation dans Azure Cosmos DB
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB est une base de données indépendante des schémas qui vous permet d’itérer sur votre application sans avoir à vous soucier de la gestion des schémas ou des index. Par défaut, Azure Cosmos DB indexe automatiquement toutes les propriétés de tous les éléments de votre conteneur sans avoir à définir de schéma ou configurer d’index secondaires.
L’objectif de cet article est d’expliquer comment Azure Cosmos DB indexe les données et comment il utilise les index pour améliorer les performances des requêtes. Nous vous recommandons de parcourir cette section avant de découvrir comment personnaliser les stratégies d’indexation.
Des éléments aux arborescences
Chaque fois qu’un élément est stocké dans un conteneur, son contenu est projeté sous forme de document JSON, puis converti en une représentation arborescente. Cette conversion signifie que chaque propriété de cet élément est représentée comme nœud dans une arborescence. Un pseudo nœud est créé en tant que parent pour toutes les propriétés de premier niveau de l’élément. Les nœuds terminaux contiennent des valeurs scalaires réelles effectuées par un élément.
Par exemple, tenez compte de cet élément :
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Cette arborescence représente l’exemple d’élément JSON :
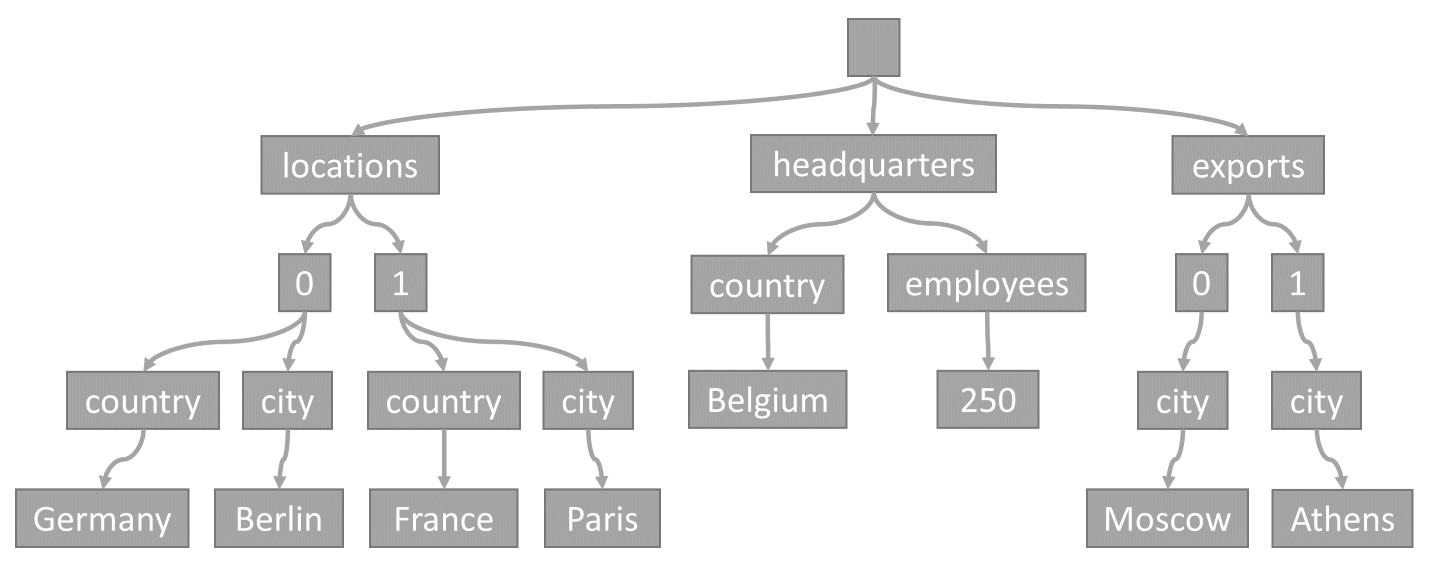
Notez comment les tableaux sont encodés dans l’arborescence : chaque entrée d’un tableau reçoit un nœud intermédiaire étiqueté avec l’index de cette entrée dans le tableau (0, 1, et ainsi de suite).
Des arborescences aux chemins de propriété
Azure Cosmos DB transforme les éléments en arborescences, car cela permet au système de référencer les propriétés avec leurs chemins dans ces arborescences. Pour obtenir le chemin d’accès d’une propriété, nous pouvons parcourir l’arborescence entre le nœud racine et cette propriété, et concaténer les étiquettes de chaque nœud traversé.
Voici les chemins pour chaque propriété de l’exemple d’élément décrit précédemment :
/locations/0/country: "Germany"/locations/0/city: "Berlin"/locations/1/country: "France"/locations/1/city: "Paris"/headquarters/country: "Belgium"/headquarters/employees: 250/exports/0/city: "Moscow"/exports/1/city: "Athens"
Azure Cosmos DB indexe efficacement le chemin de chaque propriété et sa valeur correspondante quand un élément est écrit.
Types d’index
Azure Cosmos DB prend actuellement en charge trois types d’index. Vous pouvez configurer ces types d’index lors de la définition de la stratégie d’indexation.
Index de plage
Les index de plage sont basés sur une structure ordonnée de type arborescence. Le type d’index plage est utilisé pour les types de requête suivants :
Requêtes d’égalité :
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Correspondance d’égalité sur un élément de tableau
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Requêtes de plage :
SELECT * FROM container c WHERE c.property > 'value'Notes
(fonctionne pour
>,<,>=,<=,!=)Vérification de la présence d’une propriété :
SELECT * FROM c WHERE IS_DEFINED(c.property)Fonctions système String :
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")Requêtes
ORDER BY:SELECT * FROM container c ORDER BY c.propertyRequêtes
JOIN:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Les index plage sont utilisables sur des valeurs scalaires (chaîne ou nombre). La stratégie d’indexation par défaut pour les conteneurs nouvellement créés applique des index de plage pour les chaînes ou les nombres. Pour savoir comment configurer des index plage, consultez les exemples de stratégie d’indexation de plage
Notes
Une clause ORDER BY qui commande par une seule propriété a toujours besoin d’un index plage et échouera si le chemin d’accès qu’elle référence n’en a pas. De même, une requête ORDER BY qui commande selon plusieurs propriétés nécessite toujours un index composite.
Index spatial
Les index spatiaux permettent d’exécuter des requêtes efficaces sur des objets géospatiaux comme des points, des lignes, des polygones et des multipolygones. Ces requêtes utilisent des mots clés ST_DISTANCE, ST_WITHIN, ST_INTERSECTS. Voici quelques exemples qui utilisent le type d’index spatial :
Requêtes de distance géospatiale :
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Géospatial dans les requêtes :
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Requêtes d’intersection géospatiale :
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Les index spatiaux sont utilisables sur des objets GeoJSON correctement formatés . Les points, les LineStrings, les polygones et les multipolygones sont actuellement pris en charge. Pour savoir comment configurer des index spatiaux, consultez les exemples de stratégie d’indexation spatiale
Index composites
Les index composites augmentent l’efficacité quand vous effectuez des opérations sur plusieurs champs. Le type d’index composite est utilisé pour les types de requête suivants :
Requêtes
ORDER BYsur plusieurs propriétés :SELECT * FROM container c ORDER BY c.property1, c.property2Requêtes avec un filtre et
ORDER BY. Ces requêtes peuvent utiliser un index composite si la propriété de filtre est ajoutée à la clauseORDER BY.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Les requêtes avec un filtre sur deux ou plusieurs propriétés où au moins une propriété est un filtre d'égalité
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Tant qu’un prédicat de filtre utilise un type d’index, le moteur de requête évalue celui-ci en premier avant d’analyser le reste. Par exemple, si vous avez une requête SQL comme SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
La requête ci-dessus filtre d’abord les entrées où firstName = « Andrew » à l’aide de l’index. Elle transmet ensuite toutes les entrées firstName = « Andrew » par un pipeline pour évaluer le prédicat du filtre CONTAINS.
Vous pouvez accélérer les requêtes et éviter les analyses de conteneur complètes quand vous utilisez des fonctions qui effectuent une analyse complète comme CONTAINS. Vous pouvez ajouter d’autres prédicats de filtre qui utilisent l’index pour accélérer ces requêtes. L’ordre des clauses de filtre n’est pas important. Le moteur de requête détermine les prédicats les plus sélectifs et exécute la requête en conséquence.
Pour savoir comment configurer des index composites, consultez les exemples de stratégie d’indexation composite
Index vectoriels
Les index vectoriels augmentent l’efficacité lors de l’exécution de recherches vectorielles à l’aide de la fonction système VectorDistance. Les recherches vectorielles vont avoir une latence considérablement plus faible, un débit plus élevé et une consommation de RU moindre lors de l’utilisation d’un index vectoriel.
Pour savoir comment configurer des index vectoriels, consultez les exemples de stratégie d’indexation vectorielle
Requêtes de recherche vectorielle
ORDER BY:SELECT c.name FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Projection du score de similarité dans des requêtes de recherche vectorielle :
SELECT c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Filtres de plage sur le score de similarité.
SELECT c.name FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)Important
Les index vectoriels doivent être définis à la création du conteneur et ne peuvent pas être modifiés une fois créés. Dans une version ultérieure, les index vectoriels vont être modifiables.
Utilisation de l’index
Le moteur de requête peut évaluer les filtres de requête de cinq façons, de la plus efficace à la moins efficace :
- Recherche dans l'index
- Analyse précise de l'index
- Analyse développée de l’index
- Analyse complète de l'index
- Analyse complète
Quand vous indexez des chemins de propriétés, le moteur de requête utilise automatiquement l’index de la manière la plus efficace possible. En dehors de l’indexation des nouveaux chemins de propriétés, vous n’avez pas besoin de configurer quoi que ce soit pour optimiser la façon dont les requêtes utilisent l’index. Les frais d’unité de requête (RU, Request Unit) d’une requête correspondent à une combinaison des frais d’utilisation de l’index et de chargement des éléments.
Voici un tableau qui résume les différentes façons dont les index sont utilisés dans Azure Cosmos DB :
| Type de recherche dans l’index | Description | Exemples courants | Frais RU d’utilisation de l’index | Charge RU issue du chargement des éléments à partir d’un magasin de données transactionnel |
|---|---|---|---|---|
| Recherche dans l'index | Lecture des valeurs indexées requises uniquement et chargement des éléments correspondants uniquement à partir du magasin de données transactionnel | Filtres d’égalité, IN | Constants par filtre d’égalité | Augmentent en fonction du nombre d’éléments présents dans les résultats de la requête |
| Analyse précise de l'index | Recherche binaire des valeurs indexées requises uniquement et chargement des éléments correspondants uniquement à partir du magasin de données transactionnel | Comparaisons de plages (>, <, <= ou >=), StartsWith | Comparables à la recherche dans l’index ; augmentent légèrement en fonction de la cardinalité des propriétés indexées | Augmentent en fonction du nombre d’éléments présents dans les résultats de la requête |
| Analyse développée de l’index | Recherche optimisée (mais moins efficace qu’une recherche binaire) de valeurs indexées et chargement des éléments correspondants uniquement à partir du magasin de données transactionnel | StartsWith (non-respect de la casse), StringEquals (non-respect de la casse) | Augmentent légèrement en fonction de la cardinalité des propriétés indexées | Augmentent en fonction du nombre d’éléments présents dans les résultats de la requête |
| Analyse complète de l'index | Lecture d’un ensemble distinct de valeurs indexées requises uniquement et chargement des éléments correspondants uniquement à partir du magasin de données transactionnel | Contains, EndsWith, RegexMatch, LIKE | Augmentent de façon linéaire en fonction de la cardinalité des propriétés indexées | Augmentent en fonction du nombre d’éléments présents dans les résultats de la requête |
| Analyse complète | Charger tous les éléments à partir du magasin de données transactionnelles | Upper, Lower | N/A | Augmentent en fonction du nombre d’éléments présents dans le conteneur |
Lorsque vous écrivez des requêtes, utilisez les prédicats de filtre qui exploite l’index aussi efficacement que possible. Par exemple, si StartsWith et Contains fonctionnent pour votre cas d’usage, optez pour StartsWith car il effectue une analyse précise plutôt qu’une analyse complète de l’index.
Informations sur l’utilisation des index
Dans cette section, nous allons aborder plus en détail la façon dont les requêtes utilisent les index. Ce niveau de détail n’est pas nécessaire pour commencer à utiliser Azure Cosmos DB, mais il est documenté ici pour les utilisateurs curieux. Nous faisons référence à l’exemple d’élément partagé précédemment dans ce document :
Exemples d’éléments :
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB utilise un index inversé. Cet index fonctionne en faisant correspondre chacun des chemins JSON avec l’ensemble des éléments qui contiennent cette valeur. Le mappage des ID d’élément est représenté sur différentes pages d’index du conteneur. Voici un exemple de diagramme d’un index inversé pour un conteneur comprenant les deux exemples d’éléments :
| Chemin d’accès | Valeur | Liste des ID d’élément |
|---|---|---|
| /locations/0/country | Allemagne | 1 |
| /locations/0/country | Irlande | 2 |
| /locations/0/city | Berlin | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | France | 1 |
| /locations/1/city | Paris | 1 |
| /headquarters/country | Belgique | 1, 2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
L’index inversé possède deux attributs importants :
- Pour un chemin donné, les valeurs sont triées par ordre croissant. Par conséquent, le moteur de requête peut facilement traiter
ORDER BYà partir de l’index. - Pour un chemin donné, le moteur de requête peut analyser l’ensemble distinct de valeurs possibles afin d’identifier les pages d’index contenant des résultats.
Le moteur de requête peut utiliser l’index inversé de quatre façons différentes :
Recherche dans l'index
Considérez la requête suivante :
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
Le prédicat de requête (filtrage sur les éléments dont le pays/région de l’une des localisations est « France ») correspond au chemin mis en évidence dans ce diagramme :
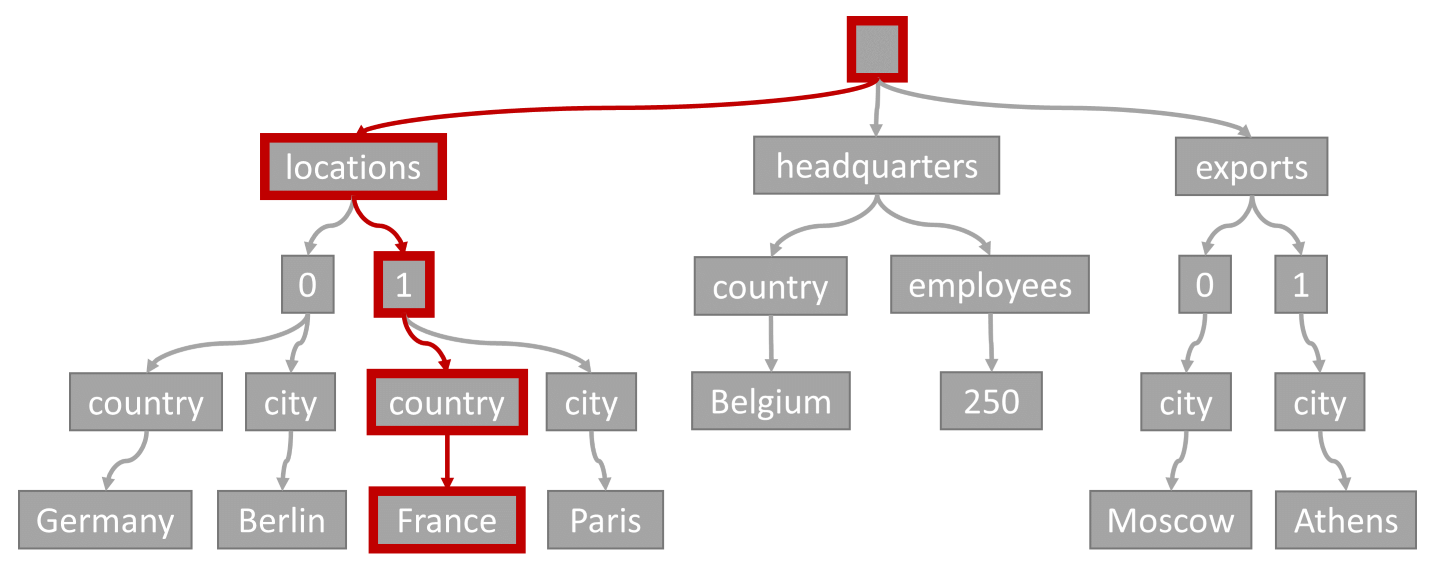
Cette requête possède un filtre d’égalité. Après avoir parcouru cette arborescence, nous pouvons donc rapidement identifier les pages d’index qui contiennent les résultats de la requête. Dans ce cas, le moteur de requête lit les pages d’index qui contiennent l’élément 1. La recherche dans l’index constitue la manière la plus efficace d’utiliser l’index. En effet, il suffit de lire les pages d’index nécessaires et de ne charger que les éléments dans les résultats de la requête. Par conséquent, le temps de recherche dans l’index et les frais RU associés sont extrêmement faibles, quel que soit le volume total de données.
Analyse précise de l'index
Considérez la requête suivante :
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Le prédicat de requête (filtrage sur des éléments contenant plus de 200 employés) peut être évalué avec une analyse précise de l’index du chemin headquarters/employees. Dans le cadre d’une analyse précise de l’index, le moteur de requête commence par effectuer une recherche binaire de l’ensemble distinct de valeurs possibles pour trouver l’emplacement de la valeur 200 du chemin headquarters/employees. Les valeurs de chaque chemin étant triées par ordre croissant, il est facile pour le moteur de requête d’effectuer une recherche binaire. Une fois qu’il a trouvé la valeur 200, il commence à lire toutes les pages d’index restantes (dans le sens croissant).
Le moteur de requête peut effectuer une recherche binaire pour éviter d’analyser les pages d’index inutiles. De ce fait, les analyses précises de l’index ont tendance à présenter une latence et des frais RU comparables à ceux des opérations de recherche dans l’index.
Analyse développée de l’index
Considérez la requête suivante :
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Le prédicat de requête (filtrage sur les éléments dont le siège social se trouve dans une localisation qui commence par « United » sans respect de la casse) peut être évalué avec une analyse développée de l’index du chemin headquarters/country. Les opérations qui effectuent une analyse développée de l’index présentent des optimisations qui évitent d’avoir à analyser toutes les pages d’index, mais sont légèrement plus coûteuses que la recherche binaire d’une analyse précise de l’index.
Par exemple, quand il évalue StartsWith avec respect de la casse, le moteur de requête recherche différentes combinaisons possibles de valeurs en majuscules et en minuscules dans l’index. Cette optimisation évite au moteur de requête de lire la plupart des pages d’index. D’autres fonctions système présentent des optimisations différentes pour ne pas avoir à lire chaque page d’index. Elles sont regroupées dans la catégorie « Analyse développée de l’index ».
Analyse complète de l'index
Considérez la requête suivante :
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Le prédicat de requête (filtrage sur les éléments dont le siège social se trouve dans une localisation qui contient « United ») peut être évalué avec une analyse de l’index du chemin headquarters/country. Contrairement à une analyse précise de l’index, une analyse complète de l’index analyse toujours l’ensemble des valeurs possibles pour identifier les pages d’index où se trouvent les résultats. Dans ce cas, Contains est exécuté sur l’index. Le temps de recherche dans l’index et les frais RU des analyses de l’index augmentent avec la cardinalité du chemin. En d’autres termes, plus le moteur de requête a de valeurs distinctes possibles à analyser, plus la latence et les frais RU sont élevés dans une analyse complète de l’index.
Par exemple, considérons deux propriétés : town et country. La cardinalité de town est 5 000 et celle de country est 200. Voici deux exemples de requêtes contenant chacun une fonction système Contains qui effectue une analyse complète de l’index sur la propriété town. La première requête utilise plus de RU que la deuxième, car la cardinalité de town est supérieure à celle de country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Analyse complète
Il arrive que le moteur de requête ne parvienne pas à évaluer un filtre de requête à l’aide de l’index. Dans ce cas, le moteur de requête doit charger tous les éléments du magasin transactionnel pour évaluer le filtre de requête. Les analyses complètes n’utilisent pas l’index et ont une charge RU qui augmente de façon linéaire avec la taille totale des données. Heureusement, les opérations qui exigent des analyses complètes sont rares.
Requêtes de recherche vectorielle sans index vectoriel défini
Si vous ne définissez pas de stratégie d’index vectoriel et que vous utilisez la fonction système VectorDistance dans une clause ORDER BY, cela entraîne une analyse complète et une charge de RU supérieure à une stratégie d’index vectoriel définie. De même, si vous utilisez VectorDistance avec la valeur booléenne de force brute définie sur true, mais vous n’avez également pas défini d’index flat pour le chemin de vecteur, une analyse complète se produit.
Requêtes avec expressions de filtre complexes
Dans les exemples précédents, nous n’avons examiné que des requêtes avec expressions de filtre simples (par exemple un seul filtre d’égalité ou de plage). En réalité, la plupart comportent des expressions de filtre bien plus complexes.
Considérez la requête suivante :
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Pour exécuter cette requête, le moteur de requête doit effectuer une recherche dans l’index sur headquarters/employees et une analyse complète de l’index sur headquarters/country. Le moteur de requête possède des heuristiques internes qu’il utilise pour évaluer l’expression de filtre de requête aussi efficacement que possible. Dans ce cas, il évite d’avoir à lire les pages d’index inutiles en commençant par la recherche dans l’index. Si, par exemple, seuls 50 éléments correspondent au filtre d’égalité, il ne doit évaluer Contains que sur les pages d’index qui contiennent ces éléments. Une analyse complète de l’index de l’ensemble du conteneur n’est pas nécessaire.
Fonctions d’agrégation scalaires avec l’index
Les requêtes avec fonctions d’agrégation doivent reposer exclusivement sur l’index pour pouvoir l’utiliser.
Dans certains cas, l’index peut retourner des faux positifs. Par exemple, lorsque Contains est évalué sur l’index, le nombre de correspondances dans l’index peut être supérieur au nombre de résultats de la requête. Le moteur de requête charge toutes les correspondances de l’index, évalue le filtre sur les éléments chargés et ne retourne que les bons résultats.
Pour la plupart des requêtes, le chargement de faux positifs dans les correspondances n’a aucun effet notable sur l’utilisation de l’index.
Par exemple, considérez la requête suivante :
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
La fonction système Contains pouvant retourner des faux positifs dans les correspondances, le moteur de requête doit vérifier si chaque élément chargé correspond à l’expression de filtre. Dans cet exemple, le moteur de requête n’a que peu d’éléments à charger en plus. L’impact sur l’utilisation de l’index et la charge RU est donc minime.
Cependant, les requêtes avec fonctions d’agrégation doivent reposer exclusivement sur l’index pour pouvoir l’utiliser. Prenons par exemple la requête suivante avec un agrégat Count :
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Comme dans le premier exemple, la fonction système Contains est susceptible de retourner des faux positifs dans les correspondances. Contrairement à la requête SELECT * toutefois, la requête Count ne peut pas évaluer l’expression de filtre sur les éléments chargés pour vérifier toutes les correspondances d’index. La requête Count doit reposer exclusivement sur l’index. Si une expression de filtre risque de retourner des faux positifs dans les correspondances, le moteur de requête a donc recours à une analyse complète.
Les requêtes comportant les fonctions d’agrégation suivantes doivent reposer exclusivement sur l’index. L’évaluation de certaines fonctions système exige donc une analyse complète.
Étapes suivantes
Découvrez plus en détail l’indexation dans les articles suivants :