Gérer les stratégies d’indexation dans Azure Cosmos DB
Dans Azure Cosmos DB, les données sont indexées suivant les stratégies d’indexation définies pour chaque conteneur. La stratégie d’indexation par défaut pour les conteneurs nouvellement créés applique des index de plage pour les chaînes ou les nombres. Vous pouvez remplacer cette stratégie par votre propre stratégie d’indexation personnalisée.
Notes
La méthode de mise à jour des stratégies d’indexation décrite dans cet article s’applique uniquement à Azure Cosmos DB for NoSQL. Si vous souhaitez en savoir plus sur l’indexation, veuillez consulter les rubriques Azure Cosmos DB for MongoDB et Indexation secondaire dans Azure Cosmos DB for Apache Cassandra.
Exemples de stratégie d’indexation
Voici quelques exemples de stratégies d’indexation présentées dans leur format JSON. Ils apparaissent sur le Portail Azure au format JSON. Les mêmes paramètres peuvent être définis par le biais de l’interface Azure CLI ou de n’importe quel SDK.
Stratégie de refus pour exclure de façon sélective certains chemins de propriété
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
Stratégie d’acceptation pour inclure de façon sélective certains chemins de propriété
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
Notes
Nous vous recommandons généralement d’utiliser une stratégie d’indexation de refus. Azure Cosmos DB indexe de manière proactive toute nouvelle propriété qui pourrait être ajoutée à votre modèle de données.
Utilisation d’un index spatial uniquement sur un chemin de propriété spécifique
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
Exemples de stratégie d’indexation vectorielle
En plus d’inclure ou d’exclure des chemins pour les propriétés individuelles, vous pouvez également spécifier un index vectoriel. En général, vous devez spécifier des index vectoriels lorsque la fonction système VectorDistance est utilisée afin de mesurer la similarité entre un vecteur de requête et une propriété vectorielle.
Remarque
Avant de continuer, vous devez activer l’indexation et recherche vectorielle NoSQL d’Azure Cosmos DB.
Important
Une stratégie d’indexation vectorielle doit se trouver sur le même chemin que celui défini dans la stratégie vectorielle du conteneur. Découvrez-en davantage sur les stratégies de vecteur de conteneur.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
},
{
"path": "/vector/*"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
Important
Chemin vectoriel ajouté à la section « excludedPaths » de la stratégie d’indexation pour garantir un niveau de performance optimisé pour l’insertion. Ne pas ajouter le chemin vectoriel à « excludedPaths » entraîne une charge RU et une latence plus élevées pour les insertions vectorielles.
Important
Actuellement, les stratégies vectorielles et les index vectoriels sont immuables après la création. Pour apporter des modifications, créez une collection.
Vous pouvez définir les types de stratégies d’index vectoriel suivants :
| Type | Description | Dimensions maximales |
|---|---|---|
flat |
Stocke les vecteurs sur le même index que d’autres propriétés indexées. | 505 |
quantizedFlat |
Quantifie (compresse) les vecteurs avant le stockage sur l’index. Cela peut améliorer la latence et le débit au prix d’une précision légèrement moins grande. | 4096 |
diskANN |
Crée un index basé sur DiskANN pour une recherche approximative rapide et efficace. | 4096 |
Les types d’index flat et quantizedFlat tirent profit de l’index d’Azure Cosmos DB pour stocker, puis lire chaque vecteur lors de l’exécution d’une recherche vectorielle. Les recherches vectorielles avec un index flat sont des recherches par force brute et produisent une exactitude de 100 %. Toutefois, il existe une limitation de dimensions 505 pour les vecteurs sur un index plat.
L’index quantizedFlat stocke les vecteurs quantifiés ou compressés sur l’index. Les recherches vectorielles avec un index quantizedFlat sont également des recherches par force brute, mais leur exactitude peut être légèrement inférieure à 100 %, car les vecteurs sont quantifiés avant l’ajout à l’index. Toutefois, les recherches vectorielles avec quantized flat doivent avoir une latence plus faible, un débit plus élevé et un coût de RU moins élevé que les recherches vectorielles sur un index flat. Il s’agit d’une bonne option pour les scénarios où vous utilisez des filtres de requête pour limiter la recherche vectorielle à un ensemble relativement petit de vecteurs.
L’index diskANN est un index distinct défini spécifiquement pour les vecteurs tirant profit de DiskANN, suite d’algorithmes d’indexation de vecteurs hautement performante développée par Microsoft Research. Les index DiskANN peuvent offrir une certaine latence, le nombre de requêtes par seconde (QPS) le plus élevé et les requêtes de coût de RU les plus faibles à une exactitude élevée. Toutefois, puisque DiskANN est un index du plus proche voisin (ANN), l’exactitude peut être inférieure à quantizedFlat ou flat.
Les index diskANN et quantizedFlat peuvent prendre des paramètres facultatifs de génération d’index pouvant être utilisés pour ajuster l’exactitude par rapport au compromis de latence qui s’applique à tous les index vectoriels des plus proches voisins approximatifs.
quantizationByteSize: définit la taille (en octets) pour la quantification de produit. Valeur Min=1, Par défaut=dynamique (le système décide), Max=512. La définition sur une taille plus grande peut entraîner des recherches vectorielles de plus haute précision au détriment d’une latence supérieure et d’un coût de RU plus élevé. Cela s’applique aux types d’indexquantizedFlatetDiskANN.indexingSearchListSize: définit le nombre de vecteurs à rechercher pendant la construction d’une génération d’index. Valeur Min=10, Par défaut=100, Max=500. La définition sur une taille plus grande peut entraîner des recherches vectorielles d’exactitude plus élevées au détriment de temps plus longs de génération d’index et de latences d’ingestion vectorielle supérieures. Cela s’applique aux indexDiskANNuniquement.
Exemples de stratégie d’indexation de tuple
Cet exemple de stratégie d’indexation définit un index de tuple sur events.name et events.category
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{"path":"/*"},
{"path":"/events/[]/{name,category}/?"}
],
"excludedPaths":[],
"compositeIndexes":[]
}
L’index ci-dessus est utilisé pour la requête ci-dessous.
SELECT *
FROM root r
WHERE
EXISTS (SELECT VALUE 1 FROM ev IN r.events
WHERE ev.name = ‘M&M’ AND ev.category = ‘Candy’)
Exemples de stratégies d’indexation composite
En plus d’inclure ou d’exclure des chemins pour les propriétés individuelles, vous pouvez également spécifier un index composite. Pour effectuer une requête qui a une clause ORDER BY pour plusieurs propriétés, un index composite est requis sur ces propriétés. Si la requête contient des filtres, ainsi que le tri sur plusieurs propriétés, vous pouvez avoir besoin de plusieurs index composites.
Les index composites présentent également un avantage en termes de niveau de performance pour les requêtes qui ont plusieurs filtres ou à la fois un filtre et une clause ORDER BY.
Notes
Un chemin composite a un /? implicite, car seule la valeur scalaire sur ce chemin est indexée. Le caractère générique /* n’est pas pris en charge dans les chemins composites. Vous ne devez pas spécifier /? ou /* dans un chemin composite. Les chemins composites respectent également la casse.
Index composite défini pour (name asc, age desc)
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
L’index composite sur le nom et l’âge est requis pour les requêtes suivantes :
Requête 1 :
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
Requête 2 :
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
Cet index composite est utile aux requêtes suivantes et optimise les filtres :
Requête 3 :
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
Requête 4 :
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
Index composite défini pour (name ASC, age ASC) et (name ASC, age DESC)
Vous pouvez définir plusieurs index composites au sein de la même stratégie d’indexation.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Index composite défini pour (name ASC, age ASC)
Vous n’êtes pas obligé de spécifier l’ordre. S’il n’est pas spécifié, l’ordre est croissant.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
Exclusion de tous les chemins d’accès à la propriété mais maintien de l’indexation active
Vous pouvez utiliser cette stratégie quand la fonctionnalité de durée de vie (TTL) est active, mais qu’aucun index supplémentaire n’est nécessaire pour utiliser Azure Cosmos DB comme magasin de clés-valeurs pur.
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
Aucune indexation
Cette stratégie désactive l’indexation. Si indexingMode est défini sur none, vous ne pouvez pas définir de TTL sur le conteneur.
{
"indexingMode": "none"
}
Mie à jour d’une stratégie d’indexation
Dans Azure Cosmos DB, vous pouvez mettre à jour la stratégie d’indexation à l’aide de l’une des méthodes suivantes :
- À partir du portail Azure
- Utilisation de l’interface de ligne de commande Azure (CLI)
- Utilisation de PowerShell
- À l’aide de l’un des Kits de développement logiciel (SDK)
Une mise à jour de la stratégie d’indexation déclenche une transformation d’index. La progression de cette transformation peut également être suivie à partir des SDK.
Notes
Lorsque vous mettez à jour la stratégie d’indexation, les écritures dans Azure Cosmos DB sont ininterrompues. En savoir plus sur l’indexation des transformations.
Important
La suppression d’un index entre immédiatement en vigueur, tandis que l’ajout d’un nouvel index prend un certain temps, car il nécessite une transformation d’indexation. Lorsque vous remplacez un index par un autre (par exemple, en remplaçant un index de propriété unique par un index composite), veillez à ajouter d’abord le nouvel index, puis attendez que la transformation d’index se termine avant de supprimer l’index précédent de la stratégie d’indexation. Dans le cas contraire, cela affectera négativement votre capacité à interroger l’index précédent et peut interrompre toutes les charges de travail actives qui font référence à l’index précédent.
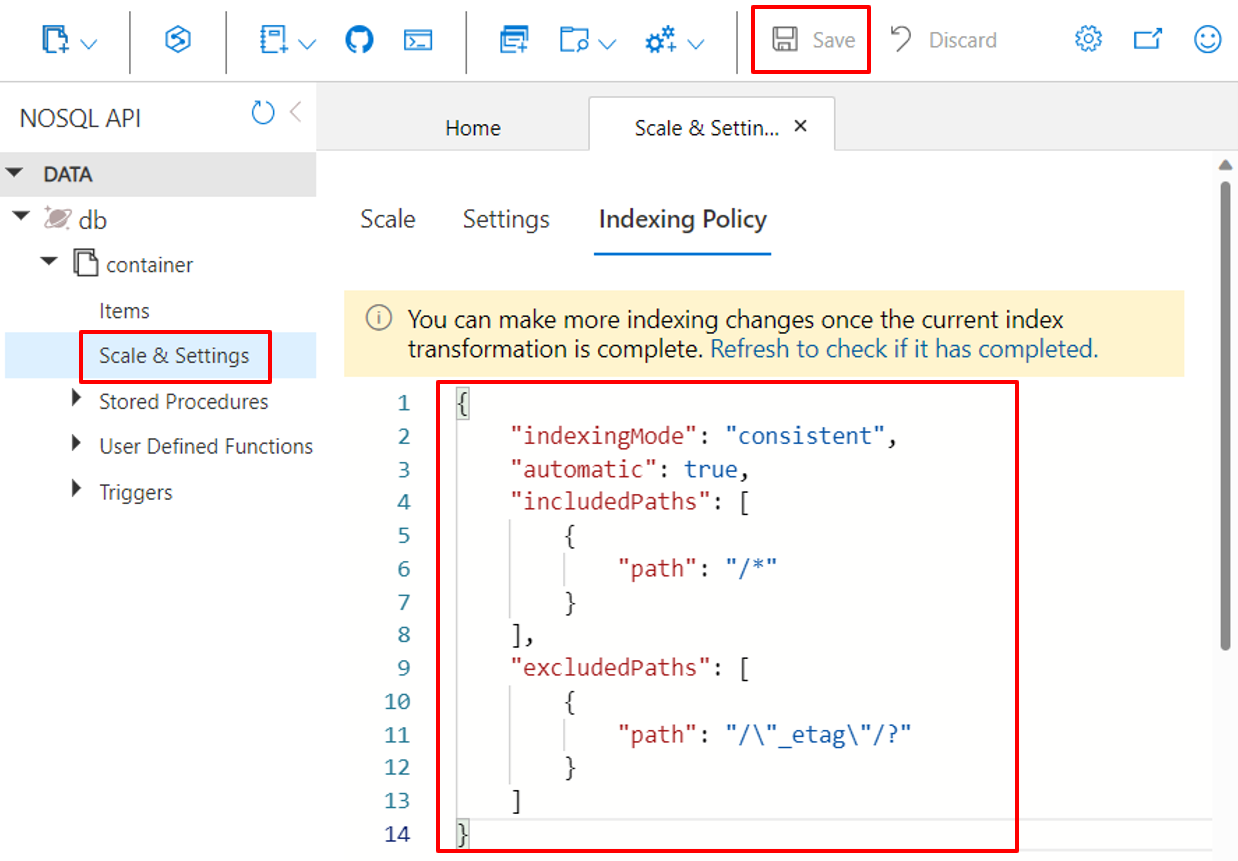
Utilisation du portail Azure
Les conteneurs Azure Cosmos DB stockent leur stratégie d’indexation sous la forme d’un document JSON que le Portail Azure vous permet de modifier directement.
Connectez-vous au portail Azure.
Créez un compte Azure Cosmos DB ou sélectionnez un compte existant.
Ouvrez le volet Explorateur de données, puis sélectionnez le conteneur avec lequel vous voulez travailler.
Sélectionnez Mise à l’échelle et paramètres.
Modifiez le document JSON de stratégie d’indexation, comme indiqué dans ces exemples.
Lorsque vous avez terminé, sélectionnez Enregistrer.
Utilisation de l’interface de ligne de commande Microsoft Azure
Pour créer un conteneur avec une stratégie d’indexation personnalisée, veuillez consulter la rubrique Créer un conteneur avec une stratégie d’index personnalisée à l’aide d’Azure CLI.
Utiliser PowerShell
Pour créer un conteneur avec une stratégie d’indexation personnalisée, veuillez consulter Créer un conteneur avec une stratégie d’index personnalisée à l’aide de PowerShell.
Utiliser le kit de développement logiciel (SDK) .NET
L’objet ContainerProperties du Kit de développement logiciel (SDK) .NET v3 expose une propriété IndexingPolicy qui vous permet de changer la valeur IndexingMode, puis d’ajouter ou de supprimer des valeurs IncludedPaths et ExcludedPaths. Si vous souhaitez en savoir plus, veuillez consulter la rubrique Démarrage rapide : bibliothèque de client Azure Cosmos DB for NoSQL pour .NET.
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
Pour suivre la progression de la transformation de l’index, vous devez passer un objet RequestOptions qui définit la propriété PopulateQuotaInfo sur true. Récupérez la valeur de l’en-tête de réponse x-ms-documentdb-collection-index-transformation-progress.
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
Quand vous définissez une stratégie d’indexation personnalisée pendant la création d’un conteneur, l’API Fluent du Kit de développement logiciel (SDK) V3 vous permet d’écrire cette définition de façon concise et efficace :
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
Utiliser le SDK Java
L’objet DocumentCollection du Kit de développement logiciel (SDK) Java expose les méthodes getIndexingPolicy() et setIndexingPolicy(). L’objet IndexingPolicy qu’elles manipulent vous permet de changer le mode d’indexation, et d’ajouter ou de supprimer des chemins inclus ou exclus. Si vous souhaitez en savoir plus, veuillez consulter la rubrique Démarrage rapide : créer une application Java pour gérer les données d’Azure Cosmos DB for NoSQL.
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
Pour suivre la progression de la transformation de l’index sur un conteneur, transmettez un objet RequestOptions qui demande les informations de quota à remplir. Récupérez la valeur de l’en-tête de réponse x-ms-documentdb-collection-index-transformation-progress.
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
Utiliser le SDK Node.js
L’interface ContainerDefinition du Kit de développement logiciel (SDK) expose une propriété indexingPolicy qui vous permet de changer la valeur indexingMode, puis d’ajouter ou de supprimer des valeurs includedPaths et excludedPaths. Si vous souhaitez en savoir plus, veuillez consulter la rubrique Démarrage rapide : bibliothèque de client Azure Cosmos DB for NoSQL pour Node.js.
Récupérez les détails du conteneur :
const containerResponse = await client.database('database').container('container').read();
Définissez le mode d’indexation sur cohérent :
containerResponse.body.indexingPolicy.indexingMode = "consistent";
Ajoutez un chemin inclus comprenant un index spatial :
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
Ajoutez un chemin exclu :
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
Mettez à jour le conteneur avec les modifications :
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
Pour suivre la progression de la transformation de l’index sur un conteneur, transmettez un objet RequestOptions qui définit la propriété populateQuotaInfo sur true. Récupérez la valeur de l’en-tête de réponse x-ms-documentdb-collection-index-transformation-progress.
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
Ajoutez un index composite :
console.log("create container with composite indexes");
const containerDefWithCompositeIndexes = {
id: "containerWithCompositeIndexingPolicy",
indexingPolicy: {
automatic: true,
indexingMode: IndexingMode.consistent,
includedPaths: [
{
path: "/*",
},
],
excludedPaths: [
{
path: '/"systemMetadata"/*',
},
],
compositeIndexes: [
[
{ path: "/field", order: "ascending" },
{ path: "/key", order: "ascending" },
],
],
},
};
const containerWithCompositeIndexes = (
await database.containers.create(containerDefWithCompositeIndexes)
).container;
Utiliser le SDK Python
Lorsque vous utilisez le Kit de développement logiciel (SDK) Python V3, la configuration du conteneur est gérée comme un dictionnaire. Depuis ce dictionnaire, vous pouvez accéder à la stratégie d’indexation et à tous ses attributs. Si vous souhaitez en savoir plus, veuillez consulter la rubrique Démarrage rapide : bibliothèque de client Azure Cosmos DB for NoSQL pour Python.
Récupérez les détails du conteneur :
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
Définissez le mode d’indexation sur cohérent :
container['indexingPolicy']['indexingMode'] = 'consistent'
Définissez une stratégie d’indexation avec un chemin d’accès inclus et un index spatial :
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
Définissez une stratégie d’indexation avec un chemin d’accès exclu :
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
Ajoutez un index composite :
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
Mettez à jour le conteneur avec les modifications :
response = client.ReplaceContainer(containerPath, container)