Intégration et livraison continues sur Azure Databricks avec Azure DevOps
Notes
Cet article couvre Azure DevOps, qui n’est ni fourni ni pris en charge par Databricks. Pour contacter le fournisseur, consultez la page Support Azure DevOps Services.
Cet article vous guide dans la configuration de l’automatisation Azure DevOps pour votre code et vos artefacts qui fonctionnent avec Azure Databricks. Plus précisément, vous configurerez un flux de travail d’intégration et de livraison continues (CI/CD) pour vous connecter à un référentiel Git, exécuter des tâches à l’aide d’Azure Pipelines pour construire et tester unitairement une roue Python (*.whl), et la déployer pour l’utiliser dans les notebooks Databricks.
Workflow de développement CI/CD
Databricks suggère le workflow suivant pour le développement CI/CD avec Azure DevOps :
- Créez un référentiel ou utilisez un référentiel existant avec votre fournisseur Git tiers.
- Connectez votre machine de développement local au même référentiel tiers. Pour obtenir des instructions, consultez la documentation de votre fournisseur Git tiers.
- Extrayez les artefacts mis à jour existants (tels que les notebooks, les fichiers de code et les scripts de génération) vers votre machine de développement locale à partir du référentiel tiers.
- Au besoin, créez, mettez à jour et testez des artefacts sur votre machine de développement locale. Envoyez ensuite les nouveaux artefacts et ceux modifiés de votre machine de développement locale vers le référentiel tiers. Pour obtenir des instructions, consultez la documentation de votre fournisseur Git tiers.
- Répétez les étapes 3 et 4 en fonction des besoins.
- Utilisez Azure DevOps régulièrement comme approche intégrée pour extraire automatiquement des artefacts de votre référentiel tiers, créer, tester et exécuter du code sur un espace de travail Azure Databricks et rendre compte des résultats de test et d’exécution. Bien que vous puissiez exécuter Azure DevOps manuellement, dans des implémentations réelles, vous demandez à votre fournisseur Git tiers d’exécuter Azure DevOps chaque fois qu’un événement spécifique se produit, tel qu’une demande de tirage (pull request) du référentiel.
Il existe de nombreux outils de CI/CD que vous pouvez utiliser pour gérer et exécuter votre pipeline. Cet article explique comment utiliser Azure DevOps. La CI/CD étant un modèle de conception, les étapes et les phases décrites dans l’exemple de cet article sont en principe transposables moyennant quelques modifications du langage de définition du pipeline dans chaque outil. En outre, une grande partie du code de cet exemple de pipeline est un code Python standard que vous pouvez appeler dans d’autres outils.
Conseil
Pour plus d’informations sur l’utilisation de Jenkins avec Azure Databricks au lieu d’Azure DevOps, consultez CI/CD avec Jenkins sur Azure Databricks.
Le reste de cet article décrit deux exemples de pipelines dans Azure DevOps que vous pouvez adapter à vos propres besoins pour Azure Databricks.
À propos de l’exemple
L’exemple de cet article utilise deux pipelines pour collecter, déployer et exécuter un exemple de code Python et des notebooks Python stockés dans un référentiel Git distant.
Le premier pipeline, appelé pipeline de build, prépare les artefacts de build pour le deuxième pipeline, nommé pipeline de mise en production. La séparation entre le pipeline de build et le pipeline de mise en production permet de créer un artefact de build, sans le déployer, ou de déployer simultanément des artefacts à partir de plusieurs builds. Pour construire l’exécution des pipelines de build et de mise en production :
- Créer une machine virtuelle Azure pour le pipeline de build.
- Copier les fichiers de votre référentiel Git sur la machine virtuelle.
- Crée un fichier tar gzip’ed contenant le code Python, les notebooks Python, ainsi que les fichiers de build, de déploiement et d’exécution associés.
- Copie le fichier tar d’archive sous la forme d’un fichier zip dans un emplacement auquel le pipeline de mise en production peut accéder.
- Crée une autre machine virtuelle Azure pour le pipeline de mise en production.
- Récupère le fichier zip à l’emplacement du pipeline de build, puis le dépaquettent pour obtenir le code Python, les notebooks Python, ainsi que les fichiers de build, de déploiement et de paramètres d’exécution associés.
- Déploie le code Python, les notebooks Python, ainsi que les fichiers de build, de déploiement et de paramètres d’exécution associés dans votre espace de travail Azure Databricks distant.
- Génère les fichiers de code du composant de la bibliothèque de paquet wheel Python dans un fichier wheel Python.
- Exécute des tests unitaires sur le code du composant pour vérifier la logique dans un fichier wheel Python.
- Exécute les notebooks Python, dont l’un appelle la fonctionnalité du fichier wheel Python.
À propos de l’interface CLI Databricks
L’exemple de cet article montre comment utiliser l’interface CLI Databricks en mode non interactif au sein d’un pipeline. L’exemple de pipeline de cet article déploie du code, génère une bibliothèque et exécute des notebooks dans votre espace de travail Azure Databricks.
Si vous utilisez l’interface CLI Databricks dans votre pipeline sans implémenter l’exemple de code, de bibliothèque et de notebooks de cet article, effectuez les étapes suivantes :
Préparez votre espace de travail Azure Databricks pour utiliser l’authentification de machine à machine (M2M) OAuth pour l’authentification d’un principal de service. Avant de commencer, vérifiez que vous disposez d’un principal de service Microsoft Entra ID avec un secret OAuth Azure Databricks. Consultez Authentifier l’accès à Azure Databricks avec un principal de service à l’aide d’OAuth (OAuth M2M).
Installez l’interface CLI Databricks dans votre pipeline. Pour cela, ajoutez une tâche Script Bash à votre pipeline qui exécute le script suivant :
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shPour ajouter une tâche Script Bash à votre pipeline, consultez Étape 3.6. Installez l’interface CLI Databricks et les outils de génération wheel Python.
Configurez votre pipeline pour activer l’interface CLI Databricks installée pour authentifier votre principal de service auprès de votre espace de travail. Pour cela, consultez Étape 3.1 : Définir des variables d’environnement pour le pipeline de mise en production.
Ajoutez si nécessaire d’autres tâches Script Bash à votre pipeline pour exécuter vos commandes CLI Databricks. Consultez Commandes CLI Databricks.
Avant de commencer
Pour utiliser l’exemple de cet article, vous devez disposer des éléments suivants :
- Un projet Azure DevOps. Si vous n’en disposez pas encore, créez un projet dans Azure DevOps.
- Un référentiel avec un fournisseur Git pris en charge par Azure DevOps. Vous ajouterez à ce référentiel l’exemple de code Python, l’exemple de notebook Python et les fichiers de paramètres de mise en production associés. Si vous ne disposez pas encore d’un référentiel, créez-en un en suivant les instructions de votre fournisseur Git. Connectez ensuite votre projet Azure DevOps à ce référentiel, si vous ne l’avez pas déjà fait. Pour obtenir des instructions, suivez les liens dans les référentiels sources pris en charge.
- Cet exemple d’article utilise l’authentification OAuth de machine à machine (M2M) pour authentifier un principal de service Microsoft Entra ID auprès d’un espace de travail Azure Databricks. Vous devez disposer d’un principal de service Microsoft Entra ID avec un secret OAuth Azure Databricks pour ce principal de service. Consultez Authentifier l’accès à Azure Databricks avec un principal de service à l’aide d’OAuth (OAuth M2M).
Étape 1 : Ajouter les fichiers de l’exemple à votre référentiel
Ici, dans le référentiel avec votre fournisseur Git tiers, vous ajoutez tous les exemples de fichiers de cet article que vos pipelines Azure DevOps créent, déploient et exécutent sur votre espace de travail Azure Databricks distant.
Étape 1.1 : Ajouter les fichiers de composant du paquet wheel Python
Dans l’exemple de cet article, vos pipelines Azure DevOps effectuent la création et le test unitaire d’un fichier wheel Python. Un notebook Azure Databricks appelle ensuite la fonctionnalité du fichier wheel Python générée.
Pour définir la logique et des tests unitaires pour le fichier wheel Python sur lequel les notebooks s’exécutent à nouveau, créez deux fichiers nommés addcol.py et test_addcol.py à la racine du référentiel, puis ajoutez-les à une structure de dossiers nommée python/dabdemo/dabdemo dans le dossier Libraries, affiché comme suit :
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
Le fichier addcol.py contient une fonction de bibliothèque intégrée dans un fichier wheel Python, puis installée sur des clusters Azure Databricks. Il s’agit d’une fonction simple qui ajoute une nouvelle colonne, remplie par un littéral, à un DataFrame Apache Spark :
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Le fichier test_addcol.py contient des tests pour passer un objet DataFrame fictif à la fonction with_status, définie dans addcol.py. Le résultat est ensuite comparé à un objet DataFrame contenant les valeurs attendues. Si les valeurs correspondent, le test réussit :
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Pour permettre à l’interface CLI Databricks d’empaqueter correctement ce code de bibliothèque dans un fichier wheel Python, créez deux fichiers nommés __init__.py et __main__.py dans le même dossier que les deux fichiers précédents. Créez également un fichier nommé setup.py dans le dossier python/dabdemo, affiché comme suit :
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
Le fichier __init__.py contient le numéro de version et l’auteur de la bibliothèque. Remplacez <my-author-name> par votre nom :
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Le fichier __main__.py contient le point d’entrée de la bibliothèque :
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Le fichier setup.py contient des paramètres supplémentaires pour la création de la bibliothèque dans un fichier wheel Python. Remplacez <my-url>, <my-author-name>@<my-organization> et <my-package-description> par des valeurs valides :
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Étape 1.2 : Ajouter un notebook de test unitaire pour le fichier wheel Python
Plus tard, l’interface CLI Databricks exécute un travail de notebook. Ce travail exécute un notebook Python avec le nom de fichier run_unit_tests.py. Ce notebook exécute pytest par rapport à la logique de la bibliothèque de paquet wheel Python.
Pour exécuter les tests unitaires pour l’exemple de cet article, à la racine de votre référentiel, ajoutez un fichier de notebook nommé run_unit_tests.py avec le contenu suivant :
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Étape 1.3 : Ajouter un notebook qui appelle le fichier wheel Python
Plus tard, l’interface CLI Databricks exécute un autre travail de notebook. Ce notebook crée un objet DataFrame, le transmet à la fonction with_status de la bibliothèque de paquet wheel Python, imprime le résultat et signale les résultats de l’exécution du travail. Créez, à la racine de votre dépôt, un fichier de notebook nommé dabdemo_notebook.py avec le contenu suivant :
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Étape 1.4 : Créer la configuration du pack
L’exemple de cet article utilise des packs de ressources Databricks pour définir les paramètres et les comportements de création, de déploiement et d’exécution du fichier wheel Python, des deux notebooks et du fichier de code Python. Les packs de ressources Databricks, aussi appelés packs, permettent d’exprimer des données, des analyses et des projets ML complets en tant que collection de fichiers sources. Consultez Que sont les packs de ressources Databricks ?.
Pour configurer l’offre groupée pour l’exemple de cet article, créez un fichier nommé databricks.yml à la racine de votre dépôt. Dans cet exemple de fichier databricks.yml, remplacez les espaces réservés suivants :
- Remplacez
<bundle-name>par un nom programmatique unique pour le pack. Par exemple :azure-devops-demo. - Remplacez
<job-prefix-name>par une chaîne pour identifier de manière unique les travaux créés dans votre espace de travail Azure Databricks pour cet exemple. Par exemple :azure-devops-demo. - Remplacez
<spark-version-id>par l’ID de version de Databricks Runtime pour vos clusters de travaux, par exemple13.3.x-scala2.12. - Remplacez
<cluster-node-type-id>par l’ID du type de nœud de cluster pour vos clusters de travaux, par exempleStandard_DS3_v2. - Remarquez que
devdans le mappagetargetsspécifie l’hôte et les comportements de déploiement associés. Dans les implémentations réelles, vous pouvez donner à cette cible un nom différent dans vos propres packs.
Voici les contenus du fichier databricks.yml de cet exemple :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
Pour plus d’informations sur la syntaxe du fichier databricks.yml, consultez Configuration de pack de ressources Databricks.
Étape 2 : Définition du pipeline de build
Azure DevOps fournit une interface utilisateur hébergée dans le cloud pour définir les étapes de votre pipeline CI/CD à l’aide de YAML. Pour plus d’informations sur Azure DevOps et les pipelines, consultez la documentation sur Azure DevOps.
Dans cette étape, vous utilisez une balise YAML pour définir le pipeline de build, lequel génère un artefact de déploiement. Pour déployer le code dans un espace de travail Azure Databricks, vous spécifiez cet artefact de build du pipeline comme une entrée vers un pipeline de mise en production. Vous allez définir ce pipeline de mise en production plus tard.
Pour exécuter des pipelines de build, Azure DevOps fournit des agents d’exécution à la demande hébergés dans le cloud qui prennent en charge les déploiements sur Kubernetes, les machines virtuelles, Azure Functions, Azure Web Apps et bien d’autres cibles. Dans cet exemple, vous utilisez un agent à la demande pour automatiser la création de l’artefact de déploiement.
Définissez l’exemple de pipeline de build de cet article comme suit :
Connectez-vous à Azure DevOps et cliquez sur le lien Se connecter afin d’ouvrir votre projet Azure DevOps.
Remarque
Si le Portail Azure s’affiche au lieu de votre projet Azure DevOps, cliquez sur Plus de services > Organisations Azure DevOps > Mes organisations Azure DevOps et ouvrez votre projet Azure DevOps.
Cliquez sur Pipelines dans la barre latérale, puis sur Pipelines dans le menu Pipelines.
Cliquez sur le bouton Nouveau pipeline et suivez les instructions à l’écran. (Si vous avez déjà des pipelines, cliquez sur Créer un pipeline à la place.) L’éditeur de pipeline s’ouvre après ces instructions. Ici, vous définissez le script de votre pipeline de build dans le fichier
azure-pipelines.ymlqui s’affiche. Si l’éditeur de pipeline n’apparaît pas après le suivi des instructions, sélectionnez le nom du pipeline de build, puis cliquez sur Modifier.Vous pouvez utiliser le sélecteur de branche Git
 pour personnaliser le processus de génération pour chaque branche de votre référentiel Git. Comme bonne pratique CI/CD, n’effectuez aucun travail de production directement dans la branche
pour personnaliser le processus de génération pour chaque branche de votre référentiel Git. Comme bonne pratique CI/CD, n’effectuez aucun travail de production directement dans la branche mainde votre dépôt. Cet exemple suppose qu’une branche nomméereleaseexiste dans le référentiel à utiliser, au lieu demain.
Le script
azure-pipelines.ymldu pipeline de build est stocké par défaut à la racine du référentiel Git distant que vous avez associé au pipeline.Remplacez le contenu de démarrage du fichier
azure-pipelines.ymlde votre pipeline par la définition suivante, puis cliquez sur Enregistrer.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Étape 3 : Définition du pipeline de mise en production
Le pipeline de mise en production déploie les artefacts de build depuis le pipeline de build dans un environnement Azure Databricks. La séparation entre le pipeline de mise en production de cette étape et le pipeline de build des étapes précédentes permet de créer une build sans la déployer, ou de déployer des artefacts simultanément à partir de plusieurs builds.
Dans votre projet Azure DevOps, cliquez sur Mises en production dans le menu Pipelines de la barre latérale.
Cliquez sur Nouveau > Nouveau pipeline de mise en production. (Si vous avez déjà des pipelines, cliquez sur Nouveau pipeline à la place.)
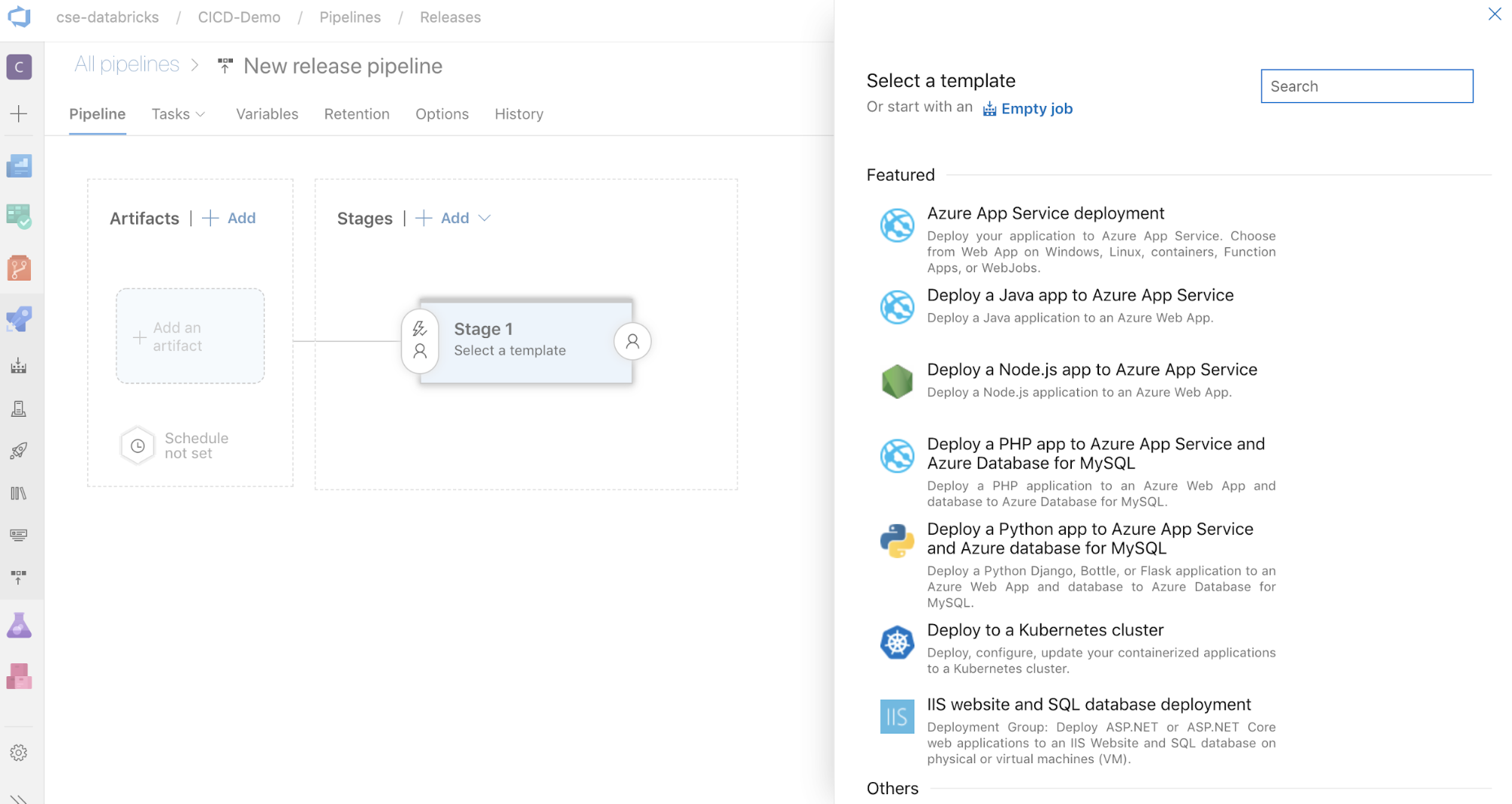
Sur le côté de l’écran se trouve la liste des modèles proposés dans les schémas de déploiement courants. Pour cet exemple de pipeline de mise en production, cliquez sur
 .
.
Dans la zone Artefacts située sur le côté de l’écran, cliquez sur
 . Dans le volet Ajouter un artefact, sélectionnez pour Source (pipeline de build) le pipeline de build que vous avez créé. Cliquez ensuite sur Ajouter.
. Dans le volet Ajouter un artefact, sélectionnez pour Source (pipeline de build) le pipeline de build que vous avez créé. Cliquez ensuite sur Ajouter.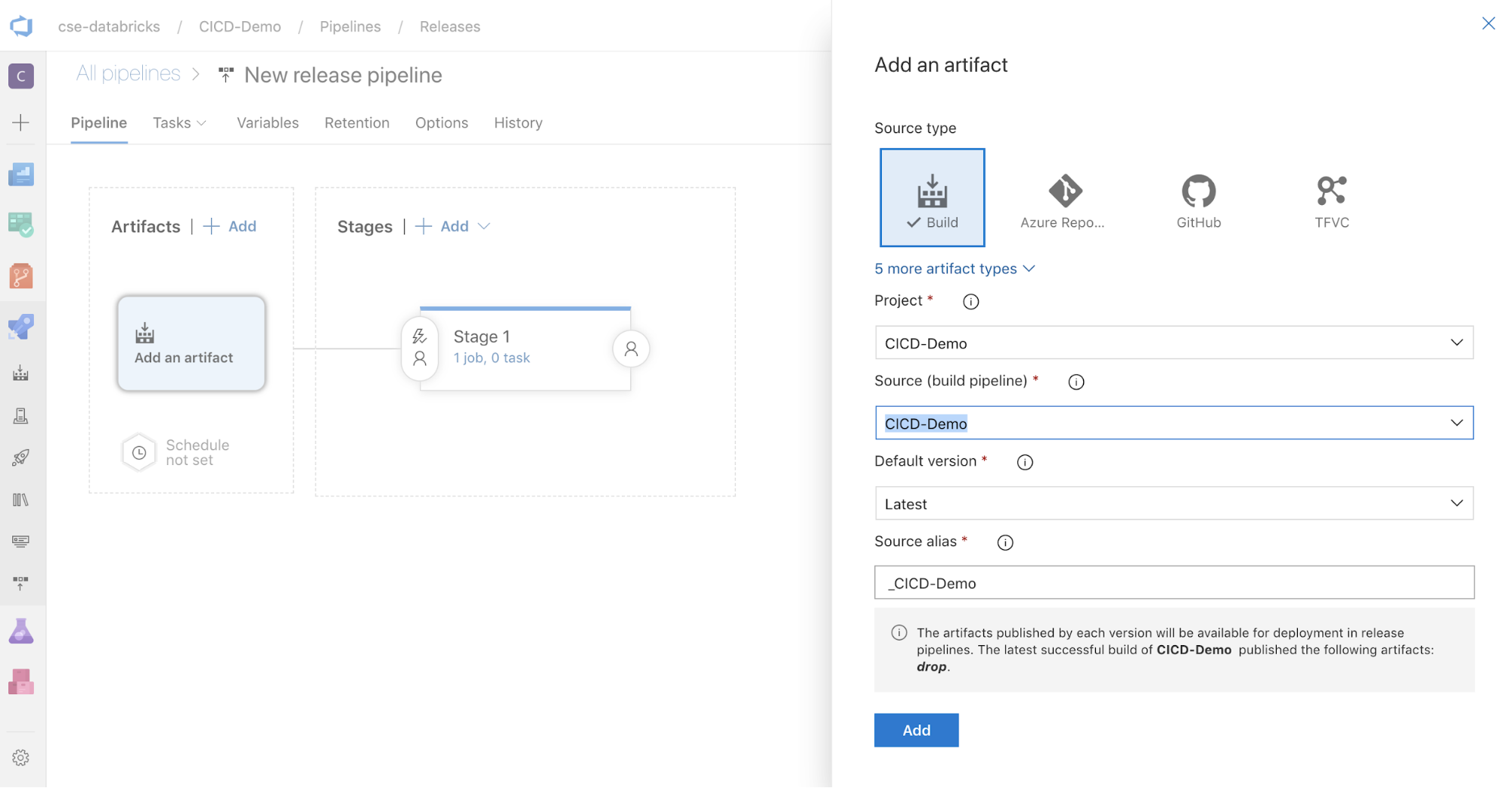
Vous pouvez configurer le mode de déclenchement du pipeline en cliquant sur
 qui affiche les options de déclenchement sur le côté de l’écran. Si vous souhaitez qu’une mise en production soit lancée automatiquement en fonction de la disponibilité de l’artefact de build ou après un flux de travail de demande de tirage (pull request), activez le déclencheur approprié. Dans cet exemple et pour le moment, vous déclenchez manuellement le pipeline de build, puis le pipeline de mise en production à la dernière étape de cet article.
qui affiche les options de déclenchement sur le côté de l’écran. Si vous souhaitez qu’une mise en production soit lancée automatiquement en fonction de la disponibilité de l’artefact de build ou après un flux de travail de demande de tirage (pull request), activez le déclencheur approprié. Dans cet exemple et pour le moment, vous déclenchez manuellement le pipeline de build, puis le pipeline de mise en production à la dernière étape de cet article.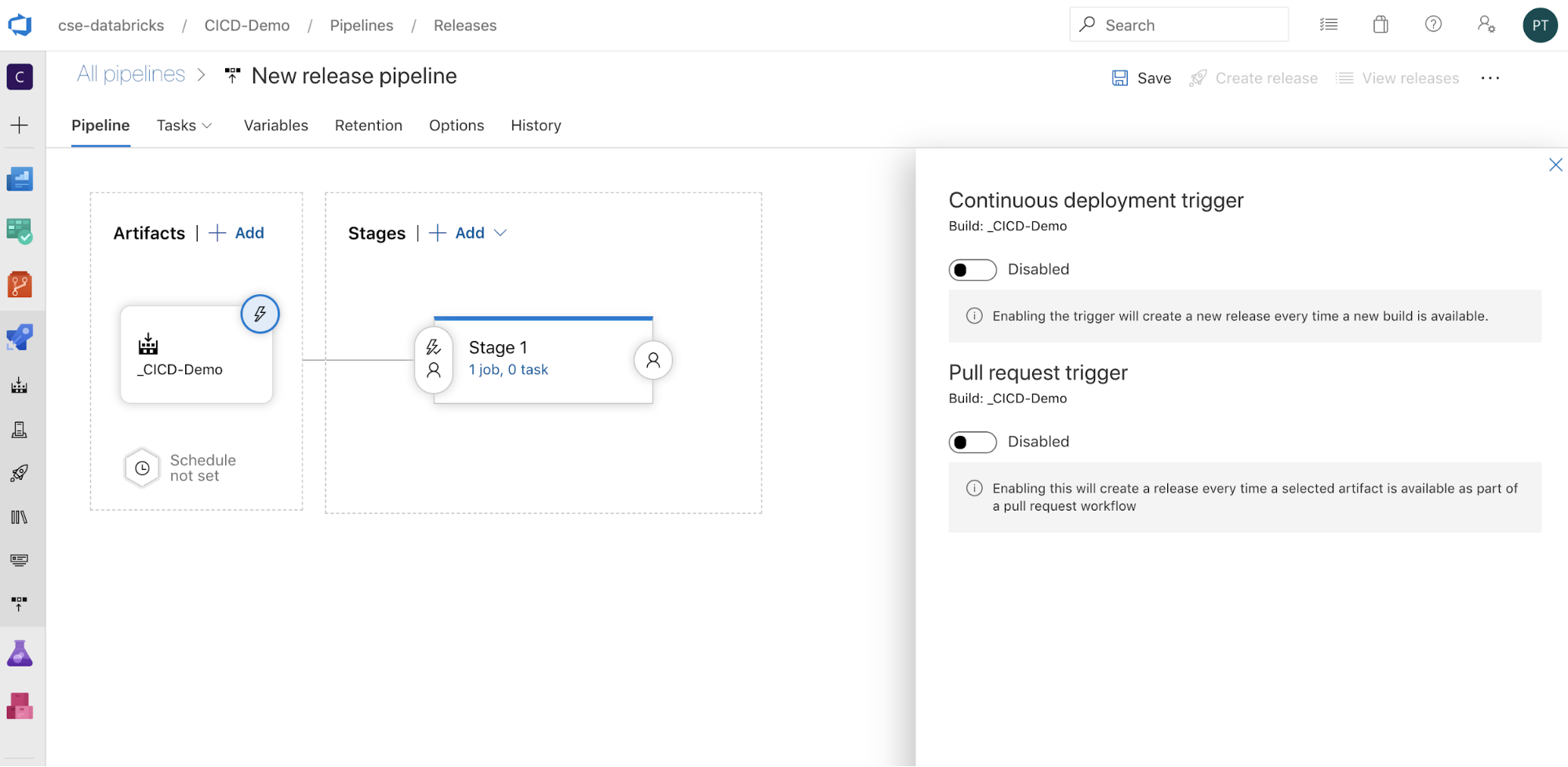
Cliquez sur Enregistrer > OK.
Étape 3.1 : Définir des variables d’environnement pour le pipeline de mise en production
Le pipeline de mise en production de cet exemple s’appuie sur les variables d’environnement suivantes. Pour les ajouter, cliquez sur Ajouter dans la section Variables de pipeline de l’onglet Variables, avec comme Étendue l’Étape 1 :
BUNDLE_TARGETqui doit correspondre au nomtargetdans votre fichierdatabricks.yml. Dans l’exemple de cet article, il s’agit dedev.DATABRICKS_HOST, qui représente l’URL par espace de travail de votre espace de travail Azure Databricks, en commençant parhttps://, par exemplehttps://adb-<workspace-id>.<random-number>.azuredatabricks.net. N’ajoutez pas la barre oblique/de fin après.net.DATABRICKS_CLIENT_ID, qui représente l’ID d’application pour le principal du service Microsoft Entra ID.DATABRICKS_CLIENT_SECRET, qui représente le secret OAuth Azure Databricks pour le principal du service Microsoft Entra ID.
Étape 3.2 : Configuration de l’agent de mise en production du pipeline de mise en production
Cliquez sur le lien 1 travail, 0 tâche dans l’objet 1re phase.
Dans l’onglet Tâches, cliquez sur Travail de l’agent.
Dans la section Sélection de l’agent, sélectionnez Azure Pipelines pour Pool d’agents.
Pour la Spécification de l’agent, sélectionnez l’agent spécifié comme agent de build, dans cet exemple ubuntu-22.04.
Cliquez sur Enregistrer > OK.
Étape 3.3 : Définition de la version de Python de l’agent de mise en production
Cliquez sur le signe plus situé dans la section Travail de l’agent, indiquée par la flèche rouge dans la figure suivante. Une liste de tâches disponibles pouvant faire l’objet d’une recherche s’affiche. Il existe également un onglet Place de marché contenant les plug-ins tiers qui peuvent être utilisés pour compléter les tâches Azure DevOps standard. Vous allez ajouter plusieurs tâches à l’agent de mise en production au cours des étapes suivantes.
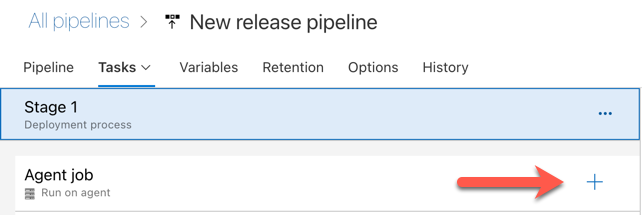
La première tâche à ajouter est Utiliser la version de Python, située dans l’onglet Outil. Si vous ne la trouvez pas, utilisez la zone Recherche pour la localiser. Sélectionnez-le alors, puis cliquez sur le bouton Ajouter situé en regard de la tâche Utiliser la version de Python.
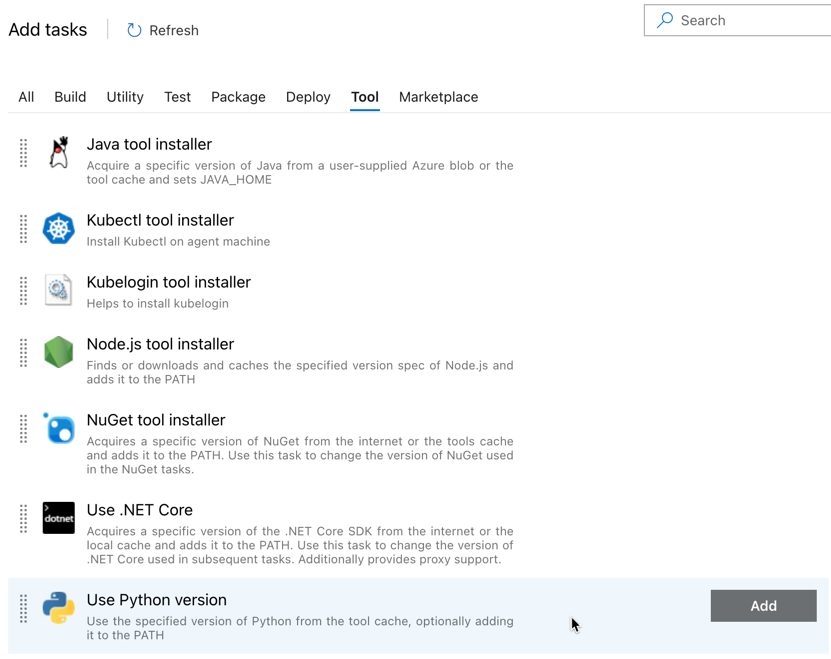
Comme avec le pipeline de build, vous souhaitez vous assurer que la version de Python est compatible avec les scripts appelés dans les tâches suivantes. Dans ce cas, cliquez sur la tâche Utiliser Python 3.x située en regard de la section Travail de l’agent, puis définissez Spécification de version sur
3.10. Définissez également Nom d’affichage surUse Python 3.10. Ce pipeline suppose que vous utilisez Databricks Runtime 13.3 LTS sur le cluster qui a également Python 3.10.12 installé.
Cliquez sur Enregistrer > OK.
Étape 3.4 : Dépaquetage de l’artefact de build du pipeline de build
Demandez maintenant à l’agent de mise en production d’extraire du fichier zip le fichier wheel Python, les fichiers de paramètres de mise en production associés, les notebooks et le fichier de code Python à l’aide de la tâche Extraire les fichiers : cliquez sur le signe plus situé dans la section Travail de l’agent, sélectionnez la tâche Extraire les fichiers dans l’onglet Utilitaire, puis cliquez sur Ajouter.
Cliquez sur la tâche Extraire les fichiers située en regard de la section Travail de l’agent, définissez Archiver les modèles de fichier sur
**/*.zip, puis définissez Dossier Destination sur la variable système$(Release.PrimaryArtifactSourceAlias)/Databricks. Définissez également Nom d’affichage surExtract build pipeline artifact.Notes
$(Release.PrimaryArtifactSourceAlias)représente un alias généré par Azure DevOps pour identifier l’emplacement de source d’artefact principal sur l’agent de mise en production, par exemple_<your-github-alias>.<your-github-repo-name>. Le pipeline de mise en production définit cette valeur comme la variable d’environnementRELEASE_PRIMARYARTIFACTSOURCEALIASdans la phase Initialiser le travail de l’agent de mise en production. Cf. Variables de mise en production et d’artefacts classiques.Définissez Nom d’affichage sur
Extract build pipeline artifact.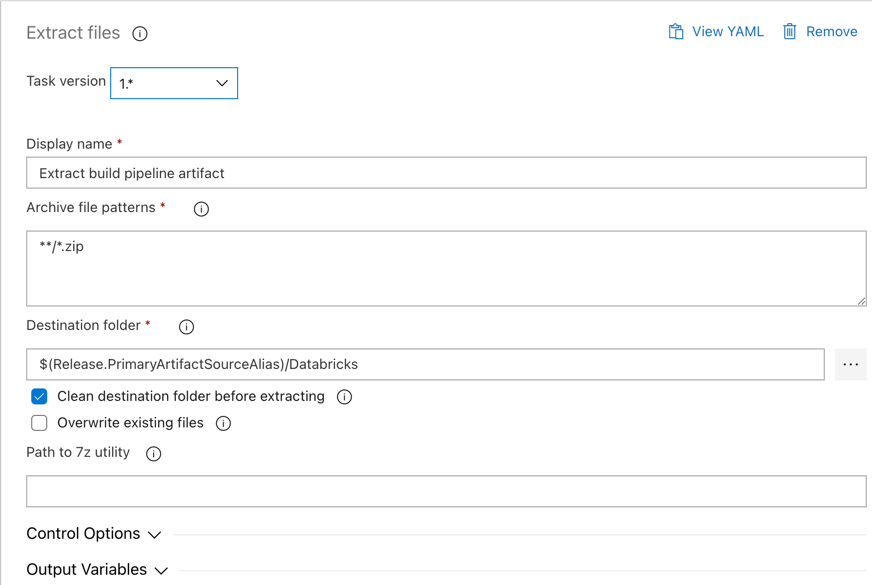
Cliquez sur Enregistrer > OK.
Étape 3.5 : Définir la variable d’environnement BUNDLE_ROOT
Pour que l’exemple de cet article fonctionne comme prévu, vous devez définir une variable d’environnement nommée BUNDLE_ROOT dans le pipeline de mise en production. Les packs de ressources Databricks utilisent cette variable d’environnement pour déterminer l’emplacement du fichier databricks.yml. Pour définir cette variable d’environnement :
Utilisation de la tâche Variables d’environnement : cliquez à nouveau sur le signe plus situé dans la section Travail de l’agent, sélectionnez la tâche Variables d’environnement dans l’onglet Utilitaire, puis cliquez sur Ajouter.
Remarque
Si la tâche Variables d’environnement n’est pas visible sous l’onglet Utilitaire, entrez
Environment Variablesdans la zone de Recherche et suivez les instructions à l’écran pour ajouter la tâche à l’onglet Utilitaire. Cela peut vous obliger à quitter Azure DevOps, puis à revenir à cet emplacement où vous vous êtes arrêté.Pour les Variables d’environnement (séparées par des virgules), entrez la définition suivante :
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Remarque
$(Agent.ReleaseDirectory)représente un alias généré par Azure DevOps pour identifier l’emplacement du répertoire de mise en production sur l’agent de mise en production, par exemple/home/vsts/work/r1/a. Le pipeline de mise en production définit cette valeur comme la variable d’environnementAGENT_RELEASEDIRECTORYdans la phase Initialiser le travail de l’agent de mise en production. Cf. Variables de mise en production et d’artefacts classiques. Pour plus d’informations sur$(Release.PrimaryArtifactSourceAlias), consultez la remarque de l’étape précédente.Définissez Nom d’affichage sur
Set BUNDLE_ROOT environment variable.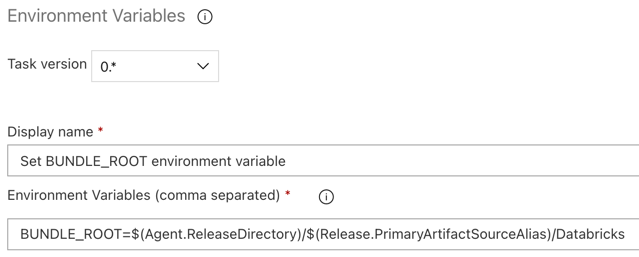
Cliquez sur Enregistrer > OK.
Étape 3.6. Installer l’interface CLI Databricks et les outils de génération wheel Python
Ensuite, installez l’interface CLI Databricks et les outils de génération wheel Python sur l’agent de mise en production. L’agent de mise en production appelle l’interface CLI Databricks et les outils de génération de paquet wheel Python et dans les tâches suivantes. Pour ce faire, utilisez la tâche Bash : cliquez à nouveau sur le signe plus situé dans la section Travail de l’agent, sélectionnez la tâche Bash dans l’onglet Utilitaire, puis cliquez sur Ajouter.
Cliquez sur la tâche Script Bash située en regard de la section Travail de l’agent.
Pour Type sélectionnez Inclus.
Remplacez le contenu de Script par la commande suivante, qui permet d’installer l’interface CLI Databricks et les outils de génération de roue Python :
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelDéfinissez Nom d’affichage sur
Install Databricks CLI and Python wheel build tools.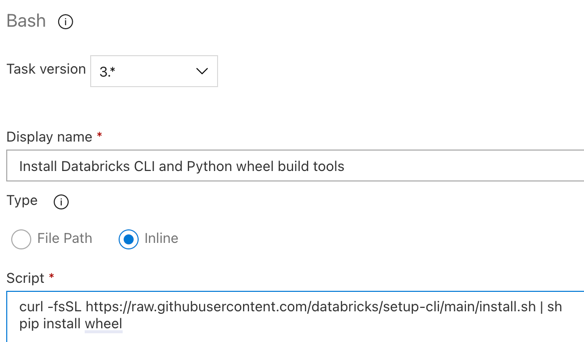
Cliquez sur Enregistrer > OK.
Étape 3.7 : Valider le pack de ressources Databricks
Dans cette étape, vous vous assurez que le fichier databricks.yml est syntaxiquement correct.
Utilisation de la tâche Bash : cliquez à nouveau sur le signe plus situé dans la section Travail de l’agent, sélectionnez la tâche Bash dans l’onglet Utilitaire et cliquez sur Ajouter.
Cliquez sur la tâche Script Bash située en regard de la section Travail de l’agent.
Pour Type sélectionnez Inclus.
Remplacez le contenu du script par la commande suivante. Cette dernière utilise l’interface CLI Databricks pour vérifier si le fichier
databricks.ymlest syntaxiquement correct :databricks bundle validate -t $(BUNDLE_TARGET)Définissez Nom d’affichage sur
Validate bundle.Cliquez sur Enregistrer > OK.
Étape 3.8 : Déployer le pack
Dans cette étape, vous générez le fichier wheel Python et déployez le fichier wheel Python, les deux notebooks Python et le fichier Python du pipeline de mise en production vers votre espace de travail Azure Databricks.
Utilisation de la tâche Bash : cliquez à nouveau sur le signe plus situé dans la section Travail de l’agent, sélectionnez la tâche Bash dans l’onglet Utilitaire et cliquez sur Ajouter.
Cliquez sur la tâche Script Bash située en regard de la section Travail de l’agent.
Pour Type sélectionnez Inclus.
Remplacez le contenu du script par la commande suivante. Cette dernière utilise l’interface CLI Databricks pour générer le fichier wheel Python et déployer les exemples de fichiers de cet article à partir du pipeline de mise en production dans votre espace de travail Azure Databricks :
databricks bundle deploy -t $(BUNDLE_TARGET)Définissez Nom d’affichage sur
Deploy bundle.Cliquez sur Enregistrer > OK.
Étape 3.9 : Exécuter un notebook de test unitaire pour le paquet wheel Python
Dans cette étape, vous exécutez un travail exécutant le notebook de test unitaire dans votre espace de travail Azure Databricks. Ce notebook exécute des tests unitaires par rapport à la logique de la bibliothèque de paquet wheel Python.
Utilisation de la tâche Bash : cliquez à nouveau sur le signe plus situé dans la section Travail de l’agent, sélectionnez la tâche Bash dans l’onglet Utilitaire et cliquez sur Ajouter.
Cliquez sur la tâche Script Bash située en regard de la section Travail de l’agent.
Pour Type sélectionnez Inclus.
Remplacez le contenu du script par la commande suivante. Cette dernière utilise l’interface CLI Databricks pour exécuter le travail dans votre espace de travail Azure Databricks :
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsDéfinissez Nom d’affichage sur
Run unit tests.Cliquez sur Enregistrer > OK.
Étape 3.10 : Exécuter le notebook qui appelle le paquet wheel Python
Dans cette étape, vous exécutez un travail exécutant un autre notebook dans votre espace de travail Azure Databricks. Ce notebook appelle la bibliothèque de paquet wheel Python.
Utilisation de la tâche Bash : cliquez à nouveau sur le signe plus situé dans la section Travail de l’agent, sélectionnez la tâche Bash dans l’onglet Utilitaire et cliquez sur Ajouter.
Cliquez sur la tâche Script Bash située en regard de la section Travail de l’agent.
Pour Type sélectionnez Inclus.
Remplacez le contenu du script par la commande suivante. Cette dernière utilise l’interface CLI Databricks pour exécuter le travail dans votre espace de travail Azure Databricks :
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookDéfinissez Nom d’affichage sur
Run notebook.Cliquez sur Enregistrer > OK.
Vous avez maintenant terminé la configuration de votre pipeline de mise en production. Cela doit ressembler à ceci :
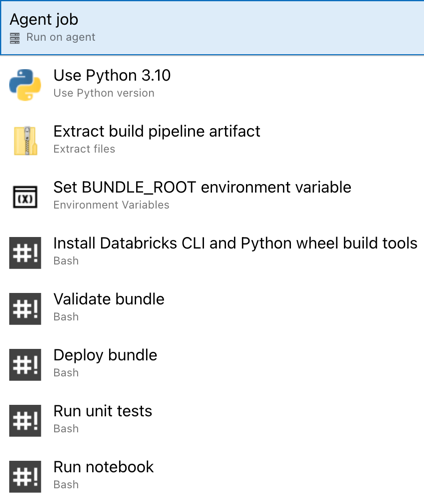
Étape 4 : Exécution des pipelines de build et de mise en production
Dans cette étape, vous exécutez manuellement les pipelines. Pour savoir comment exécuter les pipelines automatiquement, consultez Spécifier des événements déclencheurs de pipelines et des Déclencheurs de mise en production.
Pour exécuter manuellement le pipeline de build :
- Dans le menu Pipelines de la barre latérale, cliquez sur Pipelines.
- Cliquez sur le nom de votre pipeline de build, puis sur Exécuter un pipeline.
- Pour Branche/balise, sélectionnez le nom de la branche de votre référentiel Git contenant tout le code source que vous avez ajouté. Dans cet exemple, nous partons du principe qu’il s’agit de la branche
release. - Cliquez sur Exécuter. La page d’exécution du pipeline de build s’affiche.
- Pour voir la progression du pipeline de build et afficher les journaux associés, cliquez sur l’icône tournante située en regard de la section Travail.
- Une fois que l’icône du travail devient une coche verte, passez à l’exécution du pipeline de mise en production.
Pour exécuter manuellement le pipeline de mise en production :
- Une fois le pipeline de build exécuté avec succès, dans le menu Pipelines de la barre latérale, cliquez sur Mises en production.
- Cliquez sur le nom de votre pipeline de mise en production, puis sur Créer une mise en production.
- Cliquez sur Créer.
- Pour afficher la progression du pipeline de mise en production, dans la liste des versions, cliquez sur le nom de la dernière version.
- Dans la zone Étapes, cliquez sur Étape 1, puis sur Journaux.