CI/CD avec Jenkins sur Azure Databricks
Notes
Cet article couvre Jenkins, qui n’est ni fourni ni pris en charge par Databricks. Pour contacter le fournisseur, consultez la page Aide Jenkins.
Il existe de nombreux outils de CI/CD que vous pouvez utiliser pour gérer et exécuter vos pipelines CI/CD. Cet article explique comment utiliser le serveur d’automatisation Jenkins. La CI/CD est un modèle de conception, de sorte que les étapes et les phases décrites dans cet article devraient pouvoir être transférées moyennant quelques modifications du langage de définition du pipeline dans chaque outil. En outre, une grande partie du code de cet exemple de pipeline exécute du code Python standard, que vous pouvez appeler dans d’autres outils. Pour obtenir une vue d’ensemble de CI/CD sur Azure Databricks, consultez Qu’est-ce que le CI/CD sur Azure Databricks ?.
Pour plus d’informations sur l’utilisation d’Azure DevOps avec Azure Databricks à la place, consultez Intégration et livraison continues sur Azure Databricks avec Azure DevOps.
Workflow de développement CI/CD
Databricks suggère le workflow suivant pour le développement CI/CD avec Jenkins :
- Créez un référentiel ou utilisez un référentiel existant avec votre fournisseur Git tiers.
- Connectez votre machine de développement local au même référentiel tiers. Pour obtenir des instructions, consultez la documentation de votre fournisseur Git tiers.
- Extrayez les artefacts mis à jour existants (tels que les notebooks, les fichiers de code et les scripts de génération) à partir du référentiel tiers vers votre machine de développement local.
- Comme vous le souhaitez, créez, mettez à jour et testez des artefacts sur votre machine de développement local. Envoyez ensuite les nouveaux artefacts et les artefacts modifiés de votre machine de développement local vers le référentiel tiers. Pour obtenir des instructions, consultez la documentation de votre fournisseur Git tiers.
- Répétez les étapes 3 et 4 en fonction des besoins.
- Utilisez Jenkins régulièrement comme approche intégrée pour extraire automatiquement des artefacts de votre référentiel tiers vers votre machine de développement local ou votre espace de travail Azure Databricks ; créer, tester et exécuter du code sur votre machine de développement local ou espace de travail Azure Databricks ; et rendre compte des résultats de test et d’exécution. Bien que vous puissiez exécuter Jenkins manuellement, dans des implémentations réelles, vous demandez à votre fournisseur Git tiers d’exécuter Jenkins chaque fois qu’un événement spécifique se produit, tel qu’une requête de tirage de référentiel.
Le reste de cet article utilise un exemple de projet pour décrire une façon d’utiliser Jenkins pour implémenter le workflow de développement CI/CD précédent.
Pour plus d’informations sur l’utilisation d’Azure DevOps au lieu de Jenkins, consultez Intégration et livraison continues sur Azure Databricks avec Azure DevOps.
Configuration de la machine de développement local
L’exemple de cet article utilise Jenkins pour indiquer à l’interface CLI Databricks et aux packs de ressources Databricks d’effectuer les opérations suivantes :
- Créez un fichier wheel Python sur votre machine de développement local.
- Déployez le fichier wheel Python généré avec des fichiers Python et des notebooks Python supplémentaires de votre machine de développement local vers un espace de travail Azure Databricks.
- Testez et exécutez le fichier wheel et les notebooks Python chargés dans cet espace de travail.
Pour configurer votre machine de développement local pour indiquer à votre espace de travail Azure Databricks d’effectuer les étapes de génération et de chargement pour cet exemple, procédez comme suit sur votre machine de développement local :
Étape 1 : installer les outils requis
Dans cette étape, vous installez les outils de génération de paquet wheel Databricks CLI, Jenkins, jq et Python sur votre machine de développement local. Ces outils sont nécessaires pour exécuter cet exemple.
Installez Databricks CLI version 0.205 ou ultérieure, si vous ne l’avez pas déjà fait. Jenkins utilise l’interface CLI Databricks pour passer le test de cet exemple et exécuter des instructions sur votre espace de travail. Consultez Installer ou mettre à jour l’interface CLI Databricks.
Installez et démarrez Jenkins, si vous ne l’avez pas déjà fait. Consultez Installation de Jenkins pour Linux, macOSou Windows.
Installez jq. Cet exemple utilise
jqpour analyser une sortie de commande au format JSON.Utiliser
pippour installer les outils de génération de paquet wheel Python avec la commande suivante (certains systèmes peuvent vous obliger à utiliserpip3au lieu depip) :pip install --upgrade wheel
Étape 2 : créer un pipeline Jenkins
Dans cette étape, vous utilisez Jenkins pour créer un pipeline Jenkins pour l’exemple de cet article. Jenkins fournit quelques types de projets différents pour créer des pipelines CI/CD. Les pipelines Jenkins fournissent une interface pour définir les étapes d’un pipeline Jenkins en utilisant du code Groovy pour appeler et configurer les plug-ins Jenkins.
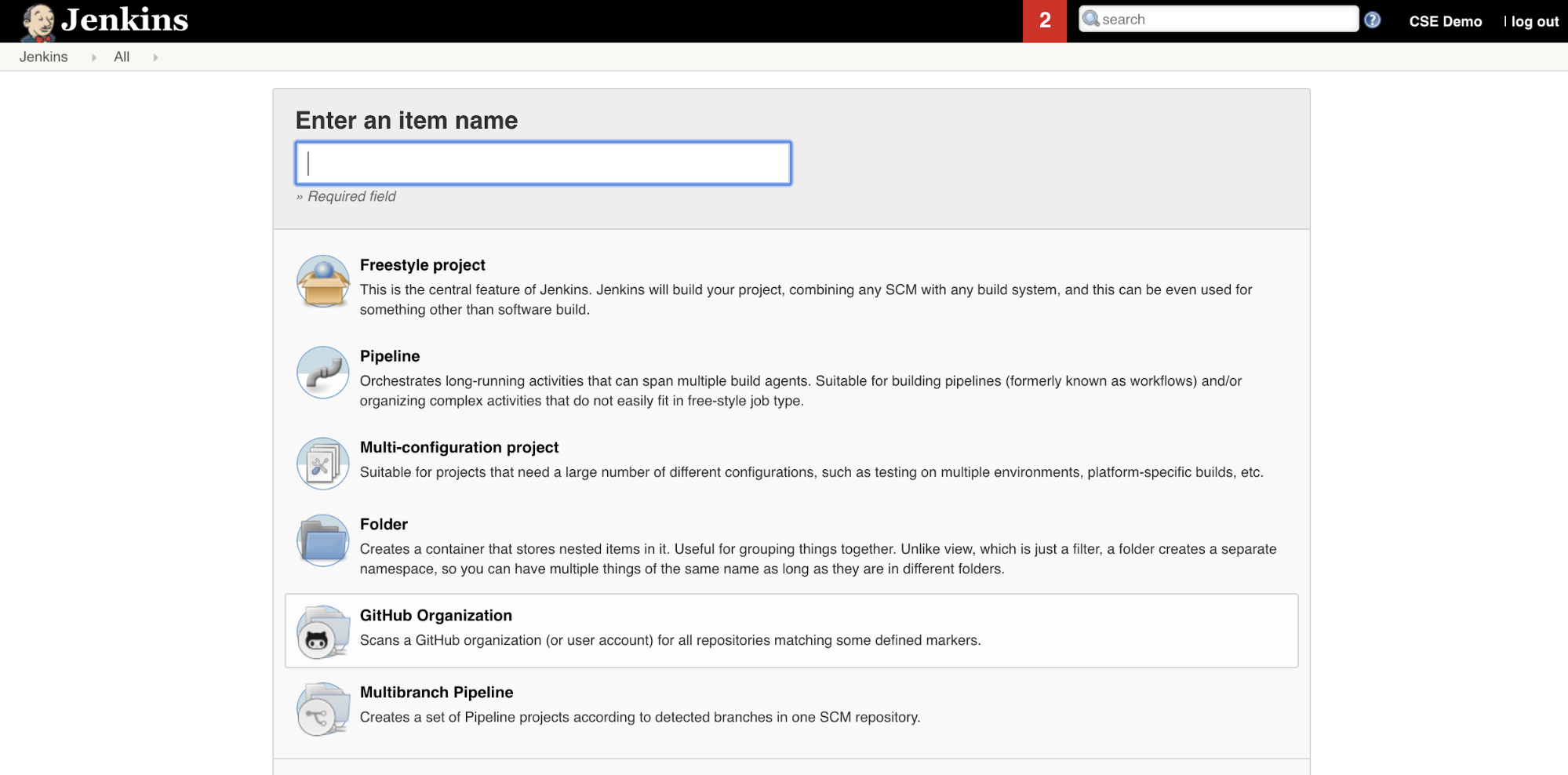
Pour créer le pipeline Jenkins dans Jenkins :
- Après avoir démarré Jenkins, à partir de votre tableau de bord Jenkins, cliquez surNouvel élément.
- Pour Entrer un nom d’élément, tapez un nom pour le pipeline Jenkins, par exemple
jenkins-demo. - Cliquez sur l’icône de type de projet Pipeline.
- Cliquez sur OK. La page Configurer du pipeline Jenkins s’affiche.
- Dans la zone Pipeline, dans la liste déroulante Defintion, sélectionnez Script de pipeline dans SCM.
- Dans la liste déroulante SCM, sélectionnez Git.
- Pour l’URL du référentiel, tapez l’URL du référentiel hébergé par votre fournisseur Git tiers.
- Pour le Spécificateur de branche, tapez
*/<branch-name>, où<branch-name>est le nom de la branche dans votre référentiel que vous souhaitez utiliser, par exemple*/main. - Pour le Chemin d’accès au script, tapez
Jenkinsfile, s’il n’est pas déjà défini. Vous créez leJenkinsfileplus loin dans cet article. - Décochez la case intitulée Validation légère si elle est déjà cochée.
- Cliquez sur Enregistrer.
Étape 3 : ajouter des variables d’environnement globales à Jenkins
Dans cette étape, vous ajoutez trois variables d’environnement globales à Jenkins. Jenkins transmet ces variables d’environnement à l’interface CLI Databricks. L’interface CLI Databricks a besoin des valeurs de ces variables d’environnement pour s’authentifier auprès de votre espace de travail Azure Databricks. Cet exemple utilise l’authentification OAuth machine à machine (M2M) pour un principal de service (bien que d’autres types d’authentification soient également disponibles). Pour configurer l’authentification OAuth M2M pour votre espace de travail Azure Databricks, consultez Authentifier l’accès à Azure Databricks avec un principal de service à l’aide d’OAuth (OAuth M2M).
Les trois variables d’environnement globales pour cet exemple sont les suivantes :
DATABRICKS_HOST, défini sur l’URL de votre espace de travail Azure Databricks, qui commence parhttps://. Consultez Noms d’instance, URL et ID d’espace de travail.DATABRICKS_CLIENT_ID, définie sur l’ID client du principal de service, également appelé ID d’application.DATABRICKS_CLIENT_SECRET, définie sur le secret OAuth Azure Databricks du principal de service.
Pour définir des variables d’environnement globales dans Jenkins à partir de votre tableau de bord Jenkins :
- Dans la barre latérale, cliquez sur Gérer Jenkins.
- Dans la section Configuration du système, cliquez sur Système.
- Dans la section Propriétés globales, cochez la boîte de dialogue Variables d’environnement.
- Cliquez sur Ajouter, puis entrez le nom et la valeur de la variable d’environnement. Répétez cette opération pour chaque variable d’environnement supplémentaire.
- Lorsque vous avez terminé d’ajouter des variables d’environnement, cliquez sur Enregistrer pour revenir à votre tableau de bord Jenkins.
Concevoir le pipeline Jenkins
Jenkins fournit quelques types de projets différents pour créer des pipelines CI/CD. Cet exemple implémente un pipeline Jenkins. Les pipelines Jenkins fournissent une interface pour définir les étapes d’un pipeline Jenkins en utilisant du code Groovy pour appeler et configurer les plug-ins Jenkins.
Vous écrivez une définition de pipeline Jenkins dans un fichier texte appelé Jenkinsfile qui est à son tour enregistré dans le référentiel de contrôle de code source d’un projet. Pour plus d’informations, consultez Pipeline Jenkins. Voici le pipeline Jenkins pour l’exemple de cet article. Dans cet exemple Jenkinsfile, remplacez les espaces réservés suivants :
- Remplacez
<user-name>et<repo-name>avec le nom d’utilisateur et le nom du référentiel hébergé par votre fournisseur Git tiers. Cet article utilise une URL GitHub comme exemple. - Remplacez
<release-branch-name>par le nom de la branche de mise en production dans votre référentiel. Par exemple, cela pourrait êtremain. - Remplacez
<databricks-cli-installation-path>par le chemin d’accès sur votre machine de développement local où l’interface CLI Databricks est installée. Par exemple, sur macOS, cela pourrait être/usr/local/bin. - Remplacez
<jq-installation-path>par le chemin d’accès sur votre machine de développement local oùjqest installé. Par exemple, sur macOS, cela pourrait être/usr/local/bin. - Remplacez
<job-prefix-name>par une chaîne pour identifier de manière unique les travaux Azure Databricks créés dans votre espace de travail pour cet exemple. Par exemple, cela pourrait êtrejenkins-demo. - Notez que
BUNDLETARGETest défini surdev, qui est le nom de la cible du pack de ressources Databricks définie plus loin dans cet article. Dans les implémentations réelles, vous devez le remplacer par le nom de votre propre cible de pack. Plus d’informations sur les cibles de pack sont fournies plus loin dans cet article.
Voici le Jenkinsfile, qui doit être ajouté à la racine de votre référentiel :
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
Le reste de cet article décrit chaque étape de ce pipeline Jenkins et explique comment configurer les artefacts et les commandes pour que Jenkins s’exécute à ce stade.
Extraire les derniers artefacts du référentiel tiers
La première étape de ce pipeline Jenkins, l’étape Checkout, est définie comme suit :
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Cette étape garantit que le répertoire de travail utilisé par Jenkins sur votre machine de développement local possède les derniers artefacts de votre référentiel Git tiers. En règle générale, Jenkins définit ce répertoire de travail sur <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. Cela vous permet, sur la même machine de développement local, de conserver votre propre copie d’artefacts en développement séparément des artefacts que Jenkins utilise à partir de votre référentiel Git tiers.
Valider le pack de ressources Databricks
La deuxième étape de ce pipeline Jenkins, l’étape Validate Bundle, est définie comme suit :
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Cette étape garantit que le pack de ressources Databricks, qui définit les workflows pour le test et l’exécution de vos artefacts, est correct d’un point de vue syntaxique. Les packs de ressources Databricks, aussi appelés packs, permettent d’exprimer des données, des analyses et des projets ML complets en tant que collection de fichiers sources. Consultez Que sont les packs de ressources Databricks ?.
Pour définir le pack pour cet article, créez un fichier nommé databricks.yml à la racine du référentiel cloné sur votre ordinateur local. Dans cet exemple de fichier databricks.yml, remplacez les espaces réservés suivants :
- Remplacez
<bundle-name>par un nom programmatique unique pour le pack. Par exemple, cela pourrait êtrejenkins-demo. - Remplacez
<job-prefix-name>par une chaîne pour identifier de manière unique les travaux Azure Databricks créés dans votre espace de travail pour cet exemple. Par exemple, cela pourrait êtrejenkins-demo. Il doit correspondre à la valeurJOBPREFIXdans votre fichier Jenkinsfile. - Remplacez
<spark-version-id>par l’ID de version de Databricks Runtime pour vos clusters de travaux, par exemple13.3.x-scala2.12. - Remplacez
<cluster-node-type-id>par l’ID de type de nœud pour vos clusters de travaux, par exempleStandard_DS3_v2. - Notez que
devdans le mappagetargetsest identique auBUNDLETARGETde votre fichier Jenkinsfile. Une cible de pack spécifie l’hôte et les comportements de déploiement associés.
Voici le fichier databricks.yml, qui doit être ajouté à la racine de votre référentiel pour que cet exemple fonctionne correctement :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Pour plus d’informations sur le fichier databricks.yml, consultez Configuration de pack de ressources Databricks.
Déployer le pack sur votre espace de travail
La troisième étape du pipeline Jenkins, intitulée Deploy Bundle, est définie comme suit :
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Cette étape effectue deux opérations :
- Étant donné que le mappage
artifactdans le fichierdatabricks.ymlest défini surwhl, cela indique à l’interface CLI Databricks de générer le fichier wheel Python à l’aide du fichiersetup.pyà l’emplacement spécifié. - Une fois que le fichier wheel Python est généré sur votre machine de développement local, l’interface CLI Databricks déploie le fichier wheel Python généré, ainsi que les fichiers et notebooks Python spécifiés dans votre espace de travail Azure Databricks. Par défaut, les packs de ressources Databricks déploient le fichier wheel Python et d’autres fichiers dans
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Pour permettre au fichier wheel Python d’être généré comme spécifié dans le fichier databricks.yml, créez les dossiers et fichiers suivants à la racine de votre référentiel cloné sur votre ordinateur local.
Pour définir la logique et les tests unitaires pour le fichier wheel Python sur lequel le notebook s’exécutera, créez deux fichiers nommés addcol.py et test_addcol.py, et ajoutez-les à une structure de dossiers nommée python/dabdemo/dabdemo dans le dossier Libraries de votre référentiel, visualisée de la manière suivante (les points de suspension indiquent les dossiers omis dans le référentiel, pour être plus concis) :
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Le fichier addcol.py contient une fonction de bibliothèque intégrée dans un fichier wheel Python, puis installée sur un cluster Azure Databricks. Il s’agit d’une fonction simple qui ajoute une nouvelle colonne, remplie par un littéral, à un DataFrame Apache Spark :
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Le fichier test_addcol.py contient des tests pour passer un objet DataFrame fictif à la fonction with_status, définie dans addcol.py. Le résultat est ensuite comparé à un objet DataFrame contenant les valeurs attendues. Si les valeurs correspondent, ce qui est le cas ici, le test est réussi :
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Pour permettre à l’interface CLI Databricks d’empaqueter correctement ce code de bibliothèque dans un fichier wheel Python, créez deux fichiers nommés __init__.py et __main__.py dans le même dossier que les deux fichiers précédents. Créez également un fichier nommé setup.py dans le dossier python/dabdemo, visualisé comme suit (les points de suspension indiquent les dossiers omis, par souci de concision) :
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Le fichier __init__.py contient le numéro de version et l’auteur de la bibliothèque. Remplacez <my-author-name> par votre nom :
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Le fichier __main__.py contient le point d’entrée de la bibliothèque :
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Le fichier setup.py contient des paramètres supplémentaires pour la création de la bibliothèque dans un fichier wheel Python. Remplacez <my-url>, <my-author-name>@<my-organization> et <my-package-description> par des valeurs significatives :
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Tester la logique de composant du paquet wheel Python
L’étape Run Unit Tests, la quatrième étape de ce pipeline Jenkins, utilise pytest pour tester la logique d’une bibliothèque pour s’assurer qu’elle fonctionne comme prévu. Cette étape est définie comme suit :
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Cette étape utilise l’interface CLI Databricks pour exécuter un travail de notebook. Ce travail exécute le notebook Python avec le nom de fichier run-unit-test.py. Ce notebook exécute pytest sur la logique de la bibliothèque.
Pour exécuter les tests unitaires pour cet exemple, ajoutez un fichier de notebook Python nommé run_unit_tests.py avec le contenu suivant à la racine de votre référentiel cloné sur votre ordinateur local :
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Utiliser le paquet wheel Python généré
La cinquième étape de ce pipeline Jenkins, intitulée Run Notebook, exécute un notebook Python qui appelle la logique dans le fichier wheel Python généré de la manière suivante :
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Cette étape exécute l’interface CLI Databricks, qui indique à son tour à votre espace de travail d’exécuter un travail de notebook. Ce notebook crée un objet DataFrame, le transmet à la fonction with_status de la bibliothèque, imprime le résultat et signale les résultats de l’exécution du travail. Créez le notebook en ajoutant un fichier de notebook Python nommé dabdaddemo_notebook.py avec le contenu suivant à la racine de votre référentiel cloné sur votre machine de développement local :
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Évaluer les résultats de l’exécution du travail de notebook
L’étape Evaluate Notebook Runs, la sixième étape de ce pipeline Jenkins, évalue les résultats de l’exécution du travail de notebook précédente. Cette étape est définie comme suit :
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Cette étape exécute l’interface CLI Databricks, qui indique à son tour à votre espace de travail d’exécuter un travail de fichier Python. Ce fichier Python détermine les critères d’échec et de réussite de l’exécution du travail de notebook et signale ce résultat d’échec ou de réussite. Créez un fichier nommé evaluate_notebook_runs.py avec le contenu suivant à la racine de votre référentiel cloné sur votre machine de développement local :
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Importer et signaler des résultats de test
La septième étape de ce pipeline Jenkins, intitulée Import Test Results, utilise l’interface CLI Databricks pour envoyer les résultats de test de votre espace de travail à votre machine de développement local. La huitième et dernière étape, intitulée Publish Test Results, publie les résultats de test sur Jenkins à l’aide du plug-in Jenkins junit. Cela vous permet de visualiser les rapports et les tableaux de bord liés à l’état des résultats de test. Ces étapes sont définies comme suit :
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
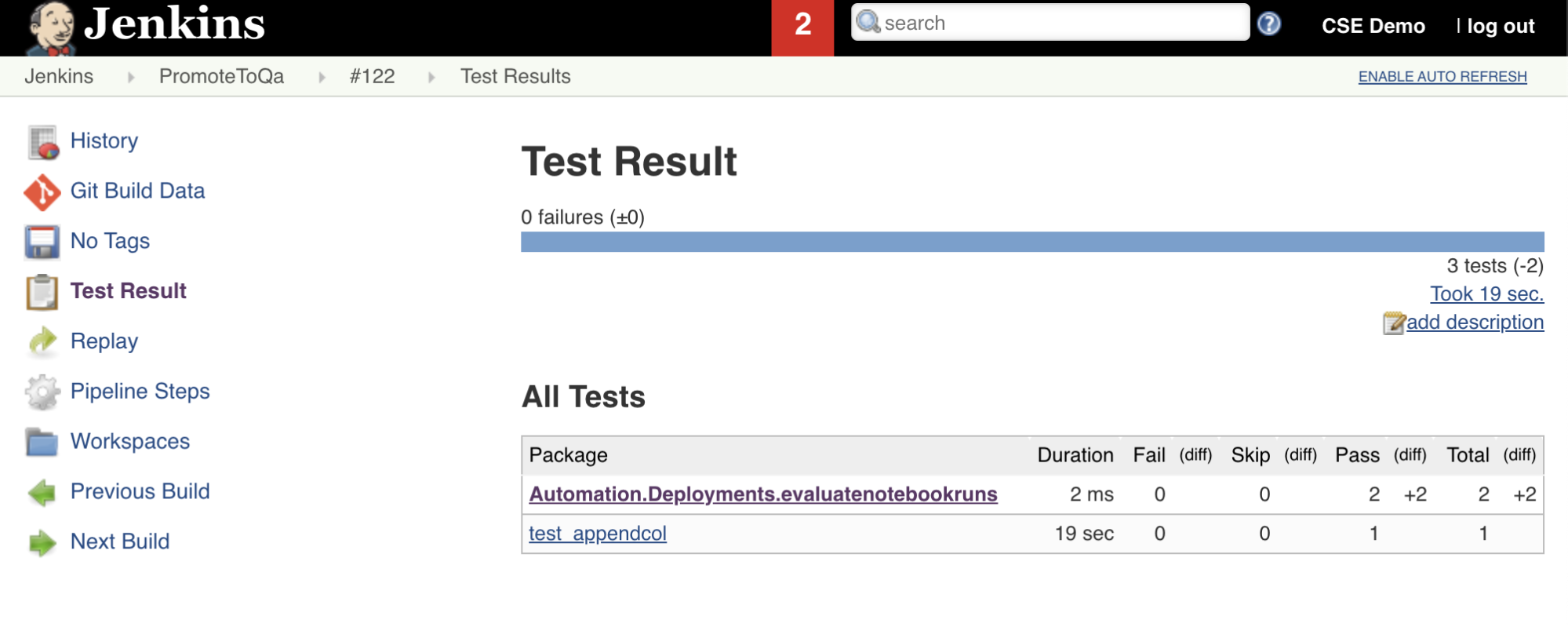
Envoyer (push) toutes les modifications de code à votre référentiel tiers
Vous devez maintenant envoyer (push) le contenu de votre référentiel cloné sur votre machine de développement local vers votre référentiel tiers. Avant d’envoyer (push), vous devez d’abord ajouter les entrées suivantes au fichier .gitignore dans votre référentiel cloné, car vous ne devez probablement pas envoyer (push) les fichiers de travail internes du pack de ressources Databricks, les rapports de validation, les fichiers de build Python et les caches Python dans votre référentiel tiers. En règle générale, vous souhaiterez régénérer de nouveaux rapports de validation et les dernières builds de paquet wheel Python dans votre espace de travail Azure Databricks, au lieu d’utiliser des rapports de validation et des builds de paquet wheel Python potentiellement obsolètes :
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Exécuter votre pipeline Jenkins
Vous êtes maintenant prêt à exécuter votre pipeline Jenkins manuellement. Pour ce faire, à partir de votre tableau de bord Jenkins :
- Cliquez sur le nom de votre pipeline Jenkins.
- Dans la barre latérale, cliquez sur Générer maintenant.
- Pour afficher les résultats, cliquez sur la dernière exécution du pipeline (par exemple,
#1), puis cliquez sur Sortie de la console.
À ce stade, le pipeline CI/CD a terminé un cycle d’intégration et de déploiement. En automatisant ce processus, vous pouvez vous assurer que votre code a été testé et déployé selon un processus efficace, cohérent et reproductible. Pour demander à votre fournisseur Git tiers d’exécuter Jenkins chaque fois qu’un événement spécifique se produit, tel qu’une requête de tirage de référentiel, consultez la documentation de votre fournisseur Git tiers.