Comment surveiller la qualité de votre agent sur le trafic de production
Important
Cette fonctionnalité est disponible en préversion publique.
Cet article explique comment surveiller la qualité des agents déployés sur le trafic de production à l’aide de l’évaluation de l’agent Mosaïque IA.
La surveillance en ligne est un aspect essentiel de la garantie que votre agent fonctionne comme prévu avec des demandes réelles. À l’aide du notebook fourni ci-dessous, vous pouvez exécuter l’évaluation de l’agent en continu sur les demandes traitées via un point de terminaison de service d’agent. Le notebook génère un tableau de bord qui affiche des métriques de qualité ainsi que des commentaires utilisateur (pouces vers le haut 👍 ou bas 👎) pour les sorties de votre agent sur les demandes de production. Ces commentaires peuvent arriver via l’application de révision des parties prenantes, ou l’API de commentaires sur les points de terminaison de production qui vous permet de capturer les réactions des utilisateurs finaux. Le tableau de bord vous permet de segmenter les métriques selon différentes dimensions, notamment par heure, les commentaires des utilisateurs, l’état de réussite/échec et la rubrique de la demande d’entrée (par exemple, pour comprendre si des rubriques spécifiques sont corrélées avec des sorties de qualité inférieure). En outre, vous pouvez approfondir les requêtes individuelles avec des réponses de faible qualité pour les déboguer davantage. Tous les artefacts, tels que le tableau de bord, sont entièrement personnalisables.
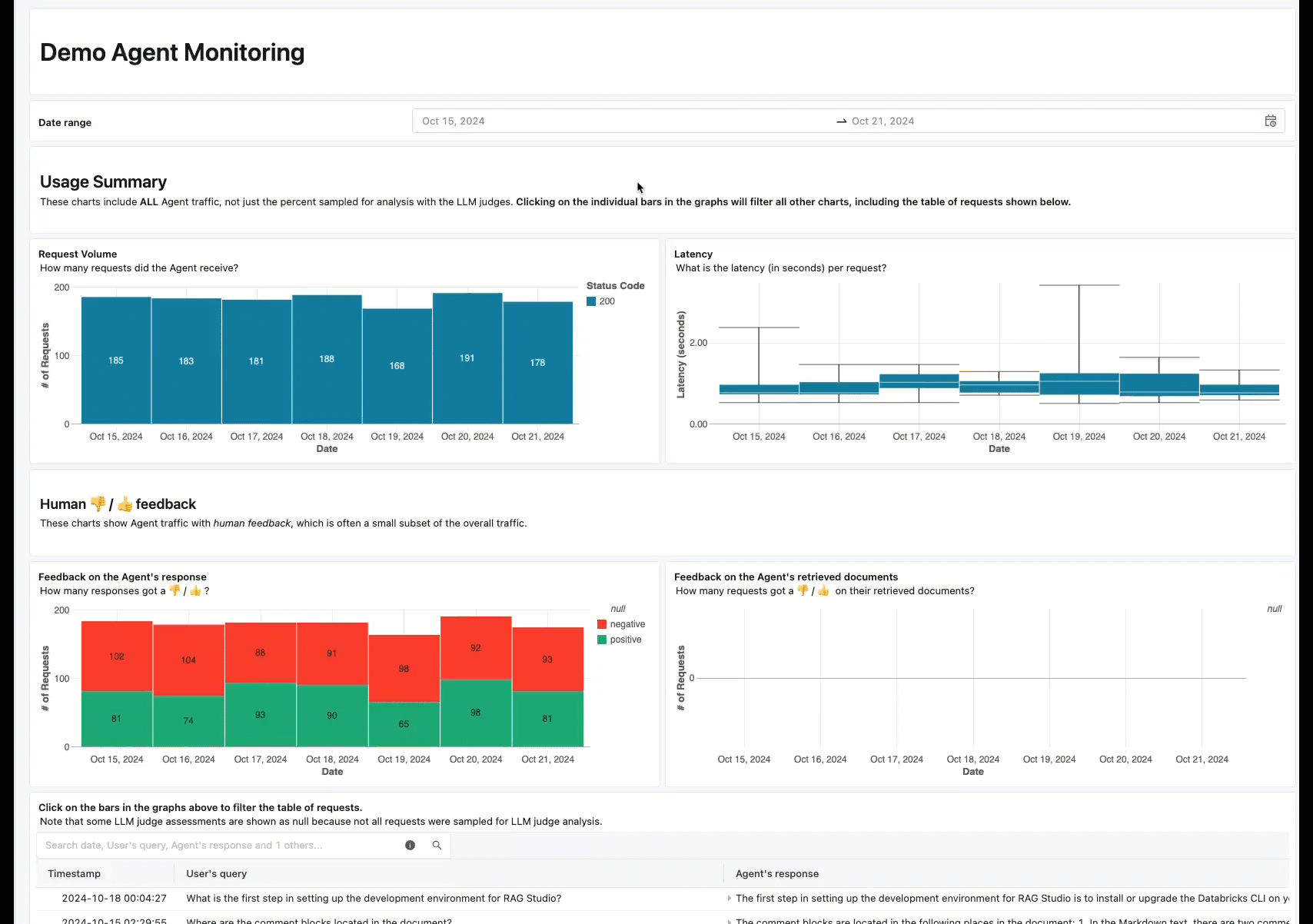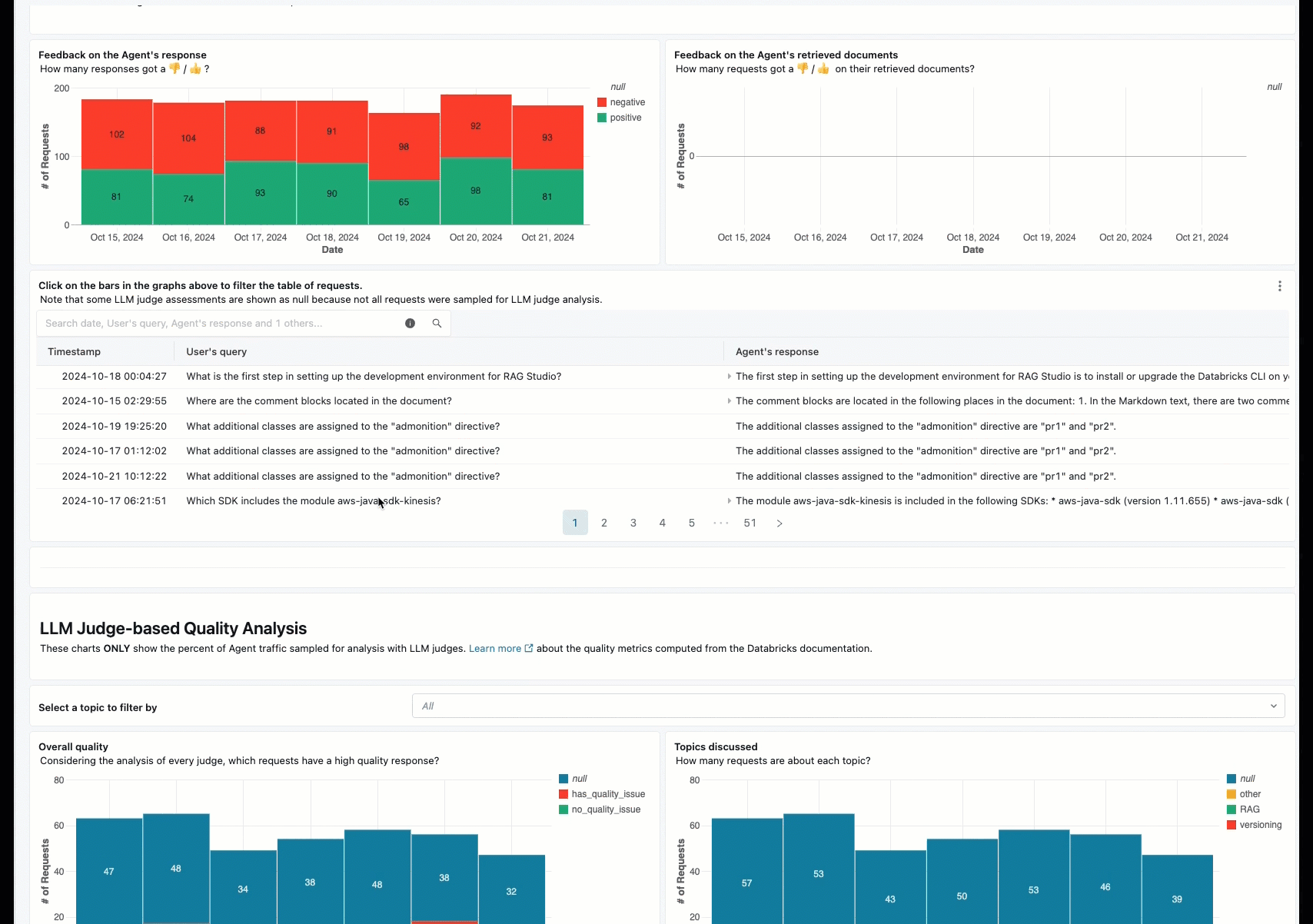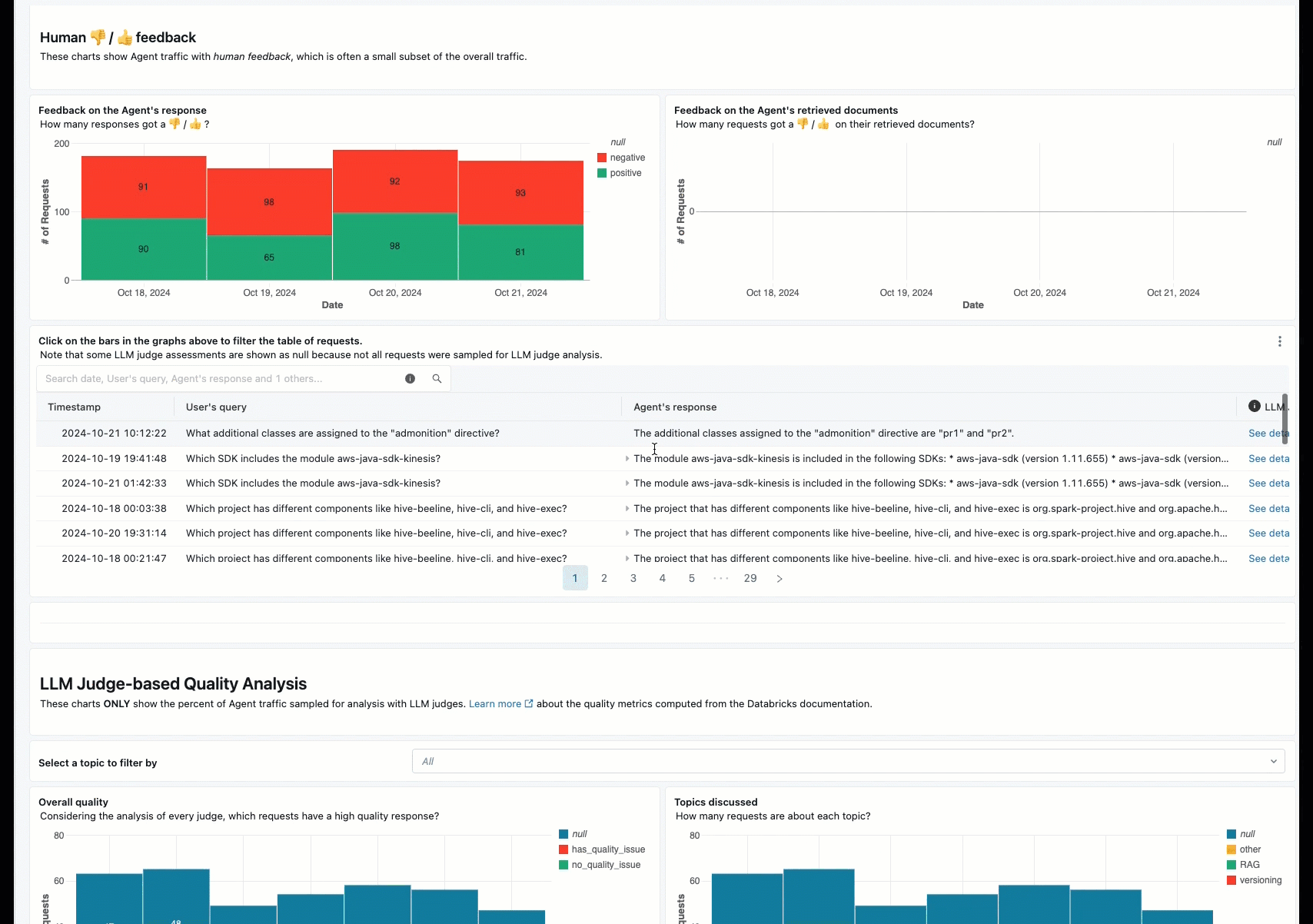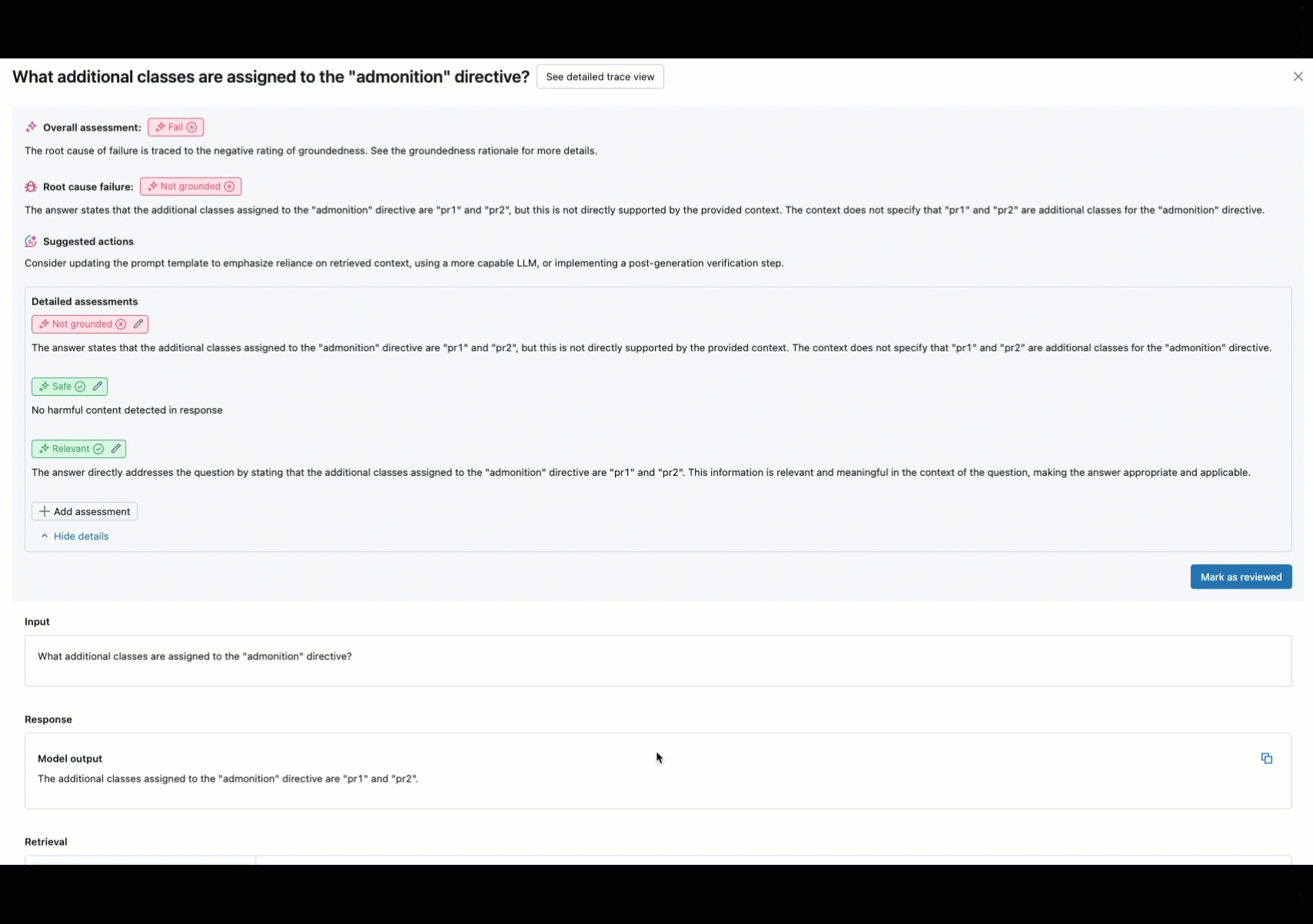
Spécifications
- Les fonctionnalités d’assistance IA optimisées par Azure doivent être activées pour votre espace de travail.
- Les tables d’inférence doivent être activées sur le point de terminaison de mise en service de l’agent.
Traiter en continu le trafic de production via l’évaluation de l’agent
L’exemple de notebook suivant montre comment exécuter l’évaluation de l’agent sur les journaux de demande à partir d’un point de terminaison de service d’agent. Pour exécuter le notebook, procédez comme suit :
- Importez le bloc-notes dans votre espace de travail (instructions). Vous pouvez cliquer sur le bouton « Copier le lien pour l’importation » ci-dessous pour obtenir une URL pour l’importation.
- Renseignez les paramètres requis en haut du bloc-notes importé.
- Nom du point de terminaison de service de votre agent déployé.
- Taux d’échantillonnage compris entre 0,0 et 1,0 pour échantillonner les requêtes. Utilisez un taux inférieur pour les points de terminaison avec de grandes quantités de trafic.
- (Facultatif) Dossier d’espace de travail pour stocker les artefacts générés (tels que les tableaux de bord). La valeur par défaut est le dossier d’accueil.
- (Facultatif) Liste de rubriques pour catégoriser les demandes d’entrée. La valeur par défaut est une liste composée d’une rubrique catch-all unique.
- Cliquez sur Exécuter tout dans le bloc-notes importé. Cela effectue un traitement initial de vos journaux de production dans une fenêtre de 30 jours et initialise le tableau de bord qui récapitule les métriques de qualité.
- Cliquez sur Planifier pour créer un travail pour exécuter régulièrement le bloc-notes. Le travail traite de façon incrémentielle vos journaux de production et conserve le tableau de bord à jour.
Le notebook nécessite un calcul serverless ou un cluster exécutant Databricks Runtime 15.2 ou version ultérieure. Lorsque vous surveillez en permanence le trafic de production sur les points de terminaison avec un grand nombre de requêtes, nous vous recommandons de définir une planification plus fréquente. Par exemple, une planification horaire fonctionne bien pour un point de terminaison avec plus de 10 000 requêtes par heure et un taux d’échantillonnage de 10 %.
Exécuter l’évaluation de l’agent sur le notebook du trafic de production
Créer des alertes sur les métriques d’évaluation
Après avoir planifié l’exécution périodique du bloc-notes, vous pouvez ajouter des alertes pour être averti lorsque les métriques de qualité diminuent plus bas que prévu. Ces alertes sont créées et utilisées de la même façon que d’autres alertes Databricks SQL. Tout d’abord, créez une requête SQL Databricks sur la table de journaux des demandes d’évaluation générée par l’exemple de notebook. Le code suivant montre un exemple de requête sur la table des demandes d’évaluation, en filtrant les demandes à partir de l’heure précédente :
SELECT
`date`,
AVG(pass_indicator) as avg_pass_rate
FROM (
SELECT
*,
CASE
WHEN `response/overall_assessment/rating` = 'yes' THEN 1
WHEN `response/overall_assessment/rating` = 'no' THEN 0
ELSE NULL
END AS pass_indicator
-- The eval requests log table is generated by the example notebook
FROM {eval_requests_log_table_name}
WHERE `date` >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
)
GROUP BY ALL
Ensuite, créez une alerte Databricks SQL pour évaluer la requête à une fréquence souhaitée et envoyez une notification si l’alerte est déclenchée. L’image suivante montre un exemple de configuration pour envoyer une alerte lorsque le taux global de passage tombe en dessous de 80 %.
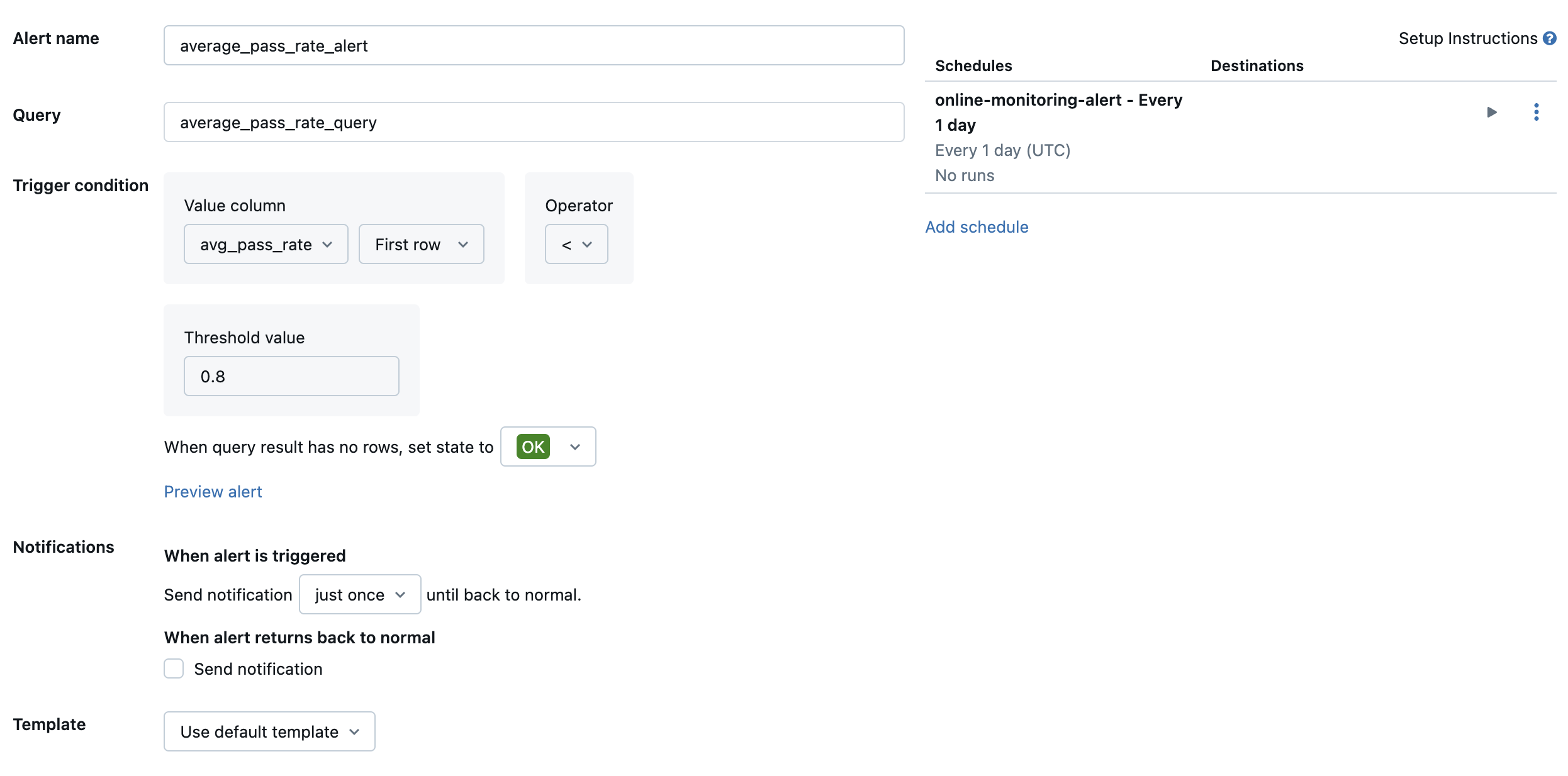
Par défaut, une notification par e-mail est envoyée. Vous pouvez également configurer un webhook ou envoyer des notifications à d’autres applications telles que Slack ou PagerDuty.
Ajouter les journaux de production sélectionnés à l’application de révision pour la révision humaine
Lorsque les utilisateurs fournissent des commentaires sur vos demandes, vous souhaiterez peut-être demander à des experts en matière d’objet de passer en revue les demandes avec des commentaires négatifs (demandes avec des pouces vers le bas sur la réponse ou les récupérations). Pour ce faire, vous ajoutez des journaux spécifiques à l’application de révision pour demander une révision d’expert.
Le code suivant montre un exemple de requête sur la table du journal d’évaluation pour récupérer l’évaluation humaine la plus récente par ID de demande et ID source :
with ranked_logs as (
select
`timestamp`,
request_id,
source.id as source_id,
text_assessment.ratings["answer_correct"]["value"] as text_rating,
retrieval_assessment.ratings["answer_correct"]["value"] as retrieval_rating,
retrieval_assessment.position as retrieval_position,
row_number() over (
partition by request_id, source.id, retrieval_assessment.position order by `timestamp` desc
) as rank
from {assessment_log_table_name}
)
select
request_id,
source_id,
text_rating,
retrieval_rating
from ranked_logs
where rank = 1
order by `timestamp` desc
Dans le code suivant, remplacez ... la ligne human_ratings_query = "..." par une requête similaire à celle ci-dessus. Le code suivant extrait ensuite les demandes avec des commentaires négatifs et les ajoute à l’application de révision :
from databricks import agents
human_ratings_query = "..."
human_ratings_df = spark.sql(human_ratings_query).toPandas()
# Filter out the positive ratings, leaving only negative and "IDK" ratings
negative_ratings_df = human_ratings_df[
(human_ratings_df["text_rating"] != "positive") | (human_ratings_df["retrieval_rating"] != "positive")
]
negative_ratings_request_ids = negative_ratings_df["request_id"].drop_duplicates().to_list()
agents.enable_trace_reviews(
model_name=YOUR_MODEL_NAME,
request_ids=negative_ratings_request_ids,
)
Pour plus d’informations sur l’application de révision, consultez Obtenir des commentaires sur la qualité d’une application agentique.