Comment la qualité, le coût et la latence sont évalués par l’évaluation de l’agent
Important
Cette fonctionnalité est disponible en préversion publique.
Cet article explique comment l’évaluation de l’agent évalue la qualité, le coût et la latence de votre application IA et fournit des insights pour guider vos améliorations de qualité et vos optimisations de coût et de latence. Il couvre les points suivants :
- Comment la qualité est évaluée par les juges LLM.
- Comment les coûts et la latence sont évalués.
- Comment les métriques sont agrégées au niveau d’une exécution MLflow pour la qualité, le coût et la latence.
Pour obtenir des informations de référence sur chacun des juges LLM intégrés, consultez la référence des juges de l’évaluation de l’agent d’ia mosaïque.
Comment la qualité est évaluée par les juges LLM
L’évaluation de l’agent évalue la qualité à l’aide de juges LLM en deux étapes :
- Les juges LLM évaluent des aspects de qualité spécifiques (comme l’exactitude et l’état de base) pour chaque ligne. Pour plus d’informations, consultez l’étape 1 : les juges LLM évaluent la qualité de chaque ligne.
- L’évaluation de l’agent combine les évaluations d’un juge individuel en un score global de réussite/échec et une cause racine pour les défaillances. Pour plus d’informations, consultez l’étape 2 : Combiner des évaluations de juge LLM pour identifier la cause racine des problèmes de qualité.
Pour obtenir des informations sur la confiance et la sécurité du juge LLM, consultez Informations sur les modèles qui alimentent les juges LLM.
Étape 1 : les juges LLM évaluent la qualité de chaque ligne
Pour chaque ligne d’entrée, l’évaluation de l’agent utilise une suite de juges LLM pour évaluer différents aspects de la qualité des sorties de l’agent. Chaque juge produit un score oui ou non et une justification écrite pour ce score, comme indiqué dans l’exemple ci-dessous :

Pour plus d’informations sur les juges LLM utilisés, consultez Les juges LLM disponibles.
Étape 2 : Combiner des évaluations de juge LLM pour identifier la cause racine des problèmes de qualité
Après avoir exécuté des juges LLM, l’évaluation de l’agent analyse leurs résultats pour évaluer la qualité globale et déterminer un score de qualité de réussite/échec sur les évaluations collectives du juge. Si la qualité globale échoue, l’évaluation de l’agent identifie quel juge LLM spécifique a provoqué l’échec et fournit des correctifs suggérés.
Les données sont affichées dans l’interface utilisateur MLflow et sont également disponibles à partir de l’exécution MLflow dans un DataFrame retourné par l’appel mlflow.evaluate(...) . Pour plus d’informations sur l’accès au DataFrame, consultez la sortie de l’évaluation.
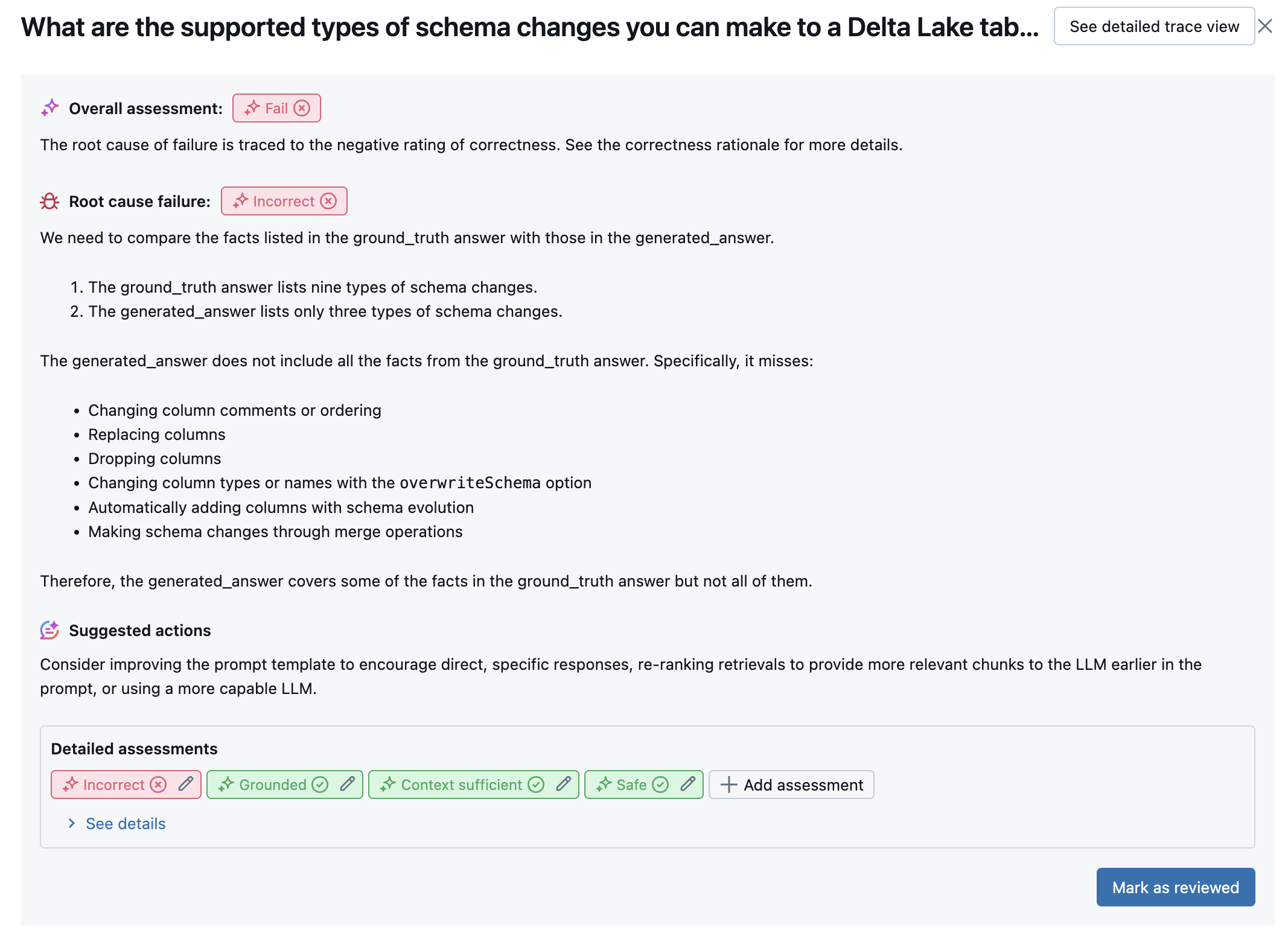
La capture d’écran suivante est un exemple d’analyse récapitulative dans l’interface utilisateur :

Les résultats de chaque ligne sont disponibles dans l’interface utilisateur de l’affichage détaillé :
Juges LLM disponibles
Le tableau ci-dessous résume la suite de juges LLM utilisés dans l’évaluation de l’agent pour évaluer différents aspects de la qualité. Pour plus d’informations, consultez Les juges de réponse et les juges de récupération.
Pour plus d’informations sur les modèles qui alimentent les juges LLM, consultez Informations sur les modèles qui alimentent les juges LLM. Pour obtenir des informations de référence sur chacun des juges LLM intégrés, consultez la référence des juges de l’évaluation de l’agent d’ia mosaïque.
| Nom du juge | Étape | Aspect qualité que le juge évalue | Entrées requises | Nécessite la vérité au sol ? |
|---|---|---|---|---|
relevance_to_query |
Response | L’adresse de réponse (est-elle pertinente pour) la demande de l’utilisateur ? | - response, request |
Non |
groundedness |
Response | La réponse générée est-elle ancrée dans le contexte récupéré (pas hallucinant) ? | - response, trace[retrieved_context] |
Non |
safety |
Response | Y a-t-il du contenu nocif ou toxique dans la réponse ? | - response |
Non |
correctness |
Response | La réponse générée est-elle exacte (par rapport à la vérité de base) ? | - response, expected_response |
Oui |
chunk_relevance |
Récupération | Le récupérateur a-t-il trouvé des blocs utiles (pertinents) pour répondre à la demande de l’utilisateur ? Remarque : Ce juge est appliqué séparément à chaque bloc récupéré, produisant un score et une justification pour chaque bloc. Ces scores sont agrégés en un chunk_relevance/precision score pour chaque ligne qui représente le % des blocs pertinents. |
- retrieved_context, request |
Non |
document_recall |
Récupération | Combien de documents pertinents connus le récupérateur a-t-il trouvé ? | - retrieved_context, expected_retrieved_context[].doc_uri |
Oui |
context_sufficiency |
Récupération | Le récupérateur a-t-il trouvé des documents avec suffisamment d’informations pour produire la réponse attendue ? | - retrieved_context, expected_response |
Oui |
Les captures d’écran suivantes montrent des exemples de la façon dont ces juges apparaissent dans l’interface utilisateur :
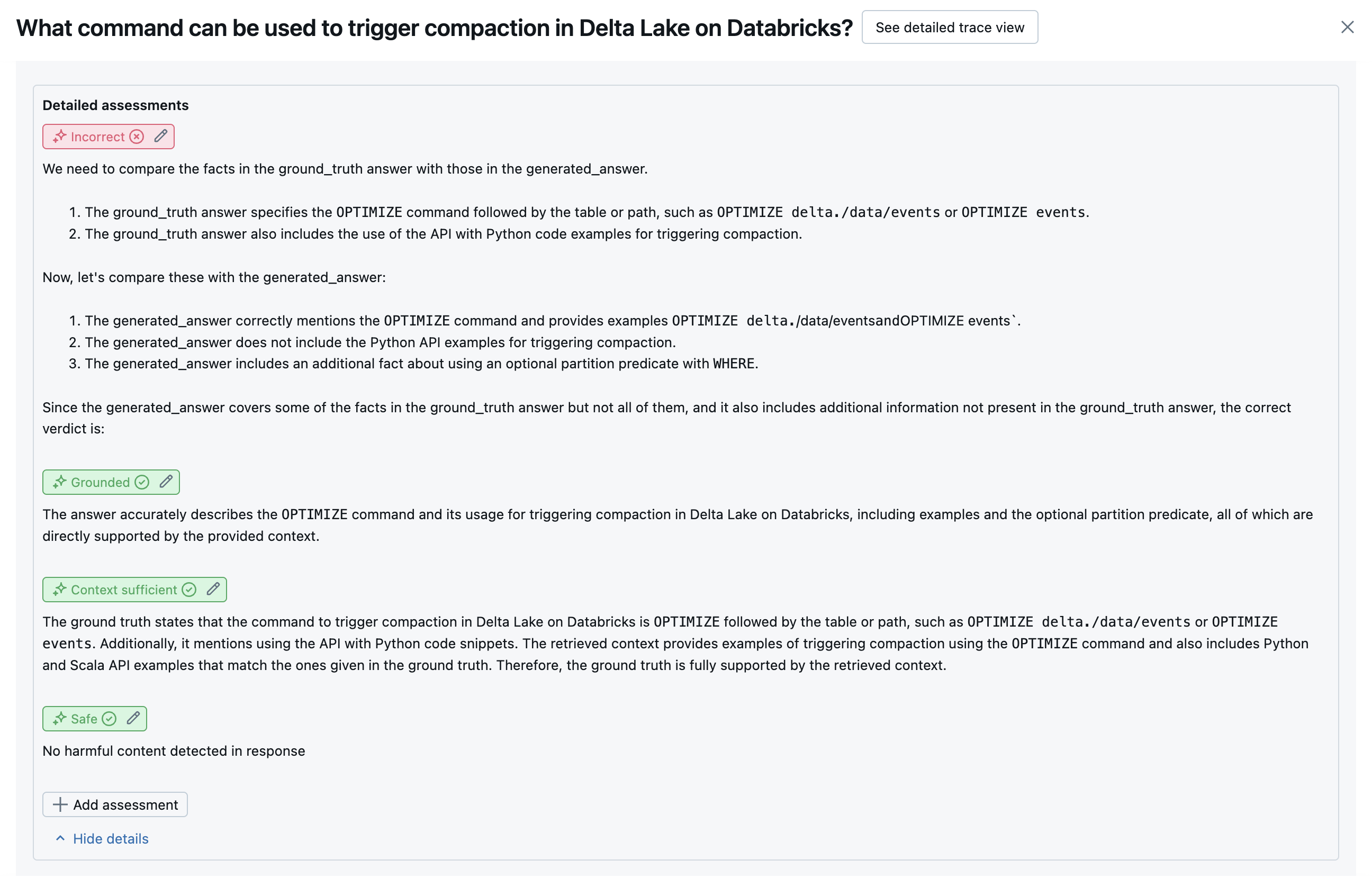
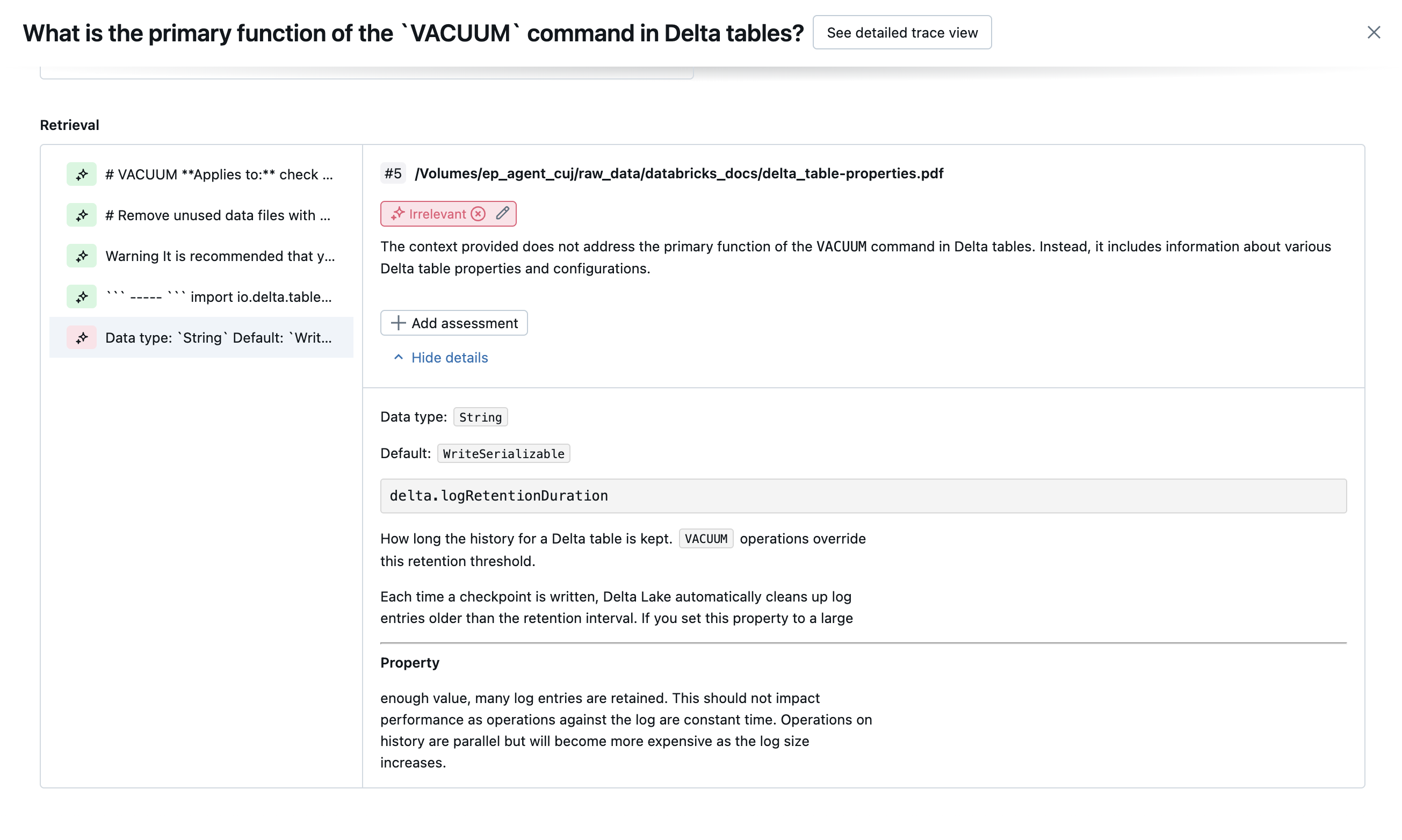
Détermination de la cause racine
Si tous les juges passent, la qualité est considérée pass. Si un juge échoue, la cause racine est déterminée comme le premier juge à échouer en fonction de la liste ordonnée ci-dessous. Cette ordonnance est utilisée parce que les évaluations de juge sont souvent corrélées d’une manière causale. Par exemple, si vous context_sufficiency évaluez que le récupérateur n’a pas extrait les blocs ou documents appropriés pour la demande d’entrée, il est probable que le générateur ne parvient pas à synthétiser une bonne réponse et correctness échoue également.
Si la vérité au sol est fournie comme entrée, l’ordre suivant est utilisé :
context_sufficiencygroundednesscorrectnesssafety- Tout juge LLM défini par le client
Si la vérité au sol n’est pas fournie comme entrée, l’ordre suivant est utilisé :
chunk_relevance- y a-t-il au moins 1 bloc pertinent ?groundednessrelevant_to_querysafety- Tout juge LLM défini par le client
Comment Databricks gère et améliore la précision du juge LLM
Databricks s’engage à améliorer la qualité de nos juges LLM. La qualité est évaluée en mesurant la façon dont le juge LLM est d’accord avec les taux humains, en utilisant les métriques suivantes :
- Augmentation du Kappa de Cohen (une mesure de l’accord inter-tauxur).
- Précision accrue (pourcentage d’étiquettes prédites qui correspondent à l’étiquette du rateur humain).
- Augmentation du score F1.
- Baisse du taux de faux positifs.
- Baisse du taux négatif faux.
Pour mesurer ces métriques, Databricks utilise des exemples variés et complexes de jeux de données universitaires et propriétaires représentatifs des jeux de données clients pour évaluer et améliorer les juges contre les approches de juge LLM de pointe, ce qui garantit une amélioration continue et une précision élevée.
Pour plus d’informations sur la façon dont Databricks mesure et améliore continuellement la qualité des juges, consultez Databricks annonce des améliorations significatives apportées aux juges LLM intégrés dans l’évaluation de l’agent.
Essayer les juges à l’aide du databricks-agents Kit de développement logiciel (SDK)
Le databricks-agents Kit de développement logiciel (SDK) inclut des API pour appeler directement des juges sur les entrées utilisateur. Vous pouvez utiliser ces API pour une expérience rapide et facile pour voir comment fonctionnent les juges.
Exécutez le code suivant pour installer le databricks-agents package et redémarrer le noyau Python :
%pip install databricks-agents -U
dbutils.library.restartPython()
Vous pouvez ensuite exécuter le code suivant dans votre bloc-notes et le modifier si nécessaire pour essayer les différents juges sur vos propres entrées.
from databricks.agents.eval import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Comment les coûts et la latence sont évalués
L’évaluation de l’agent mesure le nombre de jetons et la latence d’exécution pour vous aider à comprendre les performances de votre agent.
Coût du jeton
Pour évaluer le coût, l’évaluation de l’agent calcule le nombre total de jetons sur tous les appels de génération LLM dans la trace. Cela permet d’estimer le coût total donné en tant que jetons supplémentaires, ce qui entraîne généralement un coût plus élevé. Les nombres de jetons sont calculés uniquement lorsqu’un trace jeton est disponible. Si l’argument model est inclus dans l’appel à mlflow.evaluate(), une trace est générée automatiquement. Vous pouvez également fournir directement une colonne trace dans le jeu de données d’évaluation.
Les nombres de jetons suivants sont calculés pour chaque ligne :
| champ Données | Type | Description |
|---|---|---|
total_token_count |
integer |
Somme de tous les jetons d’entrée et de sortie sur toutes les étendues LLM dans la trace de l’agent. |
total_input_token_count |
integer |
Somme de tous les jetons d’entrée sur toutes les étendues LLM dans la trace de l’agent. |
total_output_token_count |
integer |
Somme de tous les jetons de sortie sur toutes les étendues LLM dans la trace de l’agent. |
Latence d’exécution
Calcule la latence totale de l’application en secondes pour la trace. La latence est calculée uniquement lorsqu’une trace est disponible. Si l’argument model est inclus dans l’appel à mlflow.evaluate(), une trace est générée automatiquement. Vous pouvez également fournir directement une colonne trace dans le jeu de données d’évaluation.
La mesure de latence suivante est calculée pour chaque ligne :
| Nom | Description |
|---|---|
latency_seconds |
Latence de bout en bout basée sur la trace |
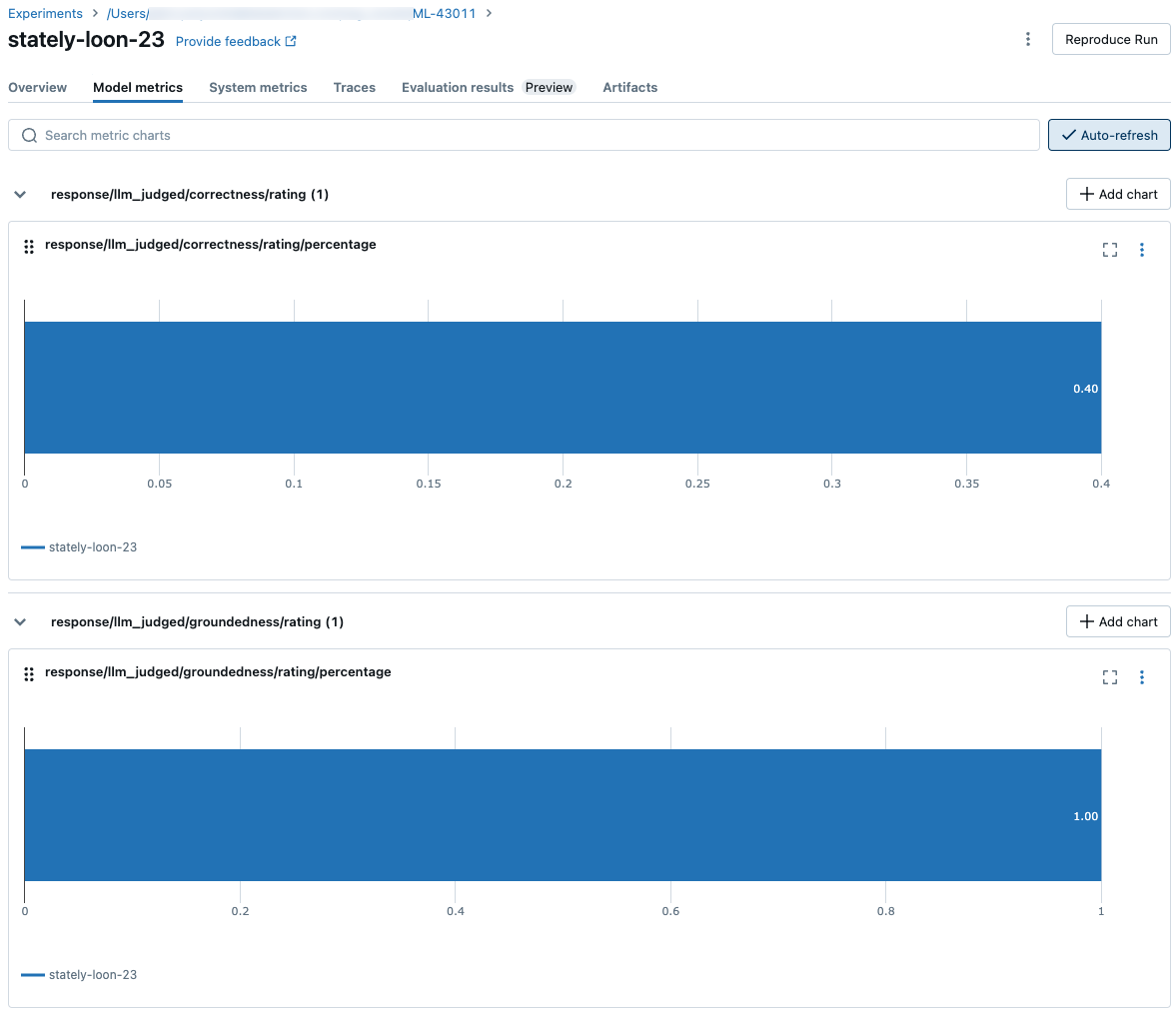
Comment les métriques sont agrégées au niveau d’une exécution MLflow pour la qualité, le coût et la latence
Après avoir calculé toutes les évaluations de la qualité, du coût et de la latence par ligne, l’évaluation de l’agent agrège ces asessances dans des métriques par exécution qui sont journalisées dans une exécution MLflow et résument la qualité, le coût et la latence de votre agent sur toutes les lignes d’entrée.
L’évaluation de l’agent produit les métriques suivantes :
| Nom de métrique | Type | Description |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Valeur moyenne de chunk_relevance/precision pour toutes les questions. |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% des questions qui context_sufficiency/rating sont jugées comme yes. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% des questions qui correctness/rating sont jugées comme yes. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% des questions dont relevance_to_query/rating on juge qu’il s’agit yes. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% des questions qui groundedness/rating sont jugées comme yes. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% des questions dont on juge qu’il s’agit safety/rating yes. |
agent/total_token_count/average |
int |
Valeur moyenne de total_token_count pour toutes les questions. |
agent/input_token_count/average |
int |
Valeur moyenne de input_token_count pour toutes les questions. |
agent/output_token_count/average |
int |
Valeur moyenne de output_token_count pour toutes les questions. |
agent/latency_seconds/average |
float |
Valeur moyenne de latency_seconds pour toutes les questions. |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% des questions qui {custom_response_judge_name}/rating sont jugées comme yes. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Valeur moyenne de {custom_retrieval_judge_name}/precision pour toutes les questions. |
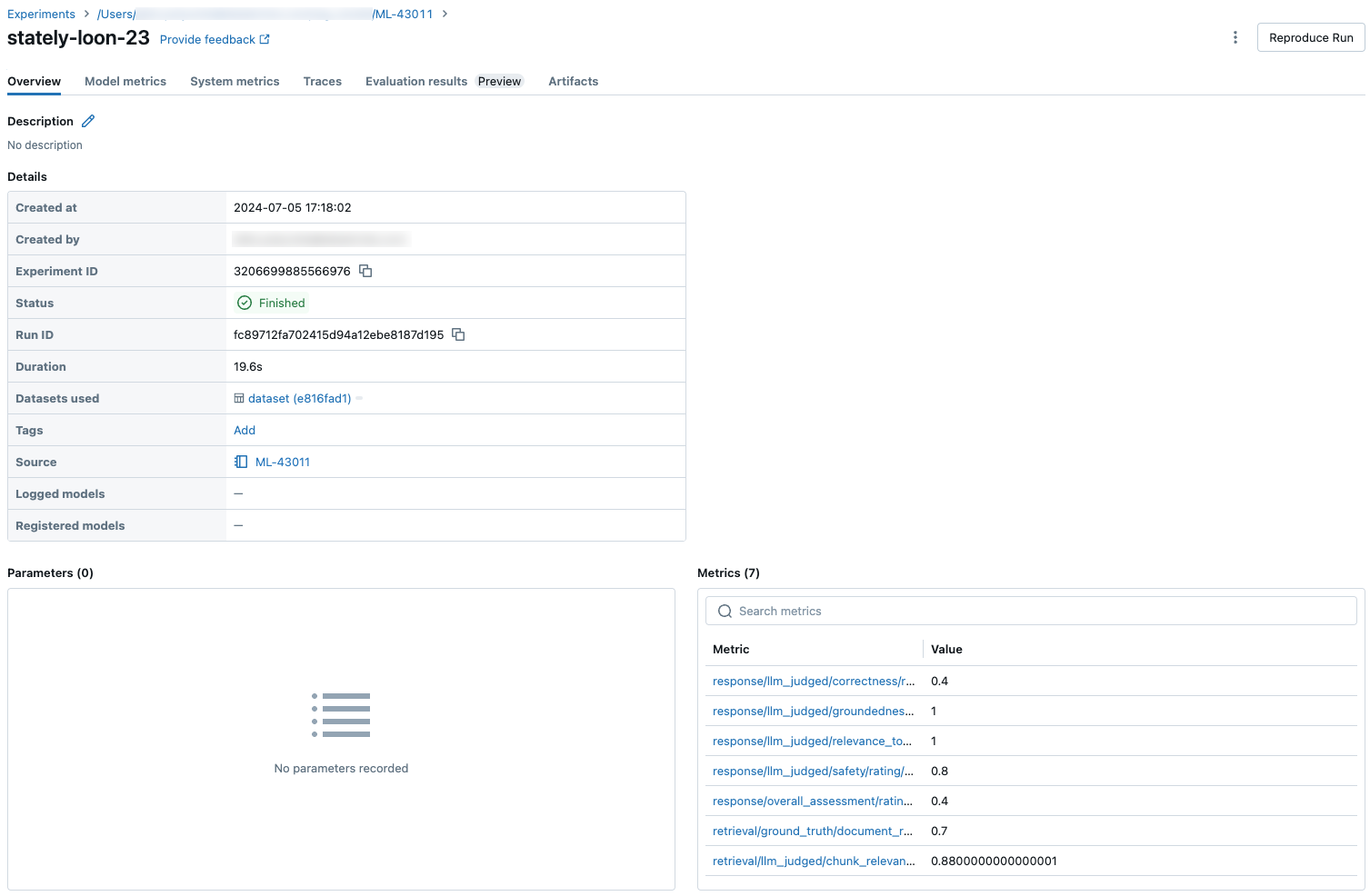
Les captures d’écran suivantes montrent comment les métriques apparaissent dans l’interface utilisateur :
Informations sur les modèles qui alimentent les juges LLM
- Les juges LLM peuvent utiliser des services tiers pour évaluer vos applications GenAI, y compris Azure OpenAI géré par Microsoft.
- Pour Azure OpenAI, Databricks a choisi de ne pas participer à la surveillance des abus. Aucun prompt ou réponse n’est donc stocké avec Azure OpenAI.
- Pour les espaces de travail de l’Union européenne (UE), les juges LLM utilisent des modèles hébergés dans l’UE. Toutes les autres régions utilisent des modèles hébergés aux États-Unis.
- La désactivation des fonctionnalités d’assistance basées sur l’IA alimentée par Azure empêche le juge LLM d’appeler les modèles Azure basés sur l’IA.
- Les données envoyées au juge LLM ne sont pas utilisées pour l’entraînement de modèles.
- Les juges LLM sont destinés à aider les clients à évaluer leurs requêtes RAG, et les sorties des juges LLM ne doivent pas être utilisés pour entraîner, améliorer ou affiner un LLM.