Guide pratique pour exécuter une évaluation et afficher les résultats
Important
Cette fonctionnalité est disponible en préversion publique.
Cet article explique comment exécuter une évaluation et afficher les résultats au fur et à mesure que vous développez votre application IA. Pour plus d’informations sur la surveillance de la qualité des agents déployés sur le trafic de production, consultez Comment surveiller la qualité de votre agent sur le trafic de production.
Pour utiliser l’évaluation de l’agent pendant le développement d’applications, vous devez spécifier un jeu d’évaluation. Un jeu d’évaluation est un ensemble de requêtes classiques qu’un utilisateur soumettrait à votre application. Le jeu d’évaluation peut également inclure la réponse attendue (vérité de base) pour chaque demande d’entrée. Si la réponse attendue est fournie, l’évaluation de l’agent peut calculer des métriques de qualité supplémentaires, telles que la correction et l’insuffisance de contexte. L’objectif du jeu d’évaluation est de vous aider à mesurer et à prédire le niveau de performance de votre application agentique en la testant sur des questions représentatives.
Pour plus d’informations sur les jeux d’évaluation, consultez Jeux d’évaluation. Pour le schéma requis, consultez Le schéma d’entrée d’évaluation de l’agent.
Pour commencer l’évaluation, vous utilisez la méthode mlflow.evaluate() de l’API MLflow. mlflow.evaluate() calcule les évaluations de qualité, ainsi que les métriques de latence et de coût pour chaque entrée dans le jeu d’évaluation, et agrège également ces résultats sur toutes les entrées. Ces résultats sont également appelés résultats d’évaluation. Le code suivant montre un exemple d’appel à mlflow.evaluate() :
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
import pandas as pd
eval_df = pd.DataFrame(...)
# Puts the evaluation results in the current Run, alongside the logged model parameters
with mlflow.start_run():
logged_model_info = mlflow.langchain.log_model(...)
mlflow.evaluate(data=eval_df, model=logged_model_info.model_uri,
model_type="databricks-agent")
Dans cet exemple, mlflow.evaluate() enregistre ses résultats d’évaluation dans l’exécution de MLflow englobante, ainsi que les informations journalisées par d’autres commandes (telles que les paramètres de modèle). Si vous appelez mlflow.evaluate() en dehors d’une exécution MLflow, elle démarre une nouvelle exécution et journalise les résultats d’évaluation dans cette exécution. Pour plus d’informations sur mlflow.evaluate(), notamment sur les résultats de l’évaluation journalisés dans l’exécution, consultez la documentation MLflow.
Spécifications
Les fonctionnalités d’assistance IA optimisées par Azure doivent être activées pour votre espace de travail.
Comment fournir une entrée à une exécution d’évaluation
Il existe deux façons de fournir une entrée à une exécution d’évaluation :
Fournir des sorties générées précédemment à comparer au jeu d’évaluation. Cette option est recommandée si vous souhaitez évaluer les sorties d’une application déjà déployée en production, ou si vous voulez comparer les résultats d’évaluation de plusieurs configurations d’évaluation.
Avec cette option, vous spécifiez un jeu d’évaluation comme indiqué dans le code suivant. Le jeu d’évaluation doit inclure des sorties générées précédemment. Pour obtenir des exemples plus détaillés, consultez Exemple : Passer des sorties générées précédemment à l’évaluation de l’agent.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Transmettre l’application en tant qu’argument d’entrée.
mlflow.evaluate()appelle l’application pour chaque entrée dans le jeu d’évaluation et signale des évaluations de qualité et d’autres métriques pour chaque sortie générée. Cette option est recommandée si votre application a été journalisée à l’aide de MLflow avec le Suivi MLflow activé, ou si votre application est implémentée en tant que fonction Python dans un notebook. Cette option n’est pas recommandée si votre application a été développée en dehors de Databricks ou si elle est déployée en dehors de Databricks.Avec cette option, vous spécifiez le jeu d’évaluation et l’application dans l’appel de fonction, comme indiqué dans le code suivant. Pour obtenir des exemples plus détaillés, consultez Exemple : Comment passer une application à l’évaluation de l’agent.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Pour plus d’informations sur le schéma du jeu d’évaluation, consultez le schéma d’entrée d’évaluation de l’agent.
Sorties d’évaluation
L’évaluation de l’agent retourne ses sorties en mlflow.evaluate() tant que trames de données et enregistre également ces sorties dans l’exécution de MLflow. Vous pouvez inspecter les sorties dans le notebook ou à partir de la page de l’exécution MLflow correspondante.
Passer en revue la sortie dans le bloc-notes
Le code suivant montre quelques exemples illustrant comment passer en revue les résultats d’une exécution d’évaluation à partir de votre notebook.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Le per_question_results_df dataframe inclut toutes les colonnes du schéma d’entrée et tous les résultats d’évaluation spécifiques à chaque requête. Pour plus d’informations sur les résultats calculés, consultez Comment la qualité, le coût et la latence sont évalués par l’évaluation de l’agent.
Passer en revue la sortie à l’aide de l’interface utilisateur MLflow
Les résultats de l’évaluation sont également disponibles dans l’interface utilisateur MLflow. Pour accéder à l’interface utilisateur MLflow, cliquez sur l’icône Experiment (Expérience) ![]() dans la barre latérale droite du notebook, puis sur l’exécution correspondante, ou cliquez sur les liens qui s’affichent dans les résultats de la cellule de notebook dans laquelle vous avez exécuté
dans la barre latérale droite du notebook, puis sur l’exécution correspondante, ou cliquez sur les liens qui s’affichent dans les résultats de la cellule de notebook dans laquelle vous avez exécuté mlflow.evaluate().
Passer en revue les résultats de l’évaluation pour une seule exécution
Cette section explique comment passer en revue les résultats d’évaluation d’une exécution individuelle. Pour comparer les résultats entre les exécutions, consultez Comparer les résultats d’évaluation entre les exécutions.
Vue d’ensemble des évaluations de qualité par les juges LLM
Les évaluations de juge par demande sont disponibles dans databricks-agents la version 0.3.0 et ultérieure.
Pour afficher une vue d’ensemble de la qualité évaluée par LLM de chaque requête dans le jeu d’évaluation, cliquez sur l’onglet Résultats de l’évaluation dans la page Exécution de MLflow. Cette page affiche un tableau récapitulatif de chaque exécution d’évaluation. Pour plus d’informations, cliquez sur l’ID d’évaluation d’une exécution.
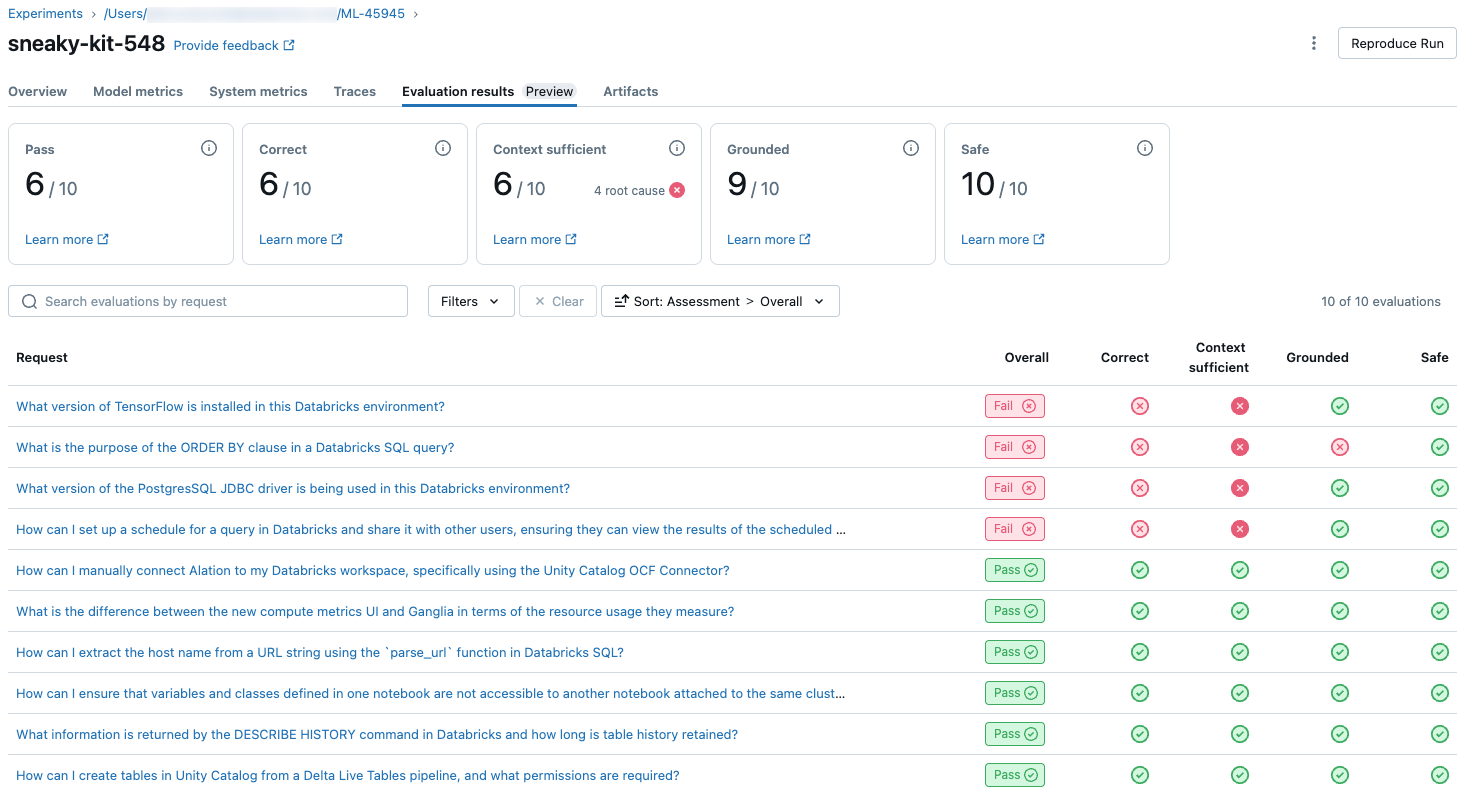
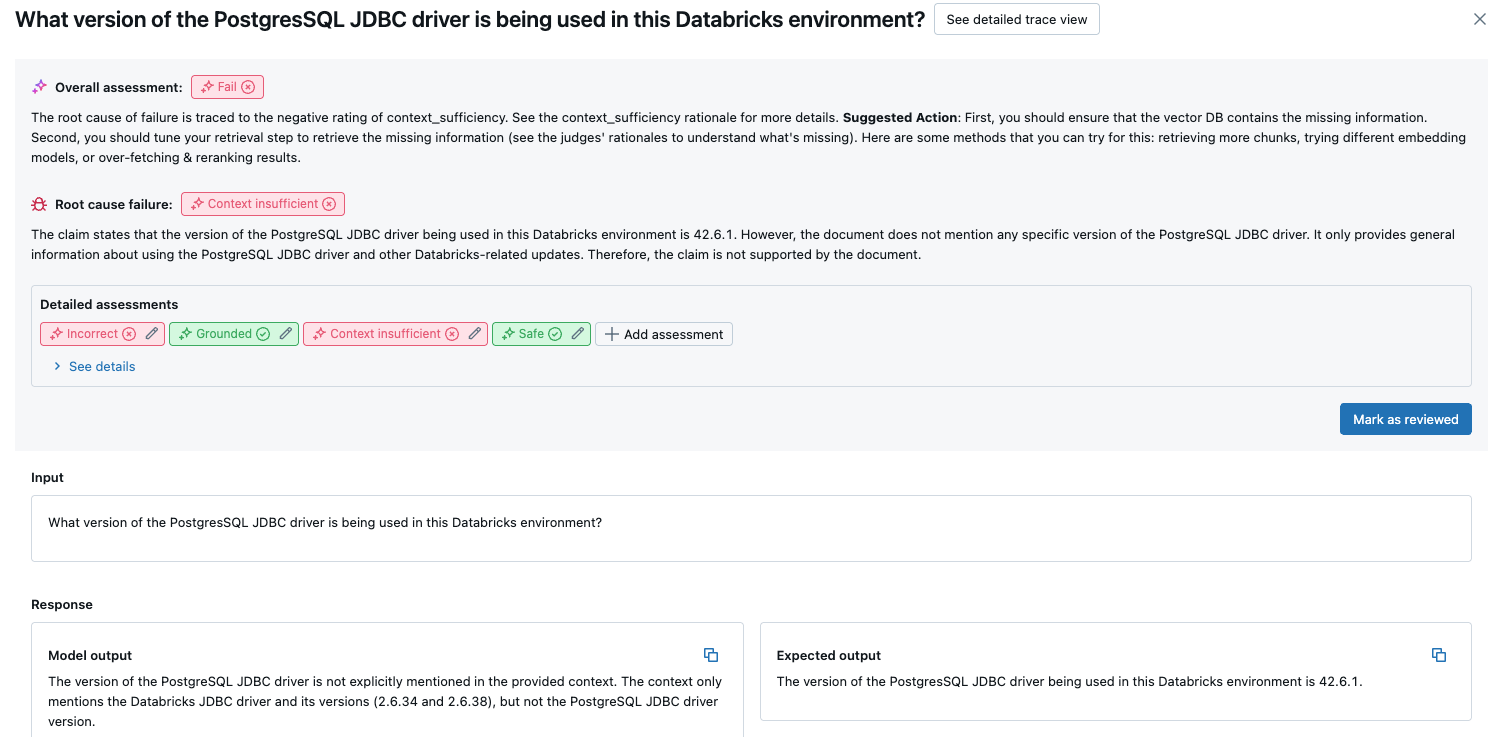
Cette vue d’ensemble montre les évaluations de différents juges pour chaque demande, l’état de réussite/échec de chaque demande en fonction de ces évaluations et la cause racine des demandes ayant échoué. Si vous cliquez sur une ligne du tableau, vous accédez à la page de détails de cette demande qui inclut les éléments suivants :
- Sortie du modèle : réponse générée à partir de l’application agentique et de sa trace, si elle est incluse.
- Sortie attendue : réponse attendue pour chaque requête.
- Évaluations détaillées : évaluations des juges LLM sur ces données. Cliquez sur Voir les détails pour afficher les justifications fournies par les juges.
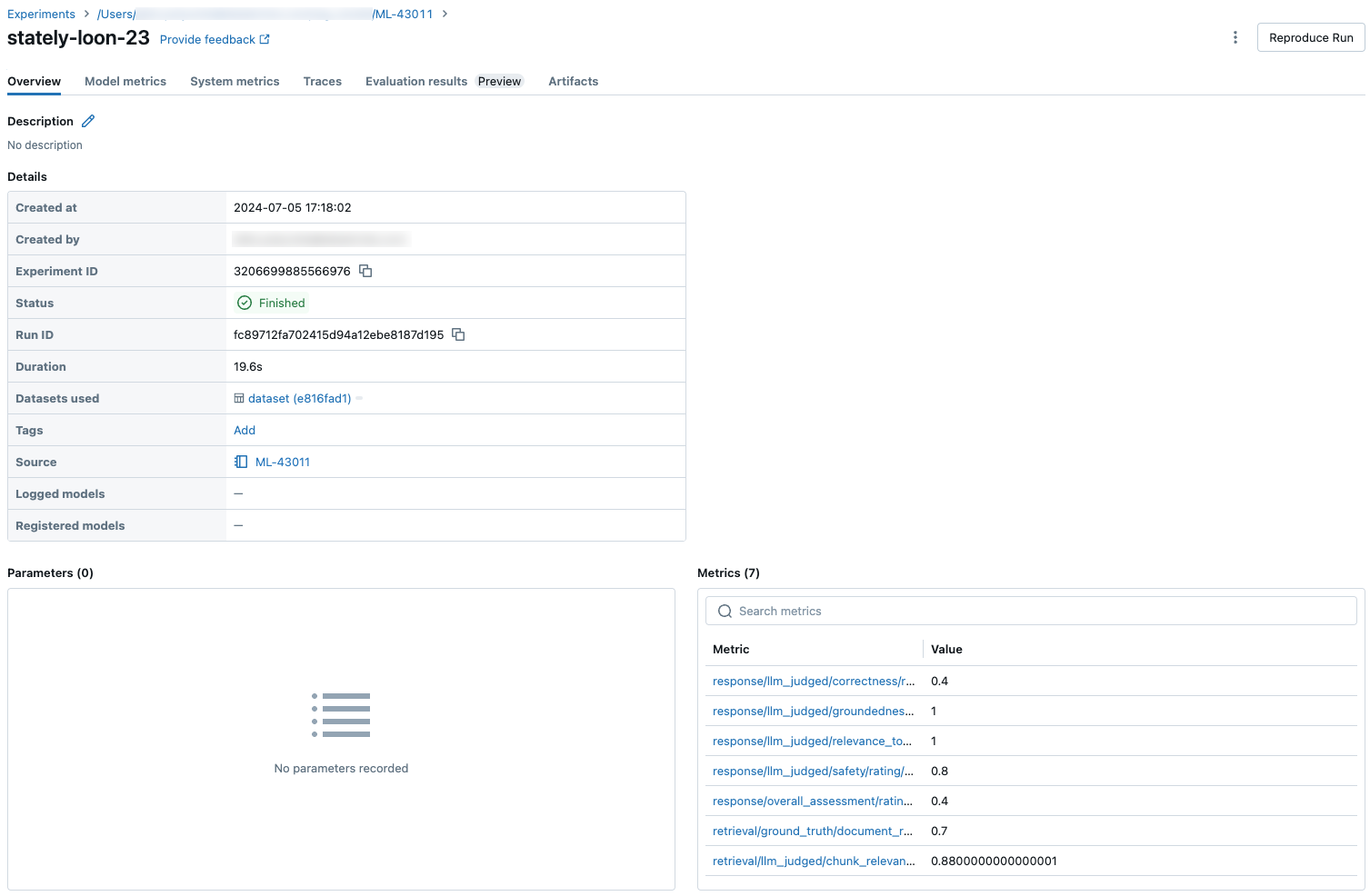
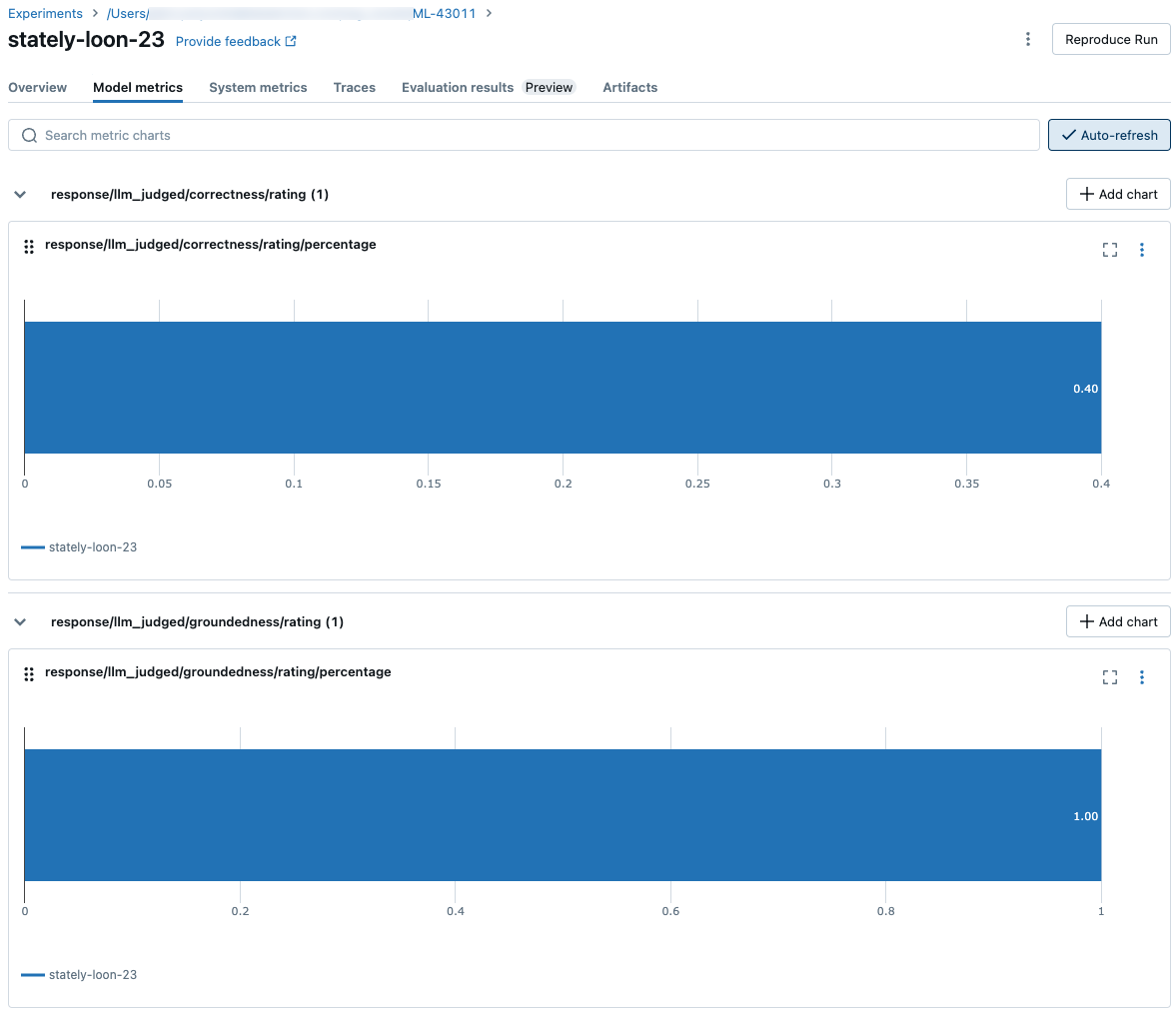
Résultats agrégés dans le jeu d’évaluation complet
Pour afficher les résultats agrégés dans le jeu d’évaluation complet, cliquez sur l’onglet Vue d’ensemble (pour les valeurs numériques) ou sur l’onglet Métriques du modèle (pour les graphiques ).
Comparer les résultats d’évaluation entre les exécutions
Il est important de comparer les résultats d’évaluation entre les exécutions pour voir comment votre application agentique répond aux modifications. La comparaison des résultats peut vous aider à comprendre si vos modifications ont un impact positif sur la qualité ou vous aident à résoudre les problèmes de changement de comportement.
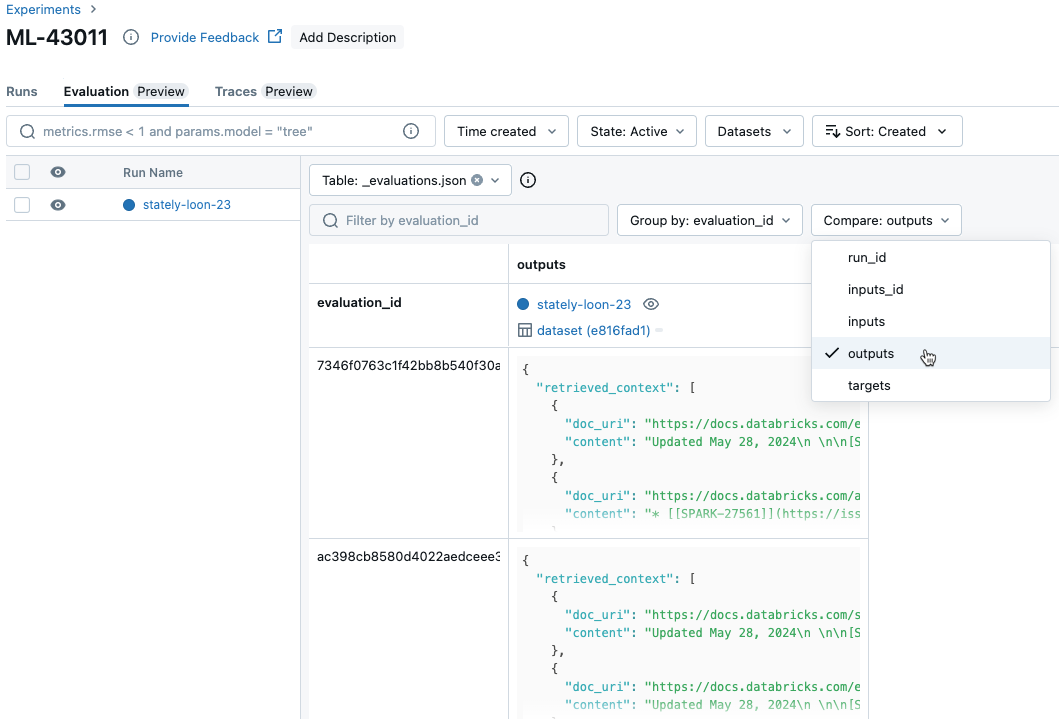
Comparer les résultats par requête entre les exécutions
Pour comparer les données de chaque requête individuelle entre les exécutions, cliquez sur l’onglet Evaluation (Évaluation) dans la page Experiment (Expérience). Un tableau montre chaque question dans le jeu d’évaluation. Utilisez les menus déroulants pour sélectionner les colonnes à afficher.
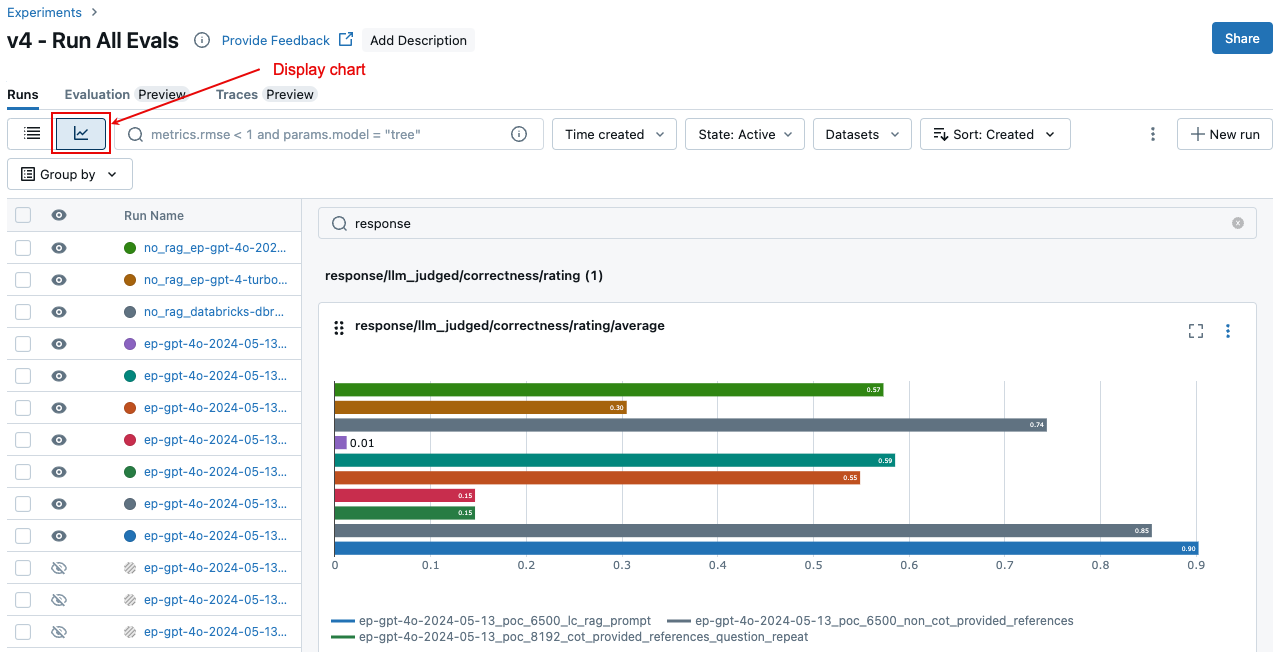
Comparer les résultats agrégés entre les exécutions
Vous pouvez accéder aux mêmes résultats agrégés à partir de la page Expérience, ce qui vous permet également de comparer les résultats entre différentes exécutions. Pour accéder à la page Experiment (Expérience), cliquez sur l’icône Experiment (Expérience) ![]() dans la barre latérale droite du notebook, ou cliquez sur les liens qui s’affichent dans les résultats de la cellule de notebook dans laquelle vous avez exécuté
dans la barre latérale droite du notebook, ou cliquez sur les liens qui s’affichent dans les résultats de la cellule de notebook dans laquelle vous avez exécuté mlflow.evaluate().
Sur la page Experiment (Expérience), cliquez sur ![]() . Cela vous permet de visualiser les résultats agrégés de l’exécution sélectionnée et de comparer les exécutions passées.
. Cela vous permet de visualiser les résultats agrégés de l’exécution sélectionnée et de comparer les exécutions passées.
Quels juges sont exécutés
Par défaut, pour chaque enregistrement d’évaluation, Mosaic AI Agent Evaluation applique le sous-ensemble de juges qui correspondent le mieux aux informations présentes dans l’enregistrement. Plus précisément :
- Si le dossier comprend une réponse fondée sur la vérité, l’évaluation de l’agent applique les juges, ainsi
safetyque lescorrectnesscontext_sufficiencygroundednessjuges. - Si le dossier n’inclut pas de réponse fondée sur la vérité, l’évaluation de l’agent applique les juges et
safetyleschunk_relevancegroundednessrelevance_to_queryjuges.
Vous pouvez également spécifier explicitement les juges à appliquer à chaque demande à l’aide de l’argument evaluator_config de mlflow.evaluate() ce qui suit :
# Complete list of built-in LLM judges
# "chunk_relevance", "context_sufficiency", "correctness", "groundedness", "relevance_to_query", "safety"
evaluation_results = mlflow.evaluate(
data=eval_df,
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
# Run only LLM judges that don't require ground-truth. Use an empty list to not run any built-in judge.
"metrics": ["groundedness", "relevance_to_query", "chunk_relevance", "safety"]
}
}
)
Remarque
Vous ne pouvez pas désactiver les métriques des juges non-LLM pour la récupération de blocs, les nombres de jetons de chaîne ou la latence.
En plus des juges intégrés, vous pouvez définir un juge LLM personnalisé pour évaluer des critères spécifiques à votre cas d’usage. Voir Personnaliser les juges LLM.
Veuillez consulter Informations sur les modèles qui alimentent les juges LLM pour des information sur la confiance et la sécurité des juges LLM.
Pour plus d’informations sur les résultats et les métriques d’évaluation, consultez Comment la qualité, le coût et la latence sont évalués par l’évaluation de l’agent.
Exemple : Comment passer une application à l’évaluation de l’agent
Pour passer une application à mlflow_evaluate(), utilisez l’argument model . Il existe 5 options pour transmettre une application dans l’argument model .
- Modèle inscrit dans le catalogue Unity.
- Modèle journalisé MLflow dans l’expérience MLflow actuelle.
- Modèle PyFunc chargé dans le notebook.
- Fonction locale dans le notebook.
- Point de terminaison d’agent déployé.
Consultez les sections suivantes pour obtenir des exemples de code illustrant chaque option.
Option 1. Modèle inscrit dans le catalogue Unity
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Option 2. Modèle journalisé MLflow dans l’expérience MLflow actuelle
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Option 3. Modèle PyFunc chargé dans le notebook
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Option 4. Fonction locale dans le notebook
La fonction reçoit une entrée mise en forme comme suit :
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
La fonction doit retourner une valeur dans l’un des trois formats pris en charge suivants :
Chaîne simple contenant la réponse du modèle.
Dictionnaire au
ChatCompletionResponseformat. Par exemple :{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }Dictionnaire au
StringResponseformat, tel que{ "content": "MLflow is a machine learning toolkit.", ... }.
L’exemple suivant utilise une fonction locale pour encapsuler un point de terminaison de modèle de base et l’évaluer :
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Option 5. Point de terminaison de l’agent déployé
Cette option fonctionne uniquement lorsque vous utilisez des points de terminaison d’agent qui ont été déployés à l’aide databricks.agents.deployde . Pour les modèles de base, utilisez l’option 4 pour encapsuler le modèle dans une fonction locale.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
Comment passer le jeu d’évaluation lorsque l’application est incluse dans l’appel mlflow_evaluate()
Dans le code suivant, data il s’agit d’un DataFrame pandas avec votre jeu d’évaluation. Il s’agit d’exemples simples. Pour plus d’informations, consultez le schéma d’entrée.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Exemple : Comment passer des sorties générées précédemment à l’évaluation de l’agent
Cette section explique comment passer des sorties générées précédemment dans l’appel mlflow_evaluate() . Pour le schéma du jeu d’évaluation requis, consultez le schéma d’entrée d’évaluation de l’agent.
Dans le code suivant, data il s’agit d’un DataFrame pandas avec votre jeu d’évaluation et les sorties générés par l’application. Il s’agit d’exemples simples. Pour plus d’informations, consultez le schéma d’entrée.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Exemple : Utiliser une fonction personnalisée pour traiter les réponses de LangGraph
Les agents LangGraph, en particulier ceux dotés de fonctionnalités de conversation, peuvent retourner plusieurs messages pour un appel d’inférence unique. Il incombe à l’utilisateur de convertir la réponse de l’agent dans un format pris en charge par l’évaluation de l’agent.
Une approche consiste à utiliser une fonction personnalisée pour traiter la réponse. L’exemple suivant montre une fonction personnalisée qui extrait le dernier message de conversation à partir d’un modèle LangGraph. Cette fonction est ensuite utilisée pour mlflow.evaluate() retourner une seule réponse de chaîne, qui peut être comparée à la ground_truth colonne.
L’exemple de code effectue les hypothèses suivantes :
- Le modèle accepte l’entrée au format {"messages » : [{"role » : « user », « content » : « hello"}]}.
- Le modèle retourne une liste de chaînes au format ["response 1 », « response 2"].
Le code suivant envoie les réponses concaténées au juge dans ce format : « response 1nresponse2 »
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Créer un tableau de bord avec des métriques
Lorsque vous effectuez une itération sur la qualité de votre agent, vous pouvez partager un tableau de bord avec vos parties prenantes qui montre comment la qualité s’est améliorée au fil du temps. Vous pouvez extraire les métriques de vos exécutions d’évaluation MLflow, enregistrer les valeurs dans une table Delta et créer un tableau de bord.
L’exemple suivant montre comment extraire et enregistrer les valeurs de métriques à partir de l’exécution d’évaluation la plus récente dans votre notebook :
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
L’exemple suivant montre comment extraire et enregistrer des valeurs de métrique pour les exécutions passées que vous avez enregistrées dans votre expérience MLflow.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Vous pouvez maintenant créer un tableau de bord à l’aide de ces données.
Le code suivant définit la fonction append_metrics_to_table utilisée dans les exemples précédents.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Limitation
Pour les conversations à plusieurs tours, la sortie d’évaluation enregistre uniquement la dernière entrée dans la conversation.
Informations sur les modèles qui alimentent les juges LLM
- Les juges LLM peuvent utiliser des services tiers pour évaluer vos applications GenAI, y compris Azure OpenAI géré par Microsoft.
- Pour Azure OpenAI, Databricks a choisi de ne pas participer à la surveillance des abus. Aucun prompt ou réponse n’est donc stocké avec Azure OpenAI.
- Pour les espaces de travail de l’Union européenne (UE), les juges LLM utilisent des modèles hébergés dans l’UE. Toutes les autres régions utilisent des modèles hébergés aux États-Unis.
- La désactivation des fonctionnalités d’assistance basées sur l’IA alimentée par Azure empêche le juge LLM d’appeler les modèles Azure basés sur l’IA.
- Les données envoyées au juge LLM ne sont pas utilisées pour l’entraînement de modèles.
- Les juges LLM sont destinés à aider les clients à évaluer leurs requêtes RAG, et les sorties des juges LLM ne doivent pas être utilisés pour entraîner, améliorer ou affiner un LLM.