Comment créer et interroger un index de recherche vectorielle
Cet article décrit comment créer et interroger un index de recherche vectorielle en utilisant Mosaic AI Vector Search.
Vous pouvez créer et gérer des composants de recherche vectorielle, tels qu’un point de terminaison de recherche vectorielle et des index de recherche vectorielle, en utilisant l’interface utilisateur, le Kit de développement logiciel (SDK) Python ou l’API REST.
Spécifications
- Espace de travail avec Unity Catalog
- Calcul serverless activé Pour obtenir des instructions, consultez Se connecter au calcul serverless.
- Le flux des changements de données être activé dans la table source. Pour obtenir des instructions, consultez Utiliser le flux des changements de données Delta Lake sur Azure Databricks.
- Pour créer un index, vous devez disposer de privilèges CREATE TABLE sur les schémas de catalogue pour créer des index. Pour interroger un index appartenant à un autre utilisateur, vous devez disposer de privilèges supplémentaires. Voir Interroger un point de terminaison de recherche vectorielle.
- Si vous souhaitez utiliser des jetons d’accès personnel (action déconseillée pour des charges de travail en production), vérifiez que les Jetons d’accès personnel sont activés. Pour utiliser un jeton de principal de service à la place, passez-le explicitement en utilisant un Kit de développement logiciel (SDK) ou des appel d’API.
Pour utiliser le Kit de développement logiciel (SDK), vous devez l’installer dans votre notebook. Utilisez le code suivant :
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
Créer un point de terminaison de recherche vectorielle
Vous pouvez créer un point de terminaison de recherche vectorielle à l’aide de l’interface utilisateur Databricks, du Kit de développement logiciel (SDK) Python ou de l’API.
Créer un point de terminaison de recherche vectorielle à l’aide de l’interface utilisateur
Suivez ces étapes pour créer un point de terminaison de recherche vectorielle à l’aide de l’interface utilisateur.
Dans la barre latérale gauche, cliquez sur Calcul.
Cliquez sur l’onglet Vector Search, puis sur Create.

La page Create endpoint form s’ouvre. Entrez un nom pour ce point de terminaison.
Cliquez sur Confirmer.
Créer un point de terminaison de recherche vectorielle à l’aide du Kit de développement logiciel (SDK) Python
L’exemple suivant utilise la fonction SDK create_endpoint() pour créer un point de terminaison de recherche vectorielle.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Créer un point de terminaison de recherche vectorielle à l’aide de l’API REST
Consultez la documentation de référence de l’API REST : POST /api/2.0/vector-search/endpoints.
(Facultatif) Créer et configurer un point de terminaison pour servir le modèle d’incorporation
Si vous choisissez Databricks pour calculer les incorporations, vous pouvez utiliser un point de terminaison d’API Foundation Model préconfiguré ou créer un point de terminaison de service de modèles pour servir le modèle d’incorporation de votre choix. Pour obtenir des instructions, consultez API Foundation Model de paiement par jeton ou Créer des points de terminaison de service de modèles d’IA générative. Pour obtenir des exemples de notebooks, consultez Exemples de notebooks pour appeler un modèle d’incorporation.
Lorsque vous configurez un point de terminaison d’incorporation, Databricks vous recommande de supprimer la sélection par défaut de Mettre à l'échelle à zéro. Le démarrage des points de terminaison peut prendre quelques minutes et la requête initiale sur un index avec un point de terminaison avec scale-down peut expirer.
Remarque
L’initialisation de l’index de recherche vectorielle peut expirer si le point d’incorporation n’est pas configuré de manière appropriée pour le jeu de données. Vous devez uniquement utiliser des points de terminaison d’UC pour les petits jeux de données et les tests. Pour les jeux de données plus volumineux, utilisez un point de terminaison GPU pour optimiser le niveau de performance.
Créer un index de recherche vectorielle
Vous pouvez créer un index de recherche vectorielle à l’aide de l’interface utilisateur, du Kit de développement logiciel (SDK) Python ou de l’API REST. L’interface utilisateur est l’approche la plus simple.
Il existe deux types d’index :
- L’index à synchronisation Delta se synchronise automatiquement avec une table Delta source, et est automatiquement mis à jour de manière incrémentielle à mesure que les données sous-jacentes dans la table Delta changent.
- L’index d’accès direct aux vecteurs prend en charge la lecture et l’écriture directes de vecteurs et de métadonnées. L’utilisateur est responsable de la mise à jour de cette table à l’aide de l’API REST ou du Kit de développement logiciel (SDK) Python. Ce type d’index ne peut pas être créé à l’aide de l’interface utilisateur. Vous devez utiliser l’API REST ou le Kit de développement logiciel (SDK).
Créer un index à l’aide de l’interface utilisateur
Dans la barre latérale gauche, cliquez sur Catalogue pour ouvrir l’interface utilisateur de l’explorateur de catalogues.
Accédez à la table Delta que vous souhaitez utiliser.
Cliquez sur le bouton Créer en haut à droite, puis sélectionnez Index de recherche vectorielle dans le menu déroulant.
Utilisez les sélecteurs dans la boîte de dialogue pour configurer l’index.
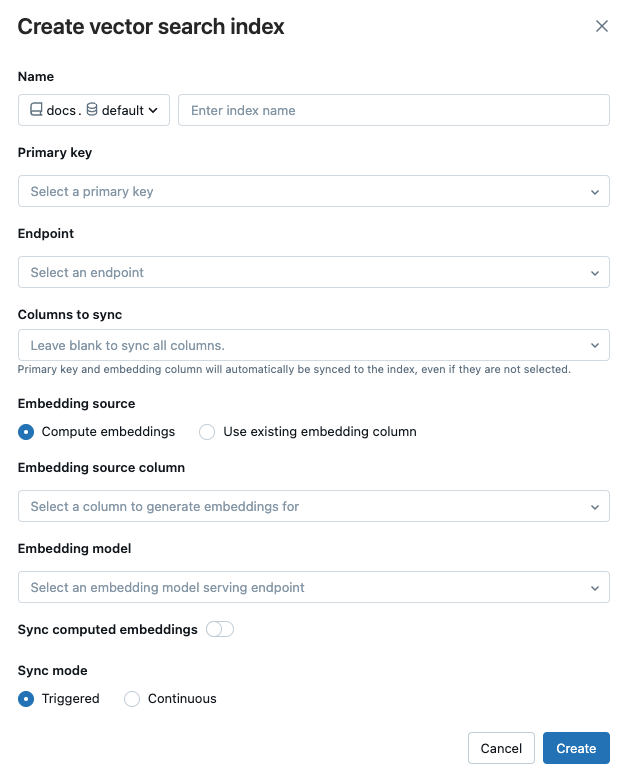
Nom : nom à utiliser pour la table en ligne dans Unity Catalog. Le nom nécessite un espace de noms à trois niveaux,
<catalog>.<schema>.<name>. Seuls les caractères alphanumériques et les traits de soulignement sont autorisés.Clé primaire : colonne à utiliser comme clé primaire.
Point de terminaison : sélectionnez le point de terminaison de recherche vectorielle que vous souhaitez utiliser.
Colonnes à synchroniser : sélectionnez les colonnes à synchroniser avec l’index vectoriel. Si vous laissez ce champ vide, toutes les colonnes de la table source sont synchronisées avec l’index. La colonne de clé primaire et la colonne de la source d’incorporation ou la colonne du vecteur d’incorporation sont toujours synchronisées.
Source d’incorporation : indiquez si Databricks doit calculer des incorporations pour une colonne de texte dans la table Delta (Calculer les incorporations) ou si votre table Delta contient des incorporations précalculées (Utiliser une colonne d’incorporation existante).
- Si vous avez sélectionné Calculer les incorporations, sélectionnez la colonne pour laquelle vous souhaitez calculer les incorporations et le point de terminaison qui sert le modèle d’incorporation. Seules les colonnes de texte sont prises en charge.
- Si vous avez sélectionné Utiliser une colonne d’incorporation existante, sélectionnez la colonne qui contient les incorporations précalculées et la dimension d’incorporation. Le format de la colonne d’intégration précalculée doit être
array[float].
Synchroniser les incorporations calculées : activez ce paramètre pour enregistrer les incorporations générées dans une table de Unity Catalog. Pour plus d’informations, consultez Enregistrer la table d’incorporation générée.
Mode de synchronisation : Continu maintient l’index synchronisé avec quelques secondes de latence. Toutefois, il a un coût plus élevé, car un cluster de calcul est provisionné pour exécuter le pipeline de streaming de synchronisation continue. Pour les mises à jour continues et déclenchées, la mise à jour est incrémentielle – seules les données qui ont changé depuis la dernière synchronisation sont traitées.
Avec le mode de synchronisation déclenché , vous utilisez le Kit de développement logiciel (SDK) Python ou l’API REST pour démarrer la synchronisation. Consultez Mettre à jour un index delta sync.
Une fois l’index configuré, cliquez sur Créer.
Créer un index à l’aide du Kit de développement logiciel (SDK) Python
L’exemple suivant crée un index de synchronisation Delta avec des incorporations calculées par Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
L’exemple suivant crée un index Delta Sync avec des incorporations autogérées. Cet exemple montre également l’utilisation du paramètre facultatif columns_to_sync pour sélectionner uniquement un sous-ensemble de colonnes à utiliser dans l’index.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Par défaut, toutes les colonnes de la table source sont synchronisées avec l’index. Pour synchroniser uniquement un sous-ensemble de colonnes, utilisez columns_to_sync. La clé primaire et les colonnes d’incorporation sont toujours incluses dans l’index.
Pour synchroniser uniquement la clé primaire et la colonne d’incorporation, vous devez les spécifier comme indiqué dans columns_to_sync :
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Pour synchroniser des colonnes supplémentaires, spécifiez-les comme indiqué. Vous n’avez pas besoin d’inclure la clé primaire et la colonne d’incorporation, car elles sont toujours synchronisées.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
L’exemple suivant crée un index d’accès vectoriel direct.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Créer un index à l’aide de l’API REST
Consultez la documentation de référence de l’API REST : POST /api/2.0/vector-search/indexes.
Enregistrer la table d’incorporation générée
Si Databricks génère les incorporations, vous pouvez enregistrer les incorporations générées dans une table de Unity Catalog. Cette table est créée dans le même schéma que l’index vectoriel et est liée à partir de la page d’index vectoriel.
Le nom de la table est le nom de l’index de recherche vectorielle, ajouté par _writeback_table. Le nom n’est pas modifiable.
Vous pouvez accéder à la table et l’interroger comme n’importe quelle autre table dans le Unity Catalog. Toutefois, vous ne devez pas supprimer ou modifier la table, car elle n’est pas destinée à être mise à jour manuellement. La table est supprimée automatiquement si l’index est supprimé.
Mettre à jour un index de recherche vectorielle
Mettre à jour un index Delta Sync
Les index créés avec un mode de synchronisation Continu se mettent automatiquement à jour lors d’un changement de la table Delta source. Si vous utilisez le mode de synchronisation déclenché , utilisez le Kit de développement logiciel (SDK) Python ou l’API REST pour démarrer la synchronisation.
Kit de développement logiciel (SDK) Python
index.sync()
API REST
Consultez la documentation de référence de l’API REST : POST /api/2.0/vector-search/indexes/{index_name}/sync.
Mettre à jour un index d’accès vectoriel direct
Vous pouvez utiliser le Kit de développement logiciel (SDK) Python ou l’API REST pour insérer, mettre à jour ou supprimer des données d’un index d’accès vectoriel direct.
Kit de développement logiciel (SDK) Python
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
API REST
Consultez la documentation de référence de l’API REST : POST /api/2.0/vector-search/indexes.
L’exemple de code suivant montre comment mettre à jour un index à l’aide d’un jeton d’accès personnel (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
L’exemple de code suivant montre comment mettre à jour un index à l’aide d’un principal de service.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Interroger un point de terminaison de recherche vectorielle
Vous ne pouvez interroger le point de terminaison de la recherche vectorielle qu’à l’aide du Kit de développement logiciel (SDK) Python, de l’API REST ou de la fonction SQL AI vector_search().
Remarque
Si l’utilisateur interrogeant le point de terminaison n’est pas le propriétaire de l’index de recherche vectorielle, l’utilisateur doit disposer des privilèges UC suivants :
- UTILISER LE CATALOGUE sur le catalogue qui contient l’index de recherche vectorielle.
- UTILISER LE SCHÉMA sur le schéma qui contient l’index de recherche vectorielle.
- SÉLECTIONNER sur l’index de recherche vectorielle.
Pour effectuer une recherche hybride par mot-clé et par similarité, définissez le paramètre query_type sur hybrid. La valeur par défaut est ann (voisin le plus proche approximative).
Kit de développement logiciel (SDK) Python
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
API REST
Consultez la documentation de référence de l’API REST : POST /api/2.0/vector-search/indexes/{index_name}/query.
L’exemple de code suivant montre comment interroger un index à l’aide d’un jeton d’accès personnel (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
L’exemple de code suivant montre comment interroger un index à l’aide d’un principal de service.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Important
La fonction IA vector_search() est en Préversion publique.
Pour utiliser cette fonction IA, consultez Fonction vector_search.
Utiliser des filtres sur des requêtes
Une requête peut définir des filtres basés sur toute colonne de la table Delta. similarity_search retourne uniquement les lignes qui correspondent aux filtres spécifiés. Les filtres suivants sont pris en charge :
| Opérateur de filtre | Comportement | Exemples |
|---|---|---|
NOT |
Annule le filtre. La clé doit se terminer par « NOT ». Par exemple, « color NOT » avec la valeur « rouge » correspond aux documents où la couleur n’est pas rouge. | {"id NOT": 2} {“color NOT”: “red”} |
< |
Vérifie si la valeur du champ est inférieure à la valeur du filtre. La clé doit se terminer par « <». Par exemple, le « prix < » de valeur 200 correspond aux documents dans lesquels le prix est inférieur à 200. | {"id <": 200} |
<= |
Vérifie si la valeur du champ est inférieure ou égale à la valeur du filtre. La clé doit se terminer par « <= ». Par exemple, le « prix <= » de valeur 200 correspond aux documents dans lesquels le prix est inférieur ou égal à 200. | {"id <=": 200} |
> |
Vérifie si la valeur du champ est supérieure à la valeur du filtre. La clé doit se terminer par « >». Par exemple, le « prix > » de valeur 200 correspond aux documents dans lesquels le prix est supérieur à 200. | {"id >": 200} |
>= |
Vérifie si la valeur du champ est supérieure ou égale à la valeur du filtre. La clé doit se terminer par « >= ». Par exemple, le « prix >= » de valeur 200 correspond aux documents dans lesquels le prix est supérieur ou égal à 200. | {"id >=": 200} |
OR |
Vérifie si la valeur du champ correspond à l’une des valeurs du filtre. La clé doit contenir OR pour séparer plusieurs sous-clés. Par exemple, color1 OR color2 avec la valeur ["red", "blue"] correspond aux documents dans lesquels soit color1 est red, soit color2 est blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Apparie les chaînes partielles. | {"column LIKE": "hello"} |
| Aucun opérateur de filtre spécifié | Le filtre vérifie si une correspondance exacte existe. Si plusieurs valeurs sont spécifiées, il apparie l’une quelconque des valeurs. | {"id": 200} {"id": [200, 300]} |
Consultez les exemples de code suivants :
Kit de développement logiciel (SDK) Python
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
API REST
Consultez POST /api/2.0/vector-search/indexes/{index_name}/query.
Exemples de notebooks
Les exemples de cette section illustrent l’utilisation du SDK Python de recherche vectorielle.
Exemples LangChain
Consultez Comment utiliser LangChain avec Mosaic AI Vector Search pour utiliser Mosaic AI Vector Search en tant qu’intégration avec les packages LangChain.
Le notebook suivant montre comment convertir vos résultats de recherche de similarité en documents LangChain.
Notebook Recherche vectorielle avec le kit SDK Python
Exemples de notebooks d’appel de modèle d’incorporation
Les notebooks suivants montrent comment configurer un point de terminaison Service de modèles Mosaic AI pour la génération d’intégrations.