Mosaic AI Vector Search
Cet article offre une vue d’ensemble de la solution de base de données vectorielle de Databricks, Mosaic AI Vector Search, notamment en quoi elle consiste et son fonctionnement.
Qu’est-ce que Mosaic AI Vector Search ?
Mosaic AI Vector Search est une base de données vectorielle intégrée à la plateforme Data Intelligence Databricks ainsi qu’à ses outils de gouvernance et de productivité. Une base de données vectorielle est une base de données optimisée pour stocker et récupérer des incorporations. Les incorporations sont des représentations mathématiques du contenu sémantique des données, généralement du texte ou des données d’image. Les incorporations sont générées par un modèle de langage volumineux et constituent un composant clé de nombreuses applications GenAI qui dépendent de la recherche de documents ou d’images similaires les uns aux autres. Par exemple, les systèmes RAG, les systèmes de recommandation et la reconnaissance d’images et de vidéos.
Avec Mosaic AI Vector Search, vous créez un index de recherche vectorielle à partir d’une table Delta. L’index inclut des métadonnées à des données incorporées. Vous pouvez ensuite interroger l’index à l’aide d’une API REST pour identifier les vecteurs les plus similaires et retourner les documents associés. Vous pouvez structurer l’index pour qu’il soit automatiquement synchronisé lorsque la table Delta sous-jacente est mise à jour.
La recherche vectorielle De mosaïque AI prend en charge les éléments suivants :
- Recherche de similarité de mot clé hybride.
- Filtrage.
- Listes de contrôle d’accès (ACL) pour gérer les points de terminaison de recherche vectorielles.
- Synchronisez uniquement les colonnes sélectionnées.
- Enregistrez et synchronisez les incorporations générées.
Comment la recherche vectorielle De Mosaïque AI fonctionne-t-elle ?
Mosaic AI Vector Search utilise l’algorithme HNSW (Hierarchical Navigable Small World) pour ses recherches du plus proche voisin et la métrique de distance Distance L2 pour mesurer la similarité vectorielle incorporée. Si vous souhaitez utiliser la similarité cosinus, vous devez normaliser vos incorporations de points de données avant de les introduire dans la recherche vectorielle. Lorsque les points de données sont normalisés, le classement produit par la distance L2 est identique au classement produit par la similarité cosinus.
Mosaic AI Vector Search prend également en charge la recherche par similarité de mot clé hybride, qui combine la recherche incorporée basée sur des vecteurs avec des techniques de recherche traditionnelles basées sur des mots clés. Cette approche trouve des correspondances de mots exacts dans la requête tout en utilisant également une recherche par similarité basée sur des vecteurs pour capturer les relations sémantiques et le contexte de la requête.
En intégrant ces deux techniques, la recherche par similarité de mot clé hybride récupère non seulement les documents qui contiennent les mots clés exacts, mais aussi ceux qui sont conceptuellement similaires, fournissant des résultats de recherche plus complets et pertinents. Cette méthode est particulièrement utile dans les applications RAG où les données sources contiennent des mots clés uniques tels que des références SKU ou des identificateurs qui ne sont pas bien adaptés à une recherche par similarité pure.
Pour plus de détails sur l’API, consultez les informations de référence sur le Kit de développement logiciel (SDK) Python et Interroger un point de terminaison de recherche vectorielle.
Calcul de recherche de similarité
Le calcul de recherche de similarité utilise la formule suivante :
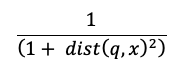
où dist est la distance euclidienne entre la requête q et l’entrée d’index x:
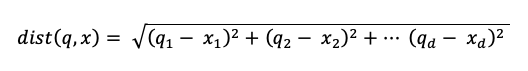
Algorithme de recherche par mot clé
Les scores de pertinence sont calculés en utilisant Okapi BM25. Toutes les colonnes de texte ou de chaîne sont recherchées, y compris le texte source incorporé et les colonnes de métadonnées au format texte ou chaîne. La fonction de tokenisation se fractionne aux limites du mot, supprime la ponctuation et convertit tout le texte en minuscules.
Combinaison de la recherche par similarité et de la recherche par mots clé
Les résultats de la recherche par similarité et de la recherche par mots clés sont combinés en utilisant la fonction de fusion de classement réciproque (RRF, Mutual Rank Fusion).
RRF réévalue chaque document de chaque méthode en utilisant le score :
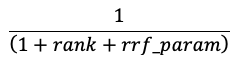
Dans l’équation ci-dessus, le classement commence à 0, additionne les scores de chaque document et renvoie les documents ayant les scores les plus élevés.
rrf_param contrôle l’importance relative des documents mieux classés et moins bien classés. D’après la littérature, rrf_param est réglé à 60.
Les scores sont normalisés de sorte que le score le plus élevé soit 1 et le score le plus bas soit 0 en utilisant l’équation suivante :
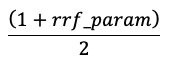
Options de fourniture des incorporations vectorielles
Pour créer une base de données vectorielle dans Databricks, vous devez d’abord décider comment fournir des incorporations vectorielles. Databricks prend en charge trois options :
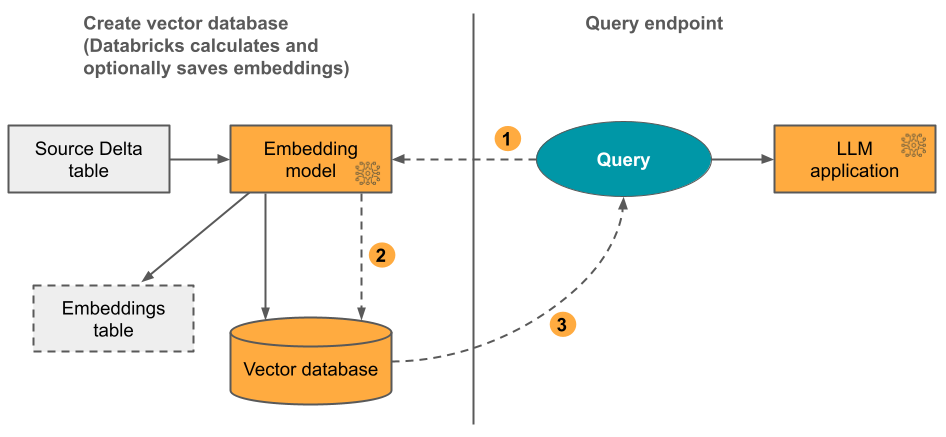
Option 1 : Index Delta Sync avec des incorporations calculées par Databricks Vous fournissez une table Delta source qui contient des données au format texte. Databricks calcule les incorporations à l’aide d’un modèle que vous spécifiez et enregistre éventuellement les incorporations dans une table du catalogue Unity. À mesure que la table Delta est mise à jour, l’index reste synchronisé avec la table Delta.
Le diagramme suivant illustre ce processus :
- Calculer les incorporations de requêtes. La requête peut inclure des filtres de métadonnées.
- Effectuer une recherche de similarités pour identifier les documents les plus pertinents.
- Retourner les documents les plus pertinents et les ajouter à la requête.
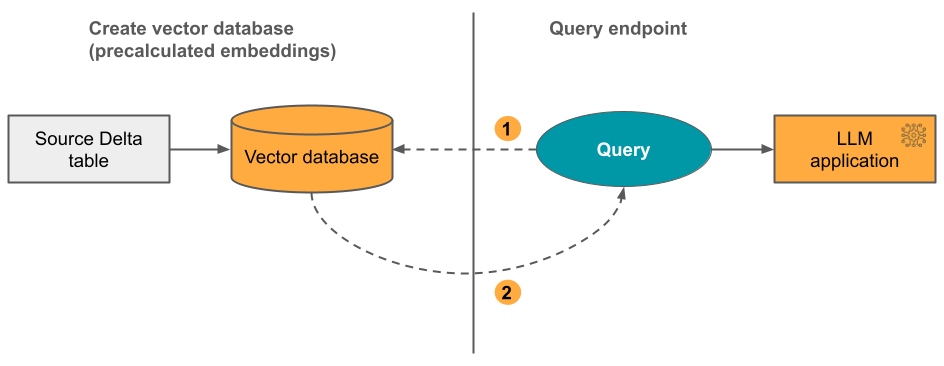
Option 2 : Index Delta Sync avec incorporations autogérés Vous fournissez une table Delta source qui contient des incorporations précalculées. À mesure que la table Delta est mise à jour, l’index reste synchronisé avec la table Delta.
Le diagramme suivant illustre ce processus :
- La requête se compose d’incorporations et peut inclure des filtres de métadonnées.
- Effectuer une recherche de similarités pour identifier les documents les plus pertinents. Retourner les documents les plus pertinents et les ajouter à la requête.
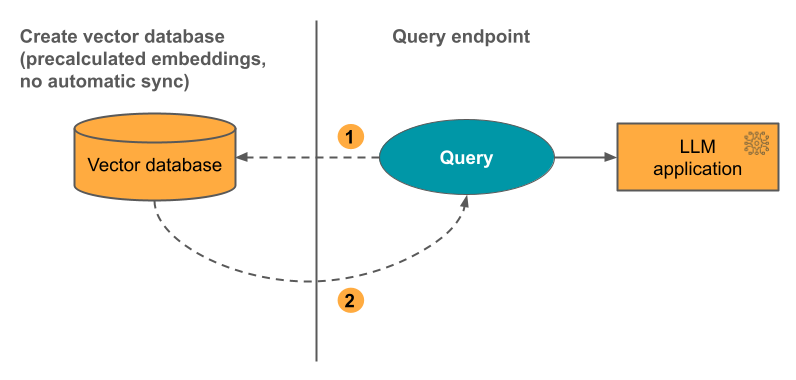
Option 3 : Index d’accès direct au vecteur Vous devez mettre à jour manuellement l’index à l’aide de l’API REST lorsque la table d’incorporation change.
Le diagramme suivant illustre ce processus :
Comment configurer Mosaic AI Vector Search
Pour utiliser Mosaic AI Vector Search, vous devez créer les éléments suivants :
- Un point de terminaison de recherche vectorielle. Ce point de terminaison sert l’index de recherche vectorielle. Vous pouvez interroger et mettre à jour le point de terminaison à l’aide de l’API REST ou du kit de développement logiciel (SDK). Les points de terminaison sont mis à l’échelle automatiquement pour prendre en charge la taille de l’index ou le nombre de requêtes simultanées. Consultez Créer un point de terminaison de recherche vectorielle pour obtenir des instructions.
- Index de recherche vectorielle. L’index de recherche vectorielle est créé à partir d’une table Delta et est optimisé pour fournir des recherches du plus proche voisin en temps réel. L’objectif de la recherche est d’identifier les documents similaires à la requête. Les index de recherche vectorielle s’affichent dans le catalogue Unity où ils sont aussi régis. Consultez Créer un index de recherche vectorielle pour obtenir des instructions.
De plus, si vous choisissez Databricks pour calculer les incorporations, vous pouvez utiliser un point de terminaison d’API Foundation Model préconfiguré ou créer un point de terminaison de service de modèles pour servir le modèle d’incorporation de votre choix. Pour obtenir des instructions, consultez API Foundation Model de paiement par jeton ou Créer des points de terminaison de service de modèles d’IA générative.
Pour interroger le point de terminaison de service du modèle, vous devez utiliser l’API REST ou le kit de développement logiciel (SDK) Python. Votre requête peut définir des filtres en fonction de n’importe quelle colonne de la table Delta. Pour plus d’informations, consultez Utiliser des filtres sur les requêtes, la référence de l’API ou la référence du kit de développement logiciel (SDK) Python.
Spécifications
- Espace de travail avec Unity Catalog
- Calcul serverless activé Pour obtenir des instructions, consultez Se connecter au calcul serverless.
- Le flux des changements de données être activé dans la table source. Pour obtenir des instructions, consultez Utiliser le flux des changements de données Delta Lake sur Azure Databricks.
- Privilèges CREATE TABLE sur les schémas de catalogue pour créer des index.
- Jetons d’accès personnels activés
L’autorisation de créer et de gérer des points de terminaison de recherche vectorielle est configurée à l’aide de listes de contrôle d’accès. Consultez les listes de contrôle d’accès du point de terminaison de recherche vectorielle.
Authentification et protection des données
Databricks implémente les contrôles de sécurité suivants pour protéger vos données :
- Chaque requête d’un client adressée à Mosaic AI Vector Search est logiquement isolée, authentifiée et autorisée.
- Mosaic AI Vector Search chiffre toutes les données au repos (AES-256) et en transit (TLS 1.2+).
Mosaic Vector Search prend en charge deux modes d’authentification :
- Jeton d’accès personnel : vous pouvez utiliser un jeton d’accès personnel pour vous authentifier auprès de Mosaic AI Vector Search. Consultez jeton d’authentification d’accès personnel. Si vous utilisez le kit de développement logiciel (SDK) dans un environnement de notebook, il génère automatiquement un jeton PAT pour l’authentification.
- Jeton de principal de service : un administrateur peut générer un jeton de principal de service et le transmettre au Kit de développement logiciel (SDK) ou à l’API. Consultez utiliser des principaux de service. Pour les cas d’utilisation en production, Databricks recommande d’utiliser un jeton de principal de service.
Les clés gérées par le client (CMK) sont prises en charge sur les points de terminaison créés à partir du 8 mai 2024.
Surveiller l’utilisation et les coûts
La table système d’utilisation facturable vous permet de surveiller l’utilisation et les coûts associés aux index et points de terminaison de recherche vectorielle. Voici un exemple de requête :
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL
THEN 'ingest'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
SUM(usage_quantity) as dbus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Pour plus d’informations sur le contenu de la table d’utilisation de facturation, consultez informations de référence de table système d’utilisation facturable. Des requêtes supplémentaires se trouvent dans l’exemple de notebook suivant.
Notebook de requêtes de tables système de recherche vectorielle
Limites de taille des ressources et des données
Le tableau suivant récapitule les limites de taille des ressources et des données pour les points de terminaison et les index de recherche vectorielle :
| Ressource | Granularité | Limite |
|---|---|---|
| Points de terminaison de recherche vectorielle | Par espace de travail | 100 |
| Incorporations | Par point de terminaison | 320,000,000 |
| Incorporation des dimensions | Par index | 4096 |
| Index | Par point de terminaison | 50 |
| Colonnes | Par index | 50 |
| Colonnes | Types pris en charge : octets, court, entier, long, flottant, double, booléen, chaîne, timestamp, date | |
| Champs de métadonnées | Par index | 20 |
| Nom d’index | Par index | 128 caractères |
Les limites suivantes s’appliquent à la création et à la mise à jour des index de recherche vectorielle :
| Ressource | Granularité | Limite |
|---|---|---|
| Taille de ligne pour l’index Delta Sync | Par index | 100 Ko |
| Incorporation de la taille de colonne source pour l’index Delta Sync | Par index | 32764 octets |
| Limite de taille de requête upsert en bloc pour l’index Direct Vector | Par index | 10 Mo |
| Limite de taille des requêtes de suppression en bloc pour l’index Direct Vector | Par index | 10 Mo |
Les limites suivantes s’appliquent à l’API de requête.
| Ressource | Granularité | Limite |
|---|---|---|
| Longueur du texte de requête | Par requête | 32764 |
| Nombre maximal de résultats retournés | Par requête | 10,000 |
Limites
- Les autorisations au niveau de la ligne et de la colonne ne sont pas prises en charge. Vous pouvez toutefois implémenter vos propres listes de contrôle (ACL) au niveau de l’application à l’aide de l’API de filtre.