RAG (Génération augmentée de récupération) sur Azure Databricks
Important
Cette fonctionnalité est disponible en préversion publique.
Agent Framework comprend un ensemble d’outils sur Databricks conçus pour aider les développeurs à créer, déployer et évaluer des agents IA de qualité de production comme les applications Retrieval Augmented Generation (RAG).
Cet article explique ce qu’est la RAG et présente les avantages du développement d’applications RAG sur Azure Databricks.
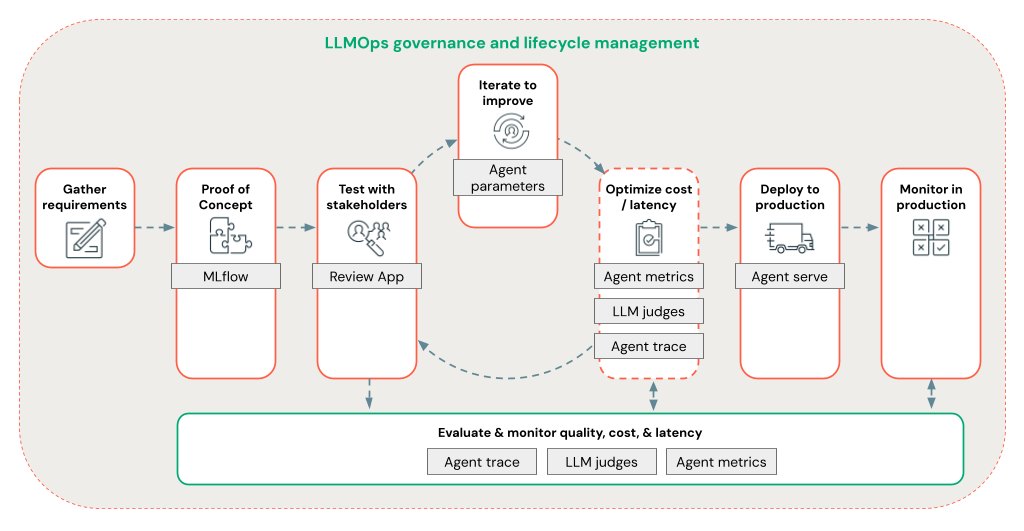
Agent Framework permet aux développeurs d’itérer rapidement sur tous les aspects du développement RAG à l’aide d’un flux de travail LLMOps de bout en bout.
Spécifications
- Les fonctionnalités d’assistance basées sur l’IA optimisées par Azure doivent être activées pour votre espace de travail.
- Tous les composants d’une application agentique doivent se trouver dans un espace de travail unique. Par exemple, dans le cas d’une application RAG, le modèle de desserte et l’instance de recherche vectorielle doivent se trouver dans le même espace de travail.
Qu’est-ce que RAG ?
RAG est une technique de conception IA générative qui améliore les grands modèles de langage (LLM) avec des connaissances externes. Cette technique améliore les LLM de la manière suivante :
- Connaissances protégées : RAG peut inclure des informations protégées non utilisées initialement pour entraîner les LLM, tels que des mémo, des e-mails et des documents pour répondre à des questions spécifiques au domaine.
- Informations à jour : une application RAG peut fournir des LLM avec des informations provenant de sources de données mises à jour.
- Citation de sources : RAG permet aux LLM de citer des sources spécifiques, ce qui permet aux utilisateurs de vérifier l’exactitude factuelle des réponses.
- Listes de contrôle d’accès (ACL) et de sécurité des données : l’étape de récupération peut être conçue pour récupérer de manière sélective des informations personnelles ou protégées en fonction des informations d’identification de l’utilisateur.
Systèmes IA composés
Une application RAG est un exemple de système IA composé : elle s’étend sur les fonctionnalités de langage des LLM en la combinant avec d’autres outils et procédures.
Dans la forme la plus simple, une application RAG effectue les opérations suivantes :
- Récupération : la requête de l’utilisateur est exploitée pour interroger un magasin de données externe, tel qu’un magasin vectoriel, une recherche par mot clé de texte ou une base de données SQL. L’objectif est d’obtenir des données de prise en charge pour la réponse des LLM.
- Augmentation : les données récupérées sont combinées à la requête de l’utilisateur, souvent à l’aide d’un modèle avec une mise en forme et des instructions supplémentaires, pour créer une invite.
- Génération : l’invite est transmise aux LLM, qui génère ensuite une réponse à la requête.
Données RAG non structurées ou structurées
L’architecture RAG peut fonctionner avec des données de prise en charge non structurées ou structurées. Les données que vous utilisez avec RAG dépendent de votre cas d’utilisation.
Données non structurées : données sans structure ou organisation spécifique. Documents qui incluent du texte et des images ou du contenu multimédia, comme l’audio ou les vidéos.
- Fichiers PDF
- Documents Google/Office
- Wikis
- Images
- Vidéos
Données structurées : données tabulaires organisées dans des lignes et des colonnes avec un schéma spécifique, comme les tables d’une base de données.
- Enregistrements de clients dans un système de BI ou d’entrepôt de données
- Données de transaction à partir d’une base de données SQL
- Données provenant d’API d’application (par exemple, SAP, Salesforce, etc.)
Les sections suivantes décrivent une application RAG pour les données non structurées.
Pipeline de données RAG
Le pipeline de données RAG prétraite et indexe les documents pour une recherche rapide et précise.
Le diagramme ci-dessous montre un exemple de pipeline de données pour un jeu de données non structuré à l’aide d’un algorithme de recherche sémantique. Les travaux Databricks orchestrent chaque étape.
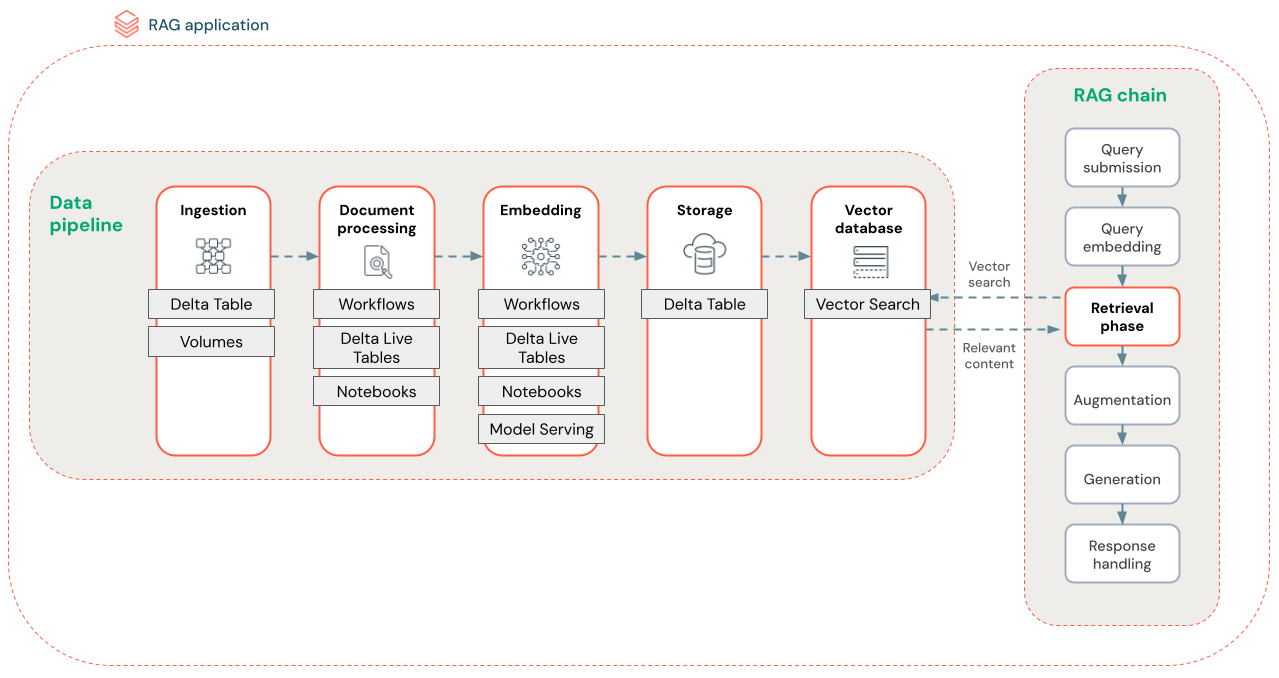
- Ingestion des données : ingérer les données à partir de votre source protégée. Stockez ces données dans une table Delta ou un volume Unity Catalog.
- Traitement des documents : Vous pouvez effectuer ces tâches à l’aide des travaux Databricks, des notebooks Databricks et des tables Delta Live.
- Analyse des documents bruts : transformez les données brutes dans un format utilisable. Par exemple, l’extraction du texte, des tables et des images d’une collection de fichiers PDF ou l’utilisation de techniques de reconnaissance optique de caractères pour extraire du texte d’images.
- Extraction des métadonnées : extrayez les métadonnées des documents, telles que les titres, les numéros de page et les URL, afin de permettre à l’étape de recherche d’être plus précise.
- Documents de bloc : fractionnez les données en blocs qui s’intègrent dans la fenêtre de contexte LLM. La récupération de ces blocs ciblés, plutôt que de documents entiers, donne au LLM un contenu plus ciblé pour générer des réponses.
- Segments d’incorporation : un modèle d’incorporation consomme les blocs pour créer des représentations numériques des informations appelées incorporations vectorielles. Les vecteurs représentent la signification sémantique du texte, et pas seulement les mots-clés de surface. Dans ce scénario, vous calculez les incorporations et utilisez Model Serving pour servir le modèle d’incorporation.
- Stockage de l’incorporation : stockez les incorporations vectorielles et le texte du bloc dans une table Delta synchronisée avec la recherche vectorielle.
- Base de données vectorielles : dans le cadre de la recherche vectorielle, les incorporations et les métadonnées sont indexées et stockées dans une base de données vectorielle pour faciliter les requêtes de l’agent RAG. Lorsqu’un utilisateur effectue une requête, sa requête est incorporée dans un vecteur. La base de données utilise ensuite l’index vectoriel pour rechercher et retourner les blocs les plus similaires.
Chaque étape implique des décisions d’ingénierie qui ont un impact sur la qualité de l’application RAG. Par exemple, le choix de la bonne taille de bloc à l’étape (3) garantit que le LLM reçoit des informations spécifiques mais contextualisées, tandis que la sélection d’un modèle d’incorporation approprié à l’étape (4) détermine l’exactitude des blocs retournés lors de la recherche.
Recherche vectorielle Databricks
Le calcul de la similarité est souvent coûteux, mais les index vectoriels tels que la recherche vectorielle Databricks l’optimisent en organisant efficacement les incorporations. Les recherches vectorielles classent rapidement les résultats les plus pertinents sans comparer chaque incorporation à la requête de l’utilisateur individuellement.
La recherche vectorielle synchronise automatiquement les nouvelles incorporations ajoutées à votre table Delta et met à jour l’index de la recherche vectorielle.
Qu’est-ce qu’un agent RAG ?
Un agent de génération augmentée de récupération (RAG) est un élément clé d’une application RAG qui améliore les fonctionnalités des grands modèles de langage (LLM) en intégrant l’extraction de données externes. L’agent RAG traite les requêtes utilisateur, récupère les données pertinentes d’une base de données vectorielle et transmet ces données aux LLM pour générer une réponse.
Des outils comme LangChain ou Pyfunc relient ces étapes en connectant leurs entrées et sorties.
Le diagramme ci-dessous montre un agent RAG pour un chatbot et les fonctionnalités Databricks utilisées pour générer chaque agent.
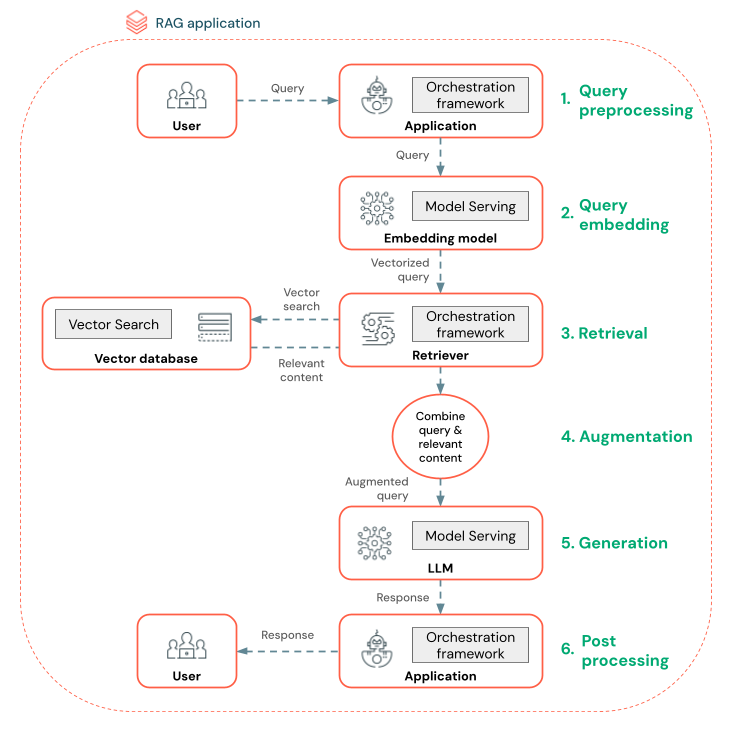
- Prétraitement de la requête : un utilisateur soumet une requête, qui est ensuite prétraitée pour la rendre apte à interroger la base de données vectorielle. Il peut s’agir de placer la requête dans un modèle ou d’extraire des mots clés.
- Vectorisation de la requête: utiliser Model Serving pour incorporer la requête à l’aide du même modèle d’incorporation que celui utilisé pour incorporer les blocs dans le pipeline de données. Ces incorporations permettent de comparer la similarité sémantique entre la requête et les blocs prétraités.
- Phase de récupération : l’extracteur, une application chargée d’extraire les informations pertinentes, prend la requête vectorisée et effectue une recherche de similarité vectorielle à l’aide de la recherche vectorielle. Les blocs de données les plus pertinents sont classés et récupérés en fonction de leur similarité à la requête.
- Augmentation de l’invite : l’extracteur combine les blocs de données récupérés avec la requête d’origine pour fournir un contexte supplémentaire au LLM. L’invite est soigneusement structurée pour s’assurer que les LLM comprennent le contexte de la requête. Les LLM disposent souvent d’un modèle pour mettre en forme la réponse. Ce processus d’ajustement de l’invite est appelé ingénierie d’invite.
- Phase de génération des LLM : les LLM génèrent une réponse à l’aide de la requête enrichie par les résultats de la recherche. Les LLM peuvent être un modèle personnalisé ou un modèle de base.
- Post-traitement : la réponse des LLM peut être traitée pour appliquer une logique professionnelle supplémentaire, ajouter des citations ou affiner le texte généré sur la base de règles ou de contraintes prédéfinies
Différents garde-fous peuvent être appliqués tout au long de ce processus pour garantir la conformité aux stratégies d’entreprise. Il peut s’agir de filtrer les requêtes appropriées, de vérifier les autorisations des utilisateurs avant d’accéder aux sources de données et d’utiliser des techniques de modération du contenu pour les réponses générées.
Développement d’agent RAG au niveau de la production
Effectuez rapidement une itération sur le développement d’agents à l’aide des fonctionnalités suivantes :
Créez et journalisez des agents à l’aide de n’importe quelle bibliothèque et MLflow. Paramétrisez vos agents pour expérimenter et itérer rapidement sur le développement d’agents.
Déployez des agents en production avec prise en charge native de la diffusion en continu des jetons et de la journalisation des requêtes/réponses, ainsi qu’une application de révision intégrée pour obtenir les commentaires des utilisateurs pour votre agent.
Le suivi de l’agent vous permet de journaliser, d’analyser et de comparer des traces dans votre code d’agent pour déboguer et comprendre comment votre agent répond aux demandes.
Évaluation et surveillance
L’évaluation et la surveillance permettent de déterminer si votre application RAG répond à vos exigences de qualité, de coût et de latence. L’évaluation se produit pendant le développement, tandis que la surveillance se produit une fois que l’application est déployée en production.
La RAG sur les données non structurées comporte de nombreux éléments qui ont un impact sur la qualité. Par exemple, les modifications de mise en forme des données peuvent influencer les blocs récupérés et la capacité des LLM à générer des réponses pertinentes. Il est donc important d’évaluer des composants individuels en plus de l’application globale.
Pour plus d’informations, consultez Qu’est-ce que l’évaluation de l’agent Mosaic AI ?.
Disponibilité dans les régions
Pour la disponibilité régionale d’Agent Framework, consultez Fonctionnalités avec une disponibilité régionale limitée