Améliorer la qualité du pipeline de données RAG
Cet article explique comment expérimenter des choix pour les pipelines de données d’un point de vue pratique lors de l’implémentation de modifications des pipelines de données.
Composants clés du pipeline de données
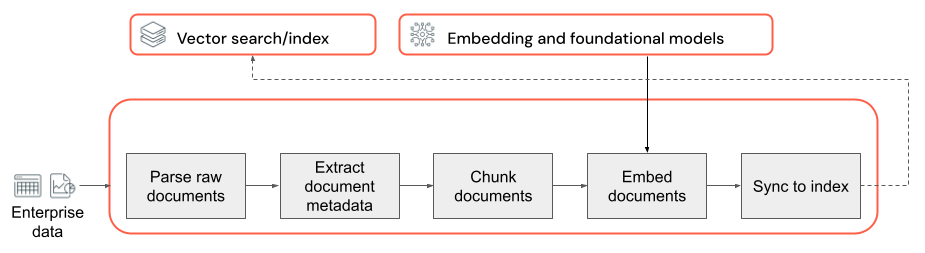
La base de toutes les applications RAG avec des données non structurées est le pipeline de données. Ce pipeline est chargé de préparer les données non structurées dans un format qui peut être utilisé effectivement par l’application RAG. Bien que ce pipeline de données puisse devenir arbitrairement complexe, voici les composants clés à prendre en compte lors de la création de votre application RAG :
- Composition du corpus : sélectionner les sources de données et le contenu appropriés en fonction du cas d’usage spécifique.
- Analyse : extraire les informations pertinentes des données brutes en utilisant des techniques d’analyse appropriées.
- Segmentation : décomposer les données analysées en blocs plus petits et gérables pour permettre une extraction efficace.
- Incorporation : convertir les données texte segmentées en une représentation vectorielle numérique qui reflète sa signification sémantique.
Composition du corpus
Sans le corpus de données approprié, votre application RAG ne peut pas extraire les informations nécessaires pour répondre à la requête d’un utilisateur. Les données appropriées dépendent entièrement des exigences et des objectifs spécifiques de votre application : il est donc essentiel de consacrer du temps à la compréhension des nuances des données disponibles (consultez la section sur les exigences de la collecte pour obtenir de l’aide).
Par exemple, lors de la création d’un bot de support client, vous pouvez envisager d’inclure :
- Des documents issus de bases de connaissances
- Forum Aux Questions (FAQ)
- Des manuels et des spécifications de produit
- Guides de résolution des problèmes
Engagez des experts du domaine et des parties prenantes dès le début d’un projet pour identifier et organiser un contenu pertinent qui pourrait améliorer la qualité et la couverture de votre corpus de données. Ils peuvent fournir des insights sur les types de requêtes que les utilisateurs sont susceptibles de soumettre et aider à hiérarchiser les informations les plus importantes à inclure.
Analyse
Une fois que vous avez identifié les sources de données pour votre application RAG, l’étape suivante consiste à extraire les informations requises des données brutes. Ce processus, appelé analyse, implique la transformation des données non structurées en un format qui peut être utilisé effectivement par l’application RAG.
Les techniques et outils d’analyse spécifiques que vous utilisez dépendent du type des données avec lesquelles vous travaillez. Par exemple :
- Documents texte (PDF, documents Word) : bibliothèques prêtes à l’emploi comme unstructured et PyPDF2 peuvent gérer différents formats de fichiers et fournir des options de personnalisation du processus d’analyse.
- Documents HTML : des bibliothèques d’analyse HTML comme BeautifulSoup peuvent être utilisées pour extraire du contenu pertinent dans des pages web. Avec ces bibliothèques, vous pouvez naviguer dans la structure HTML, sélectionner des éléments spécifiques et extraire le texte ou les attributs souhaités.
- Images et documents numérisés : des techniques de reconnaissance optique de caractères (OCR) sont généralement nécessaires pour extraire du texte dans les images. Tesseract, Amazon Textract, Azure AI Vision OCR et l’API Google Cloud Vision sont des bibliothèques OCR répandues.
Meilleures pratiques pour l’analyse des données
Lors de l’analyse de vos données, tenez compte des meilleures pratiques suivantes :
- Nettoyage des données : prétraitez le texte extrait pour supprimer les informations non pertinentes ou représentant du bruit, comme les en-têtes, les pieds de page ou les caractères spéciaux. Veillez à réduire la quantité d’informations non nécessaires ou mal mises en forme que votre chaîne RAG doit traiter.
- Gestion des erreurs et des exceptions : implémentez des mécanismes de gestion et de journalisation des erreurs pour identifier et résoudre les problèmes rencontrés pendant le processus d’analyse. Ceci vous aise à identifier et résoudre rapidement les problèmes. Cette démarche met souvent en évidence des problèmes en amont liés à la qualité des données sources.
- Personnalisation de la logique d’analyse : en fonction de la structure et du format de vos données, il peut être nécessaire de personnaliser la logique d’analyse pour extraire les informations les plus pertinentes. Bien que cela puisse nécessiter un effort supplémentaire en amont, investissez le temps nécessaire à cette démarche, car elle permet souvent d’éviter de nombreux problèmes de qualité en aval.
- Évaluation de la qualité de l’analyse : évaluez régulièrement la qualité des données analysées en examinant manuellement un échantillon du résultat. Ceci peut vous aider à identifier les problèmes ou les points à améliorer dans le processus d’analyse.
Segmentation
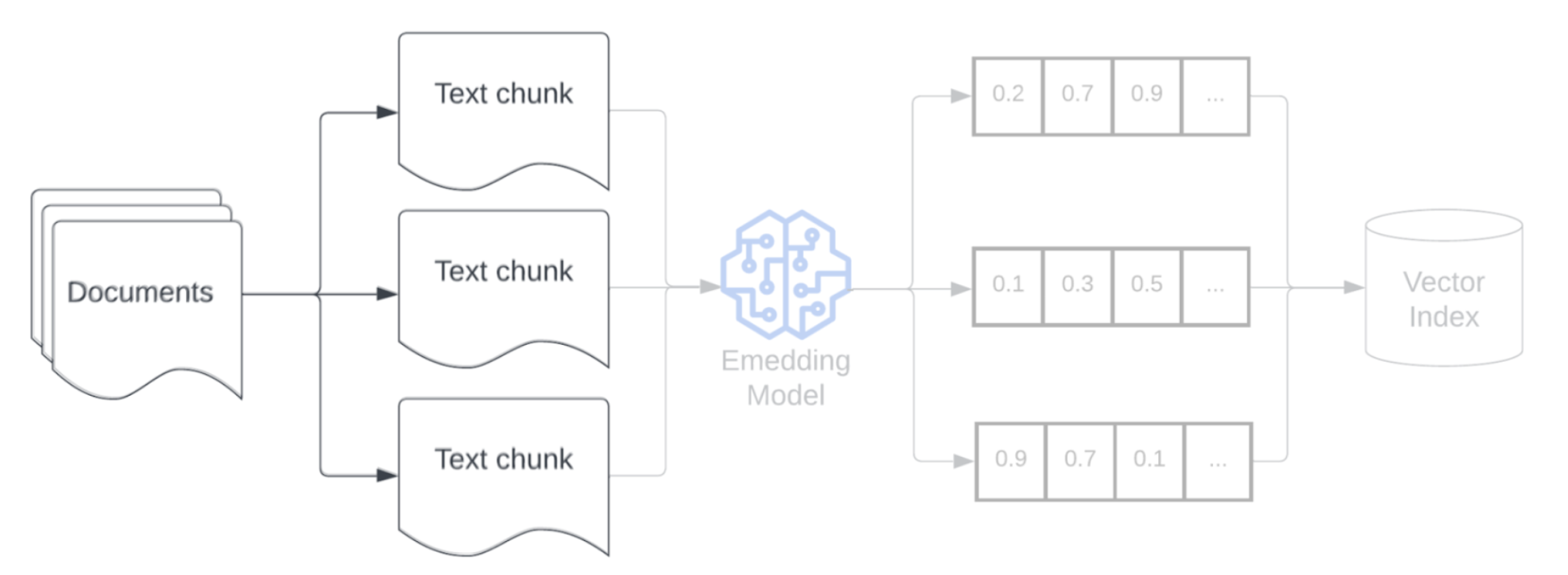
Après avoir analysé les données brutes dans un format plus structuré, l’étape suivante consiste à les décomposer en unités plus petites et plus gérables, appelées blocs. Segmenter des grands documents en blocs plus petits et sémantiquement concentrés garantit que les données extraites s’intègrent dans le contexte du LLM, tout en réduisant au minimum l’inclusion d’informations détournant l’attention ou non pertinentes. Les choix effectués pour la segmentation affectent directement les données extraites fournies au LLM, ce qui en fait une des premières couches d’optimisation dans une application RAG.
Lors de la segmentation de vos données, tenez compte des facteurs suivants :
- Stratégie de segmentation : la méthode que vous utilisez pour diviser le texte d’origine en segments. Ceci peut impliquer des techniques de base comme le fractionnement par phrases, par paragraphes ou par nombres de caractères/jetons spécifiques, via des stratégies de fractionnement plus avancées spécifiques au document.
- Taille des blocs : des blocs plus petits permettent de se concentrer sur des détails spécifiques, mais peuvent entraîner la perte d’informations du voisinage. Des blocs plus grands peuvent capturer davantage de contexte, mais ils peuvent également inclure des informations non pertinentes.
- Chevauchement entre blocs : pour faire en sorte que des informations importantes ne sont pas perdues lors du fractionnement des données en segments, envisagez d’inclure du chevauchement entre des blocs adjacents. Le chevauchement peut garantir la continuité et la préservation du contexte dans les segments.
- Cohérence sémantique : dans la mesure du possible, visez à créer des blocs sémantiquement cohérents, ce qui signifie qu’ils contiennent des informations connexes et qu’ils peuvent constituer à eux seuls une unité de texte significative. Pour cela, il faut tenir compte de la structure des données d’origine, comme les paragraphes, les sections ou les limites des sujets.
- Métadonnées : inclure des métadonnées pertinentes au sein de chaque segment, comme le nom du document source, le titre de la section ou les noms des produits, peut améliorer le processus d’extraction. Ces informations supplémentaires dans le bloc peuvent aider à faire correspondre les requêtes d’extraction aux blocs.
Stratégies de segmentation des données
La recherche de la méthode de segmentation appropriée est à la fois itérative et dépendante du contexte. Il n’y a pas qu’une seule approche : la taille des blocs et la méthode optimales dépendent du cas d’usage spécifique et de la nature des données à traiter. D’une façon générale, les stratégies de segmentation peuvent être les suivantes :
- Segmentation de taille fixe : fractionner le texte en blocs d’une taille prédéterminée, comme un nombre fixe de caractères ou de jetons (par exemple CharacterTextSplitter de LangChain). Bien que le fractionnement selon un nombre arbitraire de caractères/jetons soit rapide et facile à configurer, il ne va généralement pas aboutir à des blocs sémantiquement cohérents.
- Segmentation basée sur les paragraphes : utilisez les limites naturelles des paragraphes dans le texte pour définir des blocs. Cette méthode peut aider à préserver la cohérence sémantique des blocs, car les paragraphes contiennent souvent des informations connexes (par exemple RecursiveCharacterTextSplitter de LangChain).
- Segmentation spécifique au format : des formats tels que Markdown ou HTML ont une structure inhérente qui peut être utilisée pour définir les limites des blocs (par exemple les en-têtes Markdown). Des outils tels que MarkdownHeaderTextSplitter de LangChain, ou des séparateurs basés sur les éléments HTML header/ ou section peuvent être utilisés à cette fin.
- Segmentation sémantique : des techniques telles que la modélisation de sujet peuvent être appliquées pour identifier des sections sémantiquement cohérentes au sein du texte. Ces approches analysent le contenu ou la structure de chaque document pour déterminer les limites des blocs les plus appropriées en fonction des majuscules dans le sujet. Bien que plus complexe que les approches plus basiques, la segmentation sémantique peut aider à créer des blocs plus alignés avec les divisions sémantiques naturelles du texte (voir SemanticChunker de LangChain pour en obtenir un exemple).
Exemple : segmentation de taille fixe
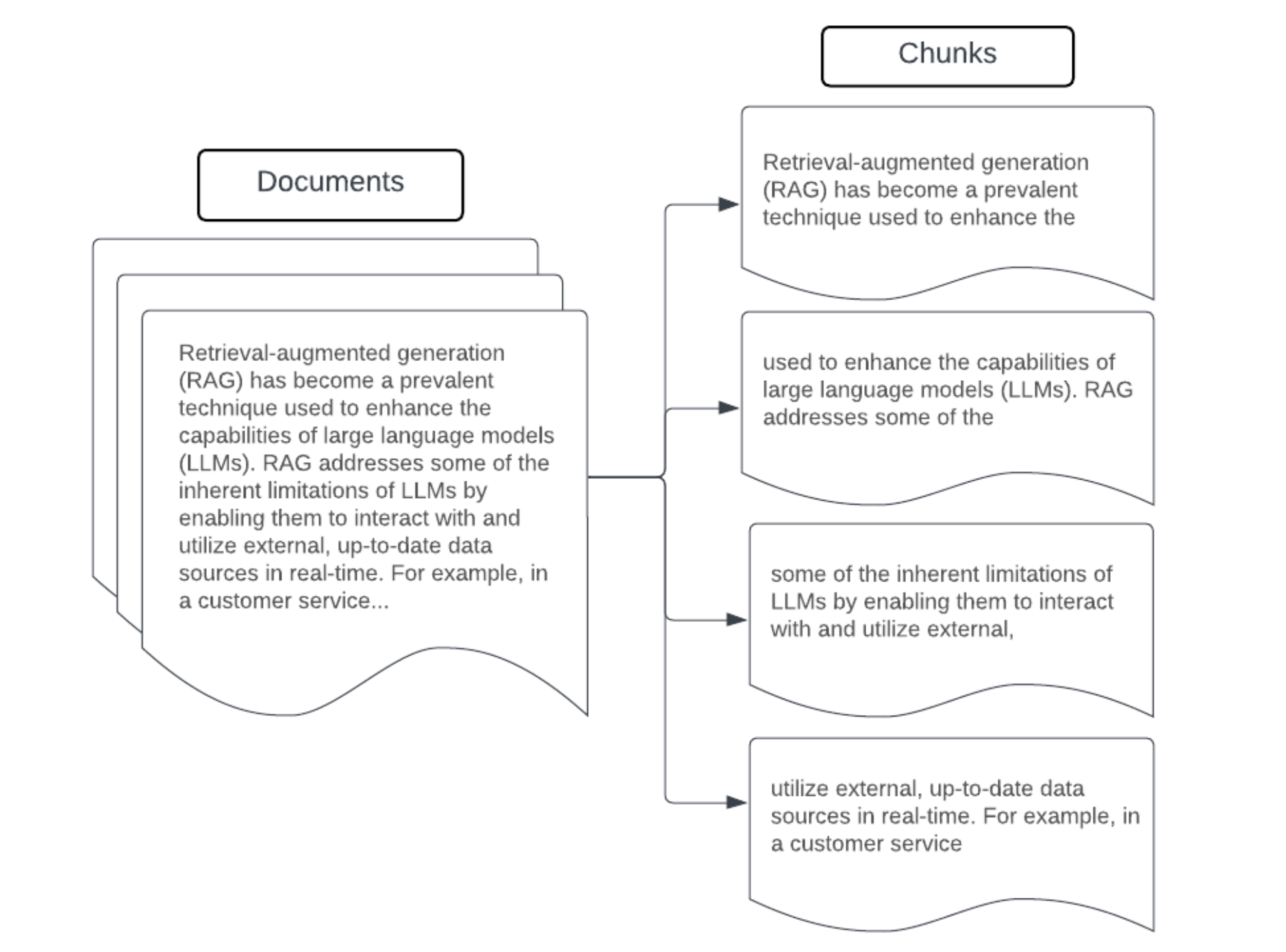
Exemple de segmentation de taille fixe en utilisant RecursiveCharacterTextSplitter de LangChain avec chunk_size=100 et chunk_overlap=20. ChunkViz offre un moyen interactif de visualiser la façon dont différentes valeurs pour la taille de bloc et le chevauchement de blocs avec les séparateurs de caractères de LangChain affectent les blocs résultants.
Modèle d'intégration
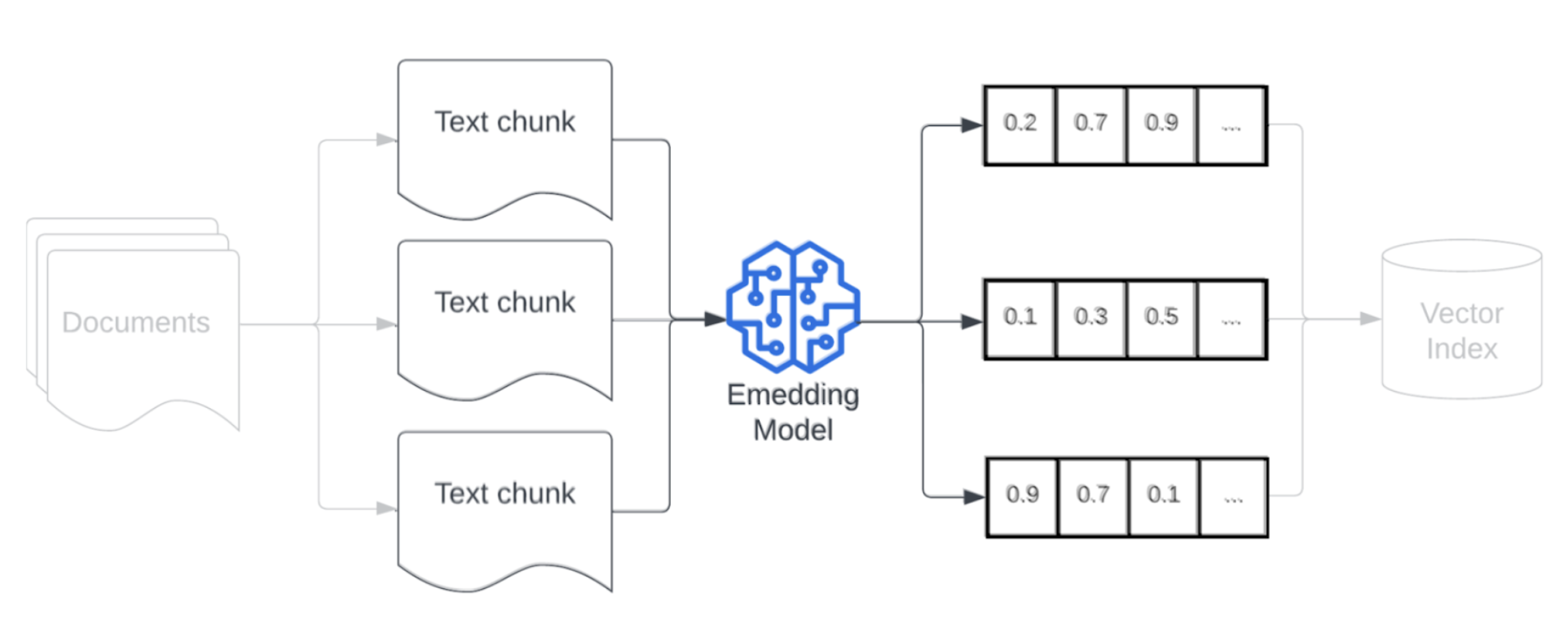
Une fois que vous avez segmenté vos données, l’étape suivante consiste à convertir les blocs de texte en une représentation vectorielle en utilisant un modèle d’incorporation. Un modèle d’incorporation est utilisé pour convertir chaque bloc de texte en une représentation vectorielle qui capture sa signification sémantique. En représentant les blocs sous forme de vecteurs denses, les incorporations permettent une extraction rapide et précise des blocs les plus pertinents en fonction de leur similarité sémantique avec une requête d’extraction. Au moment de la requête, la requête d’extraction sera transformée en utilisant le même modèle d’incorporation que celui utilisé pour incorporer les blocs dans le pipeline de données.
Quand vous sélectionnez un modèle d’incorporation, tenez compte des facteurs suivants :
- Choix du modèle : chaque modèle d’incorporation a ses nuances et les benchmarks disponibles peuvent ne pas capturer les caractéristiques spécifiques de vos données. Expérimentez différents modèles d’incorporation prêts à l’emploi, même ceux qui peuvent figurer plus bas dans des classements standard, comme MTEB. Voici quelques exemples à considérer :
- Nombre maximal de jetons : tenez compte de la limite maximale de jetons pour le modèle d’incorporation que vous choisissez. Si vous passez des blocs qui excèdent cette limite, ils seront tronqués, ce qui risque de vous faire perdre des informations importantes. Par exemple, bge-large-en-v1.5 a une limite maximale de 512 jetons.
- Taille du modèle : les modèles d’incorporation plus grands offrent généralement de meilleures performances, mais nécessitent davantage de ressources de calcul. Trouvez un équilibre entre les performances et l’efficacité, en fonction de votre cas d’usage spécifique et des ressources disponibles.
- Optimisation : si votre application RAG traite un langage spécifique à un domaine (par exemple les acronymes ou la terminologie internes de l’entreprise), envisagez d’optimiser le modèle d’incorporation sur des données spécifiques à ce domaine. Ceci peut aider le modèle à mieux capturer les nuances et la terminologie de votre domaine particulier, et peut souvent aboutir à une amélioration des performances de l’extraction.