Ressources de calcul de notebook
Cet article décrit les options pour les ressources de calcul de notebook. Vous pouvez exécuter un notebook sur un groupement Databricks, un calcul serverless ou, pour les commandes SQL, utiliser un entrepôt SQL, un type de calcul optimisé pour l’analytique SQL.
Calcul serverless pour les notebooks
Le calcul serverless vous permet de vous connecter rapidement votre notebook à des ressources informatiques à la demande.
Pour effectuer un attachement au calcul serverless, cliquez sur le menu déroulant Se connecter dans le notebook, puis sélectionnez Serverless.
Pour plus d’informations, consultez Calcul serverless pour les notebooks.
Attacher un notebook à votre cluster
Pour attacher un notebook à un cluster, vous devez disposer de l’autorisation PEUT JOINDRE À au niveau du cluster.
Important
Tant qu’un notebook est attaché à un cluster, tout utilisateur disposant de l’autorisation PEUT EXÉCUTER sur le Notebook a des autorisations implicites pour accéder au cluster.
Pour attacher un notebook à un cluster, cliquez sur le sélecteur de cluster dans la barre d’outils du notebook et sélectionnez un cluster dans le menu déroulant.
Le menu affiche une sélection de clusters que vous avez utilisés récemment ou qui sont actuellement en cours d’exécution.
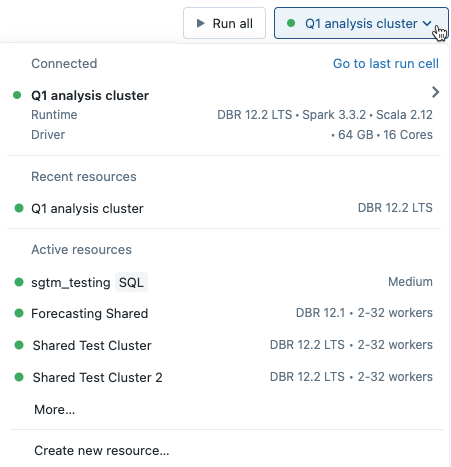
Pour sélectionner parmi tous les clusters disponibles, cliquez sur Plus.... Cliquez sur le nom du cluster pour afficher un menu déroulant, puis sélectionnez un cluster existant.
Vous pouvez également créer un nouveau cluster en sélectionnant Créer une nouvelle ressource... dans le menu déroulant.
Important
Les variables Apache Spark suivantes sont définies pour un notebook attaché.
| Classe | Nom de la variable |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Ne créez pas de SparkSession, SparkContext ou SQLContext. Cela entraînera un comportement incohérent.
Utiliser un notebook avec un entrepôt SQL
Lorsqu’un notebook est attaché à un entrepôt SQL, vous pouvez exécuter des cellules SQL et Markdown. L’exécution d’une cellule dans n’importe quel autre langage (comme Python ou R) génère une erreur. Les cellules SQL exécutées sur un entrepôt SQL apparaissent dans l’historique des requêtes de l’entrepôt SQL. L’utilisateur qui a exécuté une requête peut afficher le profil de requête à partir du notebook en cliquant sur la durée écoulée en bas de la sortie.
L’exécution d’un notebook nécessite un entrepôt SQL professionnel ou Serverless. Vous devez avoir accès à l’espace de travail et à l’entrepôt SQL.
Pour attacher un notebook à un entrepôt SQL, procédez comme suit :
Cliquez sur le sélecteur de calcul dans la barre d’outils du notebook. Le menu déroulant affiche les ressources de calcul en cours d’exécution ou que vous avez utilisées récemment. Les entrepôts SQL sont marqués de l’
 .
.Dans le menu, sélectionnez un entrepôt SQL.
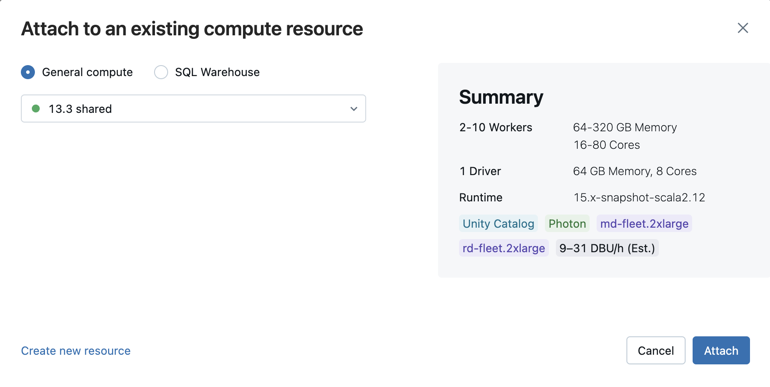
Pour afficher tous les entrepôts SQL disponibles, sélectionnez Plus... dans le menu déroulant. Une boîte de dialogue indique les ressources de calcul disponibles pour le notebook. Sélectionnez Entrepôt SQL, choisissez l’entrepôt que vous souhaitez utiliser, puis cliquez sur Joindre.
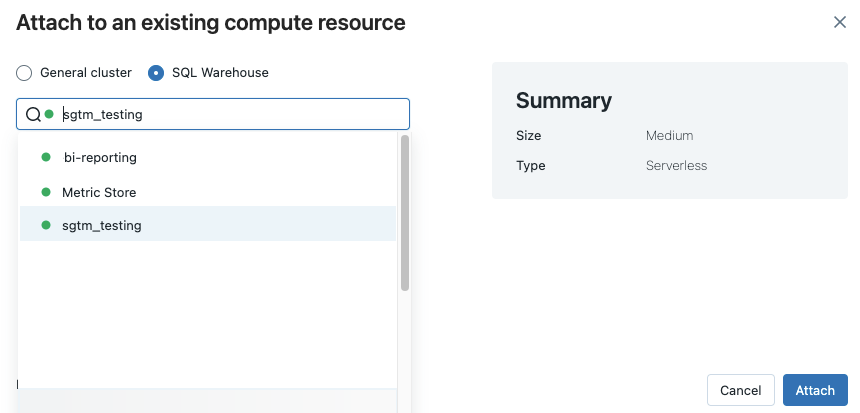
Vous pouvez également sélectionner un entrepôt SQL comme ressource de calcul, pour un notebook SQL, à la création d’un workflow ou d’un travail planifié.
Limitations de SQL Warehouse
Pour plus d’informations, consultez limitations connues des notebooks Databricks.
Détacher un notebook
Pour détacher un notebook d’une ressource de calcul, cliquez sur le sélecteur de calcul dans la barre d’outils du notebook et survolez le cluster ou l’entrepôt SQL attaché dans la liste pour afficher un menu latéral. Depuis le menu latéral, sélectionnez Détacher.
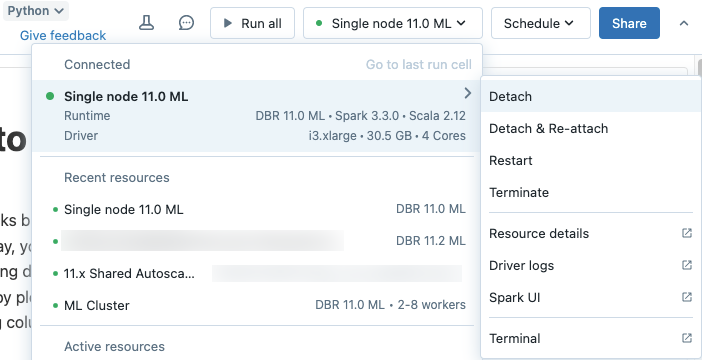
Vous pouvez également détacher des notebooks d’un cluster à l’aide de l’onglet Notebooks de la page de détails du cluster.
Conseil
Azure Databricks vous recommande de détacher des notebooks inutilisés des clusters. Cela libère de l’espace mémoire sur le pilote.