Optimiser Apache Hive à l’aide d’Apache Ambari dans Azure HDInsight
Apache Ambari est une interface web qui permet de gérer et de superviser les clusters HDInsight. Pour une présentation de l’interface utilisateur web d’Ambari, consultez Gérer des clusters HDInsight à l’aide de l’interface utilisateur web d’Apache Ambari.
Les sections suivantes décrivent les options de configuration qui permettent d’optimiser les performances globales d’Apache Hive.
- Pour modifier les paramètres de configuration de Hive, sélectionnez Hive (Hive) dans la barre latérale Services (Services).
- Accédez à l’onglet Configs (Configurations) .
Définir le moteur d’exécution de Hive
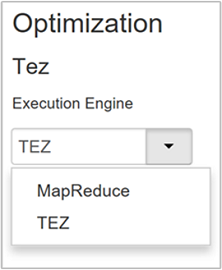
Hive fournit deux moteurs d’exécution : Apache Hadoop MapReduce et Apache TEZ. Tez est plus rapide que MapReduce. Les clusters Linux HDInsight utilisent Tez comme moteur d’exécution par défaut. Pour changer de moteur d’exécution :
Dans l’onglet Configs (Configuration) de Hive, tapez execution engine dans la zone de filtrage.
La valeur par défaut de la propriété Optimization (Optimisation) est Tez.
Paramétrer les mappeurs
Hadoop tente de fractionner (mapper) un fichier en plusieurs fichiers et de traiter ceux-ci en parallèle. Le nombre de mappeurs dépend du nombre de fractionnements. Les deux paramètres de configuration suivants déterminent le nombre de fractionnements pour le moteur d’exécution Tez :
tez.grouping.min-size: limite inférieure de la taille d’un fractionnement groupé, avec une valeur par défaut de 16 Mo (16 777 216 octets).tez.grouping.max-size: limite supérieure de la taille d’un fractionnement groupé, avec une valeur par défaut de 1 Go (1 073 741 824 octets).
En termes de performances, diminuez ces deux paramètres pour améliorer la latence ou augmentez-les pour accroître le débit.
Par exemple, pour définir quatre mappeurs pour 128 Mo de données, réglez les deux paramètres sur 32 Mo (33 554 432 octets).
Pour modifier les limites, accédez à l’onglet Configs (Configurations) du service Tez. Développez le panneau General (Général) et recherchez les paramètres
tez.grouping.max-sizeettez.grouping.min-size.Réglez ces deux paramètres sur 33 554 432 octets (32 Mo).

Ces modifications affectent tous les travaux Tez sur le serveur. Pour obtenir un résultat optimal, choisissez les valeurs appropriées aux paramètres.
Paramétrer les réducteurs
Apache ORC et Snappy offrent tous les deux des performances élevées. Toutefois, Hive peut avoir trop peu de réducteurs par défaut et ainsi générer des goulots d’étranglement.
Par exemple, admettons que vous ayez 50 Go de données en entrée. Ces données au format ORC avec la compression Snappy occupent 1 Go. Hive évalue le nombre de réducteurs nécessaires selon la formule suivante : (nombre d’octets entrés dans les mappeurs/hive.exec.reducers.bytes.per.reducer).
Avec les paramètres par défaut, le résultat pour cet exemple est de quatre réducteurs.
Le paramètre hive.exec.reducers.bytes.per.reducer spécifie le nombre d’octets traités par réducteur. La valeur par défaut est 64 Mo. En abaissant cette valeur, vous renforcez le parallélisme, ce qui peut améliorer les performances. Mais une valeur trop faible peut également générer trop de réducteurs et donc nuire aux performances. Ce paramètre est fonction de vos besoins en données, des paramètres de compression et d’autres facteurs environnementaux.
Pour modifier ce paramètre, accédez à l’onglet Configs (Configurations) de Hive et recherchez le paramètre Data per Reducer (Données par réducteur) sur la page Settings (Paramètres).
Sélectionnez Edit (Modifier) pour remplacer la valeur par 128 Mo (134 217 728 octets), puis appuyez sur Entrée pour enregistrer.
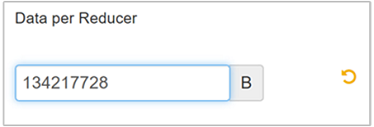
Avec une taille d’entrée de 1 024 Mo et 128 Mo de données par réducteur, on obtient huit réducteurs (1024/128).
Une valeur incorrecte du paramètre Data per Reducer (Données par réducteur) peut produire un grand nombre de réducteurs et nuire aux performances des requêtes. Pour limiter le nombre maximal de réducteurs, réglez
hive.exec.reducers.maxsur une valeur appropriée. La valeur par défaut est 1009.
Activer l’exécution en parallèle
Une requête Hive s’exécute en une ou plusieurs étapes. Si des étapes indépendantes peuvent être exécutées en parallèle, les performances de la requête s’en trouvent accrues.
Pour activer l’exécution de requête en parallèle, accédez à l’onglet Configs (Configuration) de Hive et recherchez la propriété
hive.exec.parallel. La valeur par défaut est false. Remplacez-la par true, puis appuyez sur Entrée pour enregistrer la valeur.Pour limiter le nombre de travaux à exécuter en parallèle, modifiez la propriété
hive.exec.parallel.thread.number. La valeur par défaut est 8.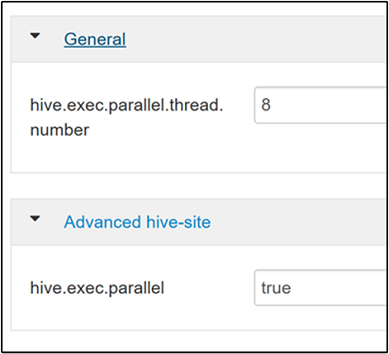
Activer la vectorisation
Hive traite les données ligne par ligne. La vectorisation permet à Hive de traiter les données par blocs de 1 024 lignes plutôt qu’une ligne à la fois. La vectorisation n’est applicable qu’aux fichiers de format ORC.
Pour activer l’exécution vectorisée des requêtes, accédez à l’onglet Configs (Configuration) de Hive et recherchez le paramètre
hive.vectorized.execution.enabled. La valeur par défaut est true pour Hive 0.13.0 ou version ultérieure.Pour activer l’exécution vectorisée du volet réduit de la requête, réglez le paramètre
hive.vectorized.execution.reduce.enabledsur true. La valeur par défaut est false (Faux).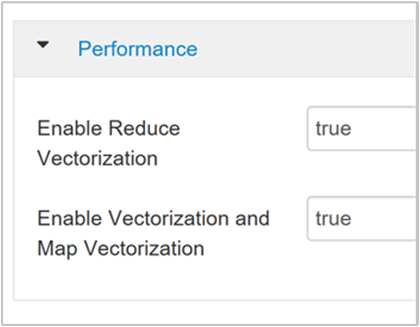
Activer l’optimisation des coûts (CBO)
Par défaut, Hive suit un ensemble de règles pour trouver le plan d’exécution optimal d’une requête. L’optimisation des coûts (CBO) évalue plusieurs plans d’exécution d'une requête. Elle attribue un coût à chaque plan, puis détermine le plan le moins coûteux pour exécuter une requête.
Pour activer la fonction CBO, accédez à Hive>Configurations>Paramètres et recherchez Activer l’optimiseur basé sur les coûts, puis basculez le bouton bascule sur Activé.

Les paramètres de configuration supplémentaires suivants augmentent les performances de traitement des requêtes dans Hive lorsque CBO est activé :
hive.compute.query.using.statsLorsque ce paramètre est réglé sur true, Hive utilise les statistiques stockées dans son metastore pour répondre aux requêtes simples, comme
count(*).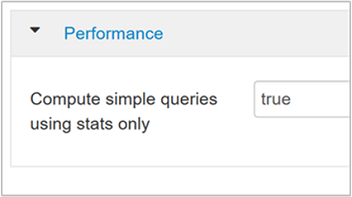
hive.stats.fetch.column.statsDes statistiques de colonne sont créées lorsque CBO est activé. Hive utilise ces statistiques de colonne, qui sont stockées dans son metastore, pour optimiser les requêtes. L’extraction des statistiques pour chaque colonne prend plus de temps lorsque le nombre de colonnes est élevé. Lorsque ce paramètre a la valeur false, il désactive l’extraction des statistiques de colonnes à partir du metastore.
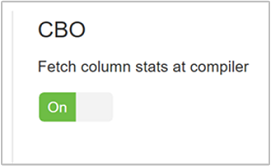
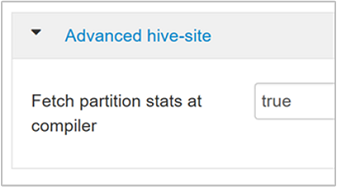
hive.stats.fetch.partition.statsLes statistiques de partition de base, comme le nombre de lignes, la taille des données et la taille du fichier, sont stockées dans le metastore. Si ce paramètre a la valeur true, les statistiques de partition sont extraites du metastore. Lorsque ce paramètre a la valeur false, la taille du fichier est extraite du système de fichiers, et le nombre de lignes est extrait du schéma de ligne.
Pour plus d’informations, consultez le billet de blog sur l’optimisation basée sur les coûts de Hive dans Analytics on Azure Blog.
Activer la compression intermédiaire
Les tâches de mappage créent des fichiers intermédiaires qui sont utilisés par les tâches du réducteur. La compression intermédiaire réduit la taille des fichiers intermédiaires.
En général, les travaux Hadoop subissent des goulots d’étranglement au niveau des E/S. La compression des données peut accélérer les E/S et le transfert global sur le réseau.
Les types de compression disponibles sont :
| Format | Outil | Algorithm | Extension de fichier | Fractionnable ? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
Non |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Oui |
| LZO | Lzop |
LZO | .lzo |
Oui, si indexé |
| Snappy | N/A | Snappy | Snappy | Non |
En règle générale, il est important d’avoir une méthode de compression fractionnable. Sinon, le nombre de mappeurs créés est faible. Si les données d’entrée sont textuelles, bzip2 est la meilleure option. Pour le format ORC, l’option de compression la plus rapide est Snappy.
Pour activer la compression intermédiaire, accédez à l’onglet Configs (Configurations) de Hive, puis réglez le paramètre
hive.exec.compress.intermediatesur true. La valeur par défaut est false (Faux).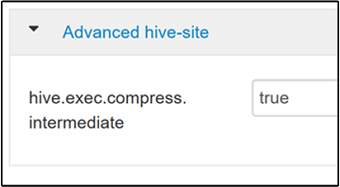
Remarque
Pour compresser les fichiers intermédiaires, choisissez un codec de compression ayant un coût d’UC faible, même s’il n’a pas une sortie de compression élevée.
Pour définir le codec de compression intermédiaire, ajoutez la propriété personnalisée
mapred.map.output.compression.codecau fichierhive-site.xmloumapred-site.xml.Pour ajouter un paramètre personnalisé :
a. Accédez à Hive>Configurations>Avancé>hive-site personnalisé.
b. Sélectionnez Ajouter une propriété… en bas du volet hive-site personnalisé.
c. Dans la fenêtre Add Property (Ajouter une propriété), entrez la clé
mapred.map.output.compression.codecet la valeurorg.apache.hadoop.io.compress.SnappyCodec.d. Sélectionnez Ajouter.
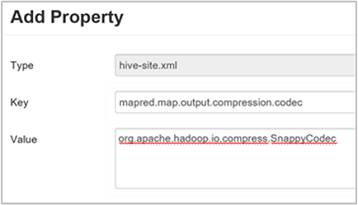
Ce paramètre compresse le fichier intermédiaire avec Snappy. Une fois la propriété ajoutée, elle apparaît dans le volet Custom Hive-site (hive-site personnalisé).
Notes
Cette procédure modifie le fichier
$HADOOP_HOME/conf/hive-site.xml.
Compresser la sortie finale
La sortie finale de Hive peut aussi être compressée.
Pour compresser la sortie finale de Hive, accédez à l’onglet Configs (Configurations) de Hive, puis réglez le paramètre
hive.exec.compress.outputsur true. La valeur par défaut est false.Pour choisir le codec de compression de la sortie, ajoutez la propriété personnalisée
mapred.output.compression.codecdans le volet Custom hive-site (hive-site personnalisé), comme indiqué à l’étape 3 de la section précédente.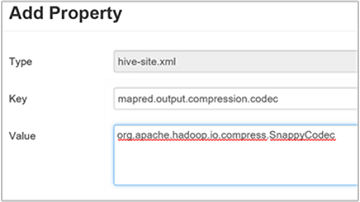
Activer l’exécution spéculative
L’exécution spéculative lance un certain nombre de tâches en double afin de détecter et de bloquer celle qui ralentit les autres, tout en améliorant l’exécution des travaux par l’optimisation des résultats de chaque tâche.
N’activez pas l’exécution spéculative pour les tâches MapReduce à exécution longue qui traitent beaucoup d’entrées.
Pour activer l’exécution spéculative, accédez à l’onglet Configs (Configurations) de Hive, puis réglez le paramètre
hive.mapred.reduce.tasks.speculative.executionsur true. La valeur par défaut est false (Faux).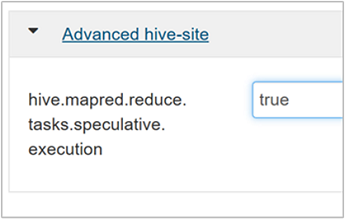
Paramétrer des partitions dynamiques
Hive permet de créer des partitions dynamiques lors de l’insertion d’enregistrements dans une table, sans prédéfinir chaque partition. Il s’agit d’une fonctionnalité puissante. Mais elle peut entraîner la création d’un grand nombre de partitions, et d’un grand nombre de fichiers pour chaque partition.
Pour que Hive crée des partitions dynamiques, la valeur du paramètre
hive.exec.dynamic.partitiondoit être true (valeur par défaut).Sélectionnez le mode de partition dynamique strict (strict) . Dans ce mode, au moins une partition doit être statique. Ce paramètre bloque les requêtes sans filtre de partition dans la clause WHERE. Autrement dit, le mode strict bloque les requêtes qui analysent toutes les partitions. Accédez à l’onglet Configs (Configurations) de Hive, puis réglez
hive.exec.dynamic.partition.modesur strict (strict) . La valeur par défaut est nonstrict (non strict) .Pour limiter le nombre de partitions dynamiques à créer, modifiez le paramètre
hive.exec.max.dynamic.partitions. La valeur par défaut est 5000.Pour limiter le nombre total de partitions dynamiques par nœud, modifiez
hive.exec.max.dynamic.partitions.pernode. La valeur par défaut est 2000.
Activer le mode local
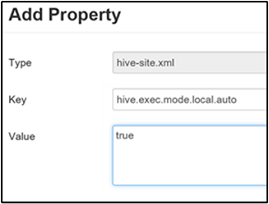
Le mode local permet à Hive d’effectuer toutes les tâches d’un travail sur une seule machine, ou parfois dans un seul processus. Ce paramètre améliore les performances des requêtes si les données d’entrée sont peu nombreuses, Et la charge nécessaire au lancement des tâches des requêtes consomme un pourcentage important de l’exécution globale des requêtes.
Pour activer le mode local, ajoutez le paramètre hive.exec.mode.local.auto au panneau Custom hive-site (hive-site personnalisé), comme indiqué à l’étape 3 de la section Activer la compression intermédiaire.
Génération d’un seul travail MapReduce par MultiGROUP BY
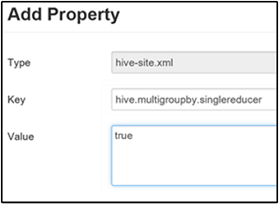
Lorsque cette propriété est réglée sur true, une requête MultiGROUP BY avec des clés group-by communes génère un seul travail MapReduce.
Pour activer ce comportement, ajoutez le paramètre hive.multigroupby.singlereducer dans le volet Custom hive-site (hive-site personnalisé), comme indiqué à l’étape 3 de la section Activer la compression intermédiaire.
Autres optimisations Hive
Les sections suivantes décrivent des autres optimisations Hive que vous pouvez définir.
Joindre des optimisations
Le type de jointure par défaut dans Hive est la jointure de lecture aléatoire. Dans Hive, les mappeurs spéciaux lisent l’entrée et envoient une paire clé/valeur de jointure à un fichier intermédiaire. Hadoop trie et fusionne ces paires dans une étape de lecture aléatoire. Cette étape de lecture aléatoire est coûteuse. La sélection de la jointure appropriée à vos données peut améliorer considérablement les performances.
| Type de jointure | Lorsque le répertoire | Comment | Paramètres Hive | Commentaires |
|---|---|---|---|---|
| Jointure de lecture aléatoire |
|
|
Aucun paramètre Hive important nécessaire | Fonctionne à chaque fois |
| Jointure de mappage |
|
|
hive.auto.convert.join=true |
Rapide, mais limité |
| Compartiment de fusion et tri | Si les deux tables sont :
|
Chaque processus :
|
hive.auto.convert.sortmerge.join=true |
Efficace |
Optimisations du moteur d’exécution
Recommandations supplémentaires pour optimiser le moteur d’exécution Hive :
| Paramètre | Recommandé | Valeur par défaut dans HDInsight |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = plus sûr, plus lent ; false = plus rapide | false |
tez.am.resource.memory.mb |
Limite supérieure de 4 Go pour la plupart | Réglée automatiquement |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |