Effectuer l'apprentissage d'un modèle PyTorch
Cet article explique comment utiliser le composant Effectuer l’apprentissage d’un modèle PyTorch du concepteur Azure Machine Learning pour effectuer l’apprentissage de modèles PyTorch, tels que DenseNet. L’entraînement a lieu une fois que vous avez défini un modèle et ses paramètres. De plus, il nécessite des données étiquetées.
Actuellement, le composant Effectuer l’apprentissage d’un modèle PyTorch prend en charge tant l’apprentissage sur un nœud unique que l’apprentissage distribué.
Utiliser le module Train PyTorch Model
Ajoutez le composant DenseNet ou ResNet à votre brouillon de pipeline dans le concepteur.
Ajoutez le composant Effectuer l’apprentissage d’un modèle PyTorch au pipeline. Ce composant se trouve dans la catégorie Apprentissage du modèle. Développez la section Effectuer l’apprentissage, puis faites glisser le composant Effectuer l’apprentissage d’un modèle PyTorch dans votre pipeline.
Notes
Il est préférable d’exécuter le composant Effectuer l’apprentissage d’un modèle PyTorch sur une cible de calcul de type GPU pour les jeux de données volumineux, à défaut de quoi votre pipeline échouera. Vous pouvez sélectionner le calcul pour un composant spécifique dans le volet droit du composant en définissant Utiliser une autre cible de calcul.
Dans l’entrée gauche, attachez un modèle non entraîné. Attachez le jeu de données d'apprentissage et le jeu de données de validation à l'entrée du milieu et de droite du module Train PyTorch Model.
Pour le modèle qui n'a fait l'objet d'aucun apprentissage, il doit s'agir d'un modèle PyTorch tel que DenseNet. Sinon, une exception « InvalidModelDirectoryError » se produira.
Pour le jeu de données, le jeu de données d’entraînement doit être un répertoire d’images étiquetées. Consultez Convertir en répertoire d’images pour savoir comment obtenir un répertoire d’images étiquetées. En l’absence d’étiquettes, une exception « NotLabeledDatasetError » est levée.
Le jeu de données d’entraînement et le jeu de données de validation ont les mêmes catégories d’étiquette. Sinon une exception InvalidDatasetError est levée.
Pour Epochs (Époques), spécifiez le nombre d’époques à entraîner. L’ensemble du jeu de données est itéré à chaque époque. La valeur par défaut est 5.
Pour Batch size (Taille du lot), spécifiez le nombre d’instances à entraîner dans un lot. La valeur par défaut est 16.
Pour Nombre d'étapes de préparation, spécifiez le nombre d'époques souhaitées pour préparer l'apprentissage, au cas où le taux d'apprentissage initial serait légèrement trop élevé pour entamer la convergence (la valeur par défaut est 0).
Pour Taux d'apprentissage, spécifiez la valeur du taux d'apprentissage (la valeur par défaut est 0,001). Le taux d'apprentissage détermine la taille de l'étape utilisée dans l'optimiseur, par exemple la SGD (descente du gradient stochastique) chaque fois que le modèle est testé et corrigé.
En réduisant ce taux, vous testez le modèle plus souvent, avec le risque de rester bloqué dans un plateau local. En l'augmentant, vous pouvez converger plus rapidement, au risque de dépasser les minima réels.
Notes
Si la perte d'apprentissage devient NAN au cours de l'apprentissage, ce qui peut être dû à un taux d'apprentissage trop élevé, une réduction du taux d'apprentissage peut se révéler utile. Dans le cadre d'un apprentissage distribué, pour stabiliser la descente du gradient, le taux d'apprentissage réel est calculé par
lr * torch.distributed.get_world_size()car la taille de lot du groupe de processus correspond à la taille universelle multipliée par celle du processus unique. Une décroissance polynomiale du taux d'apprentissage est appliquée, et celle-ci peut permettre d'obtenir un modèle plus performant.Pour Random seed (Valeur initiale aléatoire), tapez éventuellement une valeur entière à utiliser en tant que valeur initiale. L’utilisation d’un seed est recommandée si vous souhaitez garantir la reproductibilité de l’expérience d’un travail à l’autre.
Pour Patience, spécifiez le nombre d’époques où l’entraînement doit être arrêté de manière anticipée si la perte de validation ne diminue pas de manière consécutive. 3 par défaut.
Pour Fréquence d'impression, spécifiez la fréquence d'impression des journaux d'apprentissage sur les itérations de chaque époque (la valeur par défaut est 10).
Envoyez le pipeline. Si votre jeu de données a une taille supérieure, cela prendra du temps et le calcul GPU est recommandé.
Entraînement distribué
Dans la formation distribuée, la charge de travail visant à effectuer l’apprentissage d’un modèle est fractionnée et partagée entre plusieurs mini-processeurs, appelés nœuds Worker. Ces nœuds Worker fonctionnent en parallèle pour accélérer la formation du modèle. Actuellement, le concepteur prend en charge l’apprentissage distribué pour le composant Effectuer l’apprentissage d’un modèle PyTorch.
Durée d’apprentissage
L'apprentissage distribué permet au module Train PyTorch Model d'effectuer l'apprentissage d'un jeu de données volumineux comme ImageNet (1 000 classes, 1,2 million d'images) en quelques heures à peine. Le tableau suivant indique le temps d'apprentissage et les performances lors de l'apprentissage de 50 époques de Resnet50 sur ImageNet en partant de zéro et sur la base de différents appareils.
| Appareils | Durée d'apprentissage | Débit d'apprentissage | Précision de la validation Top-1 | Précision de la validation Top-5 |
|---|---|---|---|---|
| 16 GPU V100 | 6 heures 22 minutes | Environ 3 200 images/s | 68,83 % | 88,84 % |
| 8 GPU V100 | 12 heures 21 minutes | Environ 1 670 images/s | 68,84 % | 88,74 % |
Cliquez sur l’onglet « Métriques » de ce composant et consultez les graphiques de métriques d’apprentissage, tels que « Images par seconde » et « Précision Top 1 ».

Activer l'apprentissage distribué
Pour activer l’apprentissage distribué pour le composant Effectuer l’apprentissage d’un modèle PyTorch, vous pouvez définir les Paramètres du travail dans le volet droit du composant. Seul le Cluster de calcul AML est pris en charge pour l'apprentissage distribué.
Notes
Plusieurs GPU sont nécessaires pour activer l’apprentissage distribué car le backend NCCL qu’utilise le composant Effectuer l’apprentissage d’un modèle PyTorch a besoin de Cuda.
Sélectionnez le composant et ouvrez le volet droit. Développez la section Paramètres du travail.
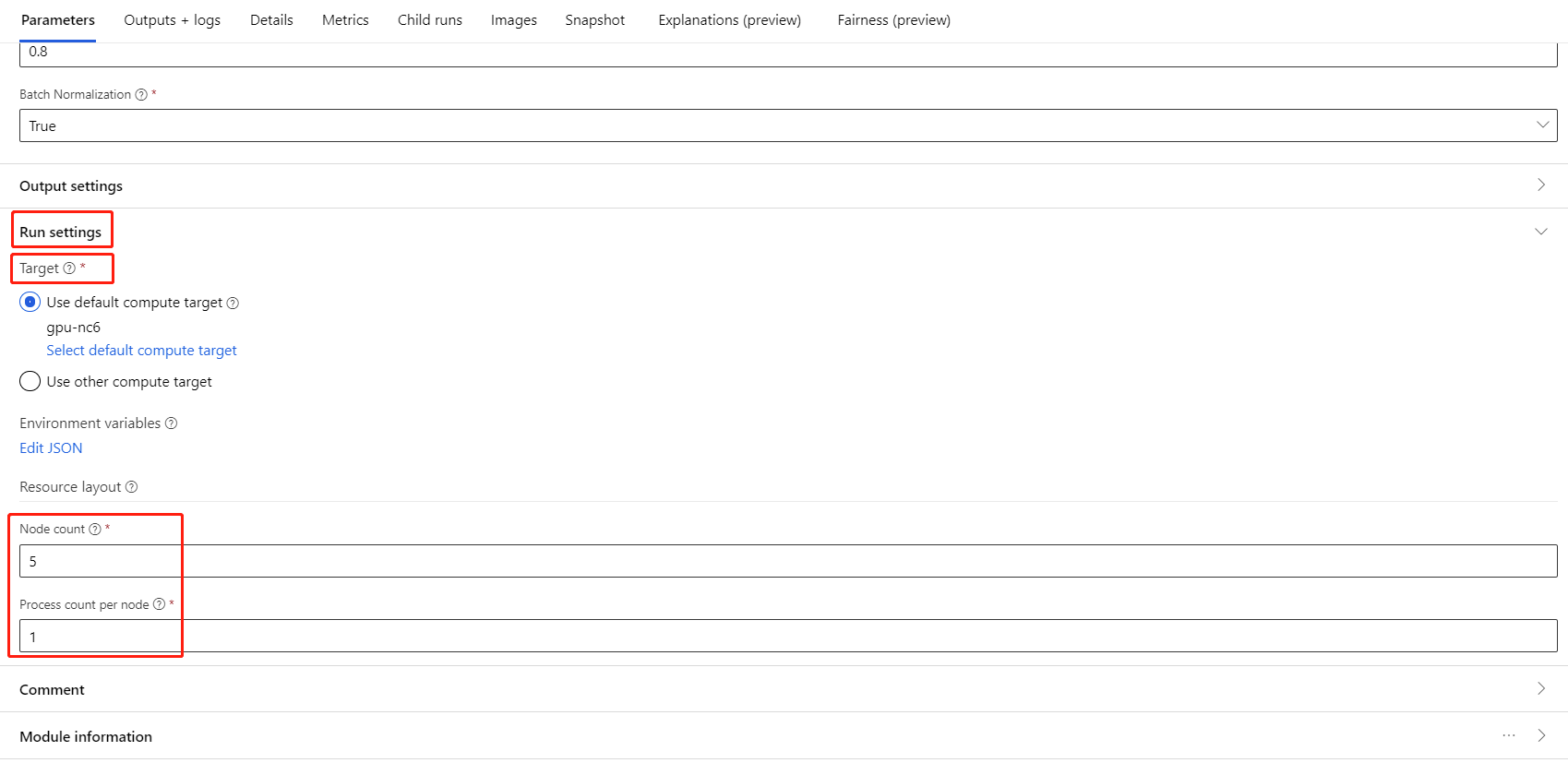
Vérifiez que vous avez sélectionné le calcul AML pour la cible de calcul.
Dans la section Disposition des ressources, vous devez définir les valeurs suivantes :
Nombre de nœuds : nombre de nœuds dans la cible de calcul utilisée pour l'apprentissage. Il doit être inférieur ou égal au Nombre maximal de nœuds de votre cluster de calcul. Par défaut, il s'agit de 1, ce qui correspond à un travail à nœud unique.
Nombre de processus par nœud : nombre de processus déclenchés par nœud. Il doit être inférieur ou égal à l'Unité de traitement de votre calcul. Par défaut, il s'agit de 1, ce qui correspond à un travail à processus unique.
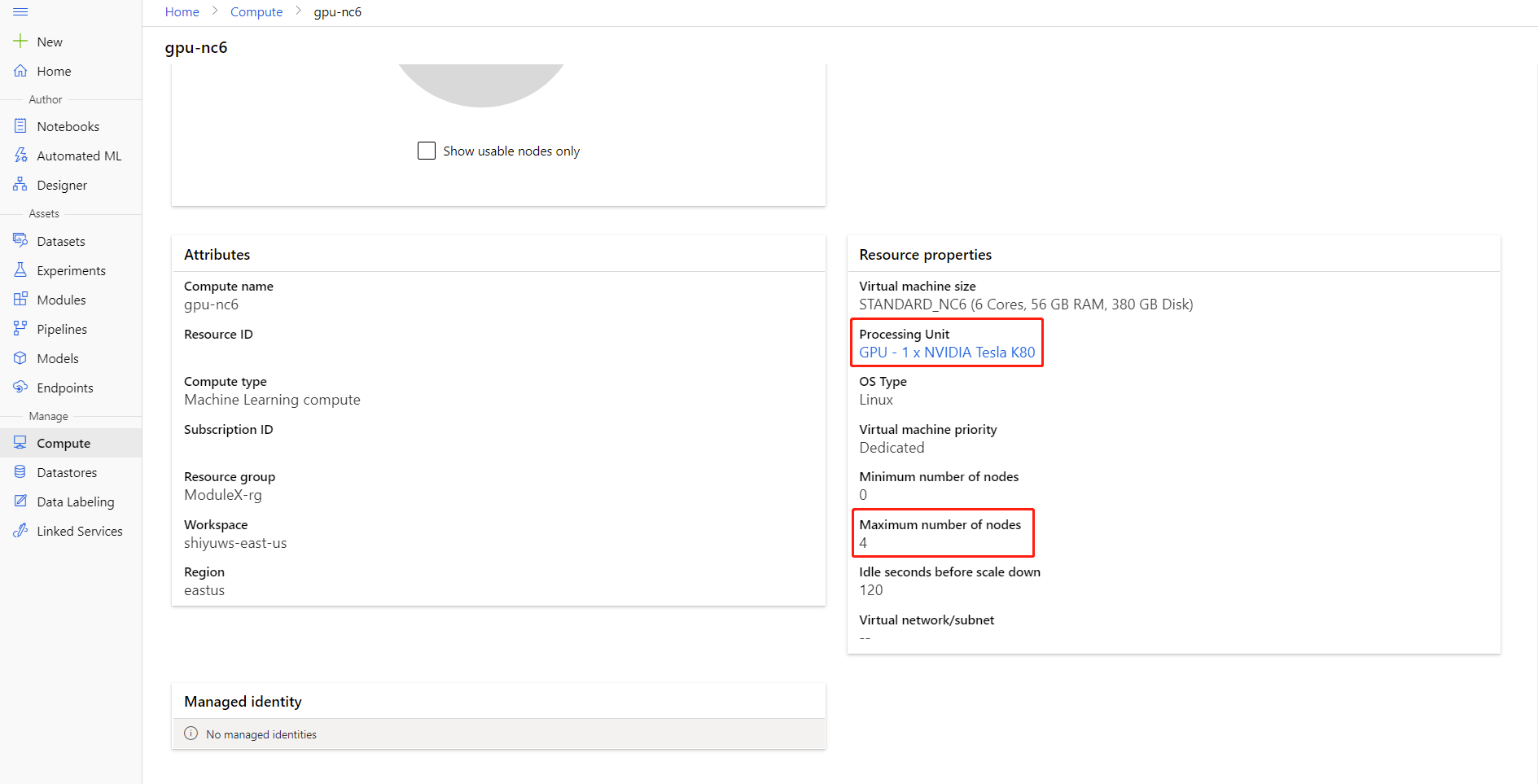
Pour connaître le Nombre maximal de nœuds et l'Unité de traitement de votre calcul, cliquez sur le nom du calcul sur la page des détails du calcul.


Pour en savoir plus sur l'apprentissage distribué dans Azure Machine Learning, cliquez ici.
Résolution des problèmes liés à l'apprentissage distribué
Si vous activez l’apprentissage distribué pour ce composant, des journaux de pilote seront générés pour chaque processus. 70_driver_log_0 est le processus principal. Vous pouvez consulter les journaux de pilote pour connaître les détails des erreurs de chaque processus sous l'onglet Sorties et journaux du volet droit.

Si l’apprentissage distribué activé pour le composant échoue sans aucun journal 70_driver, vous pouvez consulter les détails de l’erreur dans 70_mpi_log.
L'exemple suivant illustre une erreur courante : le Nombre de processus par nœud est supérieur à l'Unité de traitement du calcul.

Pour plus d’informations sur la résolution des problèmes liés aux composants, consultez cet article.
Résultats
Une fois le travail de pipeline terminé, si vous souhaitez utiliser le modèle à des fins de scoring, connectez le module Effectuer l’apprentissage d’un modèle PyTorch au module Scorer un modèle d’image pour prédire les valeurs des nouveaux exemples d’entrée.
Notes techniques
Entrées attendues
| Nom | Type | Description |
|---|---|---|
| Untrained model (Modèle non entraîné) | UntrainedModelDirectory | Modèle sans apprentissage, nécessite PyTorch |
| Jeu de données d’entraînement | ImageDirectory | Jeu de données d’entraînement |
| Jeu de données de validation | ImageDirectory | Jeu de données de validation pour l’évaluation de chaque époque |
Paramètres de composant
| Nom | Plage | Type | Default | Description |
|---|---|---|---|---|
| Époques | >0 | Integer | 5 | Sélectionnez la colonne qui contient le libellé ou la colonne de résultat |
| Taille du lot | >0 | Integer | 16 | Nombre d’instances à entraîner dans un lot |
| Nombre d'étapes de préparation | >=0 | Integer | 0 | Nombre d'époques nécessaires à la préparation de l'apprentissage |
| Taux d’apprentissage | >=double.Epsilon | Float | 0.1 | Taux d’apprentissage initial pour l’optimiseur de descente de gradient stochastique. |
| Valeur initiale aléatoire | Quelconque | Integer | 1 | Valeur initiale pour le générateur de nombres aléatoires utilisé par le modèle. |
| Patience | >0 | Integer | 3 | Nombre d’époques où l’entraînement doit être arrêté de manière anticipée |
| Fréquence d'impression | >0 | Integer | 10 | Fréquence d'impression des journaux d'apprentissage sur les itérations de chaque époque |
Sorties
| Nom | Type | Description |
|---|---|---|
| Modèle entraîné | ModelDirectory | Modèle entraîné |
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.