Déployer un flux en tant que point de terminaison en ligne managé pour l’inférence en temps réel
Après avoir généré un flux et l’avoir testé correctement, vous voudrez probablement le déployer en tant que point de terminaison afin de pouvoir appeler le point de terminaison pour l’inférence en temps réel.
Dans cet article, vous allez apprendre à déployer un flux en tant que point de terminaison en ligne managé pour l’inférence en temps réel. Les étapes à suivre sont les suivantes :
- Tester votre flux et le préparer pour le déploiement
- Créer un déploiement en ligne
- Accorder des autorisations au point de terminaison
- Tester le point de terminaison
- Consommer le point de terminaison
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. La préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail en production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Prérequis
Découvrez comment générer et tester un flux dans le flux d’invite.
Connaître les bases des points de terminaison en ligne managés. Les points de terminaison en ligne managés fonctionnent de manière scalable et complètement managée avec des machines équipées de processeurs et de GPU puissants dans Azure, lequel vous libère des contraintes de configuration et de gestion de l’infrastructure de déploiement sous-jacente. Pour plus d’informations sur les points de terminaison en ligne managés, consultez Points de terminaison et déploiements en ligne pour l’inférence en temps réel.
Les contrôles d’accès en fonction du rôle Azure (Azure RBAC) sont utilisés pour accorder l’accès aux opérations dans Azure Machine Learning. Pour pouvoir déployer un point de terminaison dans le flux d’invite, votre compte d’utilisateur doit se voir attribuer le rôle Scientifique des données AzureML ou un rôle avec plus de privilèges pour l’espace de travail Azure Machine Learning.
Disposer d’une compréhension de base des identités managées. En savoir plus sur les Identités managées.
Remarque
Le point de terminaison en ligne managé prend uniquement en charge le réseau virtuel managé. Si votre espace de travail se trouve dans un réseau virtuel personnalisé, vous devez essayer d’autres options de déploiement, comme le déploiement sur un point de terminaison en ligne Kubernetes à l’aide de l’interface CLI/du kit de développement logiciel (SDK), ou déployer sur d’autres plateformes comme Docker.
Générer le flux et le préparer pour le déploiement
Si vous avez déjà terminé le tutoriel de démarrage, vous avez déjà testé le flux correctement en soumettant une exécution par lots et en évaluant les résultats.
Si vous n’avez pas terminé le tutoriel, vous devez créer un flux. Il est recommandé de tester correctement le flux avec une exécution et une évaluation par lots avant le déploiement.
Nous allons utiliser l’exemple de classification Web de flux comme exemple pour montrer comment déployer le flux. Cet exemple de flux est un flux standard. Le déploiement de flux de conversation est similaire. Le flux d’évaluation ne prend pas en charge le déploiement.
Définition de l’environnement utilisé par le déploiement
Lorsque vous déployez un flux d’invite sur un point de terminaison en ligne managé dans l’interface utilisateur, le déploiement utilise par défaut l’environnement créé à partir de la dernière image du flux d’invite et les dépendances spécifiées dans le requirements.txt du flux. Vous pouvez spécifier des packages supplémentaires dont vous aviez besoin dans requirements.txt. Vous pouvez trouver requirements.txt dans le dossier racine de votre dossier de flux.

Remarque
Si vous utilisez des flux privés dans Azure DevOps, vous devez d’abord générer l’image avec des flux privés et sélectionner un environnement personnalisé à déployer dans l’interface utilisateur.
Créer un déploiement en ligne
Maintenant que vous avez créé un flux et que vous l’avez testé correctement, il est temps de créer votre point de terminaison en ligne pour l’inférence en temps réel.
Le flux d’invite vous permet de déployer des points de terminaison à partir d’un flux ou d’une exécution par lots. Tester le flux avant le déploiement est une bonne pratique que nous recommandons.
Dans la page de création de flux ou la page de détails de l’exécution, sélectionnez Déployer.
Page de création de flux :

Page des détails de l’exécution :

Un Assistant vous permettant de configurer le point de terminaison se produit et inclut les étapes suivantes.
Paramètres de base

Cette étape vous permet de configurer les paramètres de base du déploiement.
| Propriété | Description |
|---|---|
| Point de terminaison | Vous pouvez choisir de déployer un nouveau point de terminaison ou de mettre à jour un point de terminaison existant. Si vous sélectionnez Nouveau, vous devez spécifier le nom du point de terminaison. |
| Nom du déploiement | - Dans le même point de terminaison, le nom de déploiement doit être unique. - Si vous sélectionnez un point de terminaison existant et que vous entrez un nom de déploiement existant, ce déploiement est remplacé par les nouvelles configurations. |
| Machine virtuelle | Taille de machine virtuelle à utiliser pour le déploiement. Pour obtenir la liste des tailles prises en charge, consultez la liste des références SKU des points de terminaison en ligne managés. |
| Nombre d’instances | Nombre d’instances à utiliser pour le déploiement. Spécifiez la valeur sur la charge de travail que vous attendez. Pour une haute disponibilité, nous vous recommandons de définir la valeur sur au moins 3. Nous réservons 20 % en plus pour effectuer des mises à niveau. Pour plus d’informations, consultez les quotas de points de terminaison en ligne managés |
| Collecte de données d’inférence | Si vous activez cette option, les entrées et sorties de flux seront collectées automatiquement dans une ressource de données Azure Machine Learning et pourront être utilisées pour la supervision ultérieure. Pour en savoir plus, consultez Supervision des applications d’IA générative. |
Une fois que vous avez terminé avec les paramètres de base, vous pouvez directement passer à Vérifier + créer pour finir la création, ou vous pouvez sélectionner Suivant pour configurer les Paramètres avancés.
Paramètres avancés - Point de terminaison
Vous pouvez spécifier les paramètres suivants pour le point de terminaison.

Type d'authentification
Méthode d’authentification du point de terminaison. L’authentification par clé fournit une clé primaire et secondaire qui n’expire pas. L’authentification basée sur les jetons Azure Machine Learning fournit un jeton qui s’actualise régulièrement automatiquement. Pour plus d’informations sur l’authentification, consultez S’authentifier auprès d’un point de terminaison en ligne.
Type d'identité
Le point de terminaison doit accéder aux ressources Azure telles que Azure Container Registry ou les connexions de votre espace de travail pour l’inférence. Vous pouvez autoriser l’autorisation de point de terminaison à accéder aux ressources Azure en accordant l’autorisation à son identité managée.
L’identité attribuée par le système est créée automatiquement après la création de votre point de terminaison, tandis que l’identité attribuée par l’utilisateur est créée par l’utilisateur. En savoir plus sur les Identités managées.
Attribué par le système
Vous remarquerez qu’il existe une option pour Appliquer l’accès aux secrets de connexion (préversion). Si votre flux utilise des connexions, le point de terminaison doit y accéder pour procéder à l’inférence. L’option est activée par défaut et le point de terminaison reçoit le rôle Lecteur de secrets de connexion de l’espace de travail Azure Machine Learning pour accéder automatiquement aux connexions si vous disposez d’une autorisation de lecteur de secrets de connexion. Si vous désactivez cette option, vous devez vous-même accorder ce rôle à l’identité affectée par le système manuellement ou demander de l’aide à votre administrateur. En savoir plus sur l’octroi d’autorisations à l’identité du point de terminaison.
Affectée par l’utilisateur
Lorsque vous créez le déploiement, Azure essaie de extraire (pull) l’image conteneur de l’utilisateur du registre ACR (Azure Container Registry) de l’espace de travail, puis monte les artefacts de modèle et de code utilisateur dans le conteneur utilisateur à partir du compte de stockage de l’espace de travail.
Si vous avez créé le point de terminaison associé avec une identité affectée par l’utilisateur, celle-ci doit recevoir les rôles suivants avant la création du déploiement, sinon la création du déploiement échoue.
| Étendue | Rôle | Pourquoi il est nécessaire |
|---|---|---|
| Espace de travail Azure Machine Learning | Rôle Lecteur de secrets de connexion de l’espace de travail Azure Machine Learning OU un rôle personnalisé avec « Microsoft.MachineLearningServices/workspaces/connections/listsecrets/action » | Obtenir des connexions à l’espace de travail |
| Registre de conteneurs d’espace de travail | ACR pull | Tirage (pull) d’image de conteneur |
| Stockage par défaut de l’espace de travail | Lecteur des données blob du stockage | Charger le modèle à partir du stockage |
| (Facultatif) Espace de travail Azure Machine Learning | Enregistreur de métriques d’espace de travail | Après avoir déployé le point de terminaison, si vous souhaitez surveiller les métriques liées au point de terminaison telles que l’utilisation du processeur/GPU/disque/mémoire, vous devez accorder cette autorisation à l’identité. |
Consultez les instructions détaillées sur la façon d’accorder des autorisations à l’identité du point de terminaison dans Accorder des autorisations au point de terminaison.
Important
Si votre flux utilise des connexions d’authentification basées sur Microsoft Entra ID, que vous utilisiez une identité attribuée par le système ou par l’utilisateur, vous devez toujours accorder à l’identité managée les rôles appropriés sur les ressources correspondantes afin qu’elle puisse effectuer des appels d’API vers cette ressource. Par exemple, si votre connexion Azure OpenAI utilise une authentification basée sur Microsoft Entra ID, vous devez accorder à l’identité managée de votre point de terminaison le rôle Utilisateur OpenAI Cognitive Services ou Contributeur OpenAI Cognitive Services sur les ressources Azure OpenAI correspondantes.
Paramètres avancés - Déploiement
Dans cette étape, à l’exception des étiquettes, vous pouvez également spécifier l’environnement utilisé par le déploiement.

Utiliser l’environnement de la définition du flux actuel
Par défaut, le déploiement utilise l’environnement créé en fonction de l’image de base spécifiée dans le flow.dag.yaml et les dépendances spécifiées dans le requirements.txt.
Vous pouvez spécifier l’image de base dans le
flow.dag.yamlen sélectionnantRaw file modedu flux. Si aucune image n’est spécifiée, l’image de base par défaut est l’image de base de flux d’invite la plus récente.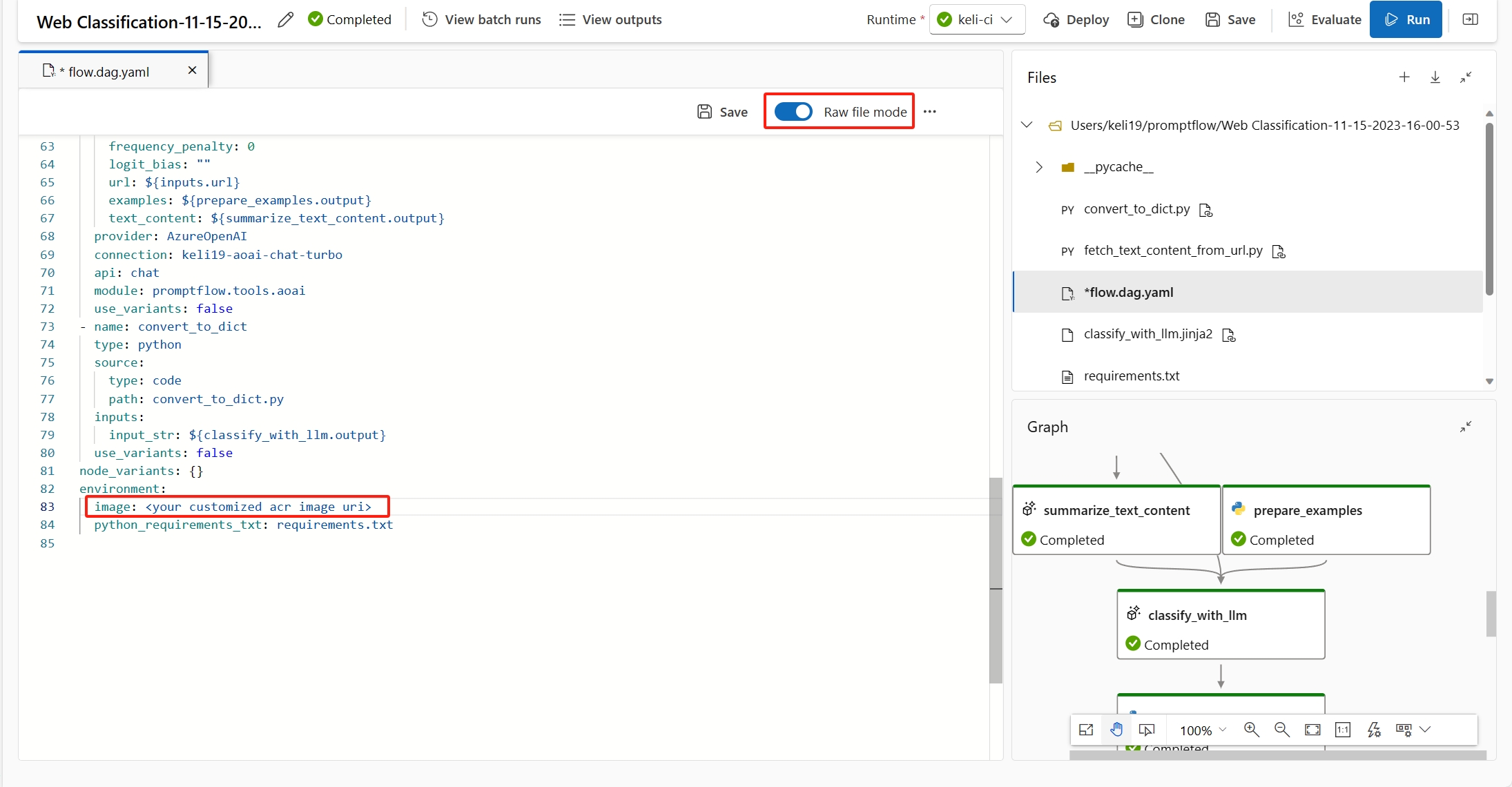
Vous pouvez trouver
requirements.txtdans le dossier racine de votre dossier de flux et y ajouter des dépendances.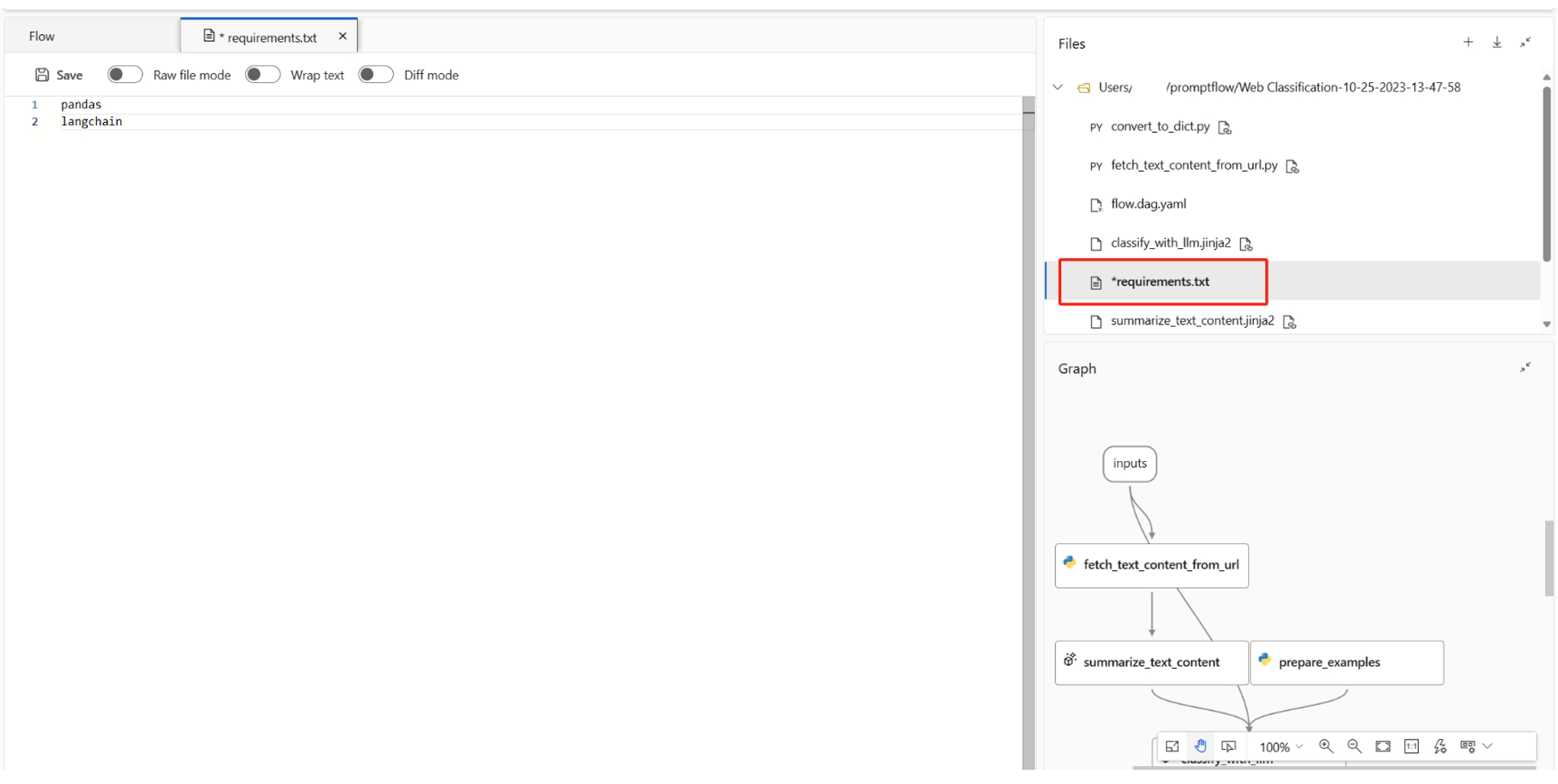

Utiliser un environnement personnalisé
Vous pouvez également créer un environnement personnalisé et l’utiliser pour le déploiement.
Remarque
Votre environnement personnalisé doit répondre aux exigences suivantes :
- l’image Docker doit être créée en fonction de l’image de base de flux d’invite,
mcr.microsoft.com/azureml/promptflow/promptflow-runtime-stable:<newest_version>. Vous trouverez ici la dernière version. - la définition de l’environnement doit inclure le
inference_config.
Voici un exemple de définition d’environnement personnalisée.
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
Activer le suivi en déclenchant les diagnostics Application Insights (préversion)
Si vous activez cette option, les données de suivi et les métriques du système pendant l’inférence (comme le nombre de jetons, la latence du flux, la demande de flux, etc.) seront collectées dans Application Insights lié à l’espace de travail. Pour plus d’informations, consultez les Données et métriques de suivi de la mise à disposition du flux d’invite.
Si vous souhaitez spécifier une autre Application Insights que l’espace de travail lié, vous pouvez le configurer par l’interface CLI.
Paramètres avancés – Sorties et connexions
Dans cette étape, vous pouvez afficher toutes les sorties de flux et spécifier celles qui seront incluses dans la réponse du point de terminaison que vous déployez. Par défaut, toutes les sorties de flux sont sélectionnées.
Vous pouvez également spécifier les connexions utilisées par le point de terminaison lorsque celui-ci procède à une inférence. Par défaut, elles sont héritées du flux.
Une fois que vous avez configuré et passé en revue toutes les étapes ci-dessus, vous pouvez sélectionner Vérifier + créer pour terminer la création.
Remarque
Attendez-vous à ce que la création du point de terminaison prenne plus de 15 minutes, car celle-ci présente plusieurs phases, notamment la création d’un point de terminaison, l’inscription du modèle, la création d’un déploiement, etc.
Vous pouvez voir la progression de la création du déploiement via la notification qui commence par Déploiement du flux d’invite.

Accorder des autorisations au point de terminaison
Important
L’octroi d’autorisations (ajout d’une attribution de rôle) est uniquement activé pour le propriétaire des ressources Azure spécifiques. Vous risquez de devoir demander de l’aide à votre administrateur informatique. Il est recommandé d’accorder des rôles à l’identité affectée par l’utilisateur avant la création du déploiement. La mise en application de l’autorisation accordée risque de prendre plus de 15 minutes.
Vous pouvez accorder toutes les autorisations dans l’interface utilisateur du portail Azure en suivant ces étapes.
Dans le portail Azure, accédez à la page de présentation de l’espace de travail Azure Machine Learning.
Sélectionnez Contrôle d’accès, et sélectionnez Ajouter une attribution de rôle.
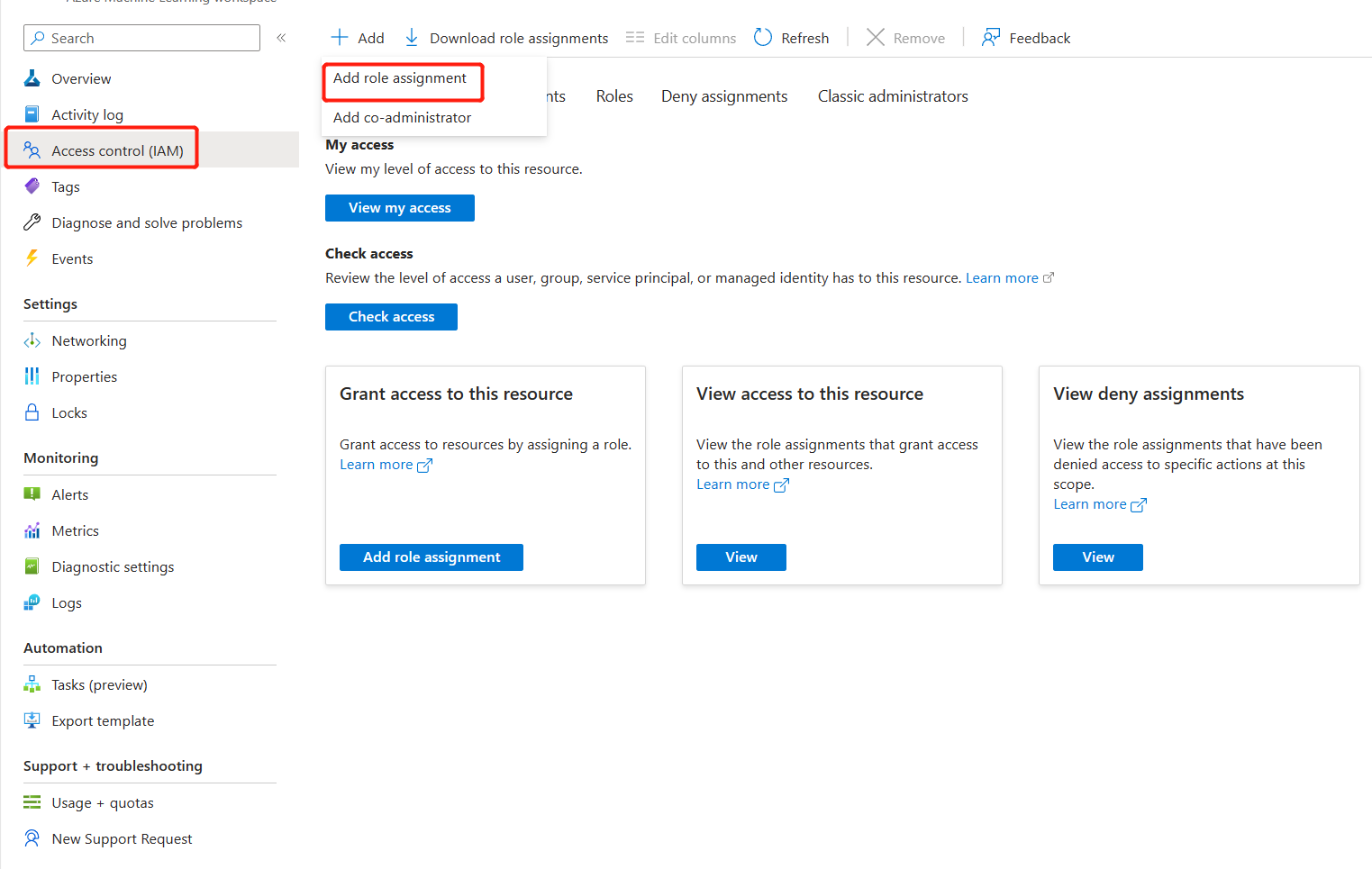
Sélectionnez Lecteur de secrets de connexion de l’espace de travail Azure Machine Learning, puis Suivant.
Remarque
Lecteur de secrets de connexion de l’espace de travail Azure Machine Learning est un rôle intégré qui a l’autorisation d’obtenir les connexions de l’espace de travail.
Si vous souhaitez utiliser un rôle personnalisé, assurez-vous que le rôle personnalisé dispose de l’autorisation « Microsoft.MachineLearningServices/workspaces/connections/listsecrets/action ». Découvrez la création de rôles personnalisés.
Sélectionnez Identité managée, puis les membres.
Pour identité affectée par le système, sélectionnez Point de terminaison en ligne Machine Learning sous Identité managée affectée par le système, puis recherchez par nom de point de terminaison.
Pour Identité affectée par l’utilisateur, sélectionnez Identité managée affectée par l’utilisateur, puis recherchez par nom d’identité.
Pour l’identité affectée par l’utilisateur, vous devez accorder des autorisations au registre de conteneurs et au compte de stockage de l’espace de travail. Vous trouverez le registre de conteneurs et le compte de stockage dans la page de vue d’ensemble de l’espace de travail dans le portail Azure.
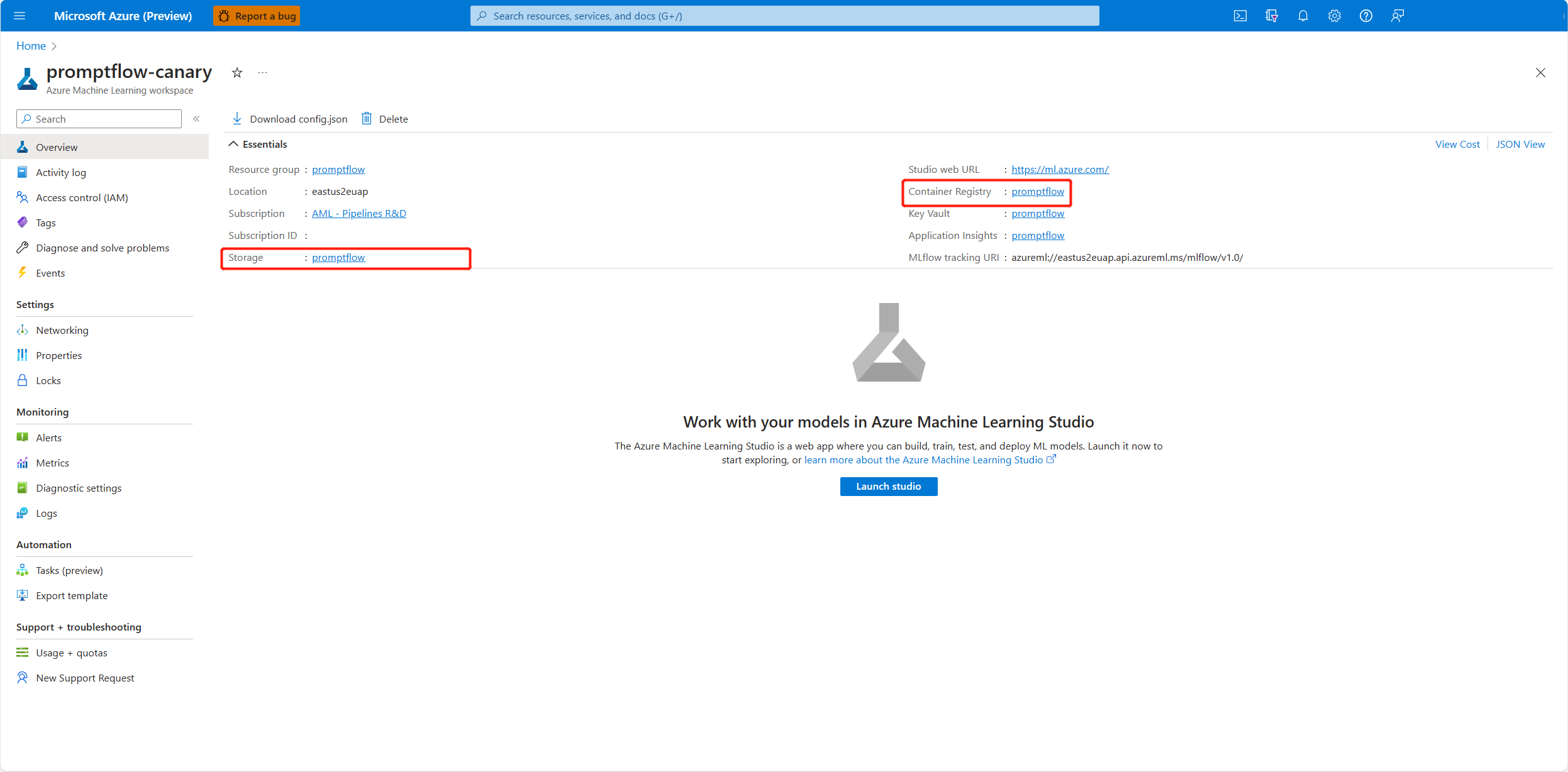
Accédez à la page de vue d’ensemble du registre de conteneurs de l’espace de travail, sélectionnez Contrôle d’accès et Ajouter une attribution de rôle, puis attribuez ACR pull |Extraire l’image conteneur à l’identité du point de terminaison.
Accédez à la page de vue d’ensemble du stockage par défaut de l’espace de travail, sélectionnez Contrôle d’accès et Ajouter une attribution de rôle, puis attribuez Lecteur des données Blob du stockage à l’identité du point de terminaison.
(facultatif) Pour l’identité affectée par l’utilisateur, si vous souhaitez surveiller les métriques liées au point de terminaison, telles que l’utilisation du processeur/GPU/disque/mémoire, vous devez également accorder le rôle Auteur de métriques d’espace de travail de l’espace de travail à l’identité.


Vérifiez l’état du point de terminaison
Des notifications seront envoyées une fois que vous aurez terminé l’Assistant de déploiement. Une fois le point de terminaison et le déploiement créés, vous pouvez sélectionner Déployer les détails dans la page de détails de la notification sur le point de terminaison.
Vous pouvez également accéder directement à la page Points de terminaison dans le studio et vérifier l’état du point de terminaison que vous avez déployé.

Tester le point de terminaison avec des exemples de données
Dans la page des détails du point de terminaison, basculez vers l’onglet Test.
Vous pouvez entrer les valeurs et sélectionner le bouton Tester.
Le résultat de test s’affiche comme suit :

Tester le point de terminaison déployé à partir d’un flux de conversation
Pour les points de terminaison déployés à partir d’un flux de conversation, vous pouvez le tester dans une fenêtre de conversation immersive.

chat_input a été défini pendant le développement du flux de conversation. Vous pouvez saisir le message chat_input dans la zone de saisie. Le panneau Entrées sur le côté droit vous permet de spécifier les valeurs pour d’autres entrées en plus de chat_input. En savoir plus sur le développement d’un flux de conversation.
Consommer le point de terminaison
Dans la page détails du point de terminaison, basculez vers l’onglet Consommer. Vous trouverez le point de terminaison REST et la clé/jeton pour consommer votre point de terminaison. Il existe également un exemple de code vous permettant d’utiliser le point de terminaison dans différents langages.
Notez que vous devez remplir les valeurs de données en fonction de vos entrées de flux. Prenez l’exemple de flux utilisé dans cet article de classification web, par exemple, vous devez spécifier data = {"url": "<the_url_to_be_classified>"} et remplir la clé ou le jeton dans l’exemple de code de consommation.

Surveiller les points de terminaison
Afficher les métriques courantes des points de terminaison en ligne managés avec Azure Monitor (facultatif)
Vous pouvez afficher diverses métriques (nombres de demandes, latence des demandes, octets réseau, utilisation de processeur/GPU/disque/mémoire, etc.) pour un point de terminaison en ligne et ses déploiements en suivant les liens de la page Détails du point de terminaison dans studio. En suivant ces liens, vous accédez à la page des métriques exactes dans le Portail Azure pour le point de terminaison ou le déploiement.
Notes
Si vous spécifiez l’identité affectée par l’utilisateur pour votre point de terminaison, vérifiez que vous avez attribué des métriques d’espace de travail de l’espace de travail Azure Machine Learning à votre identité affectée par l’utilisateur. Sinon, le point de terminaison ne sera pas en mesure de journaliser les métriques.

Pour plus d’informations sur l’affichage des métriques de point de terminaison en ligne, consultez Superviser les points de terminaison en ligne.
Afficher des métriques spécifiques aux points de terminaison de flux d’invite et des données de suivi (facultatif)
Si vous activez les Diagnostics Application Insights dans l’Assistant de déploiement de l’interface utilisateur, les données de suivi et les métriques spécifiques au flux d’invite sont collectées dans l’espace de travail lié à Application Insights. Consultez les détails sur l’activation du suivi pour votre déploiement.
Résoudre les problèmes de points de terminaison déployés à partir d’un flux d’invite
Absence d’autorisation pour effectuer l’action « Microsoft.MachineLearningService/workspaces/datastores/read »
Si votre flux contient l’outil Recherche d’index, après le déploiement du flux, il faut que le point de terminaison puisse accéder au magasin de données de l’espace de travail pour lire le fichier yaml MLIndex ou le dossier FAISS contenant des blocs et des incorporations. Par conséquent, vous devez accorder manuellement l’autorisation d’identité de point de terminaison.
Vous pouvez accorder l’autorisation d’identité de point de terminaison AzureML Data Scientist sur l’étendue de l’espace de travail ou définir un rôle personnalisé qui contient l’action « MachineLearningService/workspace/workspace/datastore/reader ».
Erreur MissingDriverProgram
Si vous déployez votre flux avec un environnement personnalisé et rencontrez l’erreur suivante, cela peut être dû au fait que vous n’avez pas spécifié le inference_config dans la définition de votre environnement personnalisé.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Il existe 2 façons de corriger cette erreur.
(Recommandé) Vous pouvez trouver l’URI d’image conteneur sur la page de détails de votre environnement personnalisé et le définir comme image de base de flux dans le fichier flow.dag.yaml. Lorsque vous déployez le flux dans l’interface utilisateur, vous sélectionnez simplement Utiliser l’environnement de la définition du flux actuel, et le service back-end crée l’environnement personnalisé basé sur cette image de base et
requirement.txtpour votre déploiement. En savoir plus sur l’environnement spécifié dans la définition de flux.
Vous pouvez corriger cette erreur en ajoutant
inference_configdans votre définition d’environnement personnalisée. En savoir plus sur l’utilisation d’un environnement personnalisé.Voici un exemple de définition d’environnement personnalisée.

$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
La réponse du modèle prend trop de temps
Vous remarquerez probablement que le déploiement met parfois trop de temps à répondre. Cela se produit lorsque plusieurs facteurs potentiels entrent en jeu.
- Le modèle n’est pas suffisamment puissant (par exemple, utilisez gpt plutôt que text-ada)
- La requête d’index n’est pas optimisée et prend trop de temps
- Le flux comporte de nombreuses étapes à traiter
Envisagez d’optimiser le point de terminaison avec les considérations ci-dessus afin d’améliorer les performances du modèle.
Impossible d’extraire le schéma de déploiement
Après avoir déployé le point de terminaison et que vous souhaitez le tester sous l’onglet Test de la page de détails du point de terminaison, si l’onglet Test affiche Impossible d’extraire le schéma de déploiement comme suit, vous pouvez essayer les deux méthodes suivantes pour atténuer ce problème :

- Vérifiez que vous avez accordé l’autorisation correcte à l’identité du point de terminaison. En savoir plus sur l’octroi d’autorisations à l’identité du point de terminaison.
Accès refusé à la liste secrète de l’espace de travail
Si vous rencontrez une erreur telle que « Accès refusé à la liste des secrets de l’espace de travail », vérifiez que vous avez accordé l’autorisation appropriée à l’identité du point de terminaison. En savoir plus sur l’octroi d’autorisations à l’identité du point de terminaison.
Nettoyer les ressources
Si vous ne comptez pas utiliser le point de terminaison à l’issue de ce tutoriel, il est préférable de le supprimer.
Remarque
La suppression complète peut prendre environ 20 minutes.