Supervision des modèles pour les applications d’IA générative (préversion)
La supervision des modèles en production est une partie essentielle du cycle de vie de l’IA. Les changements dans les données et le comportement des consommateurs peuvent influencer votre application d’IA générative au fil du temps. Cela entraîne des systèmes obsolètes qui affectent négativement les résultats de l’entreprise et exposent les organisations à des risques économiques, de conformité et de réputation.
Important
La surveillance des modèles pour les applications d’IA génératives est actuellement en préversion publique. Ces préversions sont fournies sans contrat de niveau de service et ne sont pas recommandées pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
La supervision des modèles Azure Machine Learning pour les applications d’IA générative vous permet de superviser plus facilement vos applications LLM en production à des fins de sécurité et de qualité à une cadence permettant de garantir un impact maximal sur l’entreprise. La supervision permet de maintenir la qualité et la sécurité de vos applications d’IA génératives. Les fonctionnalités et les intégrations sont les suivantes :
- Collecter des données de production en utilisant le collecteur de données de modèles.
- Métriques d’évaluation d’IA responsables telles que le fondement, la cohérence, la fluidité, la pertinence et la similarité, qui sont interopérables avec les métriques d’évaluation de flux d’invite Azure Machine Learning.
- Possibilité de configurer des alertes en cas de violation en fonction des objectifs de l’organisation et d’exécuter la supervision de manière périodique
- Consommer les résultats dans un tableau de bord enrichi au sein d’un espace de travail dans Azure Machine Learning studio.
- Intégration aux métriques d’évaluation des flux d’invite Azure Machine Learning, analyse des données de production collectées pour fournir des alertes en temps opportun et visualisation des métriques au fil du temps.
Pour connaître les concepts de base de la supervision globale des modèles, reportez-vous à Supervision des modèles avec Azure Machine Learning (préversion). Dans cet article, vous allez apprendre à superviser une application d’IA générative soutenue par un point de terminaison en ligne managé. Voici les étapes à suivre :
- Configurez les prérequis
- Créer votre moniteur
- Confirmer l’état de la supervision
- Consommer les résultats de la supervision
Mesures d’évaluation
Les métriques sont générées par les modèles suivants de langage GPT de pointe configurés avec des instructions d’évaluation spécifiques (modèles d’invite) qui servent de modèles d’évaluation pour les tâches de séquence à séquence. Cette technique a montré des résultats empiriques solides et une corrélation élevée avec le jugement humain par rapport aux métriques d’évaluation d’IA générative standard. Pour plus d’informations sur l’évaluation du flux d’invite, consultez Envoyer un test en bloc et évaluer un flux (préversion) pour plus d’informations sur l’évaluation du flux d’invite.
Ces modèles GPT sont pris en charge et seront configurés en tant que ressource Azure OpenAI :
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Les métriques suivantes sont prises en charge. Pour plus d’informations sur chaque métrique, consultez Descriptions et cas d’usage des métriques d’évaluation de la supervision
- Fondement : évalue la façon dont les réponses générées par le modèle s’alignent sur les informations de la source d’entrée.
- Pertinence : évalue dans quelle mesure les réponses générées par le modèle sont pertinentes et directement liées aux questions données.
- Cohérence : évalue la façon dont le modèle de langage peut produire une sortie fluide, qui se lit naturellement et qui ressemble au langage humain.
- Fluidité : évalue la compétence linguistique de la réponse prédite d’une IA générative. Elle évalue la façon dont le texte généré respecte les règles grammaticales, les structures syntaxiques et l’utilisation appropriée du vocabulaire, ce qui aboutit à des réponses linguistiques correctes et naturelles.
- Similarity : évalue la similarité entre une phrase de vérité (ou un document) et la phrase de prédiction générée par un modèle IA.
Exigences de configuration des métriques
Les entrées suivantes (noms de colonnes de données) sont requises pour mesurer la qualité et la sécurité de la génération :
- texte d’invite : invite d’origine donnée (également appelée « entrées » ou « question »)
- texte d’achèvement : achèvement final de l’appel d’API retourné (également appelé « sorties » ou « réponse »)
- texte de contexte : toutes les données de contexte envoyées à l’appel d’API, ainsi que l’invite d’origine. Par exemple, si vous souhaitez obtenir des résultats de recherche uniquement à partir de certaines sources d’informations/sites web certifiés, vous pouvez définir dans les étapes d’évaluation. Il s’agit d’une étape facultative pouvant être configurée via le flux d’invite.
- texte de vérité de base : texte défini par l’utilisateur comme « source de vérité » (facultatif)
Les paramètres configurés dans votre ressource de données déterminent les métriques que vous pouvez produire, en fonction de ce tableau :
| Métrique | Prompt | Completion | Context | Vérité de terrain |
|---|---|---|---|---|
| Cohérence | Requis | Requis | - | - |
| Maîtrise | Requis | Requis | - | - |
| Fondement | Requis | Obligatoire | Requis | - |
| Pertinence | Requis | Obligatoire | Requis | - |
| Similarité | Requis | Obligatoire | - | Requis |
Prérequis
- Ressource Azure OpenAI : vous devez créer une ressource Azure OpenAI avec un quota suffisant. Cette ressource est utilisée comme point de terminaison d’évaluation.
- Identité managée : créez une identité managée affectée par l’utilisateur (UAI) et attachez-la à votre espace de travail en suivant les instructions fournies dans Attacher une identité managée affectée par l’utilisateur à l’aide de l’interface CLI v2 avec un accès de rôle suffisant, comme défini à l’étape suivante.
- Accès aux rôles : pour attribuer un rôle avec les autorisations requises, vous devez disposer de l’autorisation propriétaire ou Microsoft.Authorization/roleAssignments/write sur votre ressource. La mise à jour des connexions et des autorisations peut prendre plusieurs minutes. Ces rôles supplémentaires doivent être attribués à votre UAI :
- Ressource : espace de travail
- Rôle : scientifique des données Azure Machine Learning
- Connexion à l’espace de travail : en suivant ces conseils, vous utilisez une identité managée qui représente les informations d’identification du point de terminaison Azure OpenAI utilisé pour calculer les métriques de supervision. NE SUPPRIMEZ PAS la connexion une fois qu’elle est utilisée dans le flux.
- Version de l’API : 2023-03-15-preview
- Déploiement de flux d’invite : créez un runtime de flux d’invite en suivant ces conseils, exécutez votre flux et assurez-vous que votre déploiement est configuré à l’aide de cet article comme guide
- Sorties et entrées de flux : vous devez nommer vos sorties de flux convenablement et mémoriser ces noms de colonnes lors de la création de votre moniteur. Dans cet article, nous allons utiliser les éléments suivants :
- Entrées (obligatoires) : « prompt » (invite)
- Sorties (obligatoires) : « completion » (achèvement)
- Sorties (facultatives) : « context » (contexte) | « ground truth » (vérité de base)
- Collecte de données : dans le « Déploiement » (étape 2 de l’Assistant de déploiement du flux d’invite), le bouton bascule « collecte de données d’inférence » doit être activé à l’aide du collecteur de données de modèles
- Sorties : dans Sorties (étape 3 de l’Assistant de déploiement du flux d’invite), vérifiez que vous avez sélectionné les sorties nécessaires listées ci-dessus (par exemple, completion | context | ground_truth) qui répondent à votre configuration requise pour les métriques
- Sorties et entrées de flux : vous devez nommer vos sorties de flux convenablement et mémoriser ces noms de colonnes lors de la création de votre moniteur. Dans cet article, nous allons utiliser les éléments suivants :
Remarque
Si votre instance de calcul se trouve derrière un réseau virtuel, consultez Isolation réseau dans le flux d’invite.
Créer votre moniteur
Créez votre moniteur dans la page de présentation de Supervision 
Configurez les paramètres basiques de supervision
Dans l’Assistant de création de supervision, modifiez le type de tâche du modèle pour invite et saisie semi-automatique, comme indiqué par (A) dans la capture d’écran.

Configurer la ressource de données
Si vous avez utilisé le collecteur de données de modèles, sélectionnez vos deux ressources de données (entrées et sorties).

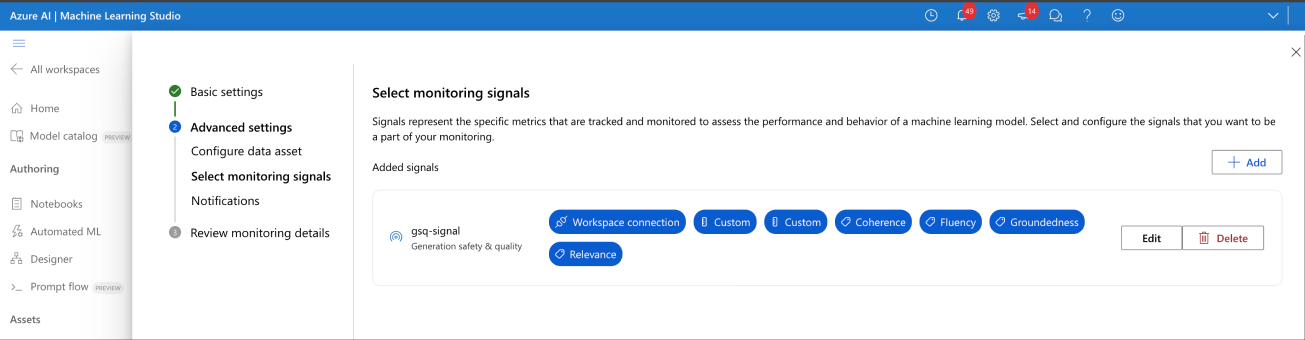
Sélectionner les signaux de supervision

- Configurez la connexion de l’espace de travail (A) comme indiquée dans la capture d’écran.
- Vous devez configurer correctement votre connexion à l’espace de travail, sinon vous recevez le suivant :

- Vous devez configurer correctement votre connexion à l’espace de travail, sinon vous recevez le suivant :
- Entrez votre nom de déploiement de l’évaluateur Azure OpenAI (B).
- (Facultatif) Joignez vos sorties et entrées de données de production : les entrées et sorties de votre modèle de production sont automatiquement jointes par le service de supervision (C). Vous pouvez le personnaliser si nécessaire, mais aucune action n’est requise. Par défaut, la colonne de jointure est correlationid.
- (Facultatif) Configurez des seuils de métrique : un score acceptable par instance est fixé à 3/5. Vous pouvez ajuster votre taux de passage global acceptable dans la plage [1,99] %

Entrez manuellement des noms de colonnes à partir de votre flux d’invite (E). Les noms standard sont ( « prompt » | « completion » | « context » | « ground_truth »), toutefois vous pouvez le configurer en fonction de votre ressource de données.
(Facultatif) Définissez le taux d’échantillonnage (F)
Une fois configuré, votre signal n’affiche plus d’avertissement.

Configurer les notifications
Aucune action n'est nécessaire. Vous pouvez configurer d’autres destinataires si nécessaire.

Confirmer la configuration du signal de supervision
Lorsque la configuration a été effectuée correctement, votre moniteur devrait ressembler à ceci : 
Confirmer l’état de supervision
Si la configuration a été effectuée correctement, votre travail de pipeline de supervision s’affiche ainsi : 
Consommer les résultats
Page de vue d’ensemble du moniteur
La vue d’ensemble de votre moniteur fournit une vue d’ensemble des performances de votre signal. Vous pouvez accéder à la page des détails de votre signal pour plus d’informations.

Page des détails du signal
La page des détails du signal vous permet d’afficher les métriques au fil du temps (A) et d’afficher les histogrammes de distribution (B).

Résoudre les alertes
Il est uniquement possible d’ajuster les seuils de signal. Le score acceptable est fixé à 3/5, et il est uniquement possible d’ajuster le champ « taux de réussite global acceptable ».
