Personnaliser le flux et les métriques d’évaluation
Les flux d’évaluation sont des types spéciaux de flux qui évaluent dans quelle mesure les sorties d’une d’exécution de flux s’alignent sur des critères et des objectifs spécifiques en calculant les métriques.
Dans le flux d’invite, vous pouvez personnaliser ou créer vos propres flux et métriques d’évaluation adaptés à vos tâches et objectifs, puis l’utiliser pour évaluer d’autres flux. Dans ce document vous apprendrez :
- Comprendre l’évaluation dans le flux d’invite
- Entrées
- La journalisation des sorties et des métriques
- Comment développer un flux d’évaluation
- Comment utiliser un flux d’évaluation personnalisé dans l’exécution par lots
Comprendre l’évaluation dans le flux d’invite
Dans le flux d’invite, un flux est une séquence de nœuds qui traitent une entrée et génèrent une sortie. De même, les flux d’évaluation peuvent prendre les entrées nécessaires et produire les sorties correspondantes, qui sont souvent les scores ou les métriques. Les concepts des flux d’évaluation sont similaires à ceux des flux standard, mais il existe des différences dans l’expérience de création et la façon dont ils sont utilisés.
Voici quelques fonctionnalités spéciales aux flux d’évaluation :
- Ils s’exécutent généralement après l’exécution à tester en recevant ses sorties. Ils utilisent les sorties pour calculer les scores et les métriques. Les sorties d’un flux d’évaluation sont les résultats qui mesurent les performances du flux testé.
- Ils peuvent avoir un nœud d’agrégation qui calcule les performances globales du flux testé sur le jeu de données de test.
- Ils peuvent consigner les métriques à l’aide de la fonction
log_metric().
Nous allons présenter comment les entrées et les sorties doivent être définies dans le développement de méthodes d’évaluation.
Entrées
Les flux d’évaluation calculent les métriques ou les scores d’une exécution par lots de flux en fonction d’un jeu de données. Pour ce faire, ils doivent prendre en compte les sorties de l’exécution testées. Vous pouvez définir les entrées d’un flux d’évaluation de la même façon que la définition des entrées d’un flux standard.
Un flux d’évaluation s’exécute après une autre exécution pour évaluer dans quelle mesure les sorties de cette exécution s’alignent sur des critères et des objectifs spécifiques. Par conséquent, l’évaluation reçoit les sorties générées à partir de cette exécution.
Par exemple, si le flux testé est un flux QnA qui génère des réponses basées sur une question, vous pouvez en conséquence nommer une entrée de votre évaluation en tant que answer. Si le flux testé est un flux de classification qui classifie un texte dans une catégorie, vous pouvez nommer une entrée de votre évaluation en tant que category.
D’autres entrées telles que ground truth peuvent également être nécessaires. Par exemple, si vous souhaitez calculer l’exactitude d’un flux de classification, vous devez fournir la colonne category dans le jeu de données comme vérité de base. Si vous souhaitez calculer l’exactitude d’un flux QnA, vous devez fournir la colonne answer dans le jeu de données comme vérité de base.
Par défaut, l’évaluation utilise le même jeu de données que le jeu de données test fourni dans l’exécution testée. Toutefois, si les étiquettes correspondantes ou les valeurs de vérité au sol cibles se trouvent dans un jeu de données différent, vous pouvez facilement basculer vers celui-ci.
Certaines autres entrées peuvent être nécessaires pour calculer les métriques telles que question et context dans le scénario QnA ou RAG. Vous pouvez définir ces entrées de la même façon que la définition des entrées d’un flux standard.
Description des entrées
Pour rappeler quelles entrées sont nécessaires pour calculer les métriques, vous pouvez ajouter une description pour chaque entrée requise. Les descriptions s’affichent lors du mappage des sources dans la soumission d’exécution par lot.

Pour ajouter des descriptions pour chaque entrée, sélectionner Afficher la description dans la section Entrée lors du développement de votre méthode d’évaluation. Vous pouvez également sélectionner « Masquer la description » pour masquer la description.

Ensuite, cette description s’affiche lors de l’utilisation de cette méthode d’évaluation dans la soumission d’exécution par lot.
Sorties et métriques
Les sorties d’une évaluation sont les résultats qui mesurent les performances du flux testé. La sortie contient généralement des métriques telles que des scores et peut également inclure du texte pour la réflexion et les suggestions.
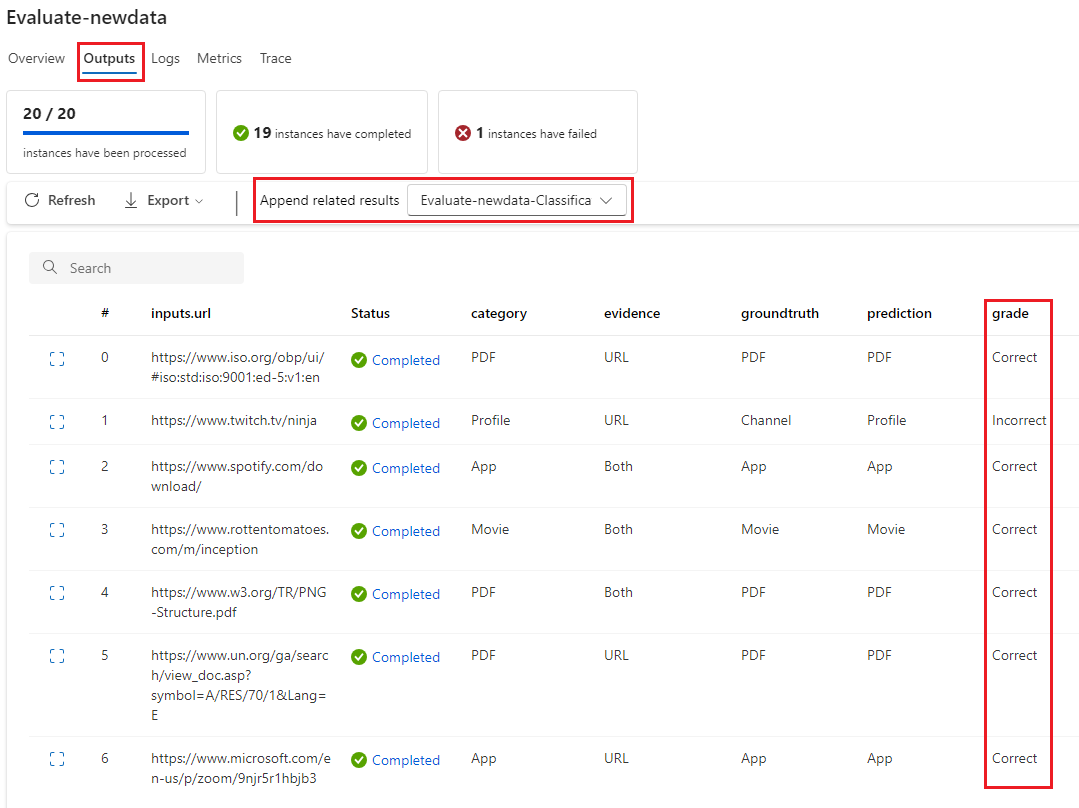
Sorties d’évaluation : scores au niveau de l’instance
Dans le flux d’invite, le flux traite une ligne de données à la fois et génère un enregistrement de sortie. De même, dans la plupart des cas d’évaluation, il existe un score pour chaque sortie, ce qui vous permet de vérifier l’exécution du flux sur chaque donnée individuelle.
Le flux d’évaluation peut calculer des scores pour chaque données, et vous pouvez enregistrer les scores pour chaque échantillon de données en tant que sorties de flux en les paramétrant dans la section des sorties du flux d’évaluation. Cette expérience de création est identique à la définition d’une sortie de flux standard.

Vous pouvez afficher les scores dans l’onglet Vue d’ensemble->Sortie lorsque cette méthode d’évaluation est utilisée pour évaluer un autre flux. Ce processus est identique à la vérification des sorties d’exécution par lots d’un flux standard. Le score au niveau de l’instance est ajouté à la sortie du flux testé.
Nœud d’agrégation et de journalisation des métriques
En outre, il est également important de fournir une évaluation globale de l’exécution. Pour distinguer le score individuel d’évaluation de chaque sortie unique, nous appelons les valeurs permettant d’évaluer les performances globales d’une exécution en tant que « métriques ».
Pour calculer la valeur d’évaluation globale basée sur chaque score individuel, vous pouvez vérifier l’« agrégation » d’un nœud Python dans un flux d’évaluation pour le transformer en nœud de « réduction », ce qui permet au nœud de prendre les entrées en tant que liste et de les traiter par lots.

De cette façon, vous pouvez calculer et traiter tous les scores de chaque sortie de flux et calculer un résultat global pour chaque sortie de score. Par exemple, si vous souhaitez calculer l’exactitude d’un flux de classification, vous pouvez calculer l’exactitude de chaque sortie de score, puis calculer l’exactitude moyenne de toutes les sorties de score. Ensuite, vous pouvez consigner l’exactitude moyenne en tant que métrique à l’aide de promptflow_sdk.log_metrics(). Les métriques doivent être numériques (décimaux/entiers). La journalisation des métriques de type chaîne n’est pas prise en charge.
L’extrait de code suivant est un exemple de calcul de l’exactitude globale en faisant la moyenne du score de l’exactitude (grade) de chaque données. L’exactitude globale est consignée sous forme de métrique à l’aide de promptflow_sdk.log_metrics().
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
Comme vous avez appelé cette fonction dans le nœud Python, vous n’avez pas besoin de l’affecter ailleurs, et vous pouvez afficher les métriques ultérieurement. Lorsque cette méthode d’évaluation est utilisée dans une exécution par lots, les métriques indiquant que les performances globales peuvent être consultées sous l’onglet Vue d’ensemble->Métriques.

Commencer à développer une méthode d’évaluation
Il existe deux façons de développer vos propres méthodes d’évaluation :
- Créer un nouveau flux d’évaluation à partir de zéro : développez une toute nouvelle méthode d’évaluation à partir de zéro. Dans la page d’accueil de l’onglet Flux d’invite, dans la section « Créer par type », vous pouvez choisir « Flux d’évaluation » et afficher un modèle de flux d’évaluation.

- Personnaliser un flux d’évaluation intégré : modifiez un flux d’évaluation intégrée. Recherchez le flux d’évaluation intégré dans l’Assistant de création de flux. Dans la galerie de flux, sélectionnez « Cloner » pour procéder à la personnalisation. Vous pouvez ensuite voir et vérifier la logique et le flux des évaluations intégrées, puis modifier le flux. De cette façon, vous ne commencez pas à partir de zéro, mais à partir d’un échantillon à utiliser pour votre personnalisation.

Calculer les scores pour chaque données
Comme mentionné, l’évaluation est exécutée pour calculer les scores et les métriques en fonction d’un flux qui s’exécute sur un jeu de données. Par conséquent, la première étape des flux d’évaluation consiste à calculer les scores pour chaque sortie individuelle.
Prenez le flux d’évaluation intégré Classification Accuracy Evaluation comme exemple. Le score grade, qui mesure l’exactitude de chaque sortie générée par le flux à sa vérité de base correspondante, est calculé dans le nœud grade. Si vous créez un flux d’évaluation à partir de zéro lors de la création par type, ce score est calculé dans le nœud line_process dans le modèle. Vous pouvez également remplacer le nœud Python line_process par un nœud LLM afin d’utiliser LLM pour calculer le score, ou afin d’utiliser plusieurs nœuds pour effectuer le calcul.

Ensuite, vous devez spécifier la sortie des nœuds comme sorties du flux d’évaluation, ce qui indique que les sorties sont les scores calculés pour chaque échantillon de données. Vous pouvez également générer un raisonnement en tant qu’informations supplémentaires, et cela est similaire à l’expérience de définition des sorties dans le flux standard.
Calculer et consigner les métriques
La deuxième étape de l’évaluation consiste à calculer les métriques globales pour évaluer l’exécution. Comme mentionné, les métriques sont calculées dans un nœud Python défini sur Aggregation. Ce nœud prend les scores calculés dans le nœud précédent et organise le score de chaque échantillon de données dans une liste, puis les calcule ensemble en une fois.
Si vous créez et modifiez à partir de zéro lors de la création par type, ce score est calculé dans le nœud aggregate. L’extrait de code est le modèle d’un nœud d’agrégation.
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
Vous pouvez utiliser votre propre logique d’agrégation, telle que le calcul de la moyenne, de la valeur moyenne ou de l’écart type des scores.
Vous devez ensuite consigner les métriques avec la fonction promptflow.logmetrics(). Vous pouvez consigner plusieurs métriques dans un seul flux d’évaluation. Les métriques doivent être numériques (float/int).
Utiliser un flux d’évaluation personnalisé
Après la création de vos propres flux et métriques d’évaluation, vous pouvez ensuite utiliser ce flux pour évaluer les performances de votre flux standard.
Tout d’abord, commencez à partir de la page de création de flux sur laquelle vous souhaitez évaluer. Par exemple, un flux QnA dont vous ne savez pas encore comment il s’exécute sur un jeu de données volumineux et que vous souhaitez tester. Cliquez sur le bouton
Evaluateet choisissezCustom evaluation.
Ensuite, à l’instar des étapes d’envoi d’une exécution de lot comme mentionné dans Envoyer une exécution par lot et évaluer un flux dans le flux d’invite, suivez les premières étapes afin de préparer le jeu de données pour exécuter le flux.
Ensuite, à l’étape
Evaluation settings - Select evaluation, en plus des évaluations intégrées, les évaluations personnalisées sont également disponibles pour la sélection. Cela répertorie tous vos flux d’évaluation dans votre liste de flux que vous avez créée, clonées ou personnalisées. Les flux d’évaluation créés par d’autres personnes dans le même projet ne s’affichent pas dans cette section.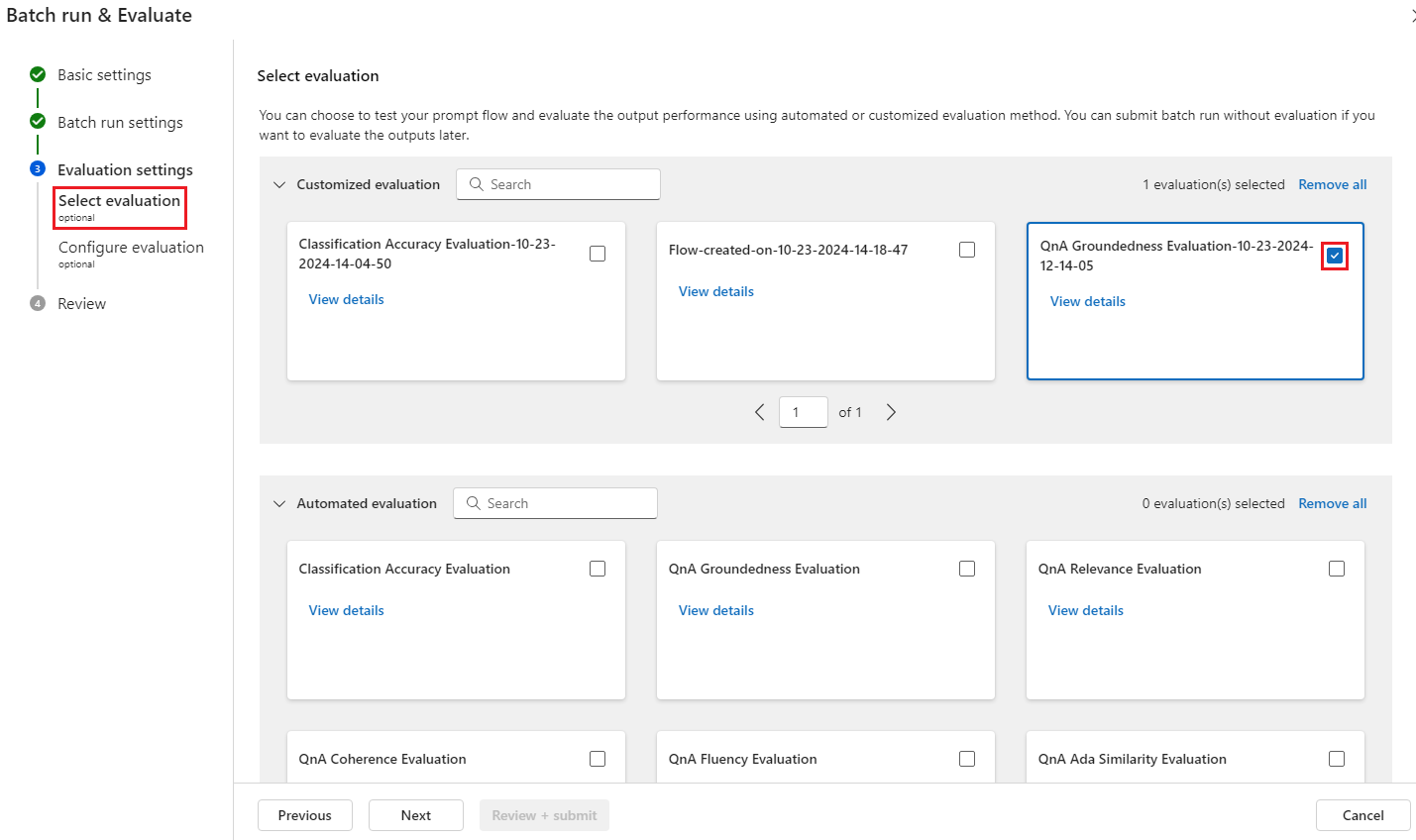
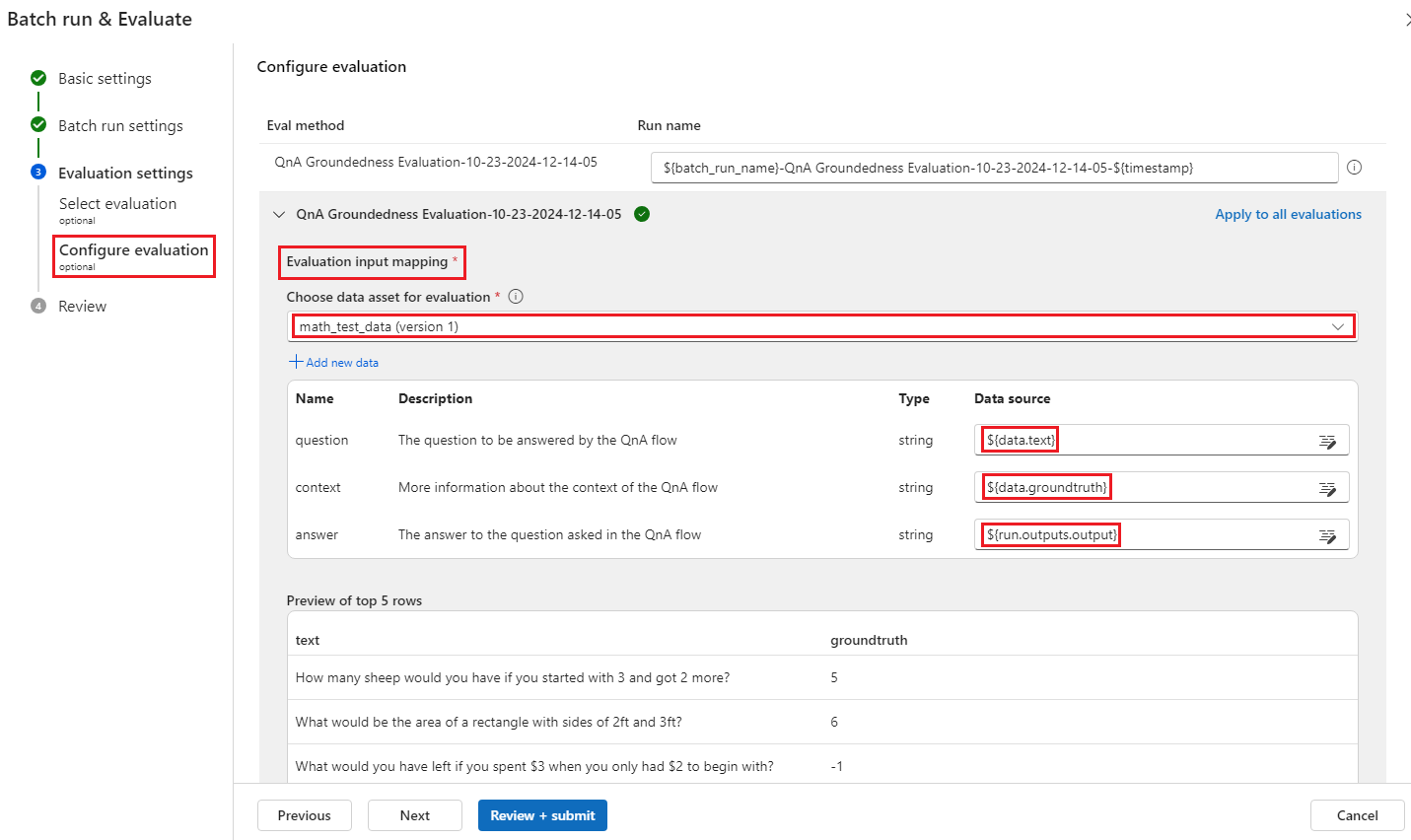
Ensuite, à l’étape
Evaluation settings - Configure evaluation, vous devez spécifier les sources des données d’entrée nécessaires pour la méthode d’évaluation. Par exemple, la colonne groundtruth est susceptible de provenir d’un jeu de données.Pour exécuter une évaluation, vous pouvez indiquer les sources de ces entrées nécessaires dans la section « mappage d’entrée » lors de l’envoi d’une évaluation. Ce processus est identique à la configuration mentionnée dans Envoyer une exécution par lot et évaluer un flux dans le flux d’invite.
- Si la source de données provient de votre sortie d’exécution, la source est indiquée sous la forme
${run.output.[OutputName]} - Si la source de données provient de votre jeu de données de test, la source est indiquée sous la forme
${data.[ColumnName]}
Remarque
Si votre évaluation ne nécessite pas de données du jeu de données, vous n’avez pas besoin de référencer des colonnes de jeu de données dans la section de mappage d’entrée, indiquant que la sélection du jeu de données est une configuration facultative. La sélection du jeu de données n’affecte pas le résultat de l’évaluation.
- Si la source de données provient de votre sortie d’exécution, la source est indiquée sous la forme
Lorsque cette méthode d’évaluation est utilisée pour évaluer un autre flux, le score au niveau de l’instance peut être affiché sous l’onglet Vue d’ensemble ->Sortie.