Envoyer une exécution par lot pour évaluer un flux
Une exécution par lot exécute un flux d’invite avec un jeu de données volumineux et génère des sorties pour chaque ligne de données. Pour évaluer les performances de votre flux d’invite avec un jeu de données volumineux, vous pouvez envoyer une exécution par lot et utiliser des méthodes d’évaluation pour générer des scores de performances et des métriques.
Une fois le flux de traitement par lots terminé, les méthodes d’évaluation s’exécutent automatiquement pour calculer les scores et les métriques. Vous pouvez utiliser les métriques d’évaluation pour évaluer la sortie de votre flux par rapport à vos critères et objectifs de performances.
Cet article explique comment envoyer une exécution par lot et utiliser une méthode d’évaluation pour mesurer la qualité de votre sortie de flux. Vous découvrirez comment afficher les résultats et les métriques de l’évaluation, et comment démarrer un nouveau cycle d’évaluation avec une méthode ou un sous-ensemble de variantes différent.
Prérequis
Pour exécuter un flux de traitement par lots avec une méthode d’évaluation, vous avez besoin des composants suivants :
Un flux d’invite Azure Machine Learning opérationnel dont vous souhaitez tester les performances.
Un jeu de données de test à utiliser pour l’exécution par lot.
Votre jeu de données de test doit être au format CSV, TSV ou JSONL, et doit avoir des en-têtes qui correspondent aux noms d’entrée de votre flux. Toutefois, vous pouvez mapper différentes colonnes de jeu de données aux colonnes d’entrée pendant le processus de configuration de l’exécution d’évaluation.
Créer et envoyer une exécution par lot d’évaluation
Pour envoyer une exécution par lot, vous devez sélectionner le jeu de données avec lequel tester votre flux. Vous pouvez également sélectionner une méthode d’évaluation pour calculer les métriques de votre sortie de flux. Si vous ne souhaitez pas utiliser de méthode d’évaluation, vous pouvez ignorer les étapes d’évaluation et lancer l’exécution par lot sans calculer de métriques. Vous pouvez également exécuter un cycle d’évaluation ultérieurement.
Pour démarrer une exécution par lot avec ou sans évaluation, sélectionnez Évaluer en haut de la page de flux d’invite.
Dans la page Paramètres de base de l’Assistant Exécuter par lot et Évaluer, personnalisez le Nom d’affichage de l’exécution si vous le souhaitez et fournissez éventuellement une Description de l’exécution et des Étiquettes. Cliquez sur Suivant.
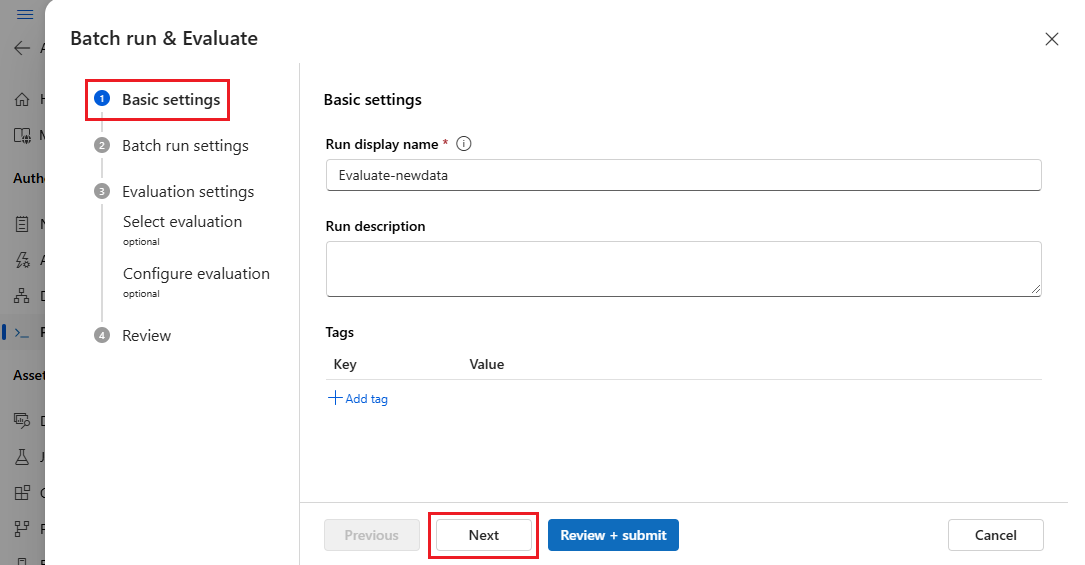
Dans la page Paramètres d’exécution par lot, sélectionnez le jeu de données à utiliser et configurez le mappage d’entrée.
Le flux d’invite prend en charge le mappage de votre entrée de flux à une colonne de données spécifique dans votre jeu de données. Vous pouvez affecter une colonne de jeu de données à une certaine entrée à l’aide de
${data.<column>}. Si vous souhaitez affecter une valeur constante à une entrée, vous pouvez entrer directement cette valeur.
Vous pouvez sélectionner Vérifier + envoyer à ce stade pour ignorer les étapes d’évaluation et exécuter l’exécution par lot sans utiliser de méthode d’évaluation. L’exécution par lot génère alors des sorties individuelles pour chaque élément de votre jeu de données. Vous pouvez vérifier les sorties manuellement ou les exporter afin d’effectuer une analyse approfondie.
Autrement, pour utiliser une méthode d’évaluation afin de valider les performances de cette exécution, sélectionnez Suivant. Vous pouvez également ajouter un nouveau cycle d’évaluation à une exécution par lot terminée.
Dans la page Sélectionner une évaluation, sélectionnez une ou plusieurs évaluations personnalisées ou intégrées à exécuter. Vous pouvez sélectionner le bouton Afficher les détails pour voir plus d’informations sur la méthode d’évaluation, telles que les métriques qu’elle génère ainsi que les connexions et les entrées dont elle a besoin.
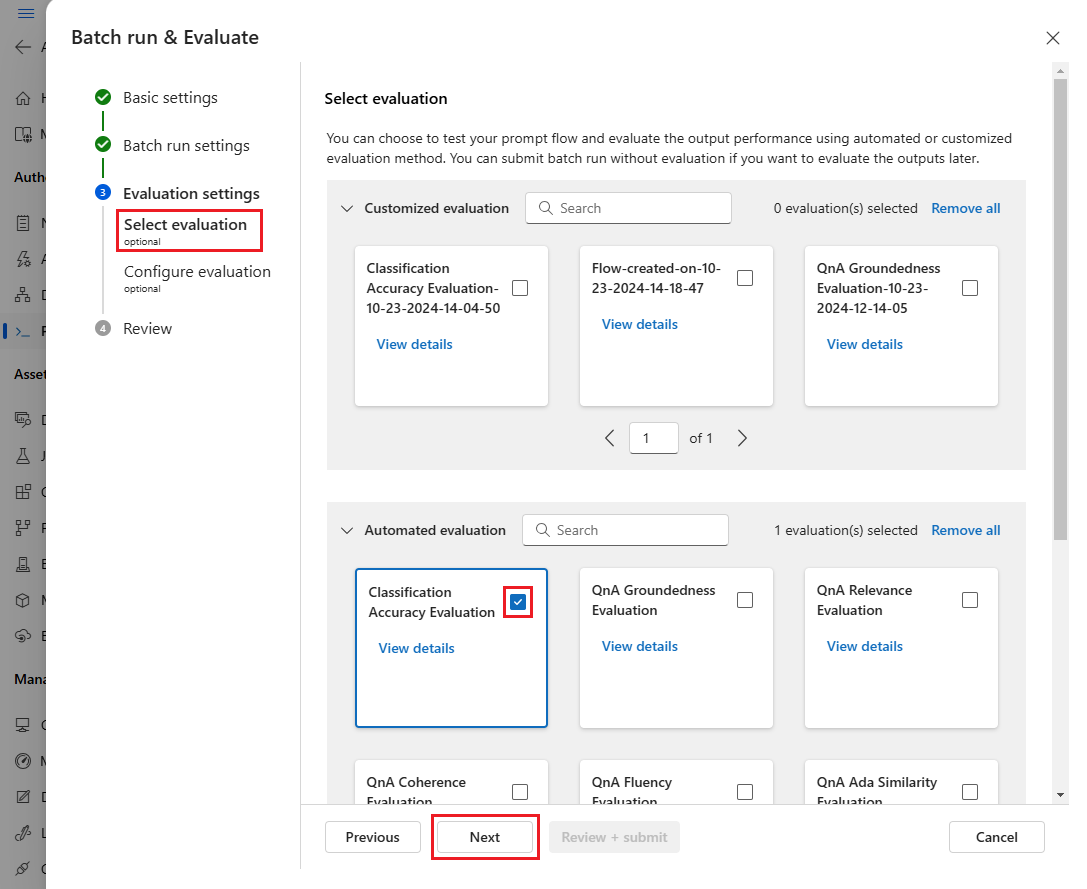
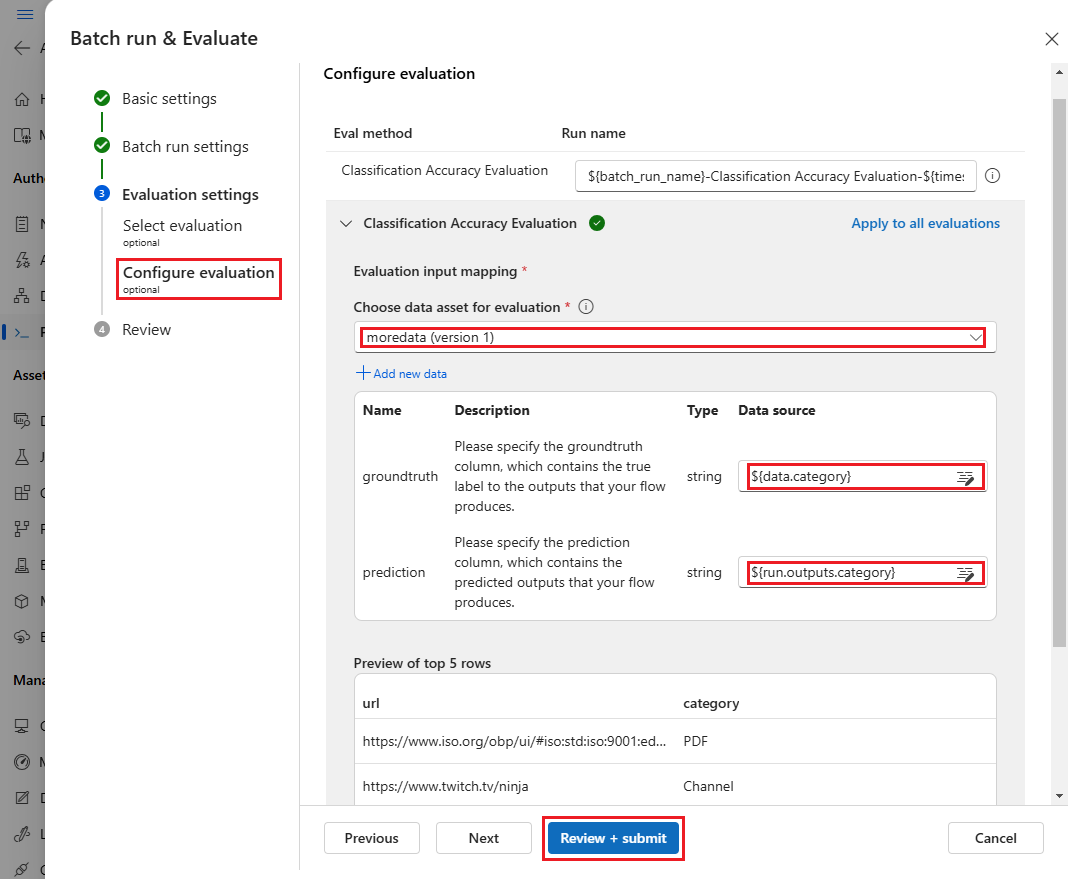
Ensuite, sur l’écran Configurer l’évaluation, spécifiez les sources d’entrées requises pour l’évaluation. Par exemple, la colonne de vérité terrain est susceptible de provenir d’un jeu de données. Par défaut, l’évaluation utilise le même jeu de données que l’exécution par lot globale. Toutefois, si les étiquettes correspondantes ou les valeurs de vérité terrain cibles se trouvent dans un jeu de données différent, vous pouvez utiliser celui-ci.
Remarque
Si votre méthode d’évaluation ne nécessite pas de données provenant d’un jeu de données, la sélection du jeu de données est une configuration facultative qui n’affecte pas les résultats d’évaluation. Vous n’avez pas besoin de sélectionner un jeu de données ou de référencer des colonnes de jeu de données dans la section de mappage d’entrée.
Dans la section Mappage d’entrée de l’évaluation, indiquez les sources d’entrées requises pour l’évaluation.
- Si les données proviennent de votre jeu de données de test, définissez la source sur
${data.[ColumnName]}. - Si les données proviennent de votre sortie d’exécution, définissez la source sur
${run.outputs.[OutputName]}.
- Si les données proviennent de votre jeu de données de test, définissez la source sur
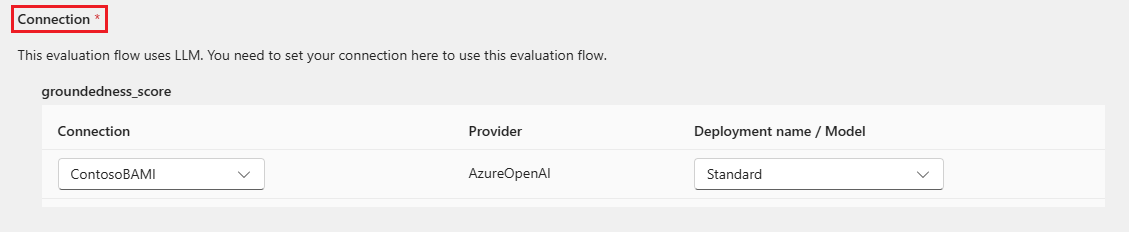
Certaines méthodes d’évaluation nécessitent des grands modèles de langage (LLM) tels que GPT-4 ou GPT-3, ou nécessitent d’autres connexions pour consommer des informations d’identification ou des clés. Pour ces méthodes, vous devez entrer les données de connexion dans la section Connexion en bas de cet écran pour pouvoir utiliser le flux d’évaluation. Pour plus d’informations, consultez Configurer une connexion.
Sélectionnez Vérifier + envoyer pour passer en revue vos paramètres, puis Envoyer pour démarrer l’exécution par lot avec l’évaluation.






Remarque
- Certains processus d’évaluation utilisent de nombreux jetons. Il est donc recommandé d’utiliser un modèle capable de prendre en charge >=16 000 jetons.
- Les exécutions par lots ont une durée maximale de dix heures. Si une exécution par lot dépasse cette limite, elle se termine et est marquée comme ayant échoué. Surveillez la capacité de votre LLM pour éviter la limitation. Si nécessaire, réduisez la taille de vos données. Si vous rencontrez toujours des problèmes, soumettez un formulaire de commentaires ou une demande de support.
Afficher les résultats et les métriques de l’évaluation
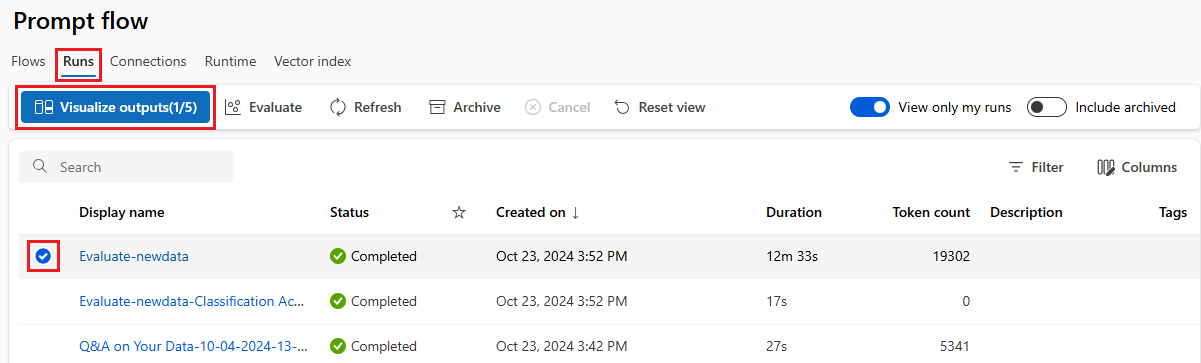
Vous trouverez la liste des exécutions par lot envoyées sous l’onglet Exécutions dans la page Flux d’invite d’Azure Machine Learning studio.
Pour vérifier les résultats d’une exécution par lot, sélectionnez l’exécution, puis Visualiser les sorties.
Sur l’écran Visualiser les sorties, la section Exécutions et métriques affiche les résultats globaux de l’exécution par lot et de l’exécution de l’évaluation. La section Sorties affiche les entrées d’exécution ligne par ligne dans un tableau de résultats qui inclut également l’ID de ligne, Exécution, État et Métriques système.
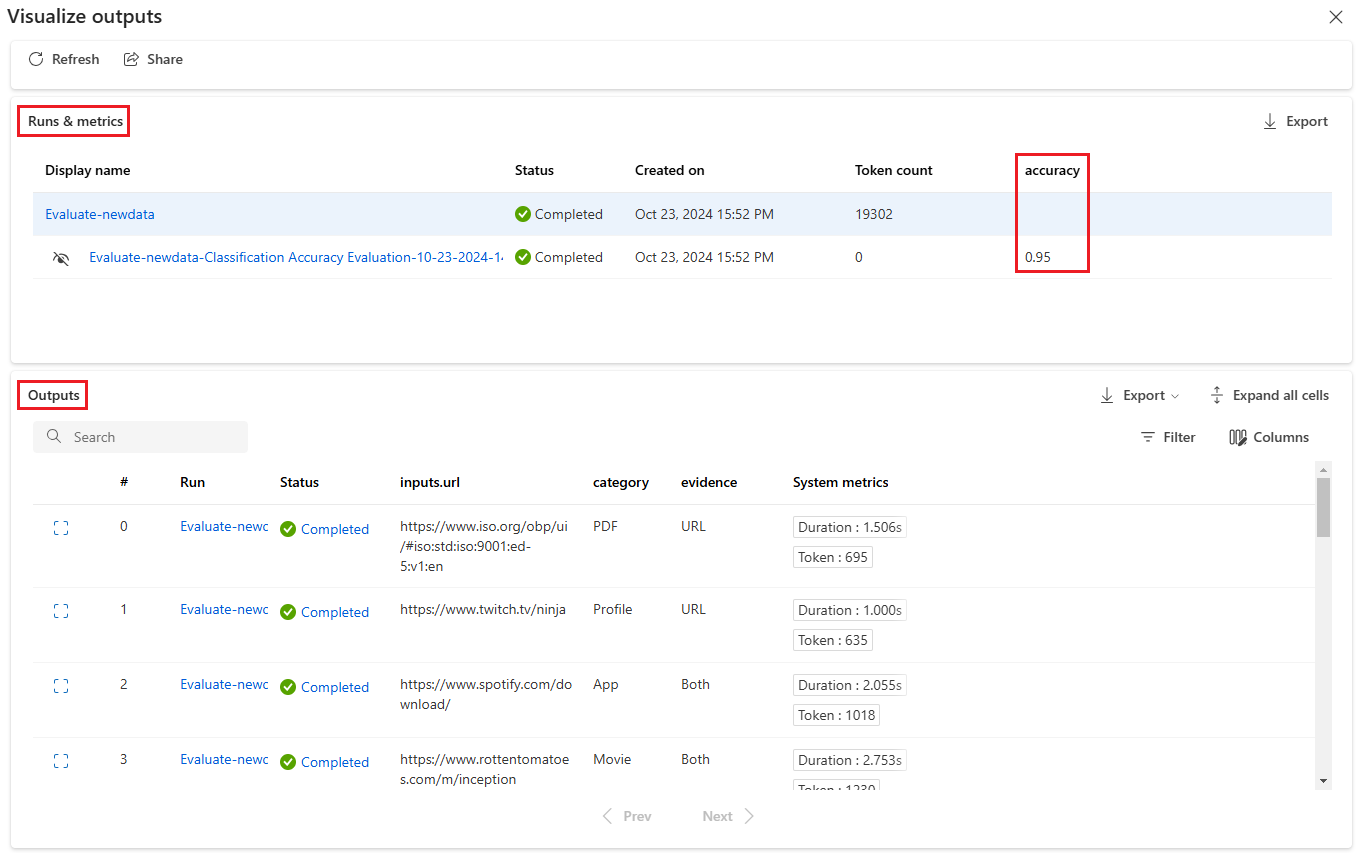
Si vous activez l’icône Affichage en regard de l’exécution d’évaluation dans la section Exécutions et métriques, le tableau Sorties affiche également le score d’évaluation ou la note pour chaque ligne.
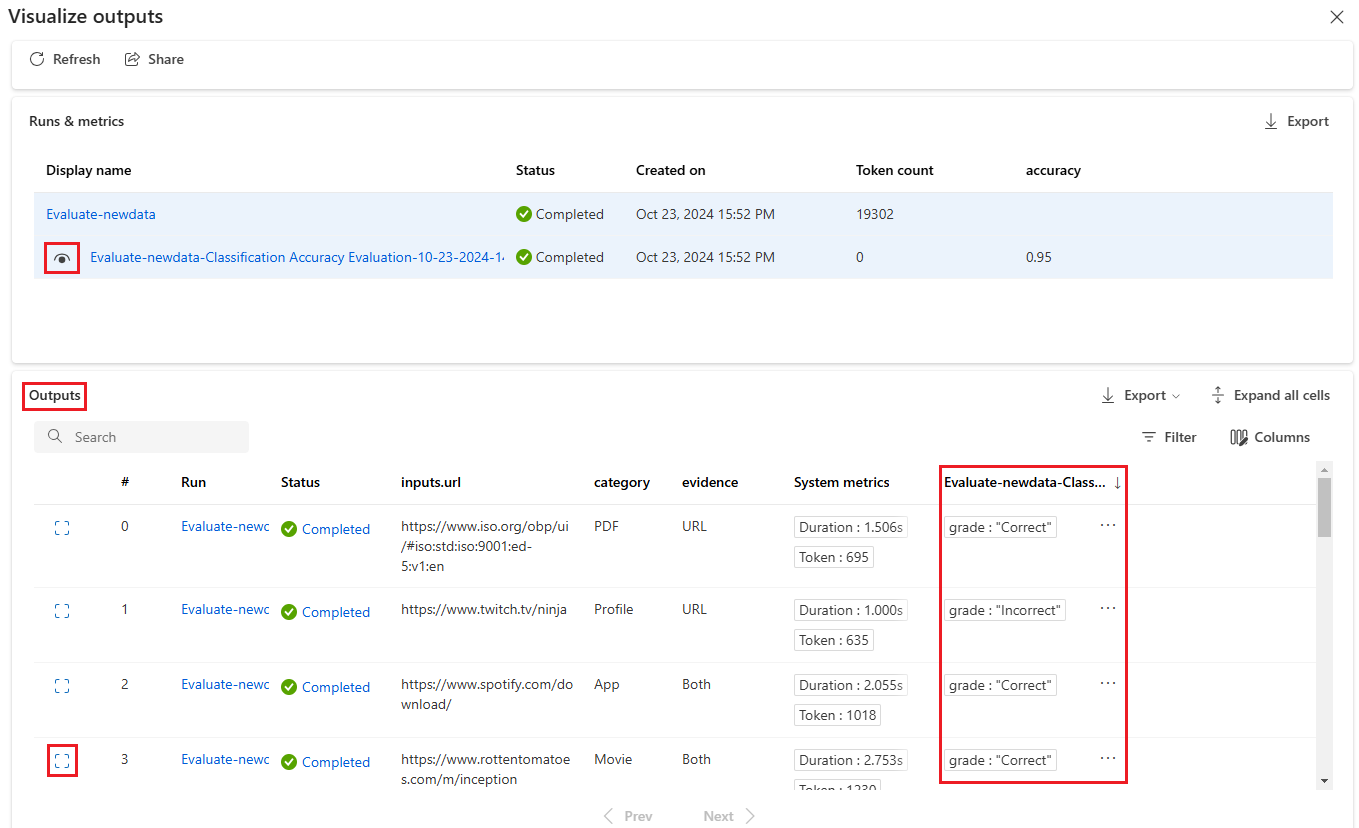
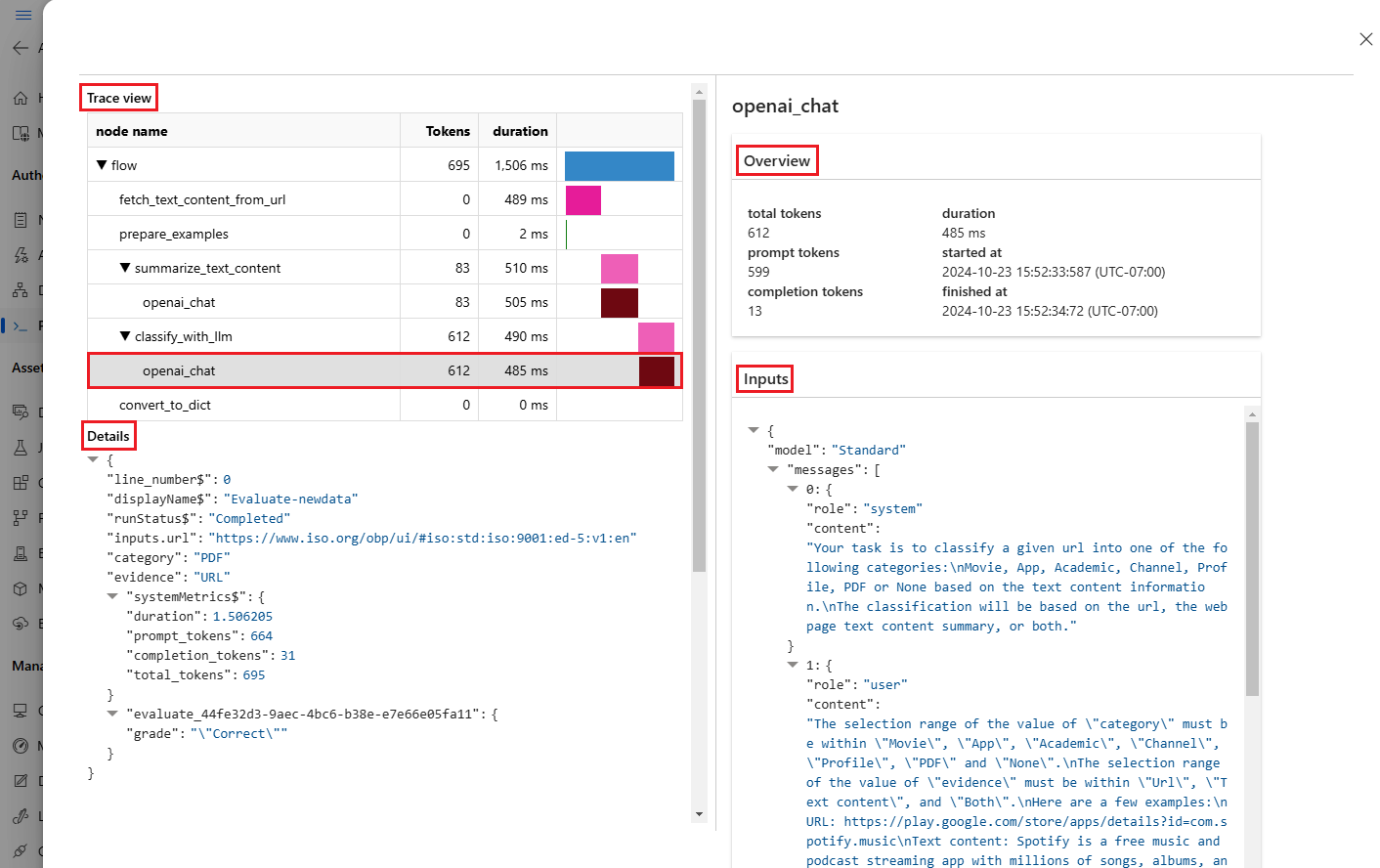
Sélectionnez l’icône Afficher les détails en regard de chaque ligne du tableau Sorties pour observer et déboguer l’Affichage de trace et les Détails relatifs à ce cas de test. L’affichage Trace fournit des informations telles que le nombre de jetons et la durée de ce cas. Développez et sélectionnez n’importe quelle étape pour afficher la Vue d’ensemble et les Entrées de cette étape.




Vous pouvez également afficher les résultats de l’exécution d’évaluation à partir du flux d’invite que vous avez testé. Sous Afficher les exécutions par lot, sélectionnez Afficher les exécutions par lot pour afficher la liste des exécutions par lot pour le flux, ou sélectionnez Afficher les dernières sorties d’exécution par lot pour afficher les sorties de la dernière exécution.

Dans la liste des exécutions par lot, sélectionnez un nom d’exécution par lot pour ouvrir la page de flux de cette exécution.
Dans la page de flux d’une exécution d’évaluation, sélectionnez Afficher les sorties ou Détails pour afficher les détails du flux. Vous pouvez également Cloner le flux pour créer un flux ou le Déployer en tant que point de terminaison en ligne.

Sur l’écran Détails :
L’onglet Vue d’ensemble affiche des informations complètes sur l’exécution, notamment les propriétés de l’exécution, l’ensemble de données d’entrée, l’ensemble de données de sortie, les étiquettes et la description.
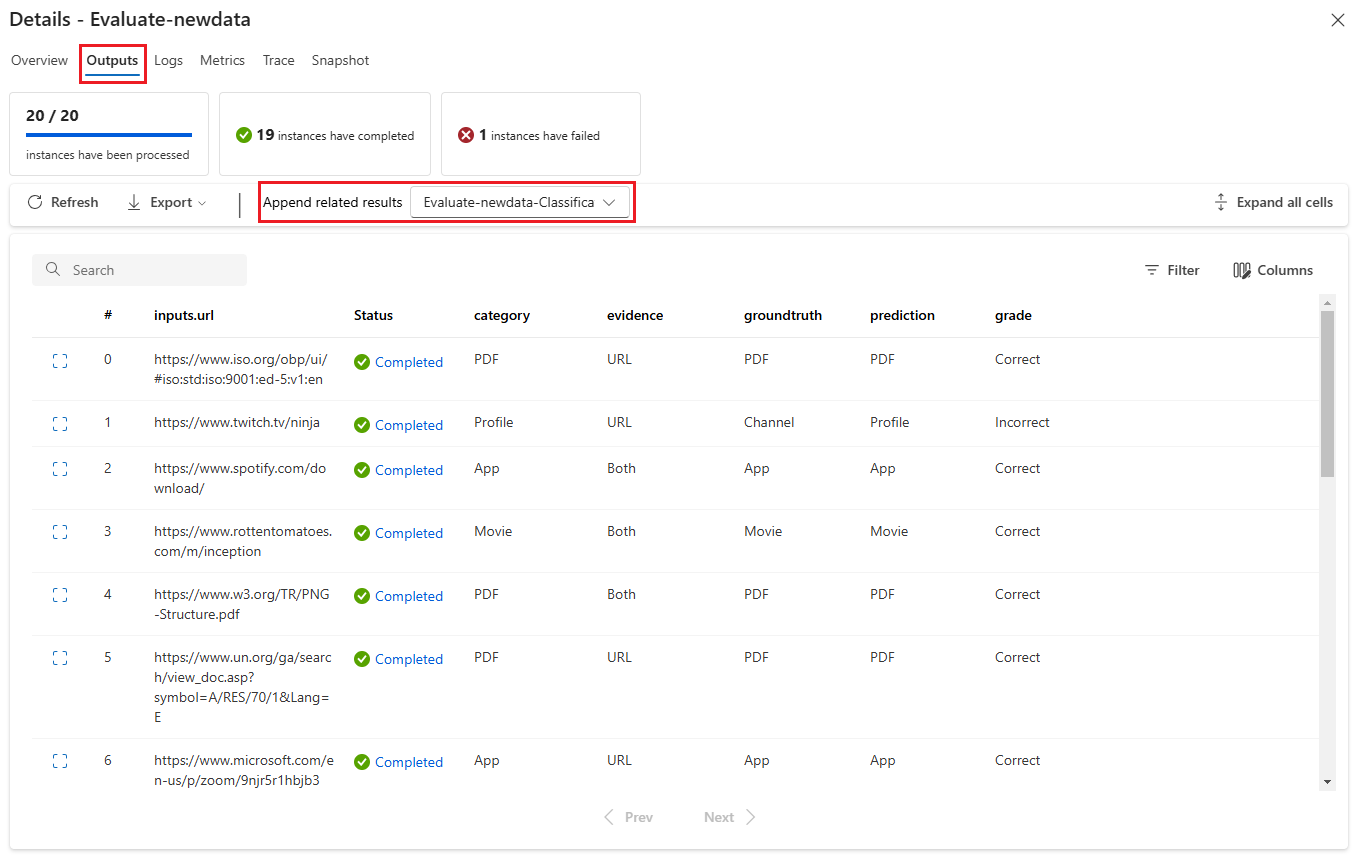
L’onglet Sorties affiche un résumé des résultats en haut de la page, suivi du tableau des résultats de l’exécution par lot. Si vous sélectionnez l’exécution d’évaluation en regard d’Ajouter des résultats connexes, le tableau affiche également les résultats de l’exécution d’évaluation.
L’onglet Journaux montre les journaux d’exécution, qui peuvent être utiles pour le débogage détaillé des erreurs d’exécution. Vous pouvez télécharger les fichiers journaux.
L’onglet Métriques fournit un lien vers les métriques de l’exécution.
L’onglet Trace fournit des informations détaillées telles que le nombre de jetons et la durée de chaque cas de test. Développez et sélectionnez n’importe quelle étape pour afficher la Vue d’ensemble et les Entrées de cette étape.
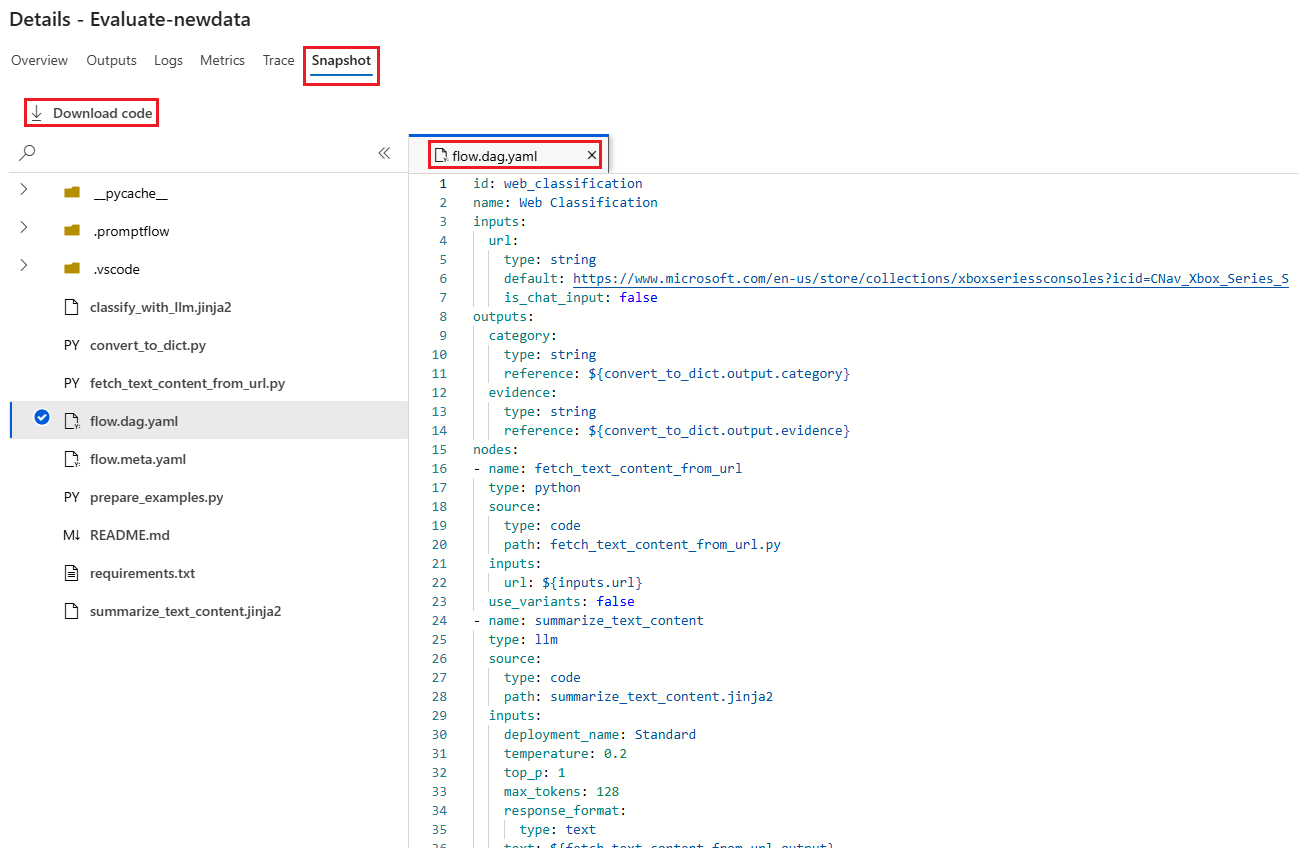
L’onglet Instantané affiche les fichiers et le code de l’exécution. Vous pouvez voir la définition de flux flow.dag.yaml et télécharger un ou plusieurs des fichiers.


Démarrer un nouveau cycle d’évaluation pour la même exécution
Vous pouvez exécuter un nouveau cycle d’évaluation pour calculer les métriques d’une exécution par lot terminée sans réexécuter le flux. Ce processus permet d’économiser le coût lié à la réexécution de votre flux, et est utile dans les scénarios suivants :
- Vous n’avez pas sélectionné de méthode d’évaluation lorsque vous avez envoyé une exécution par lot, et vous souhaitez maintenant évaluer les performances de l’exécution.
- Vous avez utilisé une méthode d’évaluation pour calculer une certaine métrique, et souhaitez maintenant calculer une autre métrique.
- Votre exécution d’évaluation précédente a échoué, mais l’exécution par lot a généré des sorties correctement et vous souhaitez réessayer l’évaluation.
Pour démarrer un autre cycle d’évaluation, sélectionnez Évaluer en haut de la page de flux d’exécution par lot. L’Assistant Nouvelle évaluation s’ouvre sur l’écran Sélectionner une évaluation. Terminez la configuration et envoyez la nouvelle exécution d’évaluation.
La nouvelle exécution apparaît dans la liste Exécutions du flux d’invite, et vous pouvez sélectionner plusieurs lignes dans la liste, puis sélectionner Visualiser les sorties pour comparer les sorties et les métriques.
Comparer l’historique des exécutions d’évaluation et les métriques
Si vous modifiez votre flux pour améliorer ses performances, vous pouvez envoyer plusieurs exécutions par lot afin de comparer les performances des différentes versions de flux. Vous pouvez également comparer les métriques calculées par différentes méthodes d’évaluation afin d déterminer la méthode qui convient le mieux à votre flux.
Pour vérifier l’historique des exécutions par lot de votre flux, sélectionnez Afficher les exécutions par lot en haut de la page de votre flux. Vous pouvez sélectionner chaque exécution pour vérifier les détails. Vous pouvez également sélectionner plusieurs exécutions et sélectionner Visualiser les sorties pour comparer les métriques et les sorties de ces exécutions.

Comprendre les métriques d’évaluation intégrées
Le flux d’invite Azure Machine Learning fournit plusieurs méthodes d’évaluation intégrées pour vous aider à mesurer les performances de la sortie de flux. Chaque méthode d’évaluation calcule des métriques différentes. Le tableau suivant décrit les méthodes d’évaluation intégrées disponibles.
| Méthode d’évaluation | Métrique | Description | Connexion requise ? | Entrée requise | Valeurs du score |
|---|---|---|---|---|---|
| Évaluation de l’exactitude de la classification | Précision | Mesure les performances d’un système de classification en comparant ses sorties à la vérité terrain | Non | prédiction, vérité de base | Dans la plage [0, 1] |
| Évaluation du fondement des questions-réponses | Fondement | Mesure le fondement des réponses prédites du modèle dans la source d’entrée. Même si les réponses du LLM sont justes, elles ne sont pas basées sur la vérité terrain si elles ne sont pas vérifiables par rapport à la source. | Oui | question, réponse, contexte (sans vérité de base) | 1 à 5, avec 1 = pire et 5 = meilleur |
| Évaluation de la similarité des questions-réponses GPT | Similarité GPT | Mesure la similarité entre les réponses de vérité terrain fournies par l’utilisateur et la réponse prédite par le modèle à l’aide d’un modèle GPT | Oui | question, réponse, vérité de base (contexte non nécessaire) | 1 à 5, avec 1 = pire et 5 = meilleur |
| Évaluation de la pertinence des questions-réponses | Pertinence | Mesure la pertinence des réponses prédites du modèle aux questions posées | Oui | question, réponse, contexte (sans vérité de base) | 1 à 5, avec 1 = pire et 5 = meilleur |
| Évaluation de la cohérence des questions-réponses | Cohérence | Mesure la qualité de toutes les phrases dans la réponse prédite d’un modèle et la façon dont elles s’intègrent naturellement | Oui | question, réponse (sans vérité de base ni de contexte) | 1 à 5, avec 1 = pire et 5 = meilleur |
| Évaluation de la fluidité des questions-réponses | Maîtrise | Mesure la justesse grammaticale et linguistique de la réponse prédite du modèle | Oui | question, réponse (sans vérité de base ni de contexte) | 1 à 5, avec 1 = pire et 5 = meilleur |
| Évaluation des scores F1 des questions-réponses | Score F1 | Mesure le ratio du nombre de mots partagés entre la prédiction du modèle et la vérité terrain | Non | question, réponse, vérité de base (contexte non nécessaire) | Dans la plage [0, 1] |
| Évaluation de la similarité des questions-réponses Ada | Similarité Ada | Calcule les incorporations au niveau de la phrase (document) à l’aide de l’API d’incorporations Ada pour la vérité terrain et la prédiction, puis calcule la similarité cosinus entre elles (un nombre à virgule flottante) | Oui | question, réponse, vérité de base (contexte non nécessaire) | Dans la plage [0, 1] |
Améliorer les performances de flux
Si votre exécution échoue, vérifiez les données de sortie et de journaux, et déboguez toute échec du flux. Pour corriger le flux ou améliorer les performances, essayez de modifier la requête de flux, le message système, les paramètres de flux ou la logique de flux.
Ingénierie d’invite
La construction de l’invite peut être difficile. Pour en savoir plus sur les concepts de construction des requêtes, consultez Vue d’ensemble des requêtes. Pour découvrir comment créer une requête qui peut vous aider à atteindre vos objectifs, consultez Techniques d’ingénierie de requête.
Message système
Vous pour utiliser le message système, parfois appelé méta-requête ou requête système, pour guider le comportement d’un système d’IA et améliorer les performances du système. Pour savoir comment améliorer les performances de votre flux avec des messages système, consultez Création pas à pas de messages système.
Jeux de données en or
La création d’un copilote qui utilise des LLM implique généralement de baser le modèle sur la réalité à l’aide de jeux de données sources. Un jeu de données en orvous permet de veiller à ce que les modèles LLM fournissent les réponses les plus justes et les plus utiles aux requêtes des clients.
Un jeu de données en or est une collection de questions réalistes des clients et de réponses conçues par des experts qui sert d’outil d’assurance qualité pour les LLM utilisés par votre copilote. Les jeux de données en or ne sont pas utilisés pour entraîner un LLM ou injecter un contexte dans une requête LLM, mais pour évaluer la qualité des réponses générées par le LLM.
Si votre scénario implique un copilote ou si vous créez votre propre copilote, consultez Production de jeux de données en or pour obtenir des conseils détaillés et connaître les meilleures pratiques.