Conseils pour la résolution des problèmes
Cet article traite des questions fréquentes concernant l’utilisation du flux d’invite.
Problèmes liés à la création de flux
L’erreur « L’outil de package est introuvable » se produit lorsque vous mettez à jour le flux pour une expérience orientée code
Lorsque vous mettez à jour des flux pour une première expérience du code, si le flux a utilisé les outils (Recherche d’index Faiss, Recherche d’index vectoriel, Recherche de base de données vectorielle, Sécurité de contenu (Texte)), vous pourriez rencontrer le message d’erreur suivant :
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
Pour résoudre le problème, vous avez deux options :
Option 1
Mettez à jour votre session de calcul vers la dernière version de l’image de base.
Sélectionnez le mode Fichier brut pour basculer vers l’affichage de code brut. Ouvrez ensuite le fichier flow.dag.yaml.

Mettre à jour les noms des outils.
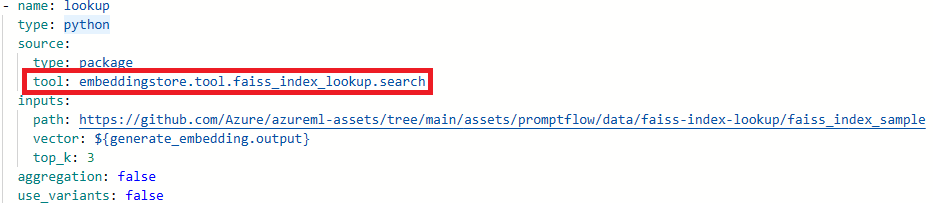
Outil Nouveau nom de l’outil Recherche d’index Faiss promptflow_vectordb.tool.faiss_index_lookup.FaissIndexLookup.search Recherche d’index vectoriel promptflow_vectordb.tool.vector_index_lookup.VectorIndexLookup.search Recherche de base de données vectorielle promptflow_vectordb.tool.vector_db_lookup.VectorDBLookup.search Sécurité de contenu (texte) content_safety_text.tools.content_safety_text_tool.analyze_text Enregistrez le fichier flow.dag.yaml.
Option 2 :
- Mettez à jour votre session de calcul vers la dernière version de l’image de base
- Supprimez l’ancien outil et recréez un nouvel outil.
Erreur « Aucun fichier ou répertoire de ce type »
Le flux d’invite s’appuie sur un stockage de partage de fichiers pour stocker une capture instantanée du flux. Si le stockage de partage de fichiers présente un problème, vous pourriez rencontrer l’incident suivant. Voici quelques solutions de contournement que vous pouvez essayer :
Si vous utilisez un compte de stockage privé, consultez Isolement réseau dans le flux d’invite pour vous assurer que votre espace de travail peut accéder à votre compte de stockage.
Si le compte de stockage est activé pour l’accès public, vérifiez s’il y a un magasin de données nommé
workspaceworkingdirectorydans votre espace de travail. Il doit s’agir d’un type de partage de fichiers.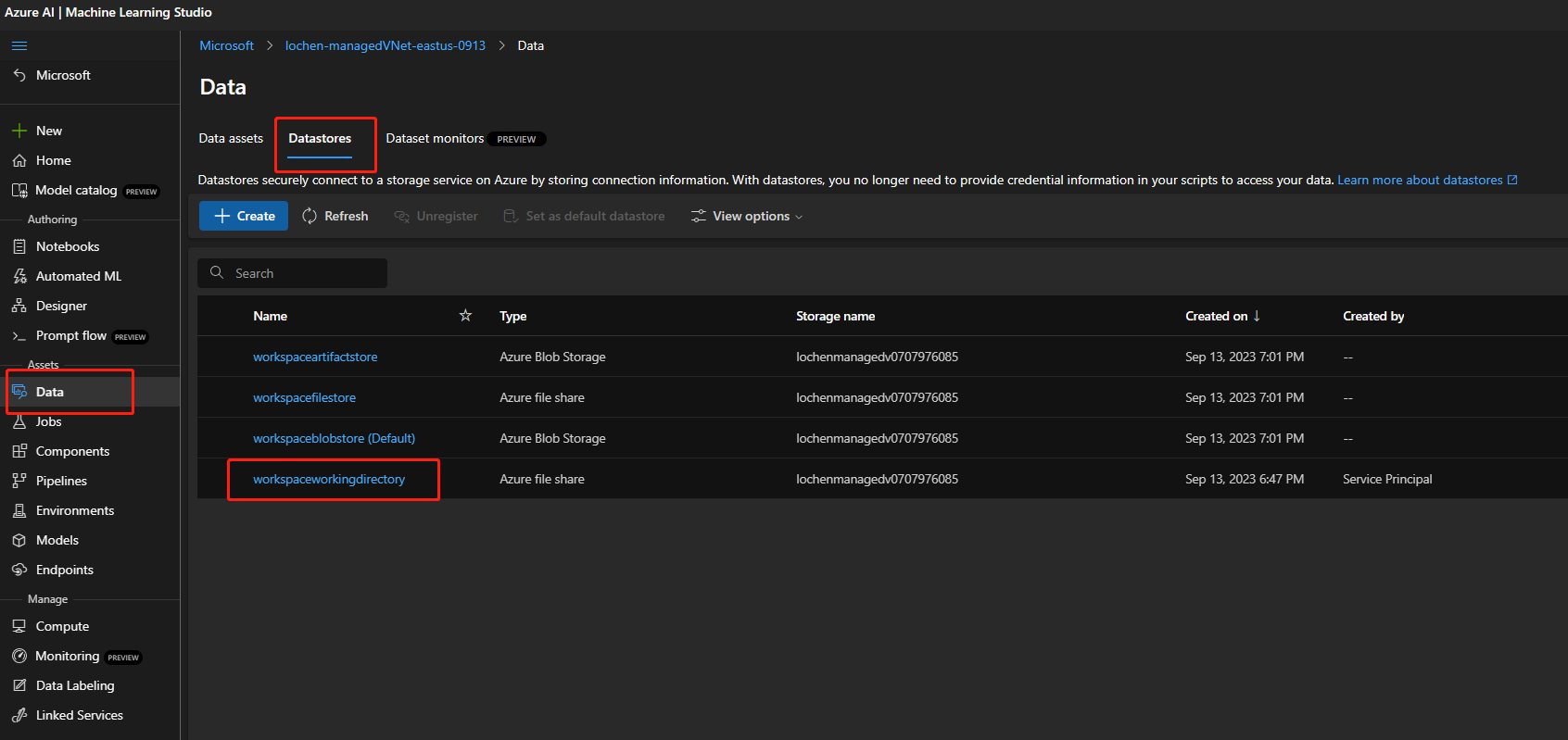
- Si vous n’avez pas obtenu ce magasin de données, vous devez l’ajouter à votre espace de travail.
- Créez un partage de fichiers avec le nom
code-391ff5ac-6576-460f-ba4d-7e03433c68b6. - Créez un magasin de données avec le nom
workspaceworkingdirectory. Consultez Créer des magasins de données.
- Créez un partage de fichiers avec le nom
- Si vous avez un magasin de données
workspaceworkingdirectory, mais que son type estblobau lieu defileshare, créez un espace de travail. Utilisez le stockage qui n’active pas les espaces de noms hiérarchiques pour Azure Data Lake Storage Gen2 comme compte de stockage par défaut d’espace de travail. Pour plus d’informations, consultez Créer un espace de travail.
- Si vous n’avez pas obtenu ce magasin de données, vous devez l’ajouter à votre espace de travail.

Flux manquant

Plusieurs raisons peuvent expliquer ce problème :
Si l’accès public à votre compte de stockage est désactivé, vous devez garantir l’accès en ajoutant votre adresse IP au pare-feu de stockage ou en activant l’accès via un réseau virtuel disposant d’un point de terminaison privé connecté au compte de stockage.
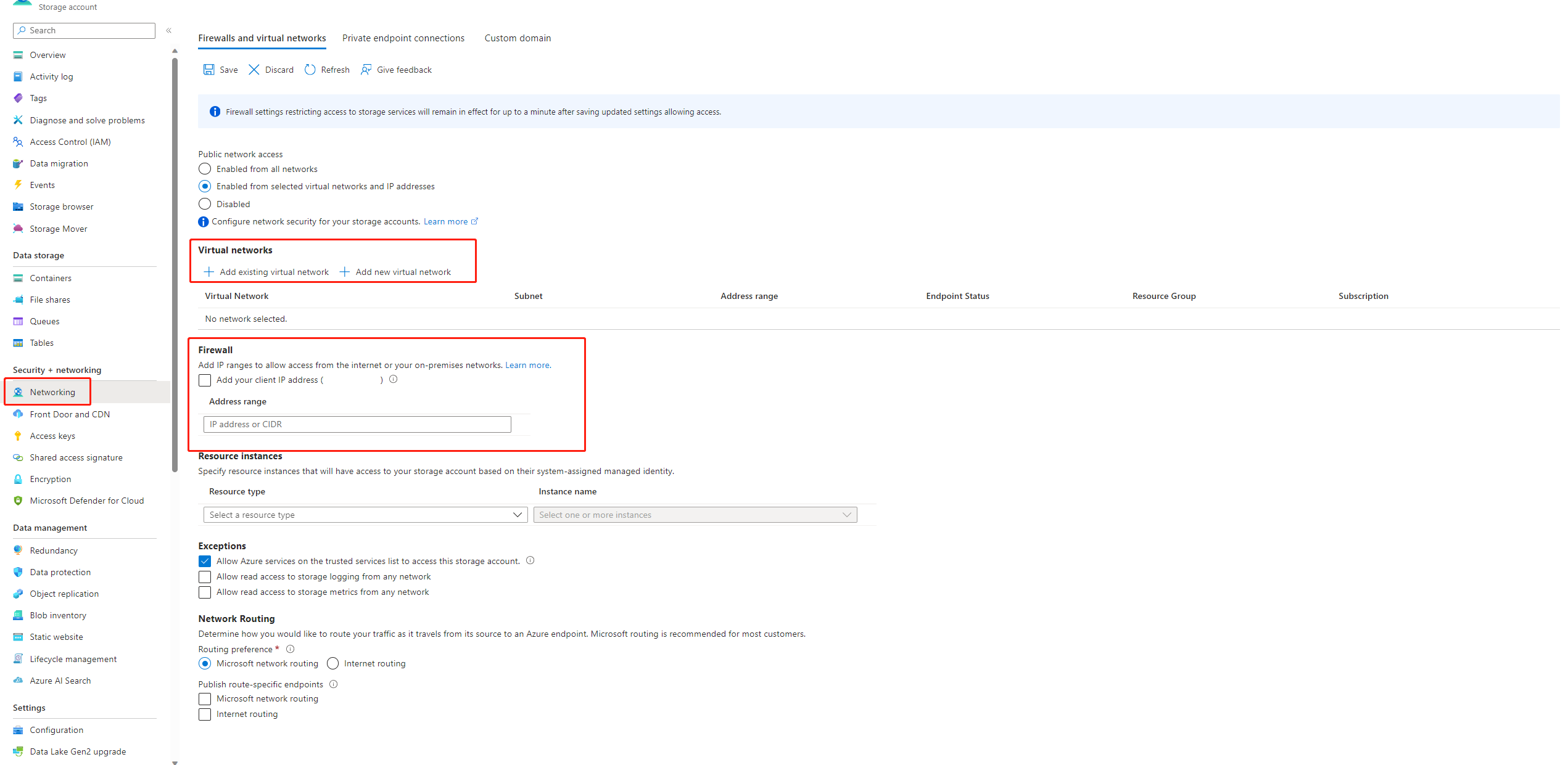
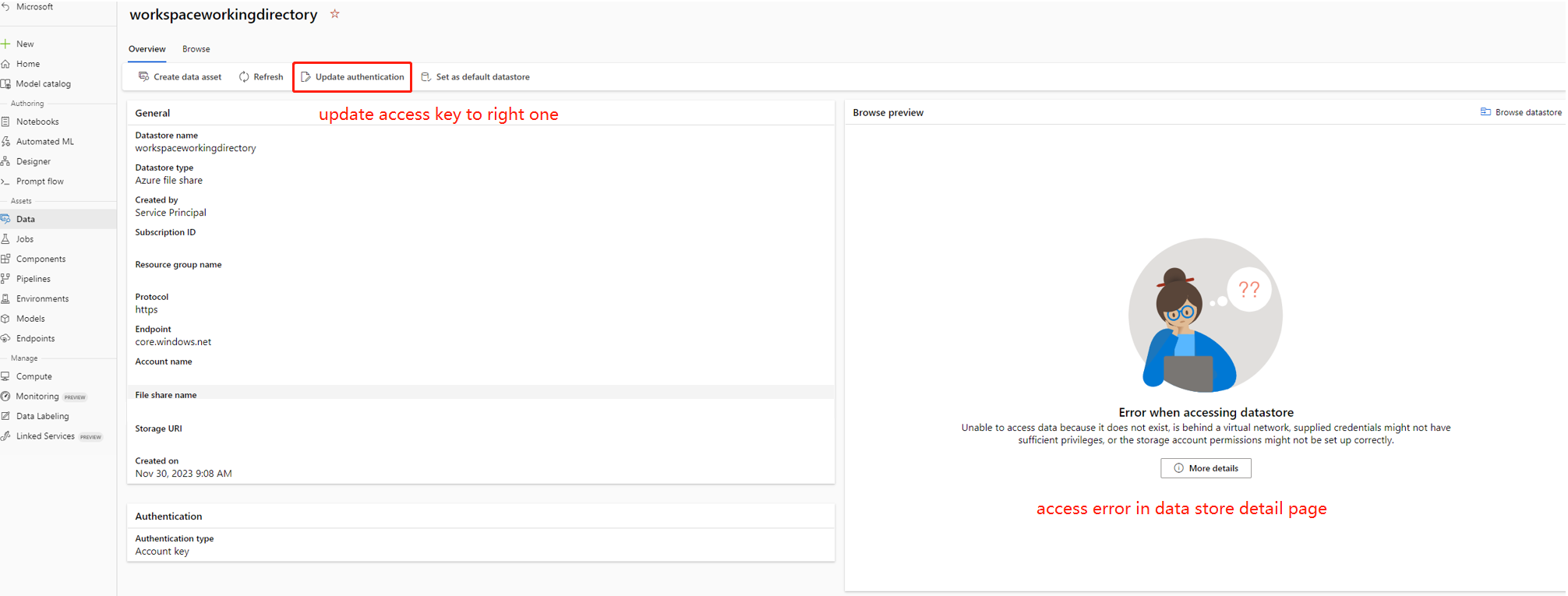
Il existe certains cas, la clé de compte dans le magasin de données n’est pas synchronisée avec le compte de stockage, vous pouvez essayer de mettre à jour la clé de compte dans la page de détails du magasin de données pour résoudre ce problème.
Si vous utilisez AI Studio, le compte de stockage doit définir CORS pour autoriser AI Studio à accéder au compte de stockage, sinon, vous voyez le problème de flux manquant. Vous pouvez ajouter les paramètres CORS suivants au compte de stockage pour résoudre ce problème.
- Accédez à la page du compte de stockage, sélectionnez
Resource sharing (CORS)soussettings, puis sélectionnez l’ongletFile service. - Origines autorisées :
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - Méthodes autorisées :
DELETE, GET, HEAD, POST, OPTIONS, PUT
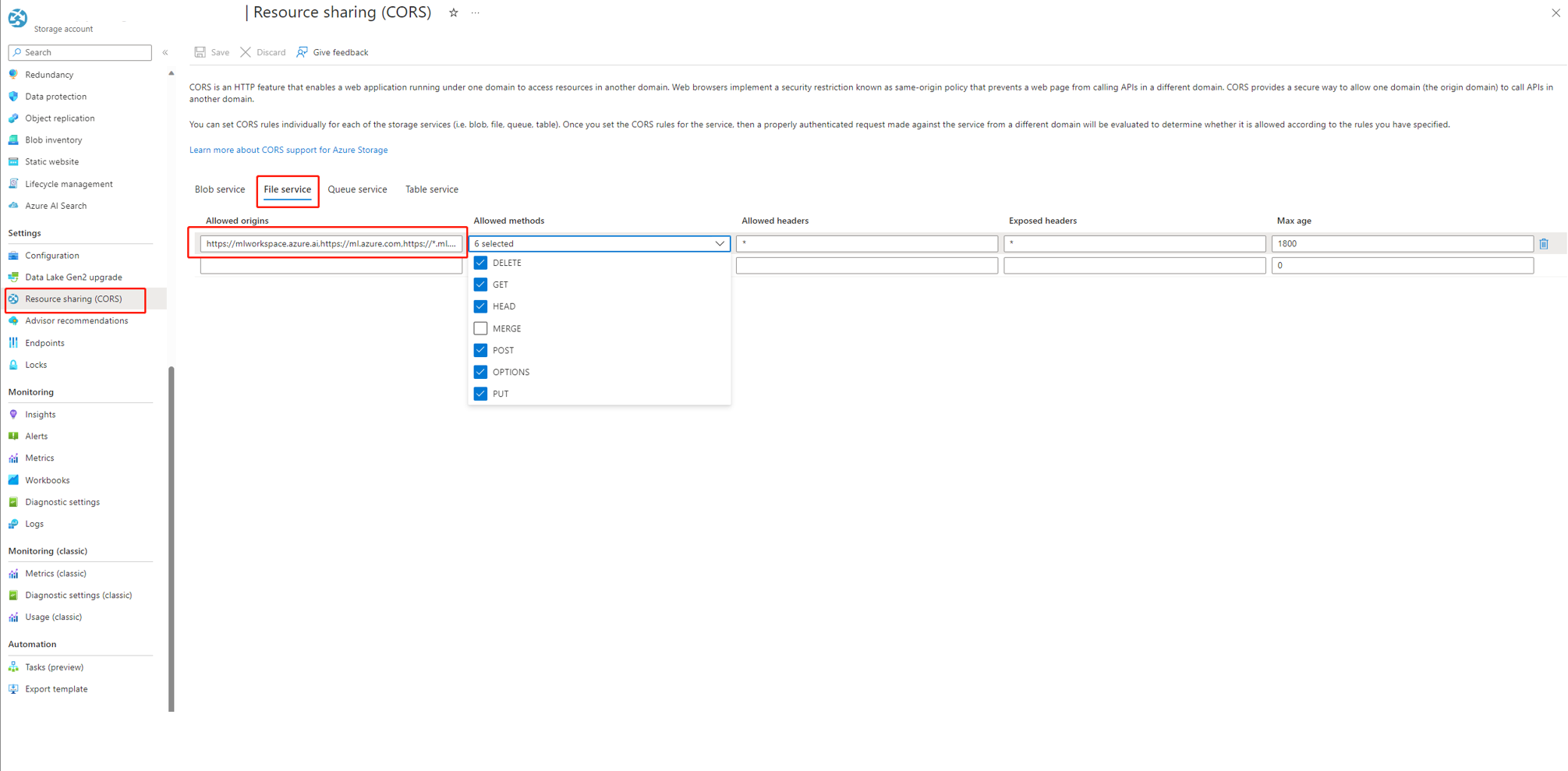
- Accédez à la page du compte de stockage, sélectionnez



Problèmes liés à la session de calcul
L’exécution a échoué car « Aucun module nommé XXX »
Ce type d’erreur lié à la session de calcul n’a pas les packages requis. Si vous utilisez un environnement par défaut, vérifiez que l’image de votre session de calcul utilise la dernière version. Si vous utilisez une image de base personnalisée, vérifiez que vous avez installé tous les packages requis dans votre contexte Docker. Pour plus d’informations, consultez Personnaliser l’image de base pour la session de calcul.
Où trouver l’instance serverless utilisée par la session de calcul ?
Vous pouvez afficher l’instance serverless utilisée par la session de calcul dans l’onglet de liste des sessions de calcul sous la page de calcul. En savoir plus sur Comment gérer les instances serverless.
Échecs de session de calcul utilisant une image de base personnalisée
Échec de démarrage de la session de calcul avec requirements.txt ou une image de base personnalisée
Prise en charge de session de calcul pour utiliser requirements.txt ou une image de base personnalisée dans flow.dag.yaml pour personnaliser l’image. Nous vous recommandons d’utiliser requirements.txt pour le cas courant, qui utilisera pip install -r requirements.txt pour installer les packages. Si vous avez une dépendance supérieure à celle des packages Python, vous devez suivre Personnaliser l’image de base pour créer une nouvelle base d’images en plus de l’image de base de flux d’invite. Utilisez-la ensuite dans flow.dag.yaml. En savoir plus sur Comment spécifier une image de base dans la session de calcul.
- Vous ne pouvez pas utiliser d’image de base arbitraire pour créer une session de calcul, vous devez utiliser l’image de base fourni par flux d’invite.
- N’épinglez pas la version de
promptflowetpromptflow-toolsdansrequirements.txt, car nous les incluons déjà dans l’image de base. L’utilisation de l’ancienne version depromptflowet depromptflow-toolspeut entraîner un comportement inattendu.
Problèmes liés à l’exécution du flux
Comment trouver les entrées et sorties brutes de l’outil LLM pour une investigation plus approfondie ?
Dans le flux d’invite, sur la page de flux avec une exécution réussie et une page de détails d’exécution, vous pouvez trouver les entrées et sorties brutes de l’outil LLM dans la section de sortie. Sélectionnez le bouton view full output pour afficher la sortie complète.

La section Trace inclut chaque demande et réponse à l’outil LLM. Vous pouvez vérifier le message brut envoyé au modèle LLM et la réponse brute du modèle LLM.

Comment corriger l’erreur 409 d’Azure OpenAI ?
Vous pouvez rencontrer une erreur 409 d’Azure OpenAI, cela signifie que vous avez atteint la limite de débit d’Azure OpenAI. Vous pouvez vérifier le message d’erreur dans la section sortie du nœud LLM. En savoir plus sur la Limite de débit d’Azure OpenAI.

Identifier le nœud le plus gourmand en temps
Vérifiez les journaux de session de calcul.
Essayez de trouver le format de journal d’avertissement suivant :
{node_name} s’exécute depuis {duration} secondes.
Par exemple :
Cas 1 : le nœud de script Python s’exécute pendant longtemps.

Dans ce cas, vous pouvez constater que
PythonScriptNodeétait en cours d’exécution pendant une longue période (près de 300 secondes). Vous pouvez ensuite vérifier les détails du nœud pour découvrir quel est le problème.cas 2 : le nœud LLM s’exécute pendant longtemps.
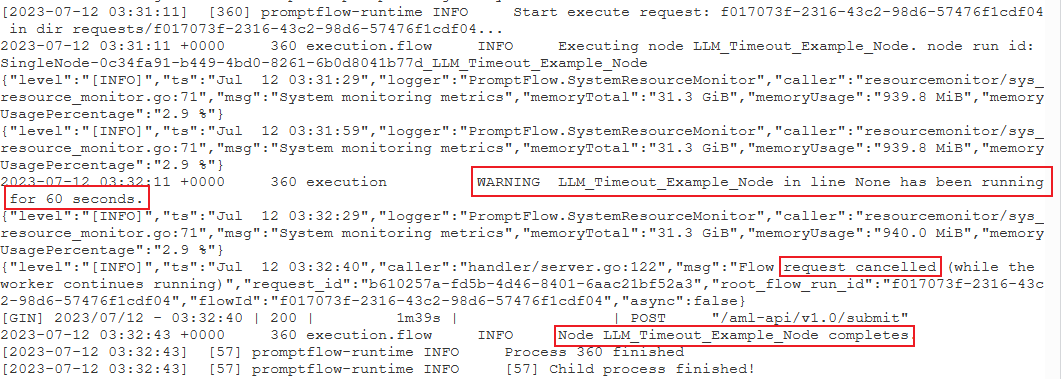
Dans ce cas, si vous trouvez le message
request canceleddans les journaux, cela peut être dû au fait que l’appel d’API OpenAI prend trop de temps et dépasse la limite de délai d’expiration.Un délai d’expiration de l’API OpenAI peut être dû à un problème de réseau ou à une requête complexe qui nécessite plus de temps de traitement. Pour plus d’informations, consultez Délai d’expiration de l’API OpenAI.
Attendez quelques secondes et réessayez votre requête. Cette action résout généralement tous les problèmes de réseau.
Si la nouvelle tentative ne fonctionne pas, vérifiez si vous utilisez un modèle à contexte long, tel que
gpt-4-32k, et si vous avez défini une valeur élevée pourmax_tokens. Dans ce cas, le comportement est attendu, car votre invite peut générer une réponse longue qui prend plus de temps que le seuil supérieur du mode interactif. Dans ce cas, nous vous recommandons d’essayerBulk test, car ce mode n’a pas de paramètre de délai d’expiration.
Si vous ne trouvez rien dans les journaux qui indique qu’il s’agit d’un problème de nœud spécifique :
- Contactez l’équipe du flux d’invite (promptflow-eng) en partageant les journaux. Nous essayons d’identifier la cause racine.


Problèmes liés au déploiement de flux
Absence d’autorisation pour effectuer l’action « Microsoft.MachineLearningService/workspaces/datastores/read »
Si votre flux contient l’outil Recherche d’index, après le déploiement du flux, il faut que le point de terminaison puisse accéder au magasin de données de l’espace de travail pour lire le fichier yaml MLIndex ou le dossier FAISS contenant des blocs et des incorporations. Par conséquent, vous devez accorder manuellement l’autorisation d’identité de point de terminaison.
Vous pouvez accorder l’autorisation d’identité de point de terminaison AzureML Data Scientist sur l’étendue de l’espace de travail ou définir un rôle personnalisé qui contient l’action « MachineLearningService/workspace/workspace/datastore/reader ».
Problème de délai d’expiration de la demande en amont lors de la consommation du point de terminaison
Si vous utilisez l’interface CLI ou le Kit de développement logiciel (SDK) pour déployer le flux, vous risquez de rencontrer une erreur de délai d’expiration. Par défaut, le request_timeout_ms est 5000. Vous pouvez spécifier au maximum 5 minutes, soit 300 000 ms. Voici un exemple montrant comment spécifier le délai d’expiration de la requête dans le fichier yaml de déploiement. Pour plus d’informations, consultez schéma de déploiement.
request_settings:
request_timeout_ms: 300000
L’API OpenAI rencontre une erreur d’authentification
Si vous régénérez votre clé Azure OpenAI et mettez à jour manuellement la connexion utilisée dans le flux d’invite, vous pouvez rencontrer des erreurs telles que « Non autorisé. Le jeton d’accès est manquant, non valide, l’audience est incorrecte ou a expiré. » lors de l’appel d’un point de terminaison existant créé avant la régénération de la clé.
Cela est dû au fait que les connexions utilisées dans les points de terminaison/déploiements ne seront pas automatiquement mises à jour. Toute modification de clé ou de secrets dans les déploiements doit être effectuée par une mise à jour manuelle afin que le déploiement de production en ligne ne puisse pas être impacté par une opération hors connexion involontaire.
- Si le point de terminaison a été déployé dans l’interface utilisateur studio, vous pouvez simplement redéployer le flux vers le point de terminaison existant à l’aide du même nom de déploiement.
- Si le point de terminaison a été déployé à l’aide du Kit de développement logiciel (SDK) ou de l’interface CLI, vous devez apporter une modification à la définition de déploiement, comme l’ajout d’une variable d’environnement factice, puis utiliser
az ml online-deployment updatepour mettre à jour votre déploiement.
Problèmes de vulnérabilité dans les déploiements de flux d’invite
Pour les vulnérabilités liées au runtime de flux d’invite, voici des approches qui peuvent vous aider à les atténuer :
- Mettez à jour les packages de dépendance dans les spécifications.txt de votre dossier de flux.
- Si vous utilisez une image de base personnalisée pour votre flux, vous devez mettre à jour le runtime de flux d’invite vers la dernière version et régénérer votre image de base, puis redéployer le flux.
Pour toutes les autres vulnérabilités des déploiements en ligne managés, Azure Machine Learning résout les problèmes de manière mensuelle.
« Erreur MissingDriverProgram » ou « Impossible de trouver le programme de pilote dans la requête »
Si vous déployez votre flux et que vous rencontrez l’erreur suivante, cela peut être lié à l’environnement de déploiement.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
Il existe deux façons de corriger cette erreur.
(Recommandé) Vous pouvez trouver l’URI d’image conteneur sur la page de détails de votre environnement personnalisé et le définir comme image de base de flux dans le fichier flow.dag.yaml. Lorsque vous déployez le flux dans l’interface utilisateur, vous sélectionnez simplement Utiliser l’environnement de la définition du flux actuel, et le service back-end crée l’environnement personnalisé basé sur cette image de base et
requirement.txtpour votre déploiement. En savoir plus sur l’environnement spécifié dans la définition de flux.
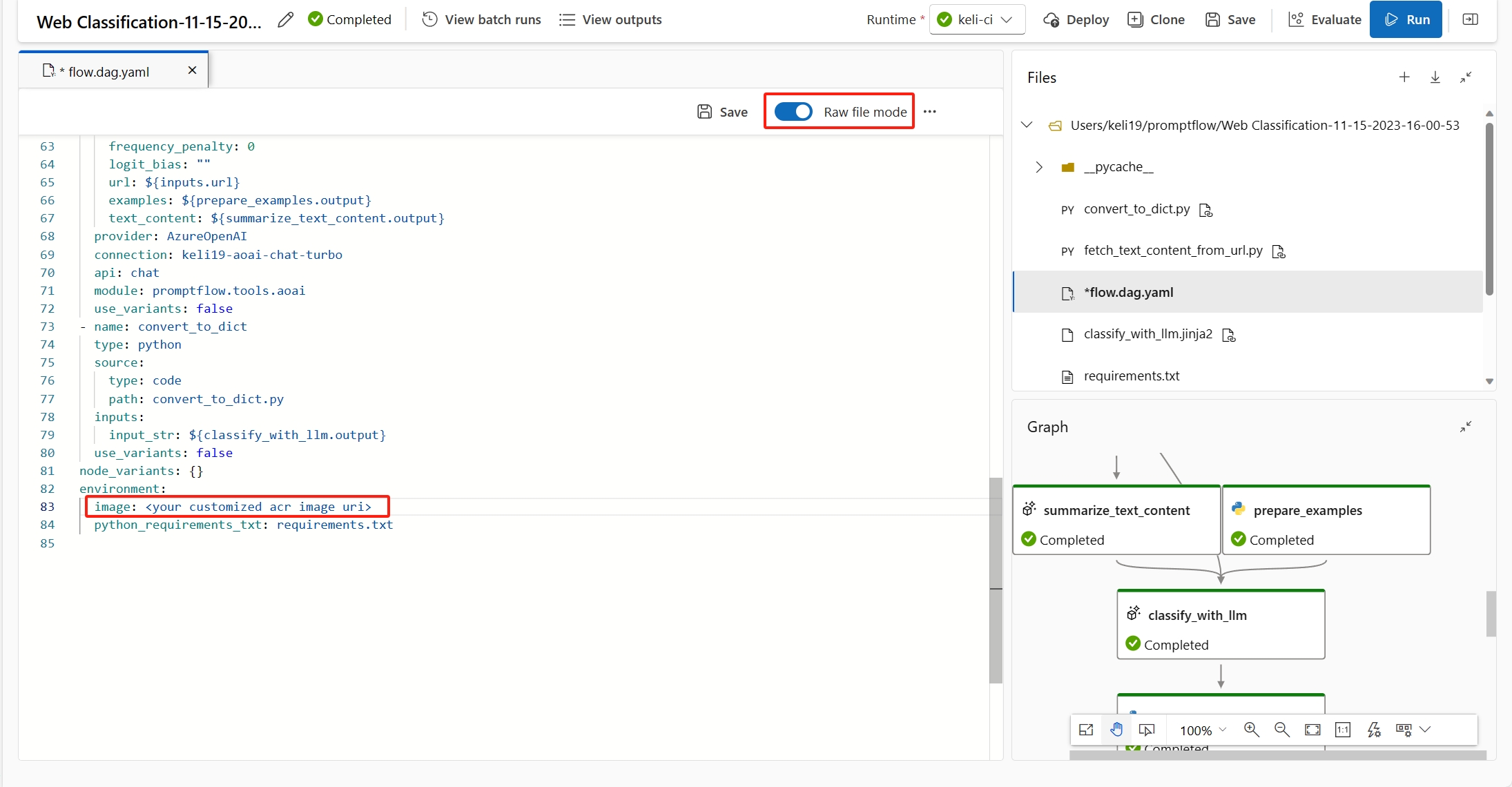
Vous pouvez corriger cette erreur en ajoutant
inference_configdans votre définition d’environnement personnalisée.Voici un exemple de définition d’environnement personnalisée.


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
La réponse du modèle prend trop de temps
Vous remarquerez probablement que le déploiement met parfois trop de temps à répondre. Cela se produit lorsque plusieurs facteurs potentiels entrent en jeu.
- Le modèle utilisé dans le flux n’est pas suffisamment puissant (exemple : utiliser GPT 3.5 au lieu de text-ada)
- La requête d’index n’est pas optimisée et prend trop de temps
- Le flux comporte de nombreuses étapes à traiter
Envisagez d’optimiser le point de terminaison avec les considérations ci-dessus afin d’améliorer les performances du modèle.
Impossible d’extraire le schéma de déploiement
Après avoir déployé le point de terminaison, vous pouvez le tester sous l’onglet Test de la page de détails du point de terminaison. Si l’onglet Test affiche Impossible d’extraire le schéma de déploiement, vous pouvez essayer les deux méthodes suivantes pour atténuer ce problème :

- Vérifiez que vous avez accordé l’autorisation correcte à l’identité du point de terminaison. En savoir plus sur l’octroi d’autorisations à l’identité du point de terminaison.
- C’est peut-être parce que vous avez exécuté votre flux dans une ancienne version du runtime, puis déployé le flux. Dans ce cas, le déploiement a utilisé l’environnement du runtime qui était également dans l’ancienne version. Pour mettre à jour le runtime, suivez Mettre à jour un runtime sur l’interface utilisateur et réexécutez le flux dans le dernier runtime, puis redéployez le flux.
Accès refusé à la liste secrète de l’espace de travail
Si vous rencontrez une erreur telle que « Accès refusé à la liste des secrets de l’espace de travail », vérifiez que vous avez accordé l’autorisation appropriée à l’identité du point de terminaison. En savoir plus sur l’octroi d’autorisations à l’identité du point de terminaison.
Problèmes liés à l’authentification et à l’identité
Comment faire pour utiliser un magasin de données sans identifiants d’identification dans un flux rapide ?
Pour utiliser le stockage sans informations d’identification dans Azure AI Studio. Pour ce faire, procédez comme suit :
- Remplacez le type d’authentification du magasin de données par Aucun.
- Accordez l’autorisation de contributeur de données de fichier/blob de projet sur le stockage.
Changer la valeur du type d’authentification du magasin de données en Aucun
Vous pouvez suivre l’authentification des données basée sur l’identité pour réduire les informations d’identification de votre magasin de données.
Vous devez modifier le type d’authentification du magasin de données sur None, qui signifie meid_token authentification basée sur l’authentification. Vous pouvez apporter des modifications à partir de la page de détails du magasin de données ou de l’interface CLI/SDK : https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

Pour le magasin de données basé sur des objets blob, vous pouvez modifier le type d’authentification et permettre également à l’espace de travail MSI d’accéder au compte de stockage.

Pour le magasin de données basé sur le partage de fichiers, vous pouvez uniquement modifier le type d’authentification.

Accorder une autorisation à une identité de l’utilisateur ou à une identité managée
Pour utiliser le magasin de données sans informations d’identification dans le flux d’invite, vous devez accorder suffisamment d’autorisations à l’identité de l’utilisateur ou à l’identité managée pour accéder au magasin de données.
- Assurez-vous que l’identité managée affectée par le système d’espace de travail dispose
Storage Blob Data ContributoretStorage File Data Privileged Contributorsur le compte de stockage, au moins besoin d’une autorisation de lecture/écriture (mieux également inclure la suppression). - Si vous utilisez l’identité utilisateur, cette option par défaut dans le flux d’invite doit vous assurer que l’identité de l’utilisateur a le rôle suivant sur le compte de stockage :
Storage Blob Data Contributorsur le compte de stockage, au moins besoin d’une autorisation de lecture/écriture (mieux également inclure la suppression).Storage File Data Privileged Contributorsur le compte de stockage, au moins besoin d’une autorisation de lecture/écriture (mieux également inclure la suppression).
- Si vous utilisez l’identité managée affectée par l’utilisateur, vous devez vérifier que l’identité managée a le rôle suivant sur le compte de stockage :
Storage Blob Data Contributorsur le compte de stockage, au moins besoin d’une autorisation de lecture/écriture (mieux également inclure la suppression).Storage File Data Privileged Contributorsur le compte de stockage, au moins besoin d’une autorisation de lecture/écriture (mieux également inclure la suppression).- Pendant ce temps, vous devez attribuer un rôle d’identité
Storage Blob Data Readutilisateur au compte de stockage au moins, si vous souhaitez utiliser le flux d’invite pour créer et tester le flux.
- Si vous ne pouvez toujours pas afficher la page de détails du flux et que la première fois que vous utilisez le flux d’invite est antérieure à 2024-01-01, vous devez accorder à l’espace de travail MSI comme
Storage Table Data Contributorcompte de stockage lié à l’espace de travail.