Indexer des données de fichiers et de raccourcis OneLake
Dans cet article, découvrez comment configurer un indexeur de fichiers OneLake pour extraire les données et métadonnées pouvant faire l’objet d’une recherche d’un lakehouse sur OneLake.
Utilisez cet indexeur pour effectuer les tâches suivantes :
- Indexation de données et indexation incrémentielle : L’indexeur peut indexer les fichiers et les métadonnées associées à partir de chemins de données dans un lakehouse. Il détecte les fichiers et métadonnées nouveaux et mis à jour par le biais d’une détection intégrée des modifications. Vous pouvez configurer l’actualisation des données selon une planification ou à la demande.
- Détection de suppression : L’indexeur peut détecter les suppressions via des métadonnées personnalisées pour la plupart des fichiers et raccourcis. Cela nécessite l’ajout de métadonnées aux fichiers pour indiquer qu’ils ont été « supprimés de manière réversible », ce qui permet leur suppression de l’index de recherche. Actuellement, il n’est pas possible de détecter les suppressions dans des fichiers de raccourcis Google Cloud Storage ou Amazon S3, car les métadonnées personnalisées ne sont pas prises en charge pour ces sources de données.
- IA appliquée via des ensembles de compétences :Les ensembles de compétences sont entièrement pris en charge par l’indexeur de fichiers OneLake. Il s’agit notamment de fonctionnalités clés telles que la vectorisation intégrée qui ajoute des étapes de segmentation et d’intégration des données.
- Modes d’analyse : L’indexeur prend en charge les modes d’analyse JSON si vous souhaitez analyser des tableaux ou des lignes JSON dans des documents individuels de recherche.
- Compatibilité avec d’autres fonctionnalités : L’indexeur OneLake est conçu pour fonctionner en toute transparence avec d’autres fonctionnalités d’indexeur, telles que les sessions de débogage, le cache d’indexeur des enrichissements incrémentiels et la base de connaissances.
Utiliser l’API REST 2024-05-01-préversion, un package contenant un kit de développement logiciel (SDK) Azure bêta ou Importer et vectoriser des données dans le portail Azure pour indexer à partir de OneLake.
Cet article utilise les API REST pour illustrer chaque étape.
Prérequis
Un espace de travail Fabric. Suivez ce tutoriel pour créer un espace de travail Fabric.
Lakehouse dans un espace de travail Fabric. Suivez ce tutoriel pour créer un lakehouse.
Données textuelles. Si vous avez des données binaires, vous pouvez utiliser l’analyse d’image de l’enrichissement par IA pour extraire du texte ou générer des descriptions d’images. Le contenu d’un fichier ne doit pas dépasser les limites de l’indexeur de votre niveau de service de recherche.
Contenu dans l’emplacement Files de votre lakehouse. Vous pouvez ajouter des données en effectuant les points suivants :
- Charger directement dans un lakehouse
- Utiliser les pipelines de données de Microsoft Fabric
- Ajouter des raccourcis de sources de données externes telles que Amazon S3 ou Google Cloud Storage.
Un service de recherche IA configuré pour une identité managée affectée par le système ou par l’utilisateur(-trice). Le service de recherche IA doit résider dans le même locataire que l’espace de travail Microsoft Fabric.
Attribution de rôle Contributeur dans l’espace de travail Microsoft Fabric où se trouve le lakehouse. Les étapes sont décrites dans la section Octroyer des autorisations de cet article.
Un Client REST permettant de formuler des appels REST semblables à ceux présentés dans cet article.
Formats de document pris en charge
L’indexeur de fichiers OneLake peut extraire du texte à partir des formats de document suivants :
- CSV (consultez Indexation d’objets blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (consultez l’indexation d’objets JSON blobs)
- KML (XML pour les représentations géographiques)
- Formats Microsoft Office : DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (e-mails Outlook), XML (XML WORD 2003 et 2006)
- Formats de document ouverts : ODT, ODS, ODP
- Fichiers de texte brut (voir aussi l’indexation de texte brut)
- RTF
- XML
- ZIP
Raccourcis pris en charge
Les raccourcis OneLake suivants sont pris en charge par l’indexeur de fichiers OneLake :
Raccourci OneLake (raccourci vers une autre instance OneLake)
Limites de cette préversion
Les types de fichiers Parquet (y compris Parquet Delta) ne sont actuellement pas pris en charge.
La suppression de fichiers n’est pas prise en charge pour les raccourcis Amazon S3 et Google Cloud Storage.
Cet indexeur ne prend pas en charge le contenu de l’emplacement de la table de l’espace de travail OneLake.
Cet indexeur ne prend pas en charge les requêtes SQL, mais la requête utilisée dans la configuration de la source de données consiste exclusivement à ajouter le dossier ou le raccourci auxquels vous souhaitez accéder.
Il n’existe aucune prise en charge de l’ingestion de fichiers de Mon espace de travail dans OneLake, car il s’agit d’un référentiel personnel par utilisateur.
Préparer l’indexation des données
Avant de configurer l’indexation, passez en revue vos données sources pour déterminer si des changements doivent être effectués. Un indexeur peut indexer le contenu d’un conteneur à la fois. Par défaut, tous les fichiers du conteneur sont traités. Vous avez plusieurs options pour un traitement plus sélectif :
Placez les fichiers dans un dossier virtuel. La définition d’une source de données d’indexeur inclut un paramètre « requête » qui peut être un sous-dossier ou un raccourci de lakehouse. Si cette valeur est spécifiée, seuls les fichiers de ce sous-dossier ou de ce raccourci au sin du lakehouse sont indexés.
Inclure ou exclure des fichiers par type de fichier. La liste des formats de documents pris en charge peut vous aider à déterminer les fichiers à exclure. Par exemple, vous pouvez exclure des fichiers image ou audio qui ne fournissent pas de texte pouvant faire l’objet d’une recherche. Cette fonctionnalité est contrôlée par les paramètres de configuration de l’indexeur.
Inclure ou exclure des fichiers arbitraires. Si vous voulez ignorer un fichier spécifique pour une raison quelconque, vous pouvez ajouter les propriétés et valeurs des métadonnées aux fichiers du lakehouse Onelake. Quand un indexeur rencontre ces propriétés, il ignore le fichier ou son contenu dans l’exécution de l’indexation.
L’inclusion et l’exclusion de fichiers est abordée dans l’étape de configuration de l’indexeur. Si vous ne configurez pas de critères, l’indexeur signale les fichiers inéligibles comme des erreurs et continue son travail. Si trop d’erreurs se produisent, le traitement peut s’arrêter. Vous pouvez spécifier une tolérance d’erreurs dans les paramètres de configuration de l’indexeur.
Un indexeur crée généralement un document de recherche par fichier, dans lequel le contenu texte et les métadonnées sont capturés sous forme de champs pouvant faire l’objet d’une recherche dans un index. Si les fichiers sont des fichiers entiers, vous pouvez éventuellement les décomposer en plusieurs documents de recherche. Par exemple, vous pouvez analyser les lignes d’un fichier CSV pour créer un document de recherche par ligne. Si vous devez segmenter un document unique en passages plus petits pour vectoriser les données, envisagez d’utiliser la vectorisation intégrée.
Indexation des métadonnées de fichier
Les métadonnées de fichier peuvent également être indexées, ce qui est pratique si vous pensez que l’une des propriétés des métadonnées standard ou personnalisées est utile dans les filtres et requêtes.
Les propriétés de métadonnées spécifiées par l’utilisateur sont extraites mot pour mot. Pour recevoir les valeurs, vous devez définir le champ dans l’index de recherche de type Edm.String, avec le même nom que la clé de métadonnées du blob. Par exemple, si un blob a une clé de métadonnées de Priority avec la valeur High, vous devez définir un champ nommé Priority dans votre index de recherche et il sera rempli avec la valeur High.
Les propriétés de métadonnées d’un fichier standard peuvent être extraites dans des champs de même nom et de même type, comme indiqué ci-dessous. L’indexeur de fichiers OneLake crée automatiquement des mappages de champs internes de ces propriétés de métadonnées, en convertissant le nom original avec traits d’union (« metadata-storage-name ») en un nom équivalent avec traits de soulignement (« metadata_storage_name »).
Vous devez toujours ajouter les champs avec traits de soulignement à la définition de l’index, mais vous pouvez omettre les mappages de champs de l’indexeur, car l’indexeur fait automatiquement l’association.
metadata_storage_name (
Edm.String) : le nom du fichier. Par exemple, si vous disposez d’un fichier /mydatalake/my-folder/subfolder/resume.pdf, la valeur de ce champ estresume.pdf.metadata_storage_path (
Edm.String) : URI complet du blob, incluant le compte de stockage. Par exemple,https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) : type de contenu tel que spécifié par le code que vous avez utilisé pour charger le blob. Par exemple :application/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset) : horodatage de la dernière modification du blob. Recherche Azure AI utilise cet horodatage pour identifier les objets blob modifiés, afin d’éviter une réindexation complète après l’indexation initiale.metadata_storage_size (
Edm.Int64) : taille du blob en octets.metadata_storage_content_md5 (
Edm.String) : code de hachage MD5 du contenu du blob s’il est disponible.
Enfin, toutes les propriétés des métadonnées spécifiques au format de document des fichiers que vous indexez peuvent également être représentées dans le schéma d’index. Pour plus d’informations sur les métadonnées spécifiques au contenu, consultez Propriétés des métadonnées de contenu.
Il est important de souligner que vous n’avez pas besoin de définir les champs relatifs à chacune des propriétés ci-dessus dans votre index de recherche. Il vous suffit de capturer les propriétés dont vous avez besoin pour votre application.
Accorder des autorisations
L’indexeur OneLake utilise l’authentification par jeton et l’accès en fonction du rôle pour les connexions à OneLake. Autorisations attribuées dans OneLake. Il n’y a aucune exigence d’autorisation sur les magasins de données physiques qui sauvegardent les raccourcis. Par exemple, si vous indexez à partir d’AWS, vous n’avez pas besoin d’octroyer des autorisations de service de recherche dans AWS.
Le rôle minimal à attribuer à votre identité de service de recherche est Contributeur.
Configurer une identité managée par l’utilisateur ou système pour votre service Search IA.
La capture d’écran suivante présente l’identité managée par le système d’un service de recherche nommé « onelake-demo ».

Cette capture d’écran présente l’identité managée par l’utilisateur du même service de recherche.

Octroyer une autorisation d’accès au service de recherche à l’espace de travail Fabric. Le service de recherche établit la connexion pour le compte de l’indexeur.
Si vous utilisez une identité managée affectée par le système, recherchez le nom du service Search IA. Pour une identité managée affectée par l’utilisateur, recherchez le nom de la ressource d’identité.
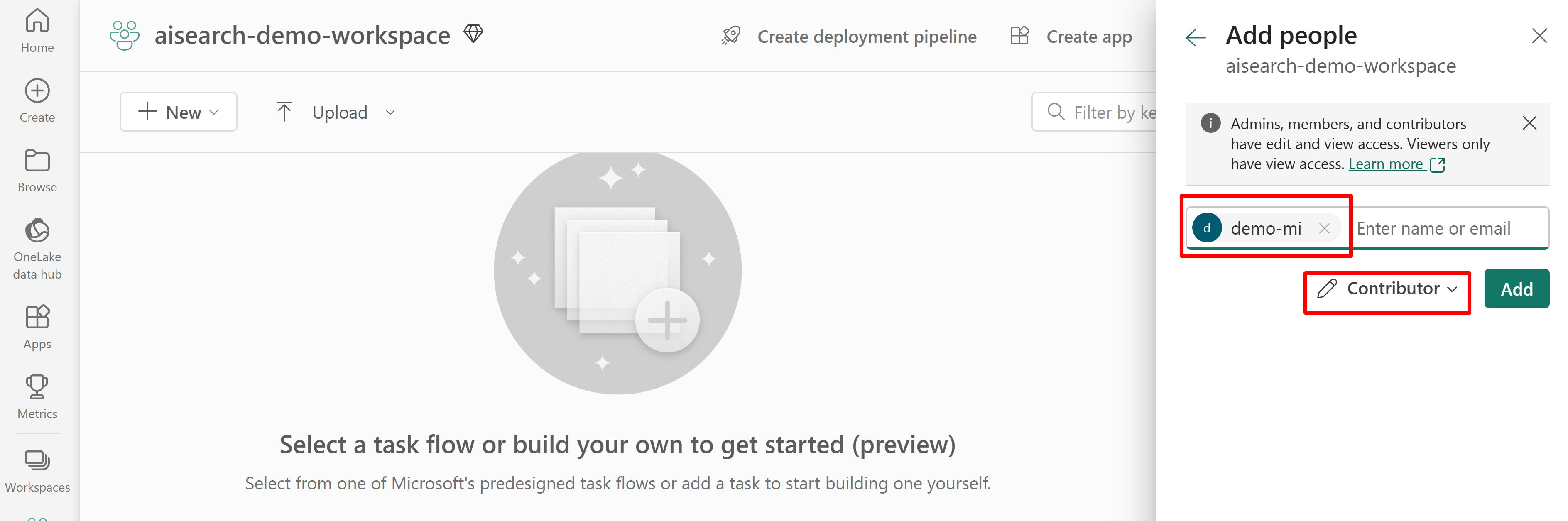
La capture d’écran suivante présente une attribution de rôle Contributeur à l’aide d’une identité managée par le système.

Cette capture d’écran présente l’attribution de rôle Contributeur à l’aide d’une identité managée système :




Définir la source de données
Une source de données est définie comme une ressource indépendante de manière à pouvoir être utilisée par plusieurs indexeurs. Vous devez utiliser l’API REST 2024-05-01-préversion pour créer la source de données.
Utilisez l’API REST Créer ou mettre à jour une source de données pour configurer sa définition. Il s’agit des étapes les plus importantes de la définition.
Définissez
"type"sur"onelake"(obligatoire).Obtenez le GUID de l’espace de travail Microsoft Fabric et le GUID du lakehouse :
Accédez au lakehouse dont vous souhaitez importer les données à partir de son URL. Elle doit ressembler à cet exemple : «https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi" ;. Copiez les valeurs suivantes utilisées dans la définition de la source de données :
Copiez le GUID de l’espace de travail, appelé
{FabricWorkspaceGuid}, qui est répertorié juste après « groupes » dans l’URL. Dans cet exemple, il s’agit de 00000000-0000-0000-0000-000000000000.
Copiez le GUID du lakehouse, appelé
{lakehouseGuid}, qui est répertorié juste après « lakehouses » dans l’URL. Dans cet exemple, il s’agit de 11111111-1111-1111-1111-111111111111.
Définissez
"credentials"sur le GUID de l’espace de travail Microsoft Fabric en remplaçant{FabricWorkspaceGuid}par la valeur que vous avez copiée à l’étape précédente. Il s’agit du OneLake auquel vous accéderez avec l’identité managée que vous allez configurer plus loin dans ce guide."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Définissez
"container.name"sur le GUID du lakehouse, en remplaçant{lakehouseGuid}par la valeur que vous avez copiée à l’étape précédente. Utilisez"query"si vous souhaitez spécifier un sous-dossier ou un raccourci du lakehouse."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Définissez la méthode d’authentification à l’aide de l’identité managée affectée par l’utilisateur ou passez à l’étape suivante pour une identité managée par le système.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }Vous trouverez la valeur
userAssignedIdentityen accédant à la ressource{userAssignedManagedIdentity}, sous Propriétés, elle est appeléeId.
Exemple :
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Si vous le souhaitez, utilisez plutôt une identité managée affectée par le système. L'« identité » est supprimée de la définition si vous utilisez l’identité managée affectée par le système.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Exemple :
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Détecter les suppressions via des métadonnées personnalisées
La définition de la source de données de l’indexeur de fichiers OneLake peut inclure une stratégie de suppression réversible si vous souhaitez que l’indexeur supprime un document de recherche lorsque le document source est marqué pour suppression.
Pour activer la suppression automatique des fichiers, utilisez des métadonnées personnalisées afin d’indiquer si un document de recherche doit être supprimé de l’index.
Le flux de travail nécessite trois actions distinctes :
- « Suppression réversible » du fichier dans OneLake
- L’indexeur supprime le document de recherche dans l’index
- « Suppression définitive » du fichier dans OneLake
La « suppression réversible » indique à l’indexeur ce qu’il doit faire (supprimer le document de recherche). Si vous supprimez d’abord le fichier physique dans OneLake, l’indexeur n’a rien à lire et le document de recherche correspondant dans l’index est orphelin.
Vous devez suivre certaines étapes dans Onelake et dans la recherche Azure AI, mais il n’y a pas d’autres dépendances de fonctionnalités.
Dans le fichier du lakehouse, ajoutez une paire clé-valeur de métadonnées personnalisées au fichier pour indiquer que le fichier est marqué pour suppression. Par exemple, vous pouvez nommer la propriété « IsDeleted », définie sur false. Lorsque vous souhaitez supprimer le fichier, attribuez-lui la valeur true.

Dans Recherche Azure AI, modifiez la définition de la source de données de façon à inclure une propriété « dataDeletionDetectionPolicy ». Par exemple, la stratégie suivante considère qu’un fichier doit être supprimé si sa propriété de métadonnées « IsDeleted » est définie sur la valeur true :
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Après que l’indexeur a traité le fichier et supprimé le document de l’index de recherche, vous pouvez supprimer le fichier physique dans le lac de données.
Quelques points clés :
La planification d’une exécution d’indexeur permet d’automatiser ce processus. Nous recommandons de planifier tous les scénarios d’indexation incrémentielle.
Si la stratégie de détection de suppression n’a pas été définie lors de la première exécution de l’indexeur, vous devez réinitialiser l’indexeur afin qu’il lise la configuration mise à jour.
Rappelez-vous que la détection de suppression n’est pas prise en charge pour les raccourcis Amazon S3 et Google Cloud Storage en raison de la dépendance des métadonnées personnalisées.
Ajouter des champs de recherche à un index
Dans un index de recherche, ajoutez des champs pour accepter le contenu et les métadonnées des fichiers du lac de données de votre OneLake.
Créer ou mettre à jour un index pour définir des champs de recherche qui stockent le contenu et les métadonnées des fichiers :
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Créez un champ de clé de document ("key": true). Pour le contenu des fichiers, les meilleurs candidats sont les propriétés de métadonnées.
metadata_storage_path(valeur par défaut) chemin complet de l’objet ou du fichier. Le champ de clé (« ID » dans cet exemple) est rempli avec les valeurs de metadata_storage_path, car il s’agit de la valeur par défaut.metadata_storage_name, utilisable uniquement si les noms sont uniques. Pour que ce champ désigne la clé, déplacez"key": truevers cette définition de champ.Propriété de métadonnées personnalisée que vous ajoutez aux fichiers. Cette option contraint votre processus de chargement de fichiers à ajouter cette propriété de métadonnées à tous les blobs. Étant donné que la clé est une propriété obligatoire, les fichiers auxquels il manque une valeur ne sont pas indexés. Si vous utilisez une propriété de métadonnées personnalisée comme clé, évitez d’apporter des modifications à cette propriété. Les indexeurs ajoutent des documents en double au même fichier si la propriété de clé est modifiée.
Les propriétés de métadonnées incluent souvent des caractères (par exemple
/et-) qui ne sont pas valides pour les clés de document. Comme l’indexeur possède une propriété « base64EncodeKeys » (true par défaut), il encode automatiquement la propriété de métadonnées, sans qu’aucune configuration ni aucun mappage de champs ne soit nécessaire.Ajoutez un champ « contenu » pour stocker le texte extrait de chaque fichier via la propriété « contenu » du fichier. Vous n’êtes pas obligé d’utiliser ce nom, mais le faire vous permet de tirer parti des mappages de champs implicites.
Ajoutez des champs pour les propriétés de métadonnées standard. L’indexeur peut lire les propriétés des métadonnées personnalisées, celles des métadonnées standard et celles des métadonnées spécifiques au contenu.
Configurer et exécuter l'indexeur de fichiers OneLake
Une fois l’index et la source de données créés, vous êtes prêt à créer l’indexeur. La configuration de l’indexeur spécifie les entrées, les paramètres et les propriétés qui contrôlent les comportements d’exécution. Vous pouvez également spécifier les parties d’un blob à indexer.
Créez ou mettez à jour un indexeur en lui attribuant un nom, et en référençant la source de données et l’index cible :
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Définissez « batchSize » si la valeur par défaut (10 documents) sous-utilise les ressources disponibles ou les épuise. Les tailles de lot par défaut sont spécifiques à la source de données. L’indexation de fichier définit la taille des lots à 10 documents en fonction de la taille moyenne des documents la plus élevée.
Sous « configuration », contrôlez les fichiers qui sont indexés en fonction du type de fichier ou ne spécifiez pas de valeur pour récupérer tous les fichiers.
Pour
"indexedFileNameExtensions", fournissez une liste d’extensions de fichier (avec un point au début) séparées par des virgules. Procédez de la même façon pour"excludedFileNameExtensions", afin d’indiquer les extensions qui doivent être ignorées. Si la même extension figure dans les deux listes, elle est exclue de l’indexation.Sous « configuration », définissez « dataToExtract » pour contrôler les parties des fichiers qui sont indexées :
« contentAndMetadata » est la valeur par défaut. Elle indique que les métadonnées et le contenu textuel extrait du fichier sont indexés.
« storageMetadata » indique que seules les propriétés standard du fichier et les métadonnées spécifiées par l’utilisateur sont indexées. Bien que les propriétés des fichiers Azure soient documentées, les propriétés de fichier sont identiques pour OneLake, à l’exception des métadonnées associées à SAS.
« allMetadata » indique que les propriétés de fichier standard et les métadonnées des types de contenu trouvés sont extraites du contenu du fichier et indexées.
Sous « configuration », définissez « parsingMode » si les fichiers doivent être mappés en plusieurs documents de recherche, ou s’ils se composent de texte brut, de documents JSON ou de fichiers CSV.
Spécifiez les mappages de champs s’il existe des différences dans le nom ou le type du champ, ou si vous avez besoin de plusieurs versions d’un champ source dans l’index de recherche.
Dans l’indexation des fichiers, il est souvent possible d’omettre les mappages de champs, car l’indexeur dispose d’une prise en charge intégrée du mappage des propriétés « content » et de métadonnées vers des champs de même nom et de même type dans un index. Dans les propriétés des métadonnées, l’indexeur remplace automatiquement les traits d’union
-par des traits de soulignement dans l’index de recherche.
Pour plus d’informations sur les autres propriétés, consultez Créer un indexeur. Pour obtenir la liste complète des descriptions des paramètres, consultez Créer un indexeur (REST) dans l’API REST. Les paramètres sont identiques pour OneLake.
Par défaut, un indexeur s’exécute automatiquement lorsque vous le créez. Vous pouvez modifier ce comportement en définissant « désactivé » sur true. Pour contrôler l’exécution de l’indexeur, exécutez un indexeur à la demande ou placez-le dans une planification.
Vérifier l’état de l’indexeur
Découvrez différentes approches pour analyser l’état de l’indexeur et l’historique d’exécution ici.
Gérer les erreurs
Les erreurs qui se produisent généralement pendant l’indexation incluent les types de contenu non pris en charge, le contenu manquant ou les fichiers surdimensionnés. Par défaut, l’indexeur de fichiers OneLake s’arrête dès qu’il rencontre un fichier dont le type de contenu n’est pas pris en charge. Toutefois, vous pourriez vouloir procéder à l’indexation même si des erreurs se produisent, puis déboguer les documents individuels plus tard.
Les erreurs temporaires sont courantes dans les solutions impliquant plusieurs plateformes et produits. Toutefois, si vous maintenez l’indexeur selon une planification (par exemple toutes les 5 minutes), l’indexeur doit pouvoir récupérer à partir de ces erreurs dans l’exécution suivante.
Il existe cinq propriétés d’indexeur qui contrôlent la réponse de l’indexeur lorsque des erreurs se produisent.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Paramètre | Valeurs valides | Description |
|---|---|---|
| « maxFailedItems » | -1, nul ou 0, entier positif | Poursuivez l’indexation si des erreurs se produisent à un moment quelconque du traitement, que ce soit durant l’analyse de blobs ou l’ajout de documents à un index. Définissez ces propriétés sur le nombre d’échecs acceptables. La valeur -1 permet le traitement, quel que soit le nombre d’erreurs qui se produisent. Dans le cas contraire, la valeur est un entier positif. |
| « maxFailedItemsPerBatch » | -1, nul ou 0, entier positif | Identique à ce qui précède, mais utilisé pour l’indexation par lots. |
| « failOnUnsupportedContentType » | True ou False | Si l’indexeur ne parvient pas à déterminer le type de contenu, spécifiez s’il faut poursuivre le travail ou le mettre en échec. |
| « failOnUnprocessableDocument » | True ou False | Si l’indexeur ne parvient pas à traiter un document d’un type de contenu autrement pris en charge, spécifiez s’il faut poursuivre le travail ou le mettre en échec. |
| « indexStorageMetadataOnlyForOversizedDocuments » | True ou False | Par défaut, les objets blob surdimensionnés sont traités comme des erreurs. Si vous définissez ce paramètre sur true, l’indexeur essaie d’indexer ses métadonnées même si le contenu ne peut pas être indexé. Pour connaître les limites de taille des blobs, consultez Limites du service. |
Étapes suivantes
Passez en revue le fonctionnement de l’Assistant d’importation et de vectorisation de données et essayez-le sur cet indexeur. Vous pouvez utiliser une vectorisation intégrée pour segmenter et créer des incorporations pour la recherche vectorielle ou hybride à l’aide d’un schéma par défaut.