Communication dans une architecture de microservices
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

Dans une application monolithique s’exécutant sur un seul processus, les composants s’appellent mutuellement avec des appels de méthode ou de fonction au niveau du langage. Ceux-ci peuvent être fortement couplés si vous créez des objets avec du code (par exemple new ClassName()), ou ils peuvent être appelés de façon découplée si vous utilisez l’injection de dépendances en référençant des abstractions au lieu d’instances d’objets concrets. Dans les deux cas, les objets s’exécutent dans le même processus. La plus grande problématique quand vous passez d’une application monolithique à une application basée sur des microservices se trouve dans le changement du mécanisme de communication. Une conversion directe des appels de méthode in-process en appels RPC à des services aboutit à des communications intensives et inefficaces qui ne fonctionnent pas bien dans les environnements distribués. La problématique liée à la conception correcte d’un système distribué est tellement bien connue qu’il existe même un ensemble de principes canoniques appelé les Illusions de l’informatique distribuée. Cet ensemble liste les suppositions que font souvent les développeurs quand ils passent de conceptions monolithiques à des conceptions distribuées.
Il n’existe pas une seule solution, il en existe plusieurs. Une solution consiste à isoler autant que possible le microservice métier. Vous utilisez ensuite une communication asynchrone entre les microservices internes, et vous remplacez la communication à petite échelle, qui est classique dans la communication intraprocessus entre objets, par une communication à plus grande échelle. Vous pouvez réaliser cela en regroupant les appels et en retournant au client des données qui agrègent les résultats de plusieurs appels internes.
Une application basée sur des microservices est un système distribué s’exécutant sur plusieurs processus ou services, généralement même entre plusieurs serveurs ou plusieurs hôtes. Chaque instance de service est généralement un processus. Pour cette raison, les services doivent interagir en utilisant un protocole de communication interprocessus, comme HTTP ou AMQP, ou un protocole binaire, comme TCP, selon la nature de chaque service.
La communauté des microservices promeut une philosophie consistant à avoir des « des points de terminaison intelligents et des canaux stupides ». Ce slogan encourage une conception qui est aussi découplée que possible entre microservices et aussi cohésive que possible au sein d’un même microservice. Comme expliqué précédemment, chaque microservice a ses propres données et sa propre logique de domaine. Cependant, les microservices composant une application de bout en bout sont généralement chorégraphiés simplement avec des communications REST au lieu de protocoles complexes comme WS-*, et avec des communications flexibles pilotées par les événements au lieu d’orchestrateurs de processus métier centralisés.
Les deux protocoles couramment utilisés sont le protocole de requête/réponse HTTP avec des API de ressources (lors de l’interrogation de la plupart d’entre eux) et une messagerie asynchrone légère lors de la communication lors de la communication de mises à jour entre plusieurs microservices. Ils sont expliqués avec plus de détails dans les sections suivantes.
Types de communication
Un client et des services peuvent communiquer via de nombreux types différents de communication, chacun d’eux ciblant un scénario et des objectifs différents. Au départ, ces types de communication peuvent être classés selon deux axes.
Le premier axe définit si le protocole est synchrone ou asynchrone :
Protocole synchrone. HTTP est un protocole synchrone. Le client envoie une requête et attend une réponse du service. Cela est indépendant de l’exécution du code client, qui peut être synchrone (le thread est bloqué) ou asynchrone (le thread n’est pas bloqué, et la réponse atteint finalement un rappel). Le point important ici est que le protocole (HTTP/HTTPS) est synchrone et que le code client peut continuer sa tâche seulement quand il reçoit la réponse du serveur HTTP.
Protocole asynchrone. D’autres protocoles, comme AMQP (un protocole pris en charge par de nombreux systèmes d’exploitation et environnements cloud), utilisent des messages asynchrones. Le code client ou l’expéditeur du message n’attend généralement pas de réponse. Il envoie simplement le message comme lors de l’envoi d’un message à une file d’attente RabbitMQ ou à tout autre service broker de messages.
Le deuxième axe définit si la communication a un ou plusieurs destinataires :
Destinataire unique. Chaque demande doit être traitée par exactement un récepteur ou un service. Le modèle Commande est un exemple de cette communication.
Plusieurs destinataires. Chaque demande peut être traitée par zéro à plusieurs destinataires. Ce type de communication doit être asynchrone. Le mécanisme de publication/abonnement utilisé dans des modèles comme Event-driven architecture en est un exemple. Il s’appuie sur une interface de bus d’événements ou un répartiteur de messages durant la propagation des mises à jour des données entre plusieurs microservices via des événements. Il est généralement implémenté via un bus de service ou un artefact similaire, par exemple Azure Service Bus, à l’aide des rubriques et abonnements.
Une application basée sur des microservices utilise souvent une combinaison de ces styles de communication. Le type le plus courant est une communication avec un seul destinataire, avec un protocole synchrone comme HTTP/HTTPS lors de l’appel d’un service web HTTP d’API ordinaire. Les microservices utilisent aussi en général des protocoles de messagerie pour la communication asynchrone entre microservices.
Il est bon de connaître ces axes pour avoir une compréhension claire des mécanismes de communication possibles, mais ils ne représentent pas des problèmes importants à prendre en compte au moment de la génération de microservices. Ni la nature asynchrone de l’exécution des threads clients ni la nature asynchrone du protocole choisi sont les points importants lors de l’intégration de microservices. Ce qui est important est de pouvoir intégrer vos microservices de façon asynchrone tout en conservant leur indépendance, comme expliqué dans la section suivante.
L’intégration de microservices asynchrones implique l’autonomie des microservices
Comme cela a été mentionné, le point important lors de la création d’une application basée sur des microservices est la façon dont vous intégrez vos microservices. Dans l’idéal, vous devez essayer de réduire la communication entre les microservices internes. Moins il existe de communications entre les microservices, mieux c’est. Mais dans de nombreux cas, vous devez intégrer les microservices d’une façon ou d’une autre. Quand vous devez le faire, la règle essentielle ici est que la communication entre les microservices doit être asynchrone. Cela ne signifie pas que vous devez utiliser un protocole spécifique (par exemple une messagerie asynchrone par opposition au protocole HTTP synchrone). Cela signifie simplement que vous devez effectuer la communication entre microservices par propagation asynchrone des données, tout en essayant de ne pas dépendre d’autres microservices internes dans le cadre de l’opération de requête-réponse HTTP du service initial.
Si possible, ne dépendez jamais d’une communication synchrone (requête/réponse) entre plusieurs microservices, pas même pour des requêtes. L’objectif de chaque microservice est d’être autonome et disponible pour le consommateur client, même si les autres services qui font partie de l’application de bout en bout sont indisponibles ou défectueux. Si vous pensez que vous devez effectuer un appel d’un microservice à d’autres microservices (par exemple, effectuer une requête HTTP pour une requête de données) afin de pouvoir fournir une réponse à une application cliente, votre architecture ne sera pas résiliente en cas d’échec de certains microservices.
De plus, l’existence de dépendances HTTP entre microservices, par exemple durant la création de cycles longs de requête-réponse avec des chaînes de requêtes HTTP, comme indiqué dans la première partie de la figure 4-15, rend non seulement vos microservices non autonomes, mais impacte aussi leur niveau de performance dès qu’un des services de la chaîne ne fonctionne pas correctement.
Plus vous ajoutez des dépendances synchrones entre microservices, comme des demandes avec des requêtes, plus le temps de réponse global se dégrade pour les applications clientes.
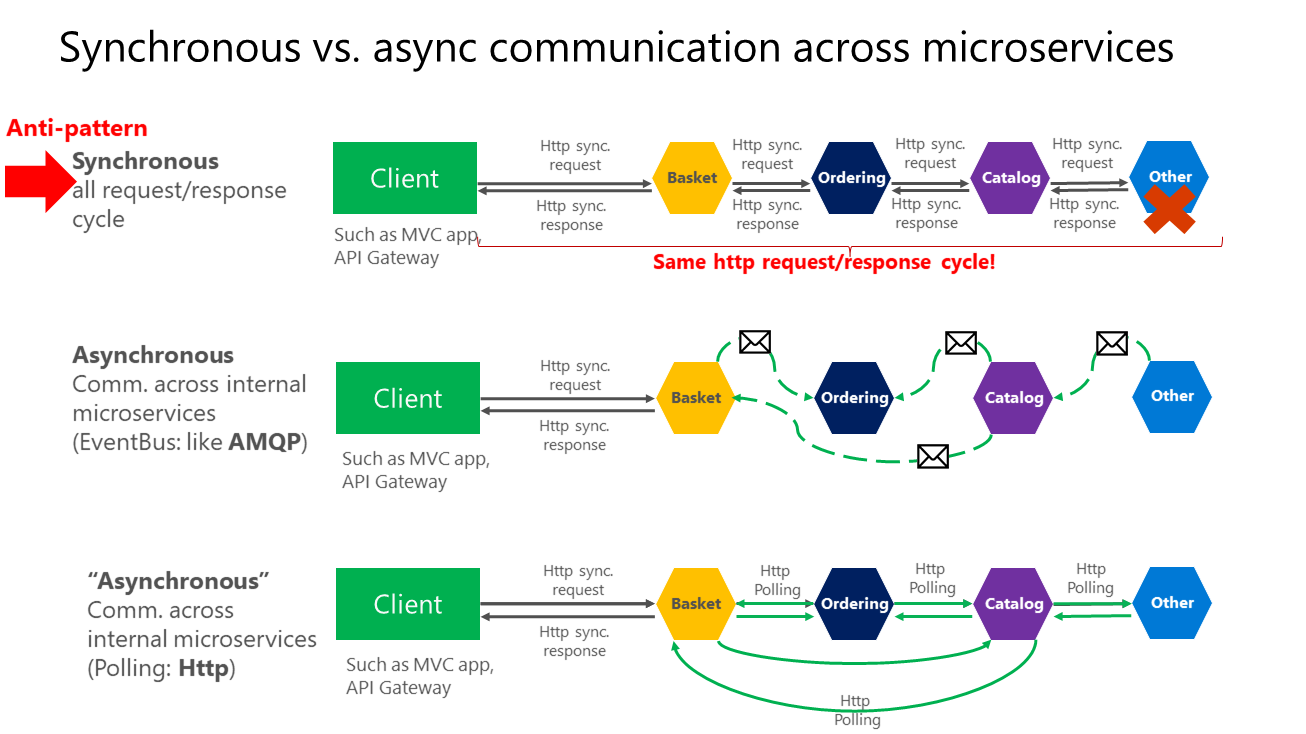
Figure 4-15. Antimodèles et modèles de communication entre microservices
Comme illustré dans le diagramme ci-dessus, dans une communication synchrone, une « chaîne » de requêtes est créée entre microservices durant le traitement de la requête cliente. Ceci est un antimodèle. Dans une communication asynchrone, les microservices utilisent des messages asynchrones ou une interrogation HTTP pour communiquer avec d’autres microservices, mais la requête cliente est immédiatement traitée.
Si votre microservice doit déclencher une action supplémentaire dans un autre microservice, si possible, n’effectuez pas cette action de façon synchrone ni dans le cadre de l’opération de requête et réponse du microservice d’origine. Au lieu de cela, effectuez l’opération de façon asynchrone (en utilisant une messagerie asynchrone ou des événements d’intégration, des files d’attente, etc.). Cependant, autant que possible, n’appelez pas l’action de façon synchrone dans le cadre de l’opération de requête et de réponse synchrone d’origine.
Enfin (et c’est là que la plupart des problèmes se posent durant la génération de microservices), si votre microservice initial a besoin de données détenues à l’origine par d’autres microservices, ne vous fiez pas à l’utilisation de requêtes synchrones pour ces données. À la place, répliquez ou propagez ces données (seulement les attributs nécessaires) dans la base de données du service initial en utilisant une cohérence à terme (généralement à l’aide d’événements d’intégration, comme cela est expliqué dans les prochaines sections).
Comme indiqué dans la section Identification des limites du modèle de domaine pour chaque microservice, la duplication des données entre plusieurs microservices n’est pas une conception incorrecte. Bien au contraire, en procédant ainsi, vous pouvez traduire les données dans le langage ou les termes spécifiques de cet autre domaine ou contexte délimité. Par exemple, dans l’application eShopOnContainers, vous avez un microservice nommé identity-api qui est responsable de la plupart des données de l’utilisateur avec une entité nommée User. Cependant, quand vous devez stocker des données relatives à l’utilisateur dans le microservice Ordering, vous les stockez sous la forme d’une autre entité nommée Buyer. L’entité Buyer partage la même identité avec l’entité User d’origine, mais elle ne doit avoir que les quelques attributs nécessaires au domaine Ordering, et non pas la totalité du profil de l’utilisateur.
Vous pouvez utiliser n’importe quel protocole pour communiquer et propager des données de façon asynchrone entre les microservices pour avoir une cohérence à terme. Comme cela a été mentionné, vous pouvez utiliser des événements d’intégration avec un bus d’événements ou un courtier de messages, ou vous pouvez même utiliser HTTP en interrogeant les autres services. Cela n’a pas d’importance. La règle importante est de ne pas créer de dépendances synchrones entre vos microservices.
Les sections suivantes expliquent les différents styles de communication que vous pouvez envisager d’utiliser dans une application basée sur des microservices.
Styles de communication
De nombreux protocoles et choix sont disponibles pour la communication, en fonction du type de communication que vous voulez utiliser. Si vous utilisez un mécanisme de communication de type requête-réponse synchrone, les protocoles tels que HTTP et REST sont les plus courants, en particulier si vous publiez vos services en dehors de l’hôte Docker ou du cluster de microservices. Si vous communiquez entre des services de manière interne (au sein de votre hôte Docker ou de votre cluster de microservices), vous pouvez également utiliser des mécanismes de communication au format binaire (par exemple WCF à l’aide de TCP et d’un format binaire). Vous pouvez aussi utiliser des mécanismes de communication asynchrones basés sur des messages, comme AMQP.
Il existe également plusieurs formats de message, comme JSON ou XML, ou même des formats binaires, qui peuvent être plus efficaces. Si le format binaire choisi n’est pas standard, il n’est probablement pas judicieux de publier vos services et de les rendre publics à l’aide de ce format. Vous pouvez utiliser un format non standard pour la communication interne entre vos microservices. Vous pouvez procéder ainsi pour la communication entre microservices dans votre hôte Docker ou votre cluster de microservices (par exemple, orchestrateurs Docker), ou pour des applications clientes propriétaires qui communiquent avec les microservices.
Communication demande/réponse avec HTTP et REST
Quand un client utilise une communication demande/réponse, il envoie une demande à un service, puis le service traite la demande et renvoie une réponse. La communication demande/réponse est particulièrement bien adaptée pour interroger des données pour une interface utilisateur en temps réel (une interface utilisateur dynamique) à partir d’applications clientes. Dans une architecture de microservices, vous allez donc probablement utiliser ce mécanisme de communication pour la plupart des requêtes, comme indiqué sur la figure 4-16.
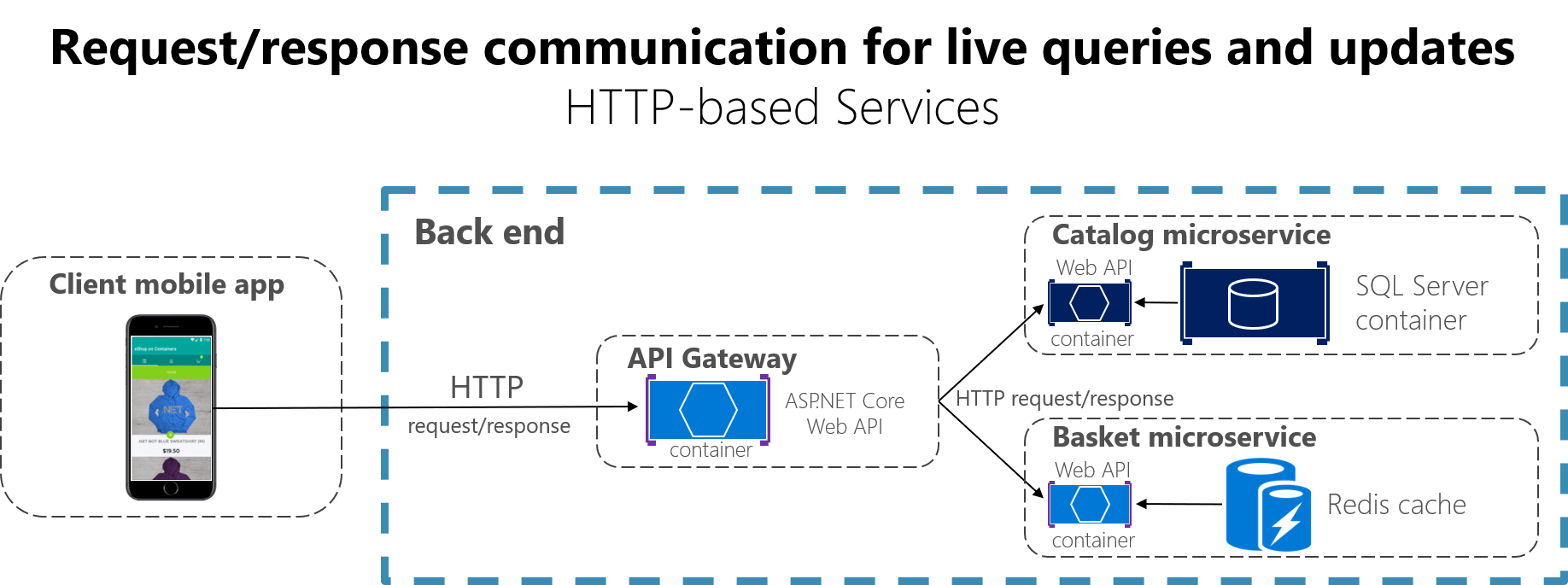
Figure 4-16. Utilisation d’une communication demande/réponse HTTP (synchrone ou asynchrone)
Quand un client utilise une communication demande/réponse, il suppose que la réponse arrivera dans un délai court, en général en moins d’une seconde ou au plus en quelques secondes. Pour les réponses différées, vous devez implémenter une communication asynchrone basée sur des modèles de messagerie et des technologies de messagerie, qui est une approche différente que nous expliquons dans la section suivante.
REST est un style d’architecture répandu pour la communication demande/réponse. Cette approche est basée sur le protocole HTTP et y est étroitement couplée ; elle utilise des verbes HTTP comme GET, POST et PUT. REST est l’approche architecturale de communication la plus couramment utilisée pour la création de services. Vous pouvez implémenter des services REST quand vous développez des services d’API web ASP.NET Core.
Vous profitez d’autres avantages si vous utilisez les services HTTP REST en tant que langage IDL (Interface Definition Language). Par exemple, si vous utilisez des métadonnées Swagger pour décrire l’API de votre service, vous pouvez utiliser des outils qui génèrent des stubs clients, qui peuvent directement découvrir et utiliser vos services.
Ressources supplémentaires
Martin Fowler. Modèle de maturité de Richardson Une description du modèle REST.
https://martinfowler.com/articles/richardsonMaturityModel.htmlSwagger : site officiel.
https://swagger.io/
Communication par envoi (push) en temps réel basée sur HTTP
Une autre possibilité (généralement utilisée à des fins différentes de REST) est une communication en temps réel un-à-plusieurs avec des frameworks de plus haut niveau, comme ASP.NET SignalR et des protocoles comme WebSockets.
Comme le montre la figure 4-17, la communication HTTP en temps réel signifie que le code serveur peut envoyer (push) du contenu à des clients connectés à mesure que les données sont disponibles, au lieu que le serveur attende qu’un client demande de nouvelles données.
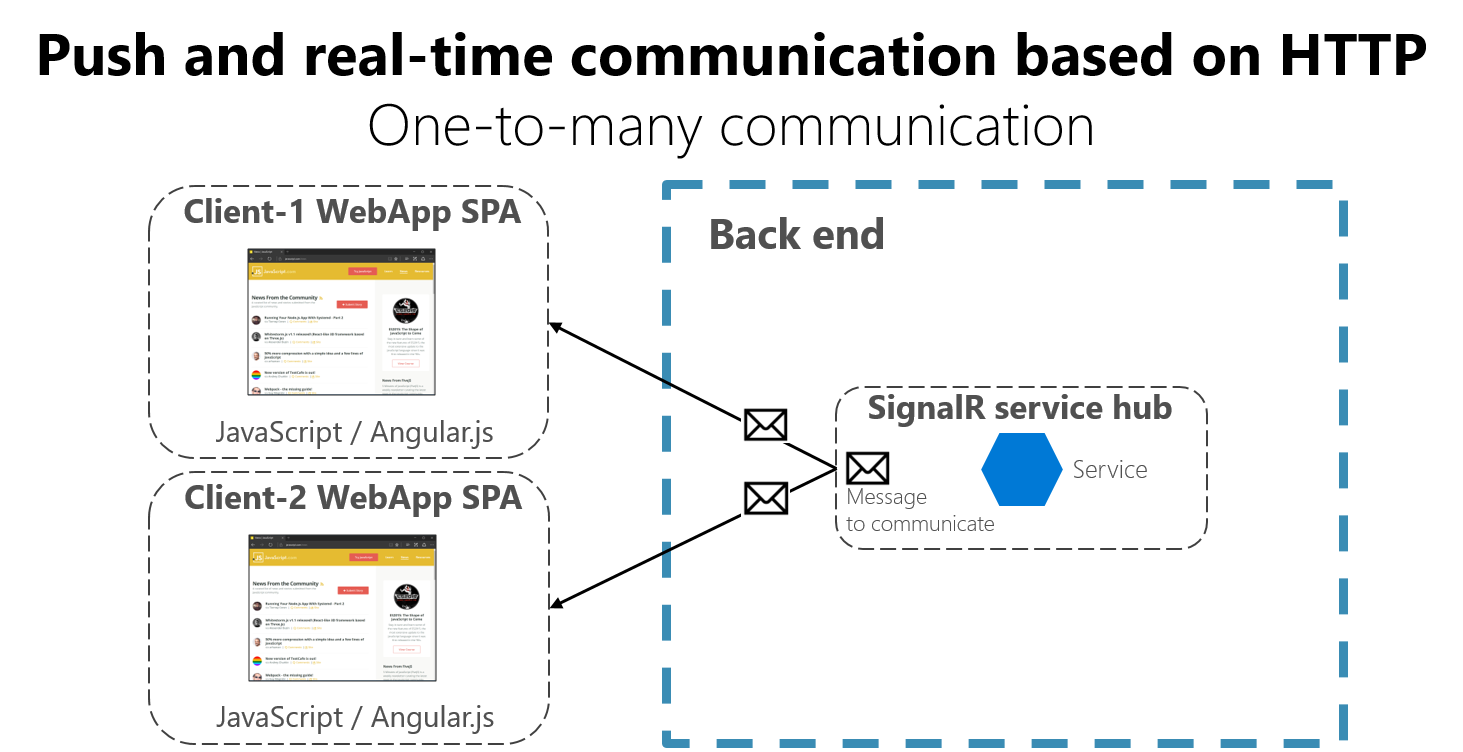
Figure 4-17. Communication par messages asynchrones un-à-plusieurs en temps réel
SignalR est un bon moyen d’effectuer une communication en temps réel pour envoyer (push) du contenu aux clients à partir d’un serveur back-end. Étant donné que la communication est en temps réel, les applications clientes montrent les modifications quasi instantanément. Ceci est généralement géré par un protocole comme WebSockets, avec de nombreuses connexions WebSockets (une par client). Un exemple classique est quand un service communique un changement de score d’une rencontre sportive simultanément à de nombreuses d’applications web clientes.