Gérer une défaillance partielle
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

Dans les systèmes distribués tels que les applications basées sur des microservices, le risque de défaillance partielle est omniprésent. Par exemple, un microservice ou un conteneur peut échouer ou ne pas être disponible pour répondre pendant un court instant, ou une machine virtuelle ou un serveur peut connaître un incident. Étant donné que les clients et les services sont des processus distincts, il peut arriver qu’un service ne puisse pas répondre à temps à une requête d’un client. Le service peut être surchargé et répondre très lentement aux requêtes, ou simplement ne pas être accessible pendant un bref laps de temps à cause de problèmes réseau.
Prenons la page des détails de commande dans l’exemple d’application eShopOnContainers. Si le microservice Ordering ne répond pas quand l’utilisateur tente d’envoyer sa commande, une mauvaise implémentation du processus client (l’application web MVC) peut bloquer indéfiniment les threads en attente d’une réponse. C’est le cas, par exemple, si le code client est défini pour utiliser des RPC synchrones sans délai d’expiration. En plus de la mauvaise expérience que cela représente pour l’utilisateur, chaque attente de réponse consomme ou bloque un thread. Or, les applications hautement scalables ont besoin de beaucoup de threads. Si de nombreux threads sont bloqués, le runtime de l’application peut finir par ne plus disposer de suffisamment de threads. Dans ce cas, l’application risque de ne plus répondre du tout au lieu de ne plus répondre juste partiellement, comme illustré à la Figure 8-1.
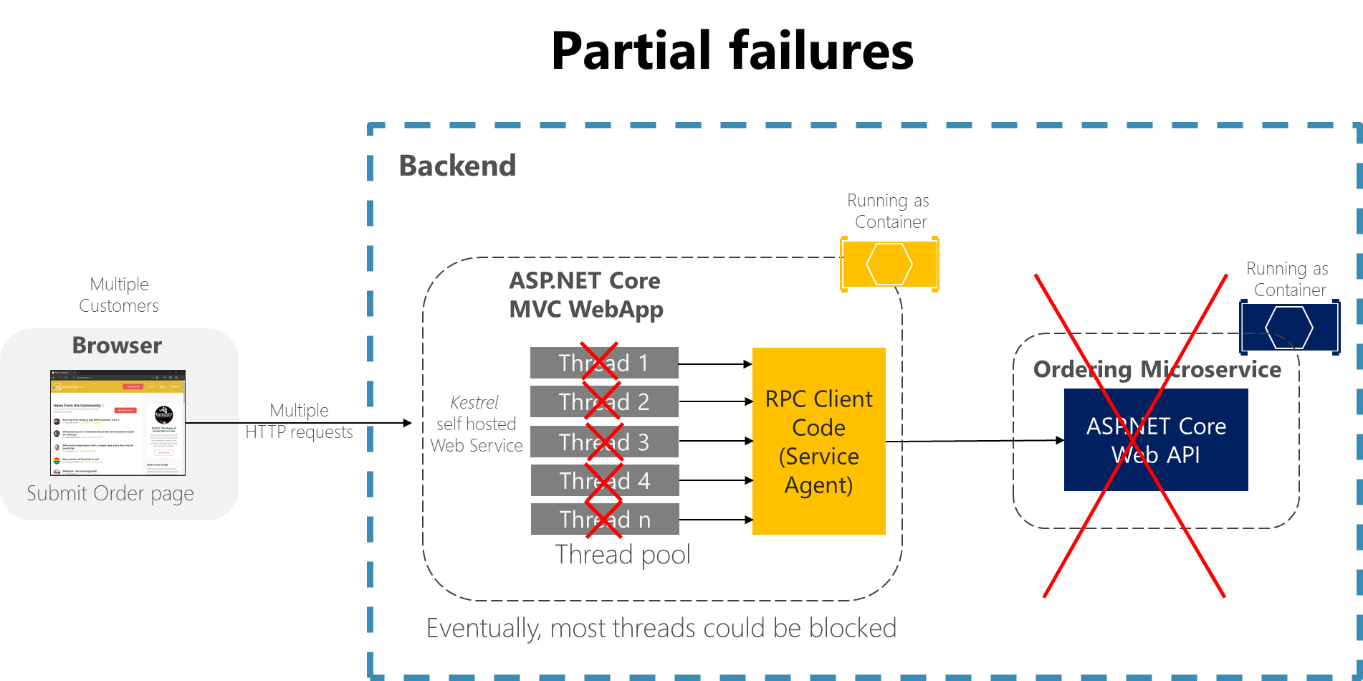
Figure 8-1 : Défaillances partielles dues à des dépendances qui impactent la disponibilité des threads du service
Dans une large application basée sur des microservices, une défaillance partielle peut avoir un impact plus global, surtout si la plupart des interactions de microservices internes sont basées sur des appels HTTP synchrones (ce qui est considéré comme anti-modèle). Pensez à un système qui reçoit des millions d’appels par jour. Si votre système a une mauvaise conception basée sur de longues chaînes d’appels HTTP synchrones, ces appels entrants peuvent provoquer des millions d’appels sortants supplémentaires (avec un ratio estimé de 1 pour 4) vers des dizaines de microservices internes et dépendances synchrones. Cette situation est illustrée dans la figure 8-2, en particulier la dépendance #3, qui démarre une chaîne, appelant la dépendance #4, qui appelle ensuite #5.
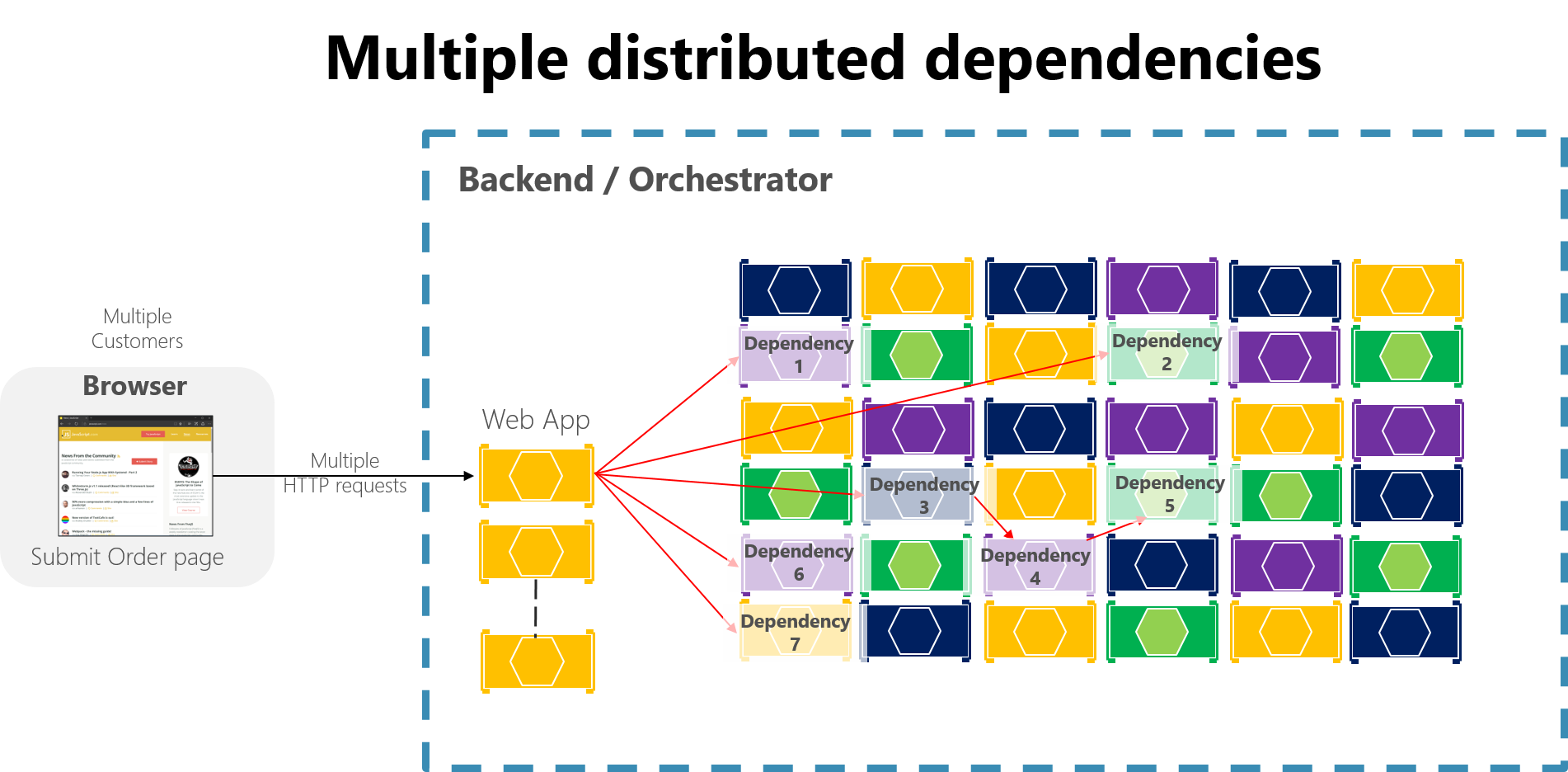
Figure 8-2 : Impact d’une mauvaise conception avec de longues chaînes de requêtes HTTP
Une défaillance intermittente est inévitable dans un système cloud et distribué, même si les dépendances présentent individuellement une haute disponibilité. C’est un point important à prendre en compte.
Si vous ne concevez pas et n’implémentez pas de techniques de tolérance de panne, même de courts temps d’arrêt peuvent avoir des répercussions amplifiées. Par exemple, l’existence de 50 dépendances avec 99,99 % de disponibilité se traduit par plusieurs heures d’arrêt chaque mois en raison de cet effet amplificateur. En cas d’échec d’une dépendance de microservice pendant le traitement d’un grand nombre de requêtes, cette défaillance peut rapidement saturer tous les threads de requête disponibles dans chaque service et entraîner le blocage de l’application entière.
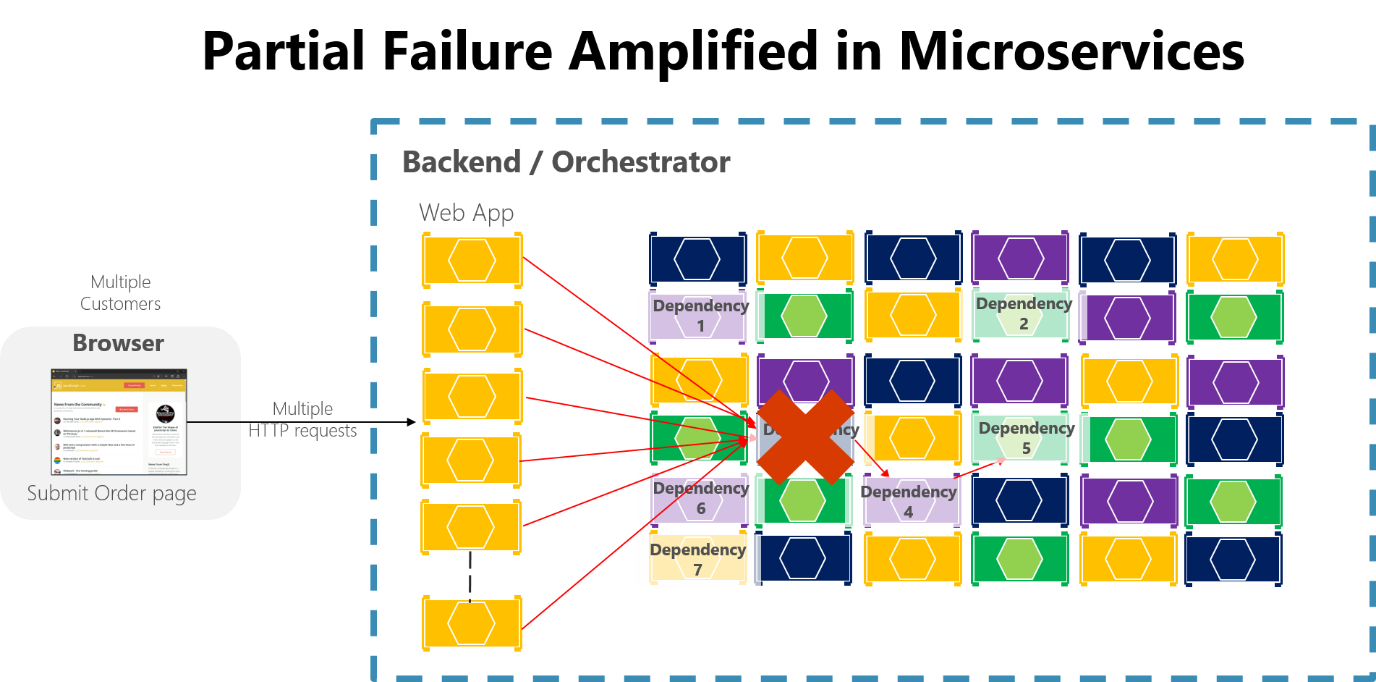
Figure 8-3 : Défaillance partielle amplifiée par les microservices avec de longues chaînes d’appels HTTP synchrones
Pour limiter ce problème, la section « L’intégration de microservices asynchrones implique l’autonomie des microservices » de ce guide vous recommande d’utiliser une communication asynchrone entre les microservices internes.
De plus, il est essentiel de concevoir vos microservices et applications clientes pour gérer les défaillances partielles, et ainsi les rendre résilients.