Migrer les métadonnées du metastore Hive d’Azure Synapse Analytics vers Fabric
L’étape initiale de la migration du metastore Hive (HMS) implique de déterminer les bases de données, les tables et les partitions que vous souhaitez transférer. Il n’est pas nécessaire de tout migrer ; vous pouvez sélectionner des bases de données spécifiques. Lors de l’identification des bases de données pour la migration, veillez à vérifier s’il existe des tables Spark managées ou externes.
Pour plus d’informations sur HMS, reportez-vous aux différences entre Azure Synapse Spark et Fabric.
Remarque
Sinon, si votre ADLS Gen2 contient des tables Delta, vous pouvez créer un raccourci OneLake vers une table Delta dans ADLS Gen2.
Prérequis
- Si vous n’en avez pas encore, créez un espace de travail Fabric dans votre locataire.
- Si vous n’en avez pas encore, créez un lakehouse Fabric dans votre espace de travail.
Option 1 : Exporter et importer HMS dans le metastore lakehouse
Suivez ces étapes clés pour la migration :
- Étape 1 : Exporter des métadonnées à partir du HMS source
- Étape 2 : Importer des métadonnées dans Fabric lakehouse
- Étapes postérieures à la migration : Valider le contenu
Remarque
Les scripts copient uniquement les objets de catalogue Spark dans Fabric lakehouse. L’hypothèse est que les données sont déjà copiées (par exemple, à partir de l’emplacement de l’entrepôt vers ADLS Gen2) ou disponibles pour les tables managées et externes (par exemple, par le biais de raccourcis préférés—) dans le lakehouse Fabric.
Étape 1 : Exporter des métadonnées à partir du HMS source
L’étape 1 se concentre sur l’exportation des métadonnées de HMS source vers la section Fichiers de votre lakehouse Fabric. Ce processus est le suivant :
1.1) Importez le notebook d’exportation de métadonnées HMS dans votre espace de travail Azure Synapse. Ce notebook interroge et exporte les métadonnées HMS des bases de données, des tables et des partitions vers un répertoire intermédiaire dans OneLake (fonctions non encore incluses). L’API de catalogue interne Spark est utilisée dans ce script pour lire les objets catalogue.
1.2) Configurez les paramètres dans la première commande pour exporter les informations de métadonnées vers un stockage intermédiaire (OneLake). L’extrait de code suivant est utilisé pour configurer les paramètres source et de destination. Veillez à les remplacer par vos propres valeurs.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Exécutez toutes les commandes de notebook pour exporter des objets catalogue vers OneLake. Une fois les cellules terminées, cette structure de dossiers sous le répertoire de sortie intermédiaire est créée.
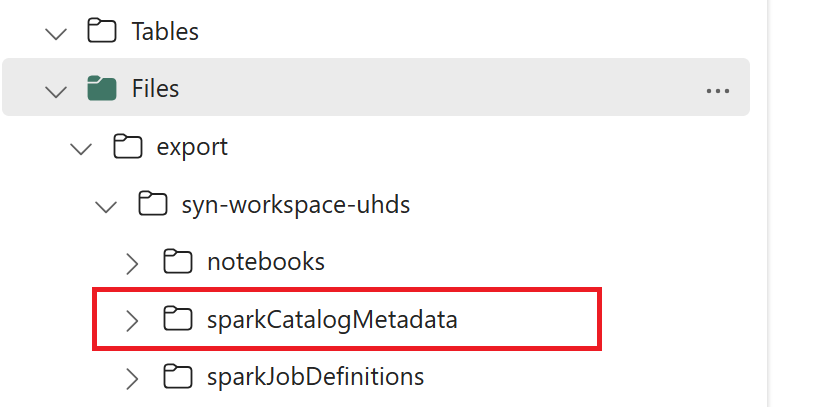
Étape 2 : Importer des métadonnées dans Fabric lakehouse
L’étape 2 est lorsque les métadonnées réelles sont importées à partir du stockage intermédiaire dans le lakehouse Fabric. La sortie de cette étape consiste à migrer toutes les métadonnées HMS (bases de données, tables et partitions). Ce processus est le suivant :
2.1) Créez un raccourci dans la section « Fichiers » de la lakehouse. Ce raccourci doit pointer vers le répertoire de l’entrepôt Spark source et est utilisé ultérieurement pour remplacer les tables managées Spark. Consultez des exemples de raccourcis pointant vers le répertoire de l’entrepôt Spark :
- Chemin d’accès contextuel au répertoire de l’entrepôt Azure Synapse Spark :
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Chemin d’accès contextuel au répertoire de l’entrepôt Azure Databricks :
dbfs:/mnt/<warehouse_dir> - Chemin d’accès contextuel au répertoire de l’entrepôt HDInsight Spark :
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Chemin d’accès contextuel au répertoire de l’entrepôt Azure Synapse Spark :
2.2) Importez le notebook d’importation de métadonnées HMS dans votre espace de travail Fabric. Importez ce notebook pour importer des objets de base de données, de table et de partition à partir d’un stockage intermédiaire. L’API de catalogue interne Spark est utilisée dans ce script pour créer des objets catalogue dans Fabric.
2.3) Configurez les paramètres dans la première commande. Dans Apache Spark, lorsque vous créez une table managée, les données de cette table sont stockées dans un emplacement géré par Spark lui-même, généralement dans le répertoire de l’entrepôt de Spark. L’emplacement exact est déterminé par Spark. Cela contraste avec les tables externes, où vous spécifiez l’emplacement et gérez les données sous-jacentes. Lorsque vous migrez les métadonnées d’une table managée (sans déplacer les données réelles), les métadonnées contiennent toujours les informations d’emplacement d’origine pointant vers l’ancien répertoire de l’entrepôt Spark. Par conséquent, pour les tables gérées,
WarehouseMappingsest utilisé pour effectuer le remplacement à l’aide du raccourci créé à l’étape 2.1. Toutes les tables managées sources sont converties en tant que tables externes à l’aide de ce script.LakehouseIdfait référence à la lakehouse créée à l’étape 2.1 contenant des raccourcis.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Exécutez toutes les commandes de notebook pour importer des objets catalogue à partir du chemin intermédiaire.
Remarque
Lors de l’importation de plusieurs bases de données, vous pouvez (i) créer un lakehouse par base de données (l’approche utilisée ici) ou (ii) déplacer toutes les tables de différentes bases de données vers un lakehouse unique. Pour ce dernier, toutes les tables migrées peuvent être <lakehouse>.<db_name>_<table_name>, et vous devez ajuster le notebook d’importation en conséquence.
Étape 3 : Valider le contenu
L’étape 3 est l’emplacement où vous vérifiez que les métadonnées ont été migrées avec succès. Consultez différents exemples.
Vous pouvez voir les bases de données importées en exécutant :
%%sql
SHOW DATABASES
Vous pouvez vérifier toutes les tables d’un lakehouse (base de données) en exécutant :
%%sql
SHOW TABLES IN <lakehouse_name>
Vous pouvez voir les détails d’une table particulière en exécutant :
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
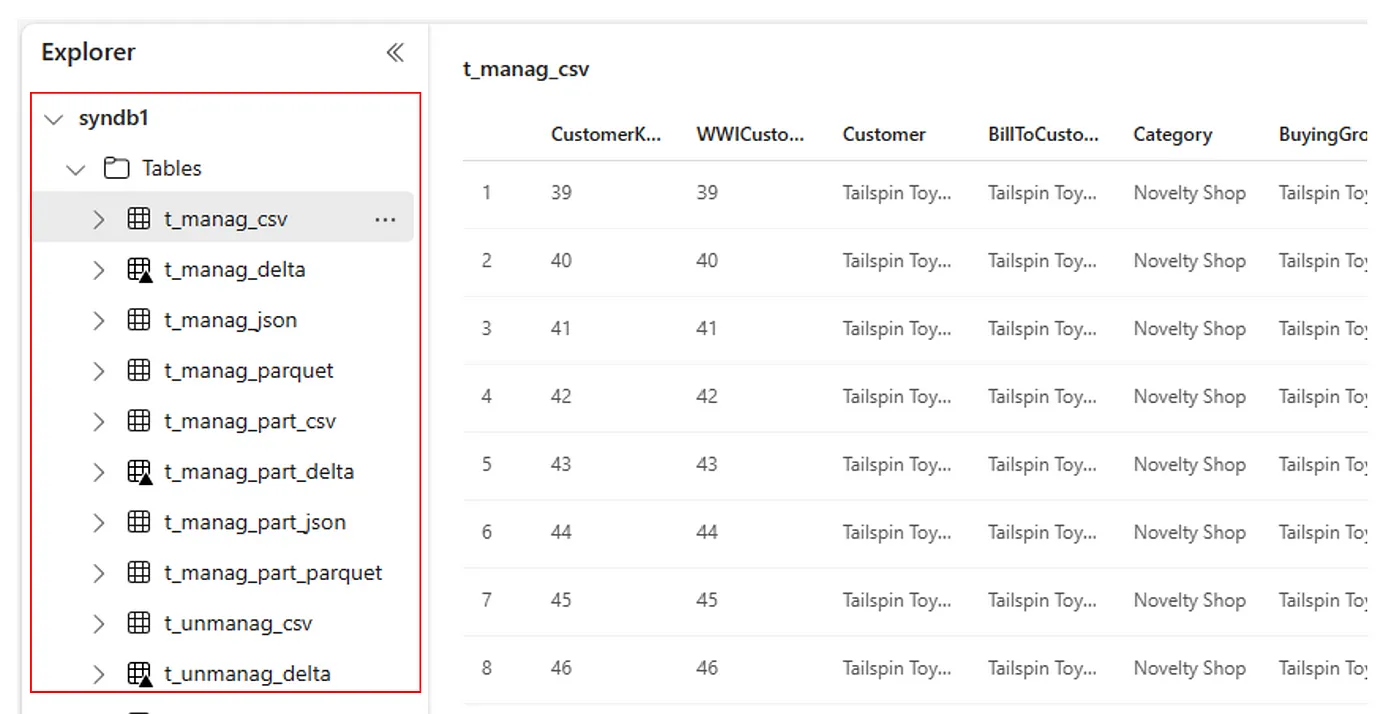
Vous pouvez également voir toutes les tables importées dans la section Tables de l’interface utilisateur de Lakehouse Explorer pour chaque lakehouse.
Autres considérations
- Scalabilité : la solution utilise l’API de catalogue Spark interne pour effectuer l’importation/exportation, mais elle ne se connecte pas directement à HMS pour obtenir des objets catalogue, de sorte que la solution n’a pas pu être mise à l’échelle si le catalogue est volumineux. Vous devez modifier la logique d’exportation à l’aide de la base de données HMS.
- Précision des données : il n’existe aucune garantie d’isolation, ce qui signifie que si le moteur de calcul Spark effectue des modifications simultanées dans le metastore pendant l’exécution du notebook de migration, des données incohérentes peuvent être introduites dans Fabric lakehouse.
Contenu connexe
- Fabric ou Azure Synapse Spark
- En savoir plus sur les options de migration pour les pools Spark,les configurations ,les bibliothèques ,les notebooks et la définition de travail Spark