Ingérer des données dans OneLake et les analyser avec Azure Databricks
Dans ce guide, vous allez :
Créez un pipeline dans un espace de travail et ingérez des données dans OneLake au format Delta.
Lisez et modifiez une table Delta dans OneLake avec Azure Databricks.
Prérequis
Avant de commencer, vous devez avoir :
Un espace de travail avec un objet Lakehouse.
Un espace de travail Azure Databricks premium. Seuls les espaces de travail Azure Databricks premium prennent en charge le relais d'informations d'identification Microsoft Entra. Lors de la création de votre cluster, activez le passage d’informations d’identification Azure Data Lake Storage dans les options avancées.
Un exemple de jeu de données.
Ingérer des données et modifier la table Delta
Accédez à votre lakehouse dans le service Power BI et sélectionnez Obtenir des données, puis Nouveau pipeline de données.
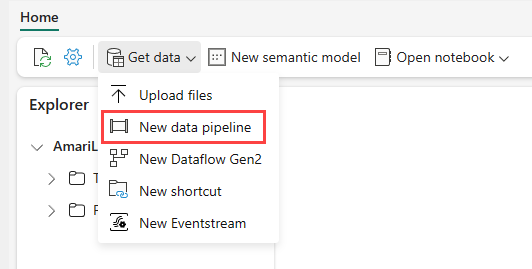
Dans l’invite Nouveau pipeline, entrez un nom pour le nouveau pipeline, puis sélectionnez Créer.
Pour cet exercice, sélectionnez l’exemple de données NYC Taxi - Green comme source de données, puis sélectionnez Suivant.
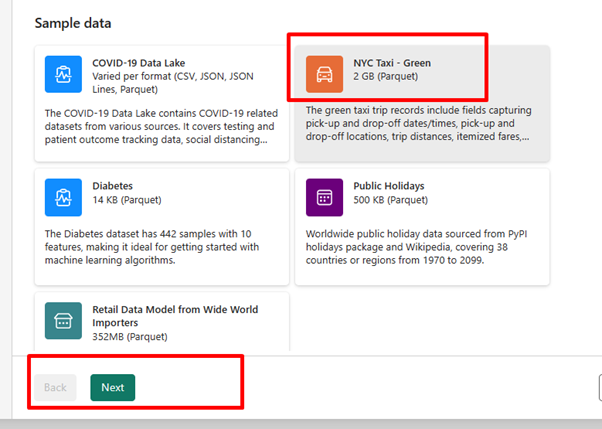
Dans l’écran d’aperçu, sélectionnez Suivant.
Pour la destination des données, sélectionnez le nom du lakehouse que vous souhaitez utiliser pour stocker les données de la table Delta OneLake. Vous pouvez choisir un lakehouse existant ou en créer un.
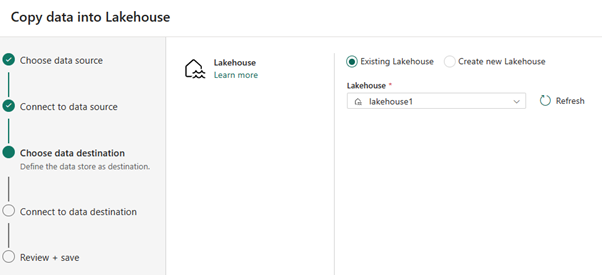
Sélectionnez l'endroit où vous souhaitez stocker la sortie. Choisissez Tables comme dossier racine et entrez « nycsample » comme nom de table.
Dans l’écran Vérifier + enregistrer, sélectionnez Démarrer le transfert de données immédiatement, puis Enregistrer + exécuter.
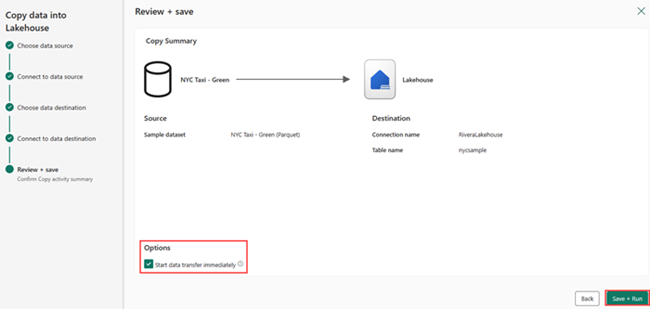
Une fois le travail terminé, accédez à votre lakehouse et affichez la table delta listée sous le dossier /Tables.
Cliquez avec le bouton droit sur le nom de la table créée, sélectionnez Propriétés, puis copiez le chemin du système de fichiers blob Azure (ABFS).
Ouvrez votre bloc-notes Azure Databricks. Lisez la table Delta sur OneLake.
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)Mettez à jour les données de table Delta en modifiant une valeur de champ.
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;