Vue d’ensemble des types de modèles dans Microsoft Syntex
S’applique à : ✓ Tous les modèles personnalisés | ✓ Tous les modèles prédéfinis
La compréhension de votre contenu dans Microsoft Syntex commence par les modèles de traitement de document. Les modèles de traitement de documents vous permettent d’identifier et de classer les documents chargés dans les bibliothèques de documents SharePoint, puis d’extraire les informations dont vous avez besoin de chaque fichier.
Lorsqu’il est appliqué à une bibliothèque de documents SharePoint, le modèle est associé à un type de contenu et comporte des colonnes pour stocker les informations extraites. Le type de contenu que vous créez est stocké dans la Galerie de types de contenu SharePoint. Vous pouvez également choisir d’utiliser des types de contenu existants pour utiliser leur schéma.
Syntex utilise des modèles personnalisés et des modèles prédéfinis.
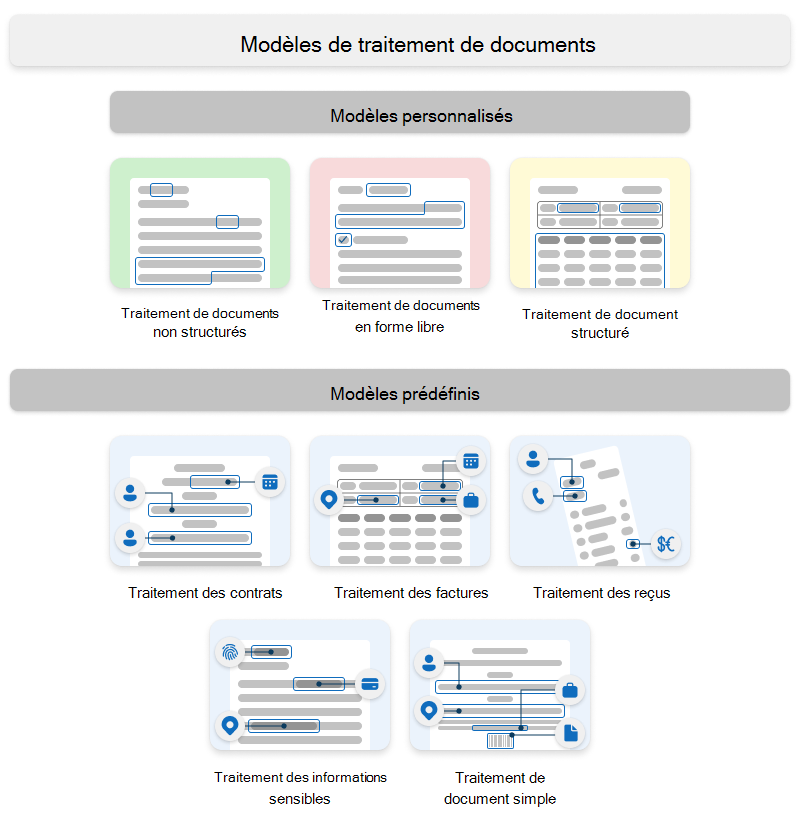
Les modèles peuvent être des modèles d’entreprise, qui sont créés dans un centre de contenu, ou des modèles locaux, qui sont créés sur votre site SharePoint local.
Modèles personnalisés
Le type de modèle personnalisé que vous choisissez dépend des types de fichiers que vous utilisez, du format et de la structure des fichiers et de l’emplacement où vous souhaitez appliquer le modèle.
Les modèles personnalisés sont les suivants :
- Traitement de documents non structurés
- Traitement de documents en forme libre
- Traitement de document structuré
Pour afficher les différences côte à côte dans les modèles personnalisés, consultez Comparer des modèles personnalisés.
Traitement de documents non structurés
Utilisez le modèle de traitement de document non structuré pour classifier automatiquement les documents et en extraire des informations. Il fonctionne de façon optimale avec les documents non structurés, tels que les lettres ou les contrats. Ces documents doivent comporter du texte qui peut être identifié sur la base de phrases ou de modèles. Le texte identifié désigne à la fois le type de fichier (sa classification) et ce que vous voulez extraire (ses extracteurs).
Par exemple, un document non structuré peut être une lettre de renouvellement de contrat, qui peut être rédigée de différentes manières. Toutefois, des informations existent systématiquement dans le corps de chaque document de renouvellement de contrat, telles que la chaîne de texte « Date de début du service de » suivie d’une date réelle.
Ce type de modèle prend en charge la plus large gamme de types de fichiers et prend en charge plus de 40 langues.
Lorsque vous créez un modèle de traitement de document non structuré, utilisez l’option Modèle de classe unique .
Pour plus d’informations, consultez Vue d’ensemble du traitement de documents non structurés.
Traitement de documents en forme libre
Utilisez le modèle de traitement de document de forme libre pour extraire automatiquement des informations à partir de documents non structurés et de forme libre, tels que des lettres et des contrats où les informations peuvent apparaître n’importe où dans le document.
Les modèles de traitement de documents de forme libre utilisent Microsoft Power Apps AI Builder pour créer et entraîner des modèles dans Syntex.
Remarque
Le modèle de traitement des documents de forme libre n’est pas encore disponible dans certaines régions. Pour plus d’informations, consultez Disponibilité des fonctionnalités par région.
Étant donné que votre organization reçoit des lettres et des documents en grande quantité à partir de diverses sources, telles que le courrier, la télécopie et l’e-mail, le traitement de ces documents et leur saisie manuelle dans une base de données peuvent prendre beaucoup de temps. En utilisant l’IA pour extraire le texte et d’autres informations de ces documents, ce modèle automatise ce processus.
Ce type de modèle est la meilleure option pour les documents au format PDF ou les fichiers image lorsque vous n’avez pas besoin de classification automatique du type de document et qu’il prend en charge plus de 40 langues.
Lorsque vous créez un modèle de traitement de document de forme libre, utilisez l’option Modèle d’extraction de forme libre.
Pour plus d’informations, consultez Vue d’ensemble du traitement de documents structurés et de forme libre.
Traitement de document structuré
Utilisez le modèle de traitement de document structuré pour identifier automatiquement les valeurs des champs et des tables. Il fonctionne mieux pour les documents structurés ou semi-structurés, tels que les formulaires et les factures.
Les modèles de traitement de documents structurés utilisent le traitement de documents Microsoft Power Apps AI Builder (anciennement appelé traitement de formulaire) pour créer et entraîner des modèles dans Syntex.
Ce type de modèle prend en charge la plus large gamme de langues et est formé pour comprendre la disposition de votre formulaire à partir d’exemples de documents, puis apprend à rechercher les données dont vous avez besoin pour extraire des emplacements similaires. Forms ont généralement une disposition plus structurée où les entités se trouvent au même emplacement (par exemple, un numéro de sécurité sociale sur un formulaire fiscal).
Lorsque vous créez un modèle de traitement de document structuré, utilisez l’option Modèle d’extraction structurée .
Pour plus d’informations, consultez Vue d’ensemble du traitement de documents structurés et de forme libre.
Modèles préconçus
Si vous n’avez pas besoin de créer un modèle personnalisé, vous pouvez utiliser un modèle de traitement de document prédéfini qui a déjà été formé pour des documents structurés spécifiques.
Les modèles prédéfinis sont les suivants :
- Traitement des contrats
- Traitement des factures
- Traitement des reçus
- Traitement des informations sensibles
- Traitement de document simple
Les modèles prédéfinis sont préformés pour reconnaître les documents et les informations structurées dans les documents. Au lieu de créer un modèle personnalisé à partir de zéro, vous pouvez itérer sur un modèle préentraîné existant pour ajouter des champs spécifiques qui répondent aux besoins de votre organization.
Traitement des contrats
Le modèle de traitement de contrat prédéfini analyse et extrait les informations clés des documents contractuels. L’API analyse les contrats dans différents formats et extrait des informations de contrat clés telles que le nom du client ou de la partie, l’adresse de facturation, la juridiction et la date d’expiration.
Pour plus d’informations sur les modèles de traitement des contrats, consultez Utiliser un modèle prédéfini pour extraire des informations à partir de contrats.
Traitement des factures
Le modèle prédéfini de traitement des factures analyse et extrait les informations clés des factures de vente. L’API analyse les factures dans différents formats et extrait les informations clés sur les factures, telles que le nom du client, l’adresse de facturation, la date d’échéance et le montant dû.
Pour plus d’informations sur les modèles de traitement des factures, consultez Utiliser un modèle prédéfini pour extraire des informations à partir de factures.
Traitement des reçus
Le modèle prédéfini de traitement des reçus analyse et extrait les informations clés des reçus. L’API analyse les reçus imprimés et manuscrits et extrait les informations de reçu clé telles que le nom du commerçant, le numéro de téléphone du commerçant, la date de transaction, la taxe et le total de la transaction.
Pour plus d’informations sur les modèles de traitement des reçus, consultez Utiliser un modèle prédéfini pour extraire des informations de reçus.
Traitement des informations sensibles
Le modèle prédéfini de traitement des informations sensibles analyse, détecte et extrait les informations clés des documents. L’API analyse les contrats dans différents formats et extrait des informations sensibles clés telles que les numéros de sécurité sociale, les numéros de compte financier, les numéros d’identification du permis de conduire et d’autres informations personnelles.
Pour plus d’informations sur les modèles de traitement des informations sensibles, consultez Utiliser un modèle prédéfini pour détecter des informations sensibles à partir de documents.
Traitement de document simple
Le modèle de traitement de document simple prédéfini offre une solution flexible et préentraînée pour extraire des paires clé-valeur, des marques de sélection et des entités nommées à partir de documents structurés de base. Contrairement à d’autres modèles prédéfinis avec des schémas fixes, ce modèle peut identifier les clés que d’autres utilisateurs peuvent manquer, ce qui offre une alternative précieuse à l’étiquetage et à l’entraînement des modèles personnalisés. Ce modèle prend également en charge les codes-barres et la détection de langue.
Pour plus d’informations sur les modèles de traitement de documents simples, consultez Utiliser un modèle prédéfini pour détecter les informations sensibles des documents.