Exporter les données Dataverse au format Delta Lake
Utilisez Azure Synapse Link for Dataverse pour exporter vos données Microsoft Dataverse à Azure Synapse Analytics au format Delta Lake. Ensuite, explorez vos données et accélérez le délai d’obtention d’informations. Cet article fournit les informations suivantes et vous montre comment effectuer les tâches suivantes :
- Explique Delta Lake et Parquet et pourquoi vous devriez exporter des données dans ce format.
- Exportez vos données Dataverse à votre espace de travail Azure Synapse Analytics au format Delta Lake avec Azure Synapse Link.
- Surveillez votre Azure Synapse Link et votre conversion de données.
- Affichez vos données depuis Azure Data Lake Storage Gen2.
- Affichez vos données depuis l’espace de travail Synapse.
Important
- Si vous effectuez une mise à niveau de CSV vers Delta Lake avec des vues personnalisées existantes, nous vous recommandons de mettre à jour le script pour remplacer toutes les tables partitionnées par des tables non partitionnées. Pour ce faire, recherchez les instances de
_partitionedet remplacez-les par une chaîne vide. - Pour la configuration de Dataverse, le mode Ajouter uniquement est activé par défaut pour exporter des données CSV au mode
appendonly. Mais la table Delta Lake aura une structure de mise à jour sur place, car la conversion Delta Lake est accompagnée d’un processus de fusion périodique. - Il n’y a aucun coût encouru avec la création de pools Spark. Les frais ne sont engagés qu’une fois qu’une tâche Spark est exécutée sur le pool Spark cible et que l’instance Spark est instanciée à la demande. Ces coûts sont liés à l’utilisation de Azure Synapse workspace Spark et sont facturés mensuellement. Le coût d’exécution de calculs Spark dépend principalement de l’intervalle de temps pour la mise à jour incrémentielle et des volumes de données. Plus d’informations : Tarification Azure Synapse Analytics
- Il est important de prendre en compte ces coûts supplémentaires lorsque vous décidez d’utiliser cette fonctionnalité, car ils ne sont pas facultatifs et doivent être payés pour continuer à utiliser cette fonctionnalité.
- Fin de vie annoncée (EOLA) pour Azure Synapse Le runtime pour Apache Spark 3.1 a été annoncé le 26 janvier 2023. Conformément à la politique de cycle de vie du runtime Synapse pour Apache Spark, le runtime d’Azure Synapse pour Apache Spark 3.1 sera retiré et désactivé à compter du 26 janvier 2024. Après la date EOL, les environnements d’exécution retirés ne sont plus disponibles pour les nouveaux pools Spark et les workflows existants ne peuvent pas s’exécuter. Les métadonnées resteront temporairement dans l’espace de travail Synapse. En savoir plus : Runtime Azure Synapse pour Apache Spark 3.1 (EOLA). Pour avoir votre lien Synapse pour Dataverse avec l’exportation au format Delta Lake, mettez à niveau vers Spark 3.3, effectuez une mise à niveau sur place pour vos profils existants. Pour plus d’informations : Mise à niveau sur place vers Apache Spark 3.3 avec Delta Lake 2.2
- À compter du 4 janvier 2024, seule la version 3.3 de Spark Pool sera prise en charge lors de la création initiale du lien.
Notes
Le statut d’Azure Synapse Link dans Power Apps (make.powerapps.com) reflète l’état de conversion de Delta Lake :
Countaffiche le nombre d’enregistrements dans la table Delta Lake.Last synchronized onDatetime représente l’horodatage de la dernière conversion réussie.Sync statusest affiché comme actif une fois la synchronisation des données et la conversion Delta Lake terminées, ce qui indique que les données sont prêtes à être consommées.
Qu’est-ce que Delta Lake ?
Delta Lake est un projet open source qui permet de créer une architecture Lakehouse au-dessus des lacs de données. Delta Lake fournit des transactions ACID (atomicité, cohérence, isolation et durabilité), une gestion évolutive des métadonnées et unifie le traitement des données en continu et par lots au-dessus des lacs de données existants. Azure Synapse Analytics est compatible avec Linux Foundation Delta Lake. La version actuelle de Delta Lake incluse avec Azure Synapse prend en charge les langues Scala, PySpark et .NET. Plus d’informations : Qu’est-ce que Delta Lake ?. Vous pouvez également en savoir plus grâce à la vidéo Introduction aux tables Delta.
Apache Parquet est le format de base pour Delta Lake, vous permettant de tirer parti des schémas de compression et d’encodage efficaces natifs du format. Le format de fichier Parquet utilise la compression par colonne. Il est efficace et économise de l’espace de stockage. Les requêtes qui récupèrent des valeurs de colonne spécifiques n’ont pas besoin de lire l’intégralité des données de la ligne, ce qui améliore les performances. Par conséquent, le pool SQL sans serveur nécessite moins de temps et moins de demandes de stockage pour lire les données.
Pourquoi utiliser Delta Lake ?
- Évolutivité : Delta Lake repose sur une licence Apache open source, conçue pour répondre aux normes de l’industrie en matière de gestion des charges de travail de traitement de données à grande échelle.
- Fiabilité : Delta Lake fournit des transactions ACID, garantissant la cohérence et la fiabilité des données même en cas de pannes ou d’accès simultanés.
- Performances : Delta Lake exploite le format de stockage en colonnes de Parquet, offrant de meilleures techniques de compression et d’encodage, ce qui peut améliorer les performances des requêtes par rapport aux fichiers CSV de requête.
- Rentable : le format de fichier Delta Lake est une technologie de stockage de données hautement compressées qui offre des économies de stockage potentielles importantes pour les entreprises. Ce format est spécialement conçu pour optimiser le traitement des données et potentiellement réduire la quantité totale de données traitées ou le temps d’exécution requis pour le calcul à la demande.
- Conformité en matière de protection des données : Delta Lake avec Azure Synapse Link fournit des outils et des fonctionnalités, y compris la suppression temporaire et la suppression définitive, pour se conformer à diverses réglementations sur la confidentialité des données, notamment le Règlement général sur la protection des données (RGPD).
Comment Delta Lake fonctionne-t-il avec Azure Synapse Link for Dataverse ?
Lors de la configuration d’un Azure Synapse Link for Dataverse, vous pouvez activer la fonction Exporter vers Delta Lake et vous connecter à un espace de travail Synapse et à un pool Spark. Azure Synapse Link exporte les tables Dataverse sélectionnées au format CSV à des intervalles de temps désignés, en les traitant via une tâche Spark de conversion de Delta Lake. À la fin de ce processus de conversion, les données CSV sont nettoyées pour être sauvegardées. De plus, une série de tâches de maintenance sont programmées pour s’exécuter quotidiennement, effectuant automatiquement des processus de compactage et de nettoyage pour fusionner et nettoyer les fichiers de données afin d’optimiser davantage le stockage et d’améliorer les performances des requêtes.
Conditions préalables
- Dataverse : vous devez disposer du rôle de sécurité Dataverse Administrateur système. De plus, les tables que vous souhaitez exporter via Azure Synapse Link doivent avoir la propriété Suivi des modifications activée. Pour plus d’informations, voir Options avancées
- Azure Data Lake Storage Gen2 : vous devez avoir un compte Azure Data Lake Storage Gen2 et un accès au rôle de Propriétaire et de Contributeur aux données d’objets Blob de stockage. Votre compte de stockage doit activer Espace de noms hiérarchique et Accès au réseau public pour la configuration initiale et la synchronisation delta. Le paramètre Autoriser l’accès aux clés du compte de stockage est requis uniquement pour la configuration initiale.
- Espace de travail Synapse : Vous devez avoir un espace de travail Synapse ainsi que le rôle Propriétaire dans le contrôle d’accès (IAM) et l’accès au rôle Administrateurs Synapse dans Synapse Studio. L’espace de travail Synapse doit être dans la même région que votre compte Azure Data Lake Storage Gen2. Le compte de stockage doit être ajouté en tant que service lié dans Synapse Studio. Pour créer un espace de travail Synapse, accédez à Création d'un espace de travail Synapse.
- Un pool dans l’espace de travail connecté avec la version 3.3 utilisant cette configuration Spark Pool recommandée Apache Spark . Azure Synapse Apache Spark ... Pour plus d’informations sur le mode de création d’un pool Spark, accédez à Créer un pool Apache Spark.
- La version Microsoft Dynamics 365 minimum requise pour utiliser cette fonctionnalité est 9.2.22082. Plus d’informations : Activer les mises à jour à accès anticipé
Configuration recommandée du pool Spark
Cette configuration peut être considérée comme une étape d’amorçage pour les cas d’utilisation moyens.
- Taille du nœud : petite (4 vCores / 32 Go)
- Mise à l’échelle automatique : Activé
- Nombre de nœuds : 5 à 10
- Pause automatique : activée
- Nombre de minutes d’inactivité : 5
- Apache Spark : 3.3
- Allouer dynamiquement des exécuteurs : activé
- Nombre d’exécuteurs par défaut : 1 à 9
Important
Utilisez le pool Spark exclusivement pour l’opération de conversation Delta Lake avec Synapse Link pour Dataverse. Pour une fiabilité et des performances optimales, évitez d’exécuter d’autres tâches Spark en utilisant le même pool Spark.
Connecter Dataverse à l’espace de travail Synapse et exporter les données au format Delta Lake
Connectez-vous à Power Apps et sélectionnez l’environnement de votre choix.
Dans le volet de navigation de gauche, sélectionnez Azure Synapse Link. Si l’élément ne se trouve pas dans le volet latéral, sélectionnez …Plus, puis sélectionnez l’élément souhaité.
Dans la barre de commandes, sélectionnez + Nouveau lien
Sélectionnez Se connecter à votre espace de travail Azure Synapse Analytics, puis sélectionnez Abonnement, Groupe de ressources et Nom de l’espace de travail.
Sélectionnez Utiliser le pool Spark pour le traitement, puis sélectionnez le Pool Spark précréé et le Compte de stockage.
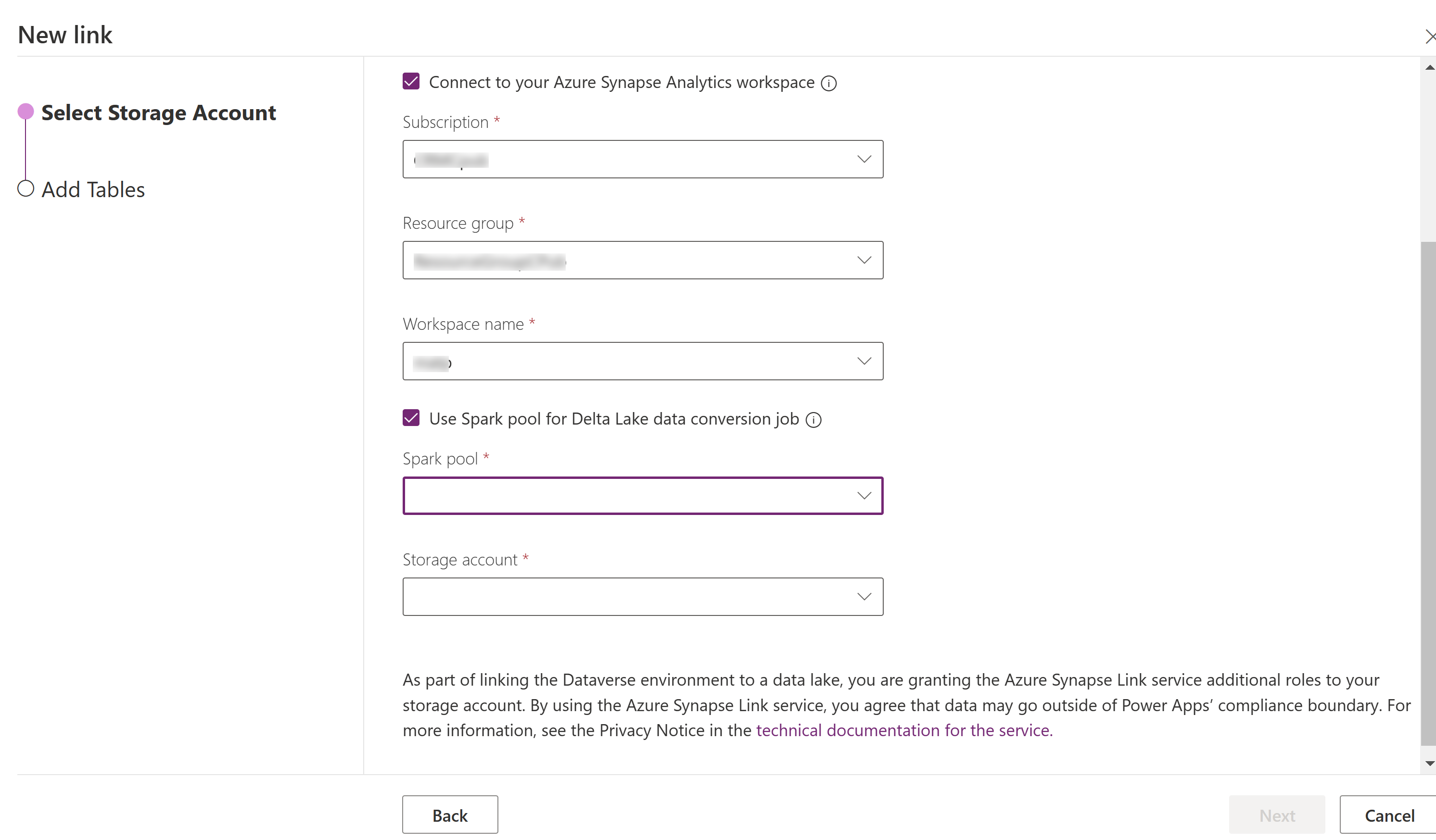
Cliquez sur Suivant.
Ajoutez les tables que vous souhaitez exporter, puis sélectionnez Avancé.
Si nécessaire, sélectionnez Afficher les paramètres de configuration avancée et saisissez l’intervalle de temps, en minutes, pour la fréquence à laquelle les mises à jour incrémentielles doivent être configurées.
Cliquez sur Enregistrer.
Surveiller votre Azure Synapse Link et votre conversion de données
- Sélectionnez le Azure Synapse Link que vous souhaitez, puis sélectionnez Accéder à l’espace de travail Azure Synapse Analytics dans la barre de commandes.
- Sélectionnez Surveiller > Applications Apache Spark. Plus d’informations : Utiliser Synapse Studio pour surveiller vos applications Apache Spark
Afficher vos données depuis l’espace de travail Synapse
- Sélectionnez le Azure Synapse Link que vous souhaitez, puis sélectionnez Accéder à l’espace de travail Azure Synapse Analytics dans la barre de commandes.
- Développez Bases de données Data Lake dans le volet de gauche, sélectionnez dataverse-environmentNameorganizationUniqueName, puis développez Tables. Toutes les tables Parquet sont répertoriées et disponibles pour analyse avec la convention de dénomination DataverseTableName. (Table Non_partitioned).
Notes
N’utilisez pas de tables avec la convention de dénomination _partitioned. Lorsque vous choisissez Delta Parquet comme format, les tables avec la convention de dénomination _partition sont utilisées comme tables intermédiaires et supprimées une fois utilisées par le système.
Afficher vos données depuis Azure Data Lake Storage Gen2
- Sélectionnez le Azure Synapse Link souhaité, puis sélectionnez Accéder à Azure Data Lake dans la barre de commandes.
- Sélectionnez les Conteneurs en dessous de Stockage de données.
- Sélectionnez dataverse- environmentName-organizationUniqueName. Tous les fichiers Parquet sont stockés dans le dossier deltalake.
Mise à niveau sur place vers Apache Spark 3.3 avec Delta Lake 2.2
Conditions préalables
- Vous devez avoir un profil Delta Lake Azure Synapse Link for Dataverse existant qui s’exécute avec un Synapse Spark version 3.1.
- Vous devez créer un nouveau pool Synapse Spark avec Spark version 3.3, en utilisant la même configuration matérielle de nœuds ou une configuration supérieure dans le même espace de travail Synapse. Pour plus d’informations sur le mode de création d’un pool Spark, accédez à Créer un pool Apache Spark. Ce pool Spark doit être créé indépendamment du pool 3.1 actuel.
Mise à niveau sur place vers Spark 3.3 :
- Connectez-vous à Power Apps et sélectionnez votre environnement préféré.
- Dans le volet de navigation de gauche, sélectionnez Azure Synapse Link. Si l’élément ne se trouve pas dans le volet de navigation de gauche, sélectionnez …Plus, puis sélectionnez l’élément souhaité.
- Ouvrez le profil Azure Synapse Link, puis sélectionnez Mise à niveau vers Apache Spark 3.3 avec Delta Lake 2.2.
- Sélectionnez le pool Spark disponible dans la liste, puis sélectionnez Mettre à jour.
Notes
La mise à niveau du pool Spark se produit uniquement lorsqu’une nouvelle tâche Spark de conversion Delta Lake est déclenchée. Assurez-vous d’avoir au moins une modification de données après avoir sélectionné Mise à jour.