Filtro del contenuto nel portale di Azure AI Foundry
Azure AI Foundry include un sistema di filtro dei contenuti che funziona insieme ai modelli di base e ai modelli di generazione di immagini DALL-E.
Importante
Il sistema di filtro del contenuto non viene applicato a richieste e completamenti elaborati dal modello Whisper nel Servizio OpenAI di Azure. Altre informazioni sul modello Whisper in Azure OpenAI.
Funzionamento
Questo sistema di filtro dei contenuti è basato su Sicurezza dei contenuti di Azure AI e funziona eseguendo sia l'input richiesto che l'output di completamento tramite un insieme di modelli di classificazione volti a rilevare e prevenire l'output di contenuti dannosi. Le variazioni nelle configurazioni dell'API e nella progettazione dell'applicazione potrebbero influire sui completamenti e quindi sul comportamento di filtro.
Con le distribuzioni del modello OpenAI di Azure, è possibile usare il filtro contenuto predefinito o creare un filtro contenuto personalizzato (descritto più avanti). Il filtro di contenuto predefinito è disponibile anche per altri modelli di testo curati da Azure AI nel catalogo dei modelli, ma i filtri di contenuto personalizzati non sono ancora disponibili per tali modelli. I modelli disponibili tramite Modelli come servizio hanno il filtro del contenuto abilitato per impostazione predefinita e non possono essere configurati.
Supporto di versioni in lingue diverse
I modelli di filtro del contenuto sono stati sottoposti a training e testati nelle lingue seguenti: inglese, tedesco, giapponese, spagnolo, francese, italiano, portoghese e cinese. Tuttavia, il servizio può funzionare in molte altre lingue, ma la qualità può variare. In tutti i casi, è necessario eseguire test personalizzati per assicurarsi che funzioni per l'applicazione.
Filtri di rischio per il contenuto (filtri di input e output)
I filtri speciali seguenti funzionano sia per l'input che per l'output dei modelli di intelligenza artificiale generativi:
Categorie
| Categoria | Descrizione |
|---|---|
| Hate | La categoria di odio descrive gli attacchi o gli usi linguistici che includono linguaggio offensivo o discriminatorio con riferimento a una persona o a un gruppo di identità basato su determinati attributi distintivi di questi gruppi, tra cui, a titolo esemplificativo, razza, etnia, nazionalità, identità di genere ed espressione, orientamento sessuale, religione, stato di immigrazione, stato di abilità, aspetto personale e dimensioni del corpo. |
| Contenuti sessuali | La categoria contenuto sessuale descrive linguaggio correlato a organi anatomici e genitali, relazioni romantiche, atti rappresentati in termini erotici o affettuosi, atti sessuali fisici, compresi quelli rappresentati come violenza sessuale o stupro, prostituzione, pornografia e abuso. |
| Violenza | La categoria violenza descrive linguaggio relativo ad azioni fisiche che hanno lo scopo di ferire, lesionare, danneggiare o uccidere qualcuno o qualcosa; descrive armi, ecc. |
| Autolesionismo | La categoria autolesionismo descrive il linguaggio correlato ad azioni fisiche che hanno lo scopo di ferire, lesionare o danneggiare il proprio corpo oppure a togliersi la vita. |
Livelli di gravità
| Categoria | Descrizione |
|---|---|
| Safe | I contenuti possono essere correlati a violenza, autolesionismo, argomenti sessuali o odio, ma i termini sono utilizzati in un contesto generale, giornalistico, scientifico, medico o altro contesto professionale simile, cosa appropriata per la maggior parte dei destinatari. |
| Basso | Contenuti che esprimono opinioni pregiudizievoli, giudicanti o polemiche, incluso l'uso di linguaggio offensivo, stereotipi, casi d'uso che esplorano un mondo di fantasia (ad esempio, videogiochi o letteratura) e rappresentazioni a bassa intensità. |
| Medio | Contenuti che usano linguaggio offensivo, derisorio, insultante, intimidatorio o sminuente verso gruppi di identità specifici, incluse rappresentazioni volte a cercare e seguire istruzioni, fantasie e glorificazioni dannose e promozione di violenza a media intensità. |
| Alta | Contenuti che mostrano istruzioni esplicite e pericolose, azioni, danni o abusi; include l'approvazione, la glorificazione o la promozione di gravi atti pericolosi, forme estreme o illegali di pericolo, radicalizzazione oppure scambi e abusi di potere non consensuali. |
Altri filtri di input
È inoltre possibile abilitare filtri speciali per gli scenari di IA generativa:
- Attacchi con jailbreak: gli attacchi con jailbreak sono prompt degli utenti progettati per indurre il modello di intelligenza artificiale generativa a esibire comportamenti che è stato addestrato a evitare o a infrangere le regole stabilite nel messaggio di sistema.
- Attacchi indiretti: gli attacchi indiretti, detti anche attacchi con prompt indiretto o attacchi con iniezione di prompt cross-domain, rappresentano una potenziale vulnerabilità in cui terze parti inseriscono istruzioni dannose all'interno di documenti a cui il sistema di intelligenza artificiale generativa può accedere ed elaborare.
Altri filtri di output
È anche possibile abilitare i filtri di output speciali seguenti:
- Materiale protetto per il testo: il materiale testuale protetto descrive contenuti testuali noti (ad esempio, testi di canzoni, articoli, ricette e contenuti Web selezionati) che possono essere prodotti da modelli linguistici di grandi dimensioni.
- Materiale protetto per il codice: il codice materiale protetto descrive il codice sorgente che corrisponde a un set di codice sorgente da repository pubblici, che possono essere prodotti da modelli linguistici di grandi dimensioni senza un'adeguata citazione dei repository di origine.
- Allineamento: il filtro di rilevamento dell'integrità rileva se le risposte testuali dei modelli linguistici di grandi dimensioni (LLM) sono fondate sui materiali di origine forniti dagli utenti.
Creare un filtro di contenuto
Per qualsiasi distribuzione di modelli in Azure AI Foundry, è possibile usare direttamente il filtro contenuto predefinito, ma potrebbe essere necessario avere più controllo. Ad esempio, è possibile rendere un filtro più rigoroso o più indulgente o abilitare funzionalità più avanzate, ad esempio schermate di richiesta e rilevamento dei materiali protetti.
Per creare un filtro di contenuto, seguire questa procedura:
Passare a AI Foundry e passare al progetto o all'hub. Selezionare quindi la scheda Sicurezza e sicurezza nel riquadro di spostamento a sinistra e selezionare i filtri contenuto.
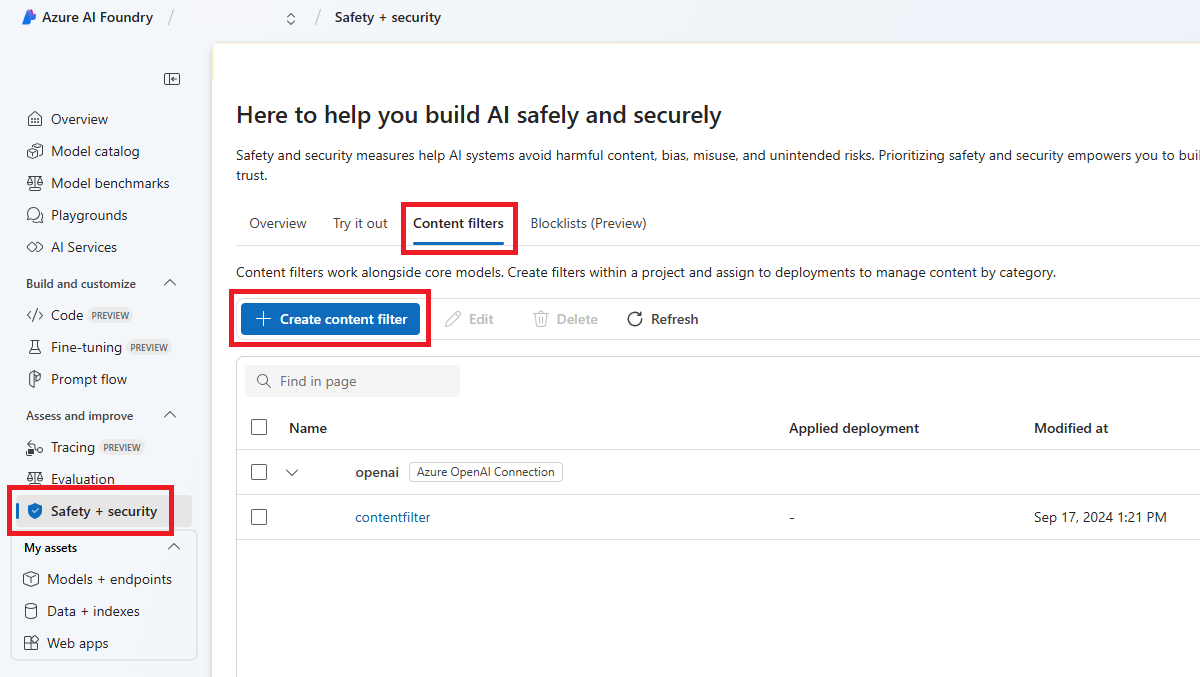
Nella pagina Informazioni di base immettere un nome per il filtro di contenuto. Selezionare una connessione da associare al filtro di contenuto. Quindi seleziona Avanti.
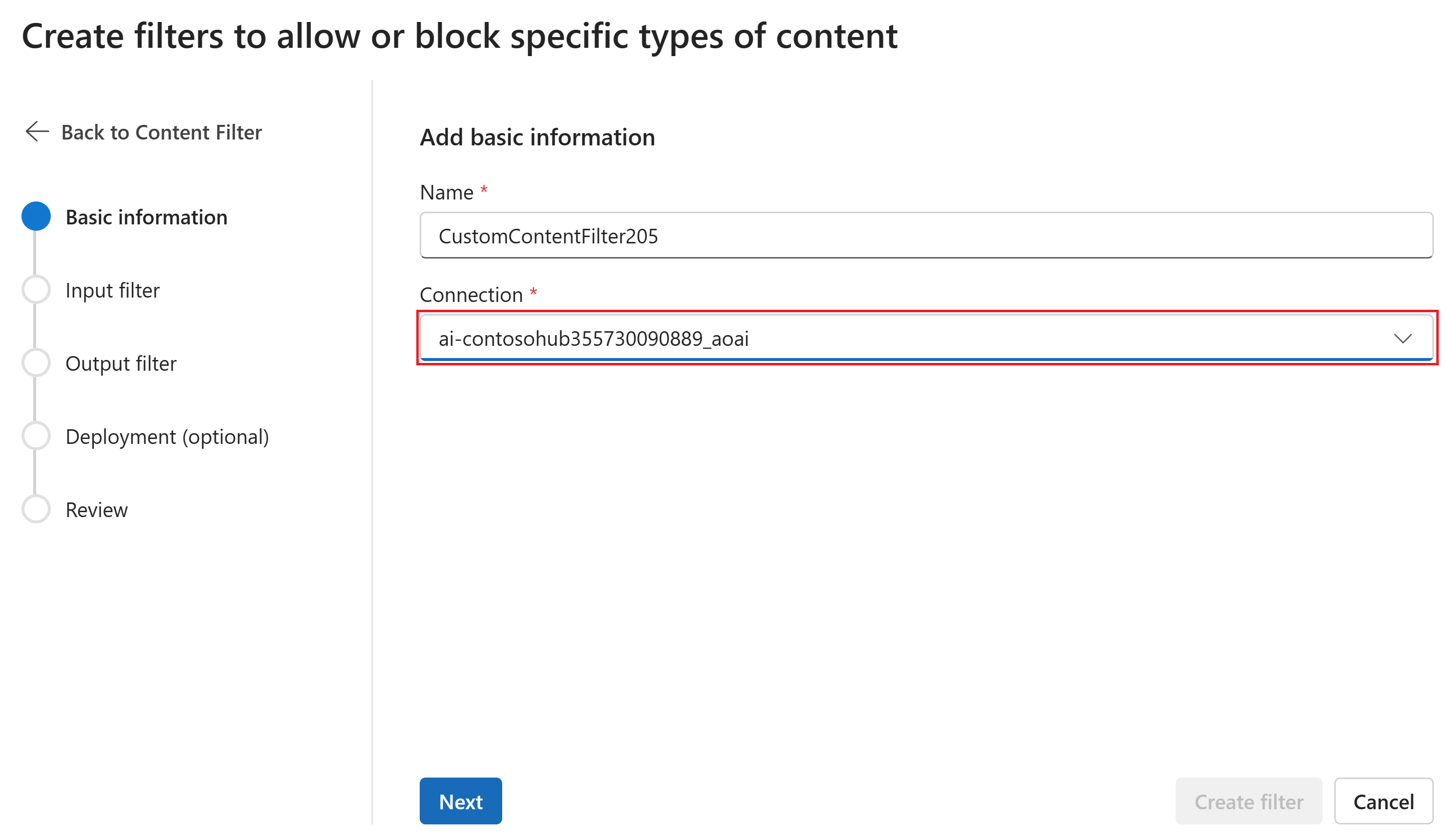
Selezionare Crea filtro contenuto.
Nella pagina Filtri di input è possibile impostare il filtro per il prompt di input. Impostare la soglia del livello di azione e di gravità per ogni tipo di filtro. In questa pagina vengono configurati sia i filtri predefiniti che altri filtri (ad esempio Prompt Shields per gli attacchi jailbreak). Quindi seleziona Avanti.

Il contenuto verrà annotato per categoria e bloccato in base alla soglia impostata. Per le categorie violenza, odio, sesso e autolesionismo, regolare il dispositivo di scorrimento per bloccare i contenuti di gravità alta, media o bassa.
Nella pagina Filtri di output è possibile configurare il filtro di output, che verrà applicato a tutto il contenuto di output generato dal modello. Configurare i singoli filtri come in precedenza. Questa pagina offre anche l'opzione Modalità streaming, che consente di filtrare i contenuti quasi in tempo reale mentre vengono generati dal modello, riducendo la latenza. Al termine, fare clic su Avanti.
Il contenuto verrà annotato per ogni categoria e bloccato in base alla soglia. Per i contenuti violenti, i contenuti di odio, i contenuti sessuali e i contenuti autolesionistici, regolare la soglia per bloccare i contenuti dannosi con livelli di gravità uguali o superiori.
Facoltativamente, nella pagina Distribuzione è possibile associare il filtro di contenuto a una distribuzione. Se una distribuzione selezionata include già un filtro associato, è necessario confermare che si vuole sostituirlo. È anche possibile associare il filtro di contenuto a una distribuzione in un secondo momento. Seleziona Crea.

Le configurazioni di filtro del contenuto vengono create a livello di hub nel portale di AI Foundry. Altre informazioni sulla configurabilità sono disponibili nella documentazione di Azure OpenAI.
Nella pagina Rivedi esaminare le impostazioni e quindi selezionare Crea filtro.




Usare un elenco di blocchi come filtro
È possibile applicare un elenco di elementi bloccati come filtro di input o output o entrambi. Abilitare l'opzione Elenco di elementi bloccati nella pagina Filtro input e/o Filtro output. Selezionare uno o più elenchi di elementi bloccati dall'elenco a discesa, oppure usare l'elenco di elementi bloccati dei contenuti volgari integrato. È possibile combinare più elenchi di elementi bloccati nello stesso filtro.
Applicare un filtro contenuto
Il processo di creazione del filtro offre la possibilità di applicare il filtro alle distribuzioni desiderate. È anche possibile modificare o rimuovere filtri di contenuto dalle distribuzioni in qualsiasi momento.
Per applicare un filtro di contenuto a una distribuzione, seguire questa procedura:
Passare a Ai Foundry e selezionare un hub e un progetto.
Selezionare Modelli e endpoint nel riquadro sinistro e scegliere una delle distribuzioni e quindi selezionare Modifica.

Nella finestra Distribuzione aggiornamenti selezionare il filtro di contenuto da applicare alla distribuzione.
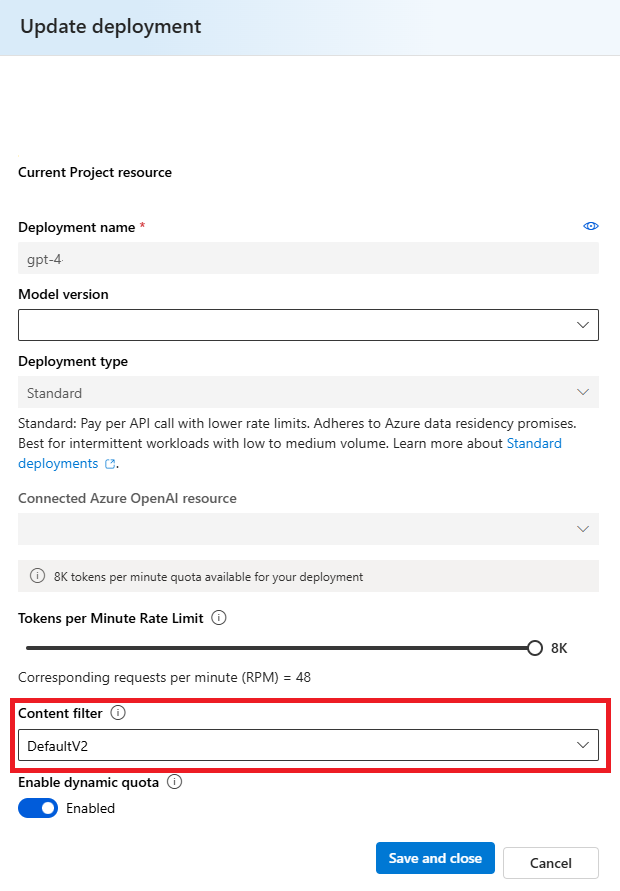


È ora possibile passare al playground per verificare se il filtro del contenuto funziona come previsto.
Configurabilità (anteprima)
La configurazione predefinita di filtro dei contenuti per la serie di modelli GPT è impostata per filtrare in base alla soglia di gravità media per tutte e quattro le categorie di danno da contenuto (odio, violenza, sesso e autolesionismo) e si applica sia ai prompt (testo, testo/immagini multimodali) che ai completion (testo). Ciò implica che i contenuti rilevati con livello di gravità medio o alto vengono filtrati, mentre i contenuti rilevati con livello di gravità basso non vengono filtrati in base ai filtri dei contenuti. Per DALL-E, la soglia di gravità predefinita è impostata su bassa sia per i prompt (testo) che per i completion (immagini), quindi i contenuti rilevati con livelli di gravità bassi, medi o alti vengono filtrati.
La funzionalità di configurabilità consente ai clienti di modificare le impostazioni (separatamente per prompt e completamenti) in modo da filtrare contenuto per ogni categoria di contenuto a livelli di gravità diversi, come descritto nella tabella seguente:
| Intensità del filtro | Configurabile per richieste | Configurabile per completamenti | Descrizione |
|---|---|---|---|
| Basso, medio, elevato | Sì | Sì | Configurazione di filtraggio più intenso. Il contenuto rilevato a livelli di gravità basso, medio e alto viene filtrato. |
| Medio, alto | Sì | Sì | Il contenuto rilevato con livello di gravità basso non viene filtrato, il contenuto a livello medio e alto viene filtrato. |
| Alto | Sì | Sì | Il contenuto rilevato a livelli di gravità basso e medio non viene filtrato. Viene filtrato solo il contenuto a livello di gravità elevato. Richiede approvazione1. |
| Nessun filtro | Se approvato1 | Se approvato1 | Nessun contenuto viene filtrato indipendentemente dal livello di gravità rilevato. Richiede approvazione1. |
1 Per i modelli OpenAI di Azure, solo i clienti che sono stati approvati per il filtro del contenuto modificato hanno il controllo completo del filtro del contenuto, inclusa la configurazione dei filtri di contenuto a livello di gravità elevato o la disattivazione dei filtri di contenuto. Applicare i filtri di contenuto modificati tramite questo modulo: Verifica di accesso limitato di OpenAI di Azure: filtri di contenuto modificati e monitoraggio degli abusi (microsoft.com)
I clienti sono responsabili di garantire che le applicazioni che integrano Azure OpenAI siano conformi al Codice di comportamento.
Passaggi successivi
- Ulteriori informazioni sui modelli alla base di OpenAI di Azure.
- Il filtro dei contenuti di Azure AI Foundry è basato su Sicurezza dei contenuti di Intelligenza artificiale di Azure.
- Altre informazioni sulla comprensione e la mitigazione dei rischi associati all'applicazione: Panoramica delle procedure di intelligenza artificiale responsabili per i modelli OpenAI di Azure.
- Altre informazioni sulla valutazione dei modelli di intelligenza artificiale generativi e dei sistemi di intelligenza artificiale tramite Valutazione dell'intelligenza artificiale di Azure.