Rendere operativa la mesh di dati per la progettazione di funzionalità basate su dominio di Intelligenza artificiale/Machine Learning
La Data Mesh consente alle organizzazioni di passare da un data lake o un data warehouse centralizzato a una decentralizzazione guidata dal dominio dell'analisi dei dati, sottolineata da quattro principi: Proprietà del dominio, Dati come prodotto, Piattaforma dati self-service e Governance computazionale federata. data mesh offre i vantaggi della proprietà dei dati distribuita e una migliore qualità e governance dei dati, che accelera il business e riduce il tempo per ottenere valore per le organizzazioni.
Implementazione del data mesh
Un'implementazione tipica di data mesh include team di settori con ingegneri dei dati che sviluppano pipeline di dati. Il team gestisce archivi dati operativi e analitici, ad esempio data lake, data warehouse o data lakehouse. Rilasciano le pipeline come prodotti di dati affinché siano utilizzati da altri team di dominio o team di data science. Altri team usano i prodotti dati usando una piattaforma di governance dei dati centrale, come illustrato nel diagramma seguente.
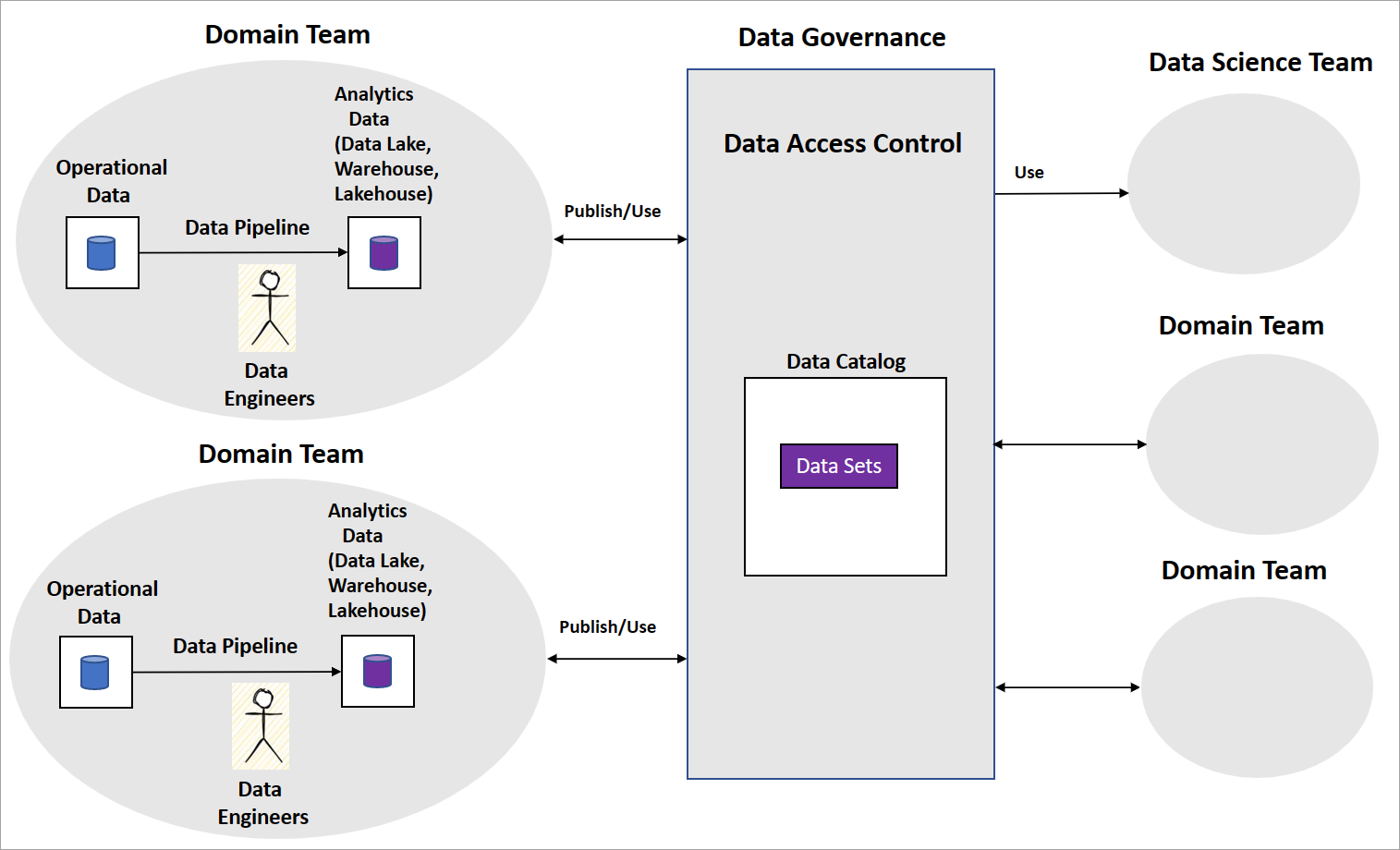
Data mesh è chiaro su come i prodotti di dati servono set di dati trasformati e aggregati per la business intelligence. Ma non è esplicito sull'approccio che le organizzazioni devono adottare per creare modelli di intelligenza artificiale/Machine Learning. Non sono disponibili indicazioni su come strutturare i team di data science, la governance del modello di intelligenza artificiale/Machine Learning e come condividere modelli o funzionalità di intelligenza artificiale/Machine Learning tra i team di dominio.
La sezione seguente illustra un paio di strategie che le organizzazioni possono usare per sviluppare funzionalità di intelligenza artificiale/Machine Learning all'interno della mesh di dati. Visualizzi una proposta per una strategia sull'ingegneria delle funzionalità basate su dominio o sulla rete di funzionalità.
Strategie di intelligenza artificiale e apprendimento automatico per data mesh
Una strategia comune consiste nell'integrare i team di data science in qualità di consumatori di dati. Questi team accedono a vari prodotti di dati di dominio nella rete di dati a seconda del caso d'uso. Eseguono l'esplorazione dei dati e la progettazione di funzionalità per sviluppare e creare modelli di intelligenza artificiale/Machine Learning. In alcuni casi, i team di dominio sviluppano anche i propri modelli di intelligenza artificiale/Machine Learning usando i propri dati e i prodotti dati di altri team per estendere e derivare nuove funzionalità.
progettazione delle funzionalità è il nucleo della creazione di modelli ed è in genere complesso e richiede competenze di dominio. Questa strategia può richiedere molto tempo perché i team di data science devono analizzare vari prodotti dati. Potrebbero non avere una conoscenza completa del dominio per creare funzionalità di alta qualità. La mancanza di conoscenze sul dominio può causare attività di progettazione delle funzionalità duplicate tra i team di dominio. Inoltre, problemi come la riproducibilità del modello di intelligenza artificiale/Machine Learning a causa di set di funzionalità incoerenti tra i team. I team di data science o di dominio devono aggiornare continuamente le funzionalità man mano che vengono rilasciate nuove versioni dei prodotti dati.
Un'altra strategia per i team di dominio è di rilasciare modelli di intelligenza artificiale/Machine Learning nel formato Open Neural Network Exchange (ONNX), ma questi risultati sono scatole nere e combinare modelli o funzionalità di intelligenza artificiale/Machine Learning tra domini sarebbe difficile.
Esiste un modo per decentralizzare il modello di intelligenza artificiale/Machine Learning tra i team di data science e di dominio per affrontare le sfide? La strategia proposta di ingegneria delle caratteristiche basata su dominio o reti di caratteristiche è un'opzione.
Ingegneria di funzionalità orientata al dominio o mesh di funzionalità
La strategia di ingegneria delle caratteristiche o rete di caratteristiche basata sul dominio offre un approccio decentralizzato alla creazione di modelli di intelligenza artificiale/Machine Learning in un contesto di data mesh. Il diagramma seguente illustra la strategia e come essa affronta i quattro principi fondamentali del data mesh.
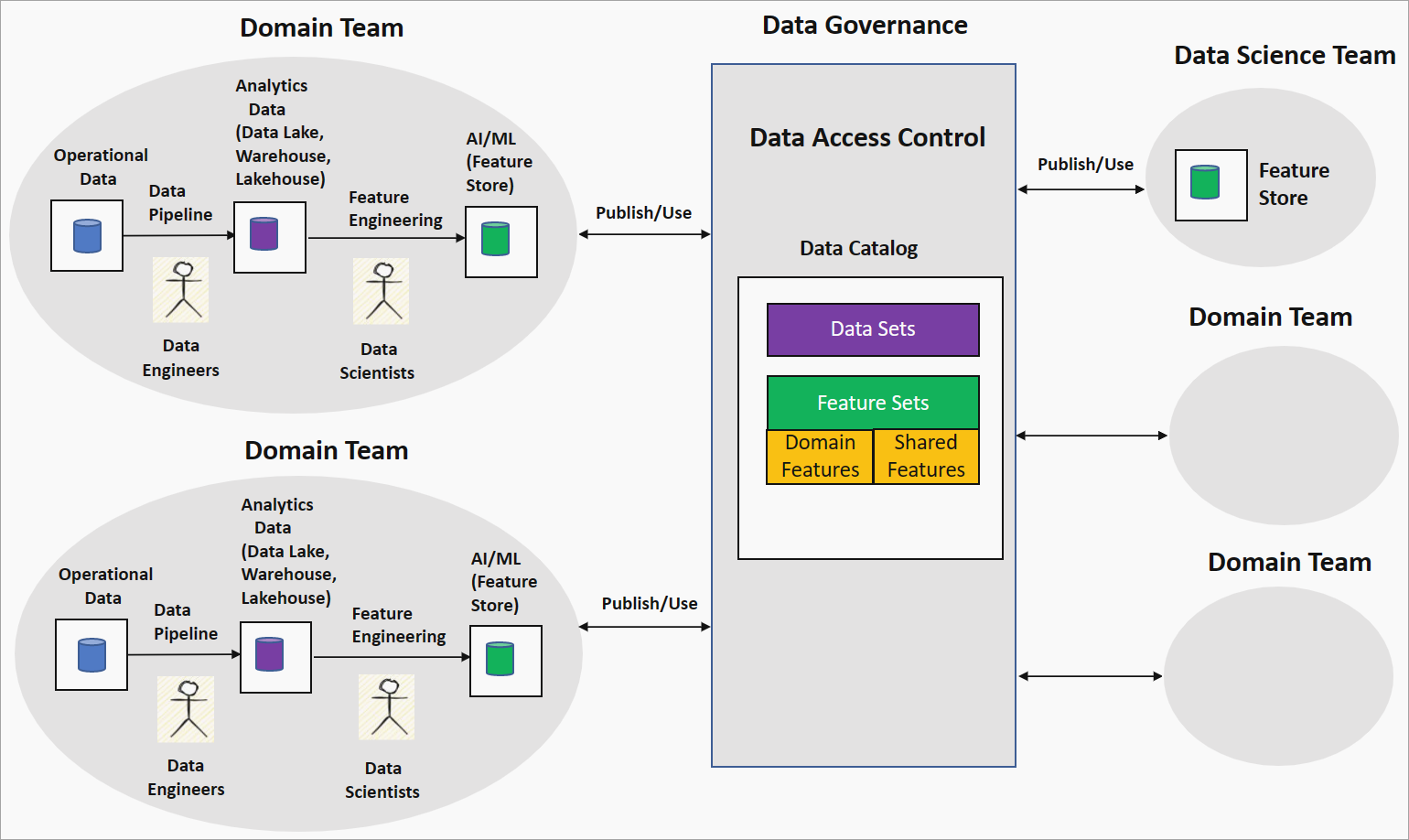
Progettazione delle funzionalità relative alla proprietà del dominio da parte dei team di dominio
In questa strategia, l'organizzazione affianca data scientist e data engineer in un team di dominio per effettuare l'esplorazione dei dati su dati puliti e trasformati in, ad esempio, un data lake. La progettazione genera caratteristiche che vengono archiviate in un archivio di caratteristiche. Un archivio funzionalità è un repository di dati che fornisce funzionalità per il training e l'inferenza e consente di tenere traccia delle versioni delle funzionalità, dei metadati e delle statistiche. Questa funzionalità consente ai data scientist del team di dominio di collaborare con esperti di dominio e di mantenere aggiornate le funzionalità man mano che i dati cambiano nel dominio.
Dati come prodotto: set di funzionalità
Le funzionalità generate dal team di dominio, note come funzionalità locali o di dominio, vengono pubblicate nel catalogo dati nella piattaforma di governance dei dati come set di funzionalità. Questi set di funzionalità vengono usati dai team di data science o da altri team di dominio per la creazione di modelli di intelligenza artificiale/Machine Learning. Durante lo sviluppo di modelli di intelligenza artificiale/Machine Learning, i team di data science o di dominio possono combinare funzionalità di dominio per produrre nuove funzionalità, denominate funzionalità condivise o globali. Queste funzionalità condivise vengono pubblicate nuovamente nel catalogo dei set di funzionalità per l'utilizzo.
Piattaforma dati self-service e governance del calcolo federato: standardizzazione e qualità delle funzionalità
Questa strategia può portare all'adozione di uno stack tecnologico diverso per le pipeline di ingegneria delle caratteristiche e a definizioni di caratteristiche incoerenti tra i team di dominio. I principi della piattaforma dati self-service assicurano che i team di dominio usino un'infrastruttura e strumenti comuni per creare le pipeline di progettazione delle funzionalità e applicare il controllo di accesso. Il principio federativo di governance computazionale garantisce l'interoperabilità dei set di funzionalità tramite la standardizzazione globale e i controlli sulla qualità delle funzionalità.
L'uso della strategia di ingegneria delle caratteristiche basata sul dominio o strategia feature mesh offre un approccio decentralizzato alla creazione di modelli di intelligenza artificiale/apprendimento automatico per le organizzazioni, aiutando a ridurre il tempo necessario per lo sviluppo dei modelli di intelligenza artificiale/apprendimento automatico. Questa strategia consente di mantenere le funzionalità coerenti tra i team di dominio. Evita la duplicazione delle attività e comporta funzionalità di alta qualità per modelli di intelligenza artificiale/Machine Learning più accurati, che aumentano il valore per l'azienda.
Implementazione del data mesh in Azure
Questo articolo descrive i concetti relativi all'operazionalizzazione di intelligenza artificiale/Machine Learning in una mesh di dati e non illustra gli strumenti o le architetture per creare queste strategie. Azure offre archivi di funzionalità come Azure Databricks feature store e Feathr da LinkedIn. È possibile sviluppare connettori personalizzati Microsoft Purview per gestire e governare gli store di funzionalità.