Motore di ingestione indipendente dai dati
Questo articolo illustra come implementare scenari di motore di inserimento indipendenti dai dati usando una combinazione di PowerApps, App per la logica di Azure e attività di copia basate sui metadati all'interno di Azure Data Factory.
Gli scenari del motore di acquisizione indipendente dai dati in genere mirano a consentire agli utenti non tecnici (non data engineer) di pubblicare risorse di dati in un Data Lake per ulteriore elaborazione. Per implementare questo scenario, è necessario disporre di funzionalità di onboarding che abilitano:
- Registrazione dell'assetto di dati
- Approvisionamento del flusso di lavoro e acquisizione dei metadati
- Pianificazione dell'ingestione
È possibile vedere come interagiscono queste funzionalità:
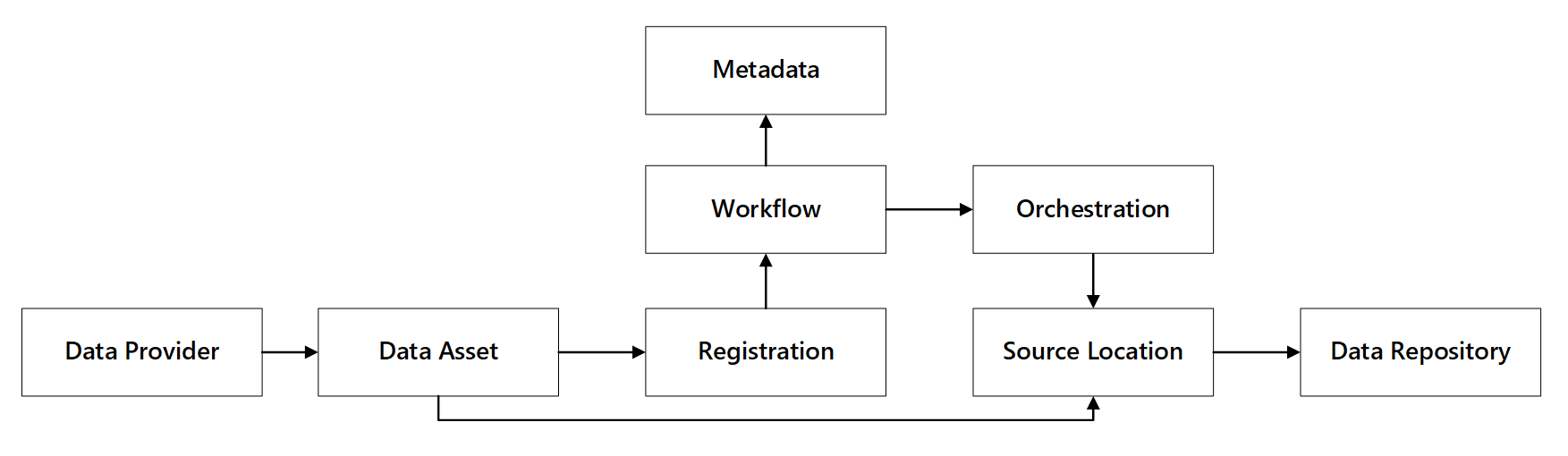
Figura 1: Interazioni con le funzionalità di registrazione dei dati.
Il diagramma seguente illustra come implementare questo processo usando una combinazione di servizi di Azure:
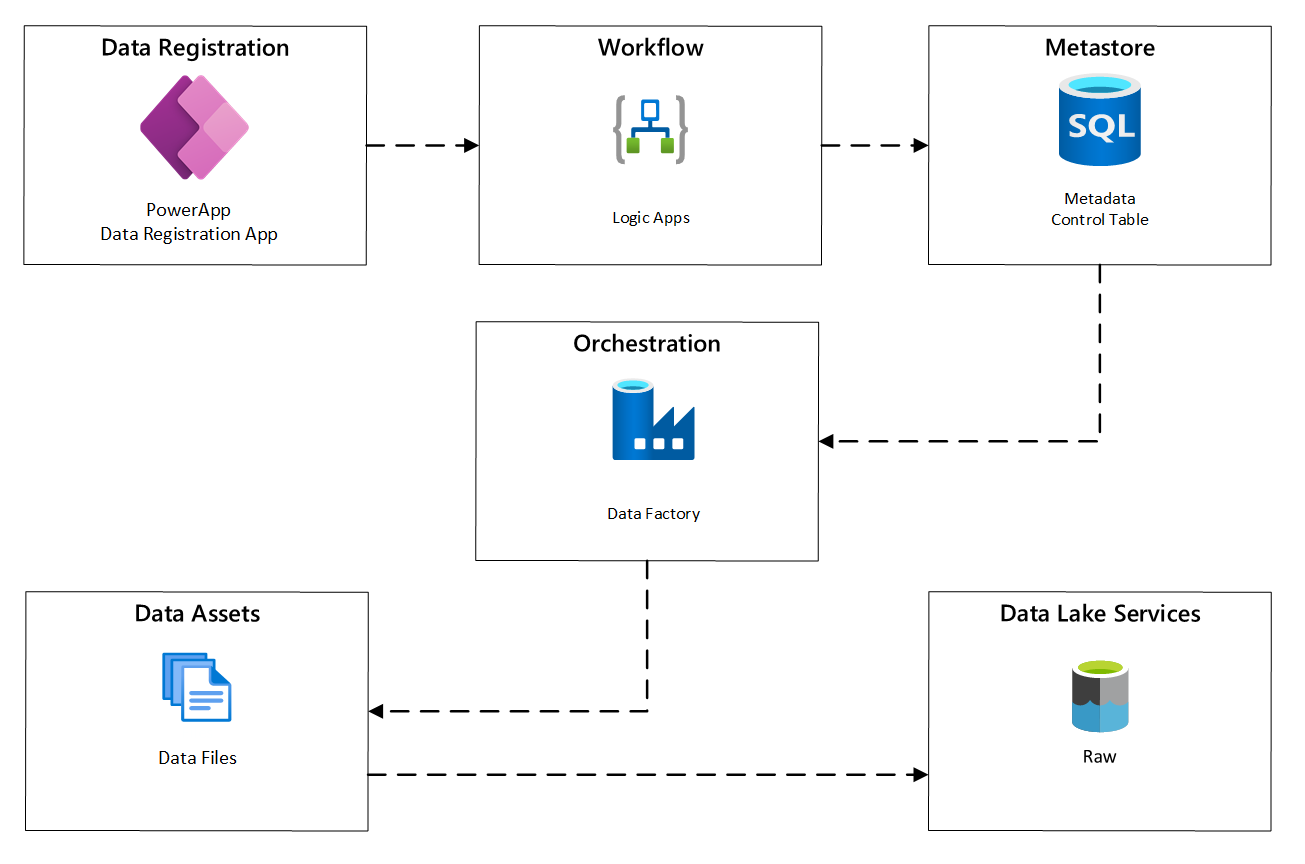
Figura 2: Processo di ingestione automatica.
Registrazione della risorsa di dati
Per fornire i metadati usati per l'inserimento automatico, è necessaria la registrazione degli asset di dati. Le informazioni acquisite contengono:
- Informazioni tecniche: Nome risorsa dati, sistema di origine, tipo, formato e frequenza.
- Informazioni sulla governance: proprietario, amministratori, visibilità (a fini di individuazione) e riservatezza.
PowerApps viene usato per acquisire i metadati che descrivono ogni asset di dati. Usa un'app basata su modello per immettere le informazioni che vengono memorizzate in una tabella Dataverse personalizzata. Quando i metadati vengono creati o aggiornati all'interno di Dataverse, attiva un flusso cloud automatizzato che richiama ulteriori passaggi di elaborazione.
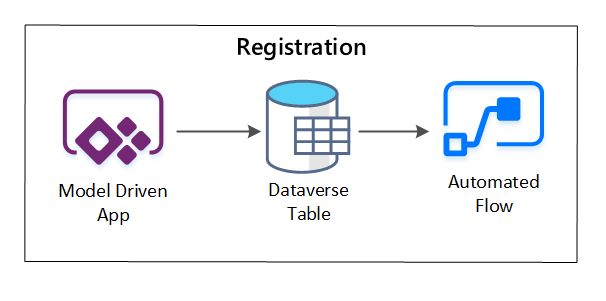
Figura 3: Registrazione degli asset di dati.
Fornitura del flusso di lavoro/acquisizione metadati
Nella fase del flusso di lavoro di provisioning i dati raccolti nella fase di registrazione vengono convalidati e salvati in modo permanente nel metastore. Vengono eseguiti sia passaggi tecnici che di convalida aziendale, tra cui:
- Validazione del feed di dati di input
- Attivazione del flusso di lavoro di approvazione
- Elaborazione logica per attivare la persistenza dei metadati nell'archivio metadati
- Revisione attività
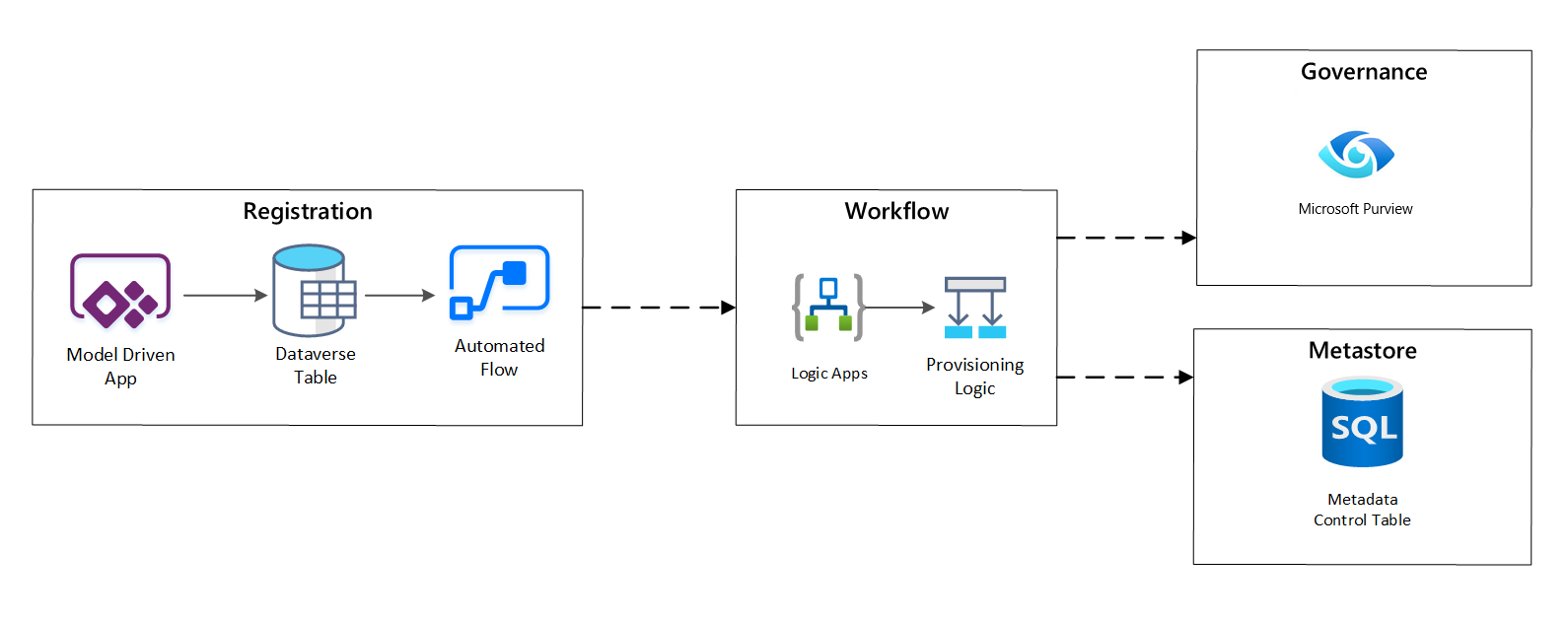
Figura 4: Flusso di lavoro di registrazione.
Dopo l'approvazione delle richieste di inserimento, il flusso di lavoro usa l'API REST Microsoft Purview per inserire le origini in Microsoft Purview.
Flusso di lavoro dettagliato per l'integrazione di prodotti dati
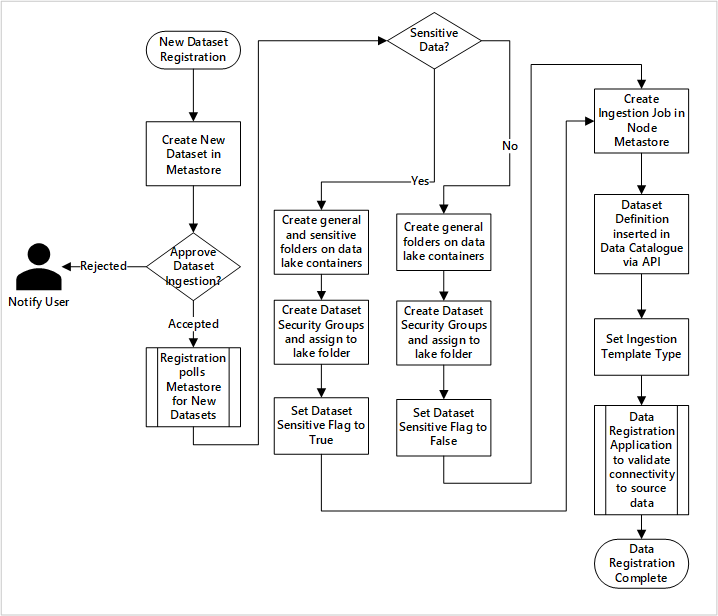
figura 5: Come vengono inseriti nuovi set di dati (automatizzati).
La figura 5 mostra il processo di registrazione dettagliato per automatizzare l'inserimento di nuove origini dati:
- I dettagli della sorgente vengono registrati, inclusi gli ambienti di produzione e della fabbrica di dati.
- Vengono acquisiti vincoli di forma, formato e qualità dei dati.
- I team responsabili delle applicazioni di dati devono indicare se i dati sono sensibili (dati personali). Questa classificazione determina il processo durante il quale vengono create le cartelle del data lake per inserire dati grezzi, arricchiti e curati. I nomi sorgente per i dati non elaborati e arricchiti e i nomi dei prodotti di dati curati.
- Vengono creati un'entità servizio ed i gruppi di sicurezza per l'inserimento e l'accesso a un set di dati.
- Un processo di inserimento viene creato nel metastore Data Factory della zona di approdo dei dati.
- Un'API inserisce la definizione dei dati in Microsoft Purview.
- In base alla convalida dell'origine dati e dell'approvazione da parte del team ops, i dettagli vengono pubblicati in un metastore di Data Factory.
Pianificazione dell'ingestione
All'interno di Azure Data Factory, attività di copia basate sui metadati forniscono funzionalità che consentono alle pipeline di orchestrazione di essere guidate dalle righe all'interno di una tabella di controllo archiviata nel database SQL di Azure. È possibile usare lo strumento Copia dati per creare pipeline basate su metadati.
Dopo la creazione di una pipeline, il flusso di lavoro di provisioning aggiunge voci alla tabella di controllo per supportare l'ingestione dalle fonti identificate mediante i metadati di registrazione degli asset di dati. Le pipeline di Azure Data Factory e il database SQL di Azure che contengono il metastore della tabella di controllo possono entrambi esistere all'interno di ogni zona di approdo dei dati per creare e inserire nuove origini dati nelle zone di approdo dei dati.
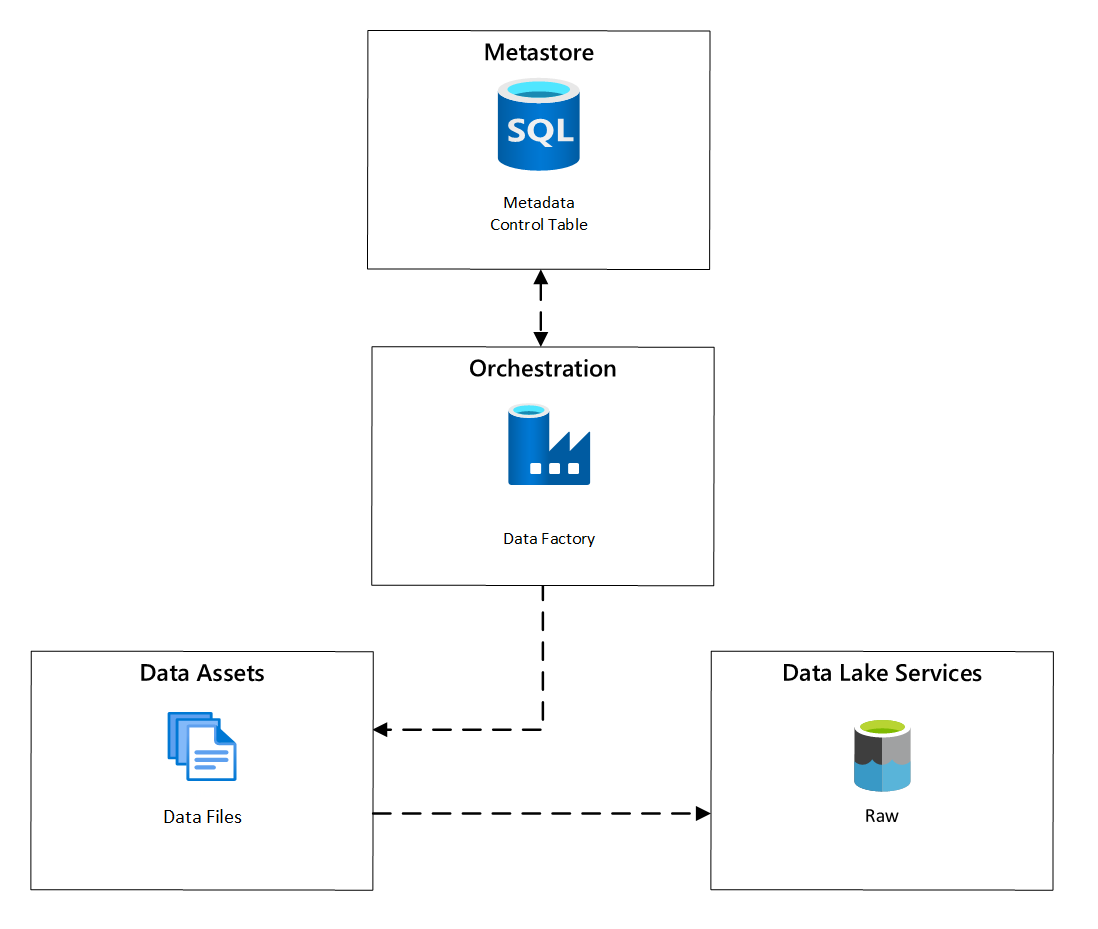
Figura 6: Pianificazione dell'inserimento delle risorse di dati.
Flusso di lavoro dettagliato per l'acquisizione di nuove origini dati
Il diagramma seguente illustra come recuperare le origini dati registrate in un metastore di un database SQL di Data Factory e come i dati vengono ingeriti inizialmente.
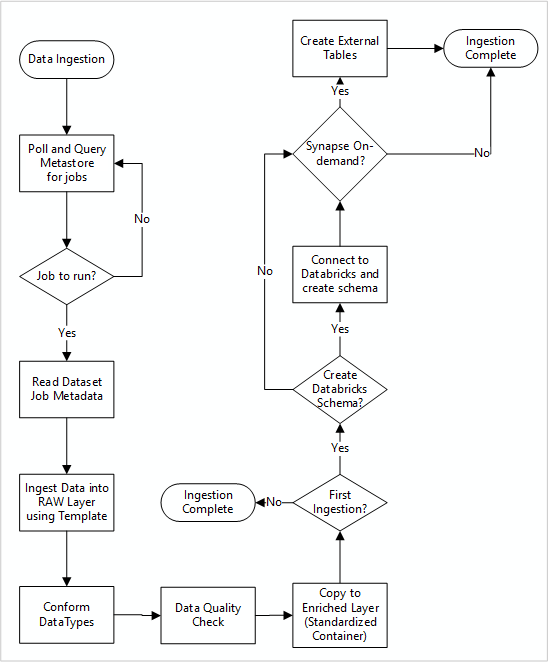
La pipeline principale di inserimento di Data Factory legge le configurazioni da un metastore SQL database di Data Factory, quindi si esegue iterativamente con i parametri corretti. I dati vengono trasferiti dall'origine al livello non elaborato in Azure Data Lake senza alcuna modifica. La forma dei dati viene convalidata in base al metastore di Data Factory. I formati di file vengono convertiti nei formati Apache Parquet o Avro, quindi trasferiti nel livello arricchito.
I dati in fase di ingestione si connettono a un'area di lavoro di data science e ingegneria di Azure Databricks, e una definizione di dati viene creata all'interno del metastore Apache Hive della zona di atterraggio dei dati.
Se è necessario usare un pool SQL serverless di Azure Synapse per esporre i dati, la soluzione personalizzata deve creare viste sui dati nel lago.
Se è necessaria la crittografia a livello di riga o a livello di colonna, la soluzione personalizzata deve trasferire i dati nel data lake, quindi inserire i dati direttamente nelle tabelle interne nei pool SQL e configurare la sicurezza appropriata nel calcolo dei pool SQL.
Metadati acquisiti
Quando si usa l'inserimento automatico dei dati, è possibile eseguire query sui metadati associati e creare dashboard per:
- Tenere traccia delle attività e dei timestamp di caricamento dei dati più recenti per i prodotti di dati correlati alle relative funzioni.
- Tenere traccia dei prodotti di dati disponibili.
- Aumentare i volumi di dati.
- Ottenere aggiornamenti in tempo reale sui fallimenti dei processi.
I metadati operativi possono essere usati per tenere traccia:
- Lavori, fasi di lavoro e relative dipendenze.
- Prestazioni lavorative e storico delle prestazioni.
- Crescita del volume di dati.
- Errori dei lavori.
- Modifiche ai metadati di origine.
- Funzioni aziendali che dipendono dai prodotti dati.
Usare l'API REST Di Microsoft Purview per individuare i dati
Le API REST di Microsoft Purview devono essere usate per registrare i dati durante l'inserimento iniziale. È possibile utilizzare le API per inviare i dati al catalogo dei dati subito dopo il loro inserimento.
Per altre informazioni, vedere come usare le API REST di Microsoft Purview.
Registrare le origini dati
Usare la chiamata API seguente per registrare nuove origini dati:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
Parametri URI dell'origine dati:
| Nome | Obbligatorio | Digitare | Descrizione |
|---|---|---|---|
accountName |
Vero | Corda | Nome dell'account Microsoft Purview |
dataSourceName |
Vero | Stringa | Nome dell'origine dati |
Usare l'API REST Di Microsoft Purview per la registrazione
Gli esempi seguenti illustrano come usare l'API REST di Microsoft Purview per registrare origini dati con i payload.
Registrare un'origine dati di Azure Data Lake Storage Gen2:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Registrare un'origine dati del database SQL:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Nota
Il <collection-name>è una raccolta attuale presente in un account di Microsoft Purview.
Creare una scansione
Scopri come puoi creare credenziali per autenticare le origini in Microsoft Purview prima di configurare ed eseguire una scansione.
Usare la chiamata API seguente per analizzare le origini dati:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
parametri URI per una scansione:
| Nome | Obbligatorio | Digitare | Descrizione |
|---|---|---|---|
accountName |
Vero | Stringa | Nome dell'account Microsoft Purview |
dataSourceName |
Vero | Stringa | Nome dell'origine dati |
newScanName |
Vero | Stringa | Nome della nuova analisi |
Usare l'API REST Di Microsoft Purview per l'analisi
Gli esempi seguenti illustrano come usare l'API REST di Microsoft Purview per analizzare le origini dati con i payload:
Analizzare un'origine dati di Azure Data Lake Storage Gen2:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Scansionare un'origine dati di un database SQL:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Usare la chiamata API seguente per analizzare le origini dati:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run