Creare pipeline di copia dei dati su larga scala con un approccio basato sui metadati nello strumento copia dati
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Quando si desidera copiare grandi quantità di oggetti (ad esempio migliaia di tabelle) o caricare dati da un'ampia gamma di origini, l'approccio appropriato consiste nell'immettere l'elenco dei nomi degli oggetti con comportamenti di copia necessari in una tabella di controllo e quindi usare pipeline con parametri per leggere la stessa dalla tabella di controllo e applicarle di conseguenza ai processi. In questo modo, è possibile mantenere (ad esempio, aggiungere/rimuovere) l'elenco di oggetti da copiare facilmente aggiornando i nomi degli oggetti nella tabella di controllo anziché ridistribuendo le pipeline. Inoltre, sarà disponibile un'unica posizione per verificare facilmente quali oggetti copiati da pipeline/trigger con comportamenti di copia definiti.
Lo strumento Copia dati in Azure Data Factory semplifica il percorso di compilazione di pipeline di copia dei dati basate su metadati. Dopo aver eseguito un flusso intuitivo da un'esperienza basata su procedura guidata, lo strumento può generare pipeline con parametri e script SQL per creare di conseguenza tabelle di controllo esterne. Dopo aver eseguito gli script generati per creare la tabella di controllo nel database SQL, le pipeline leggeranno i metadati dalla tabella di controllo e li applicheranno automaticamente ai processi di copia.
Creare processi di copia basati sui metadati dallo strumento copia dati
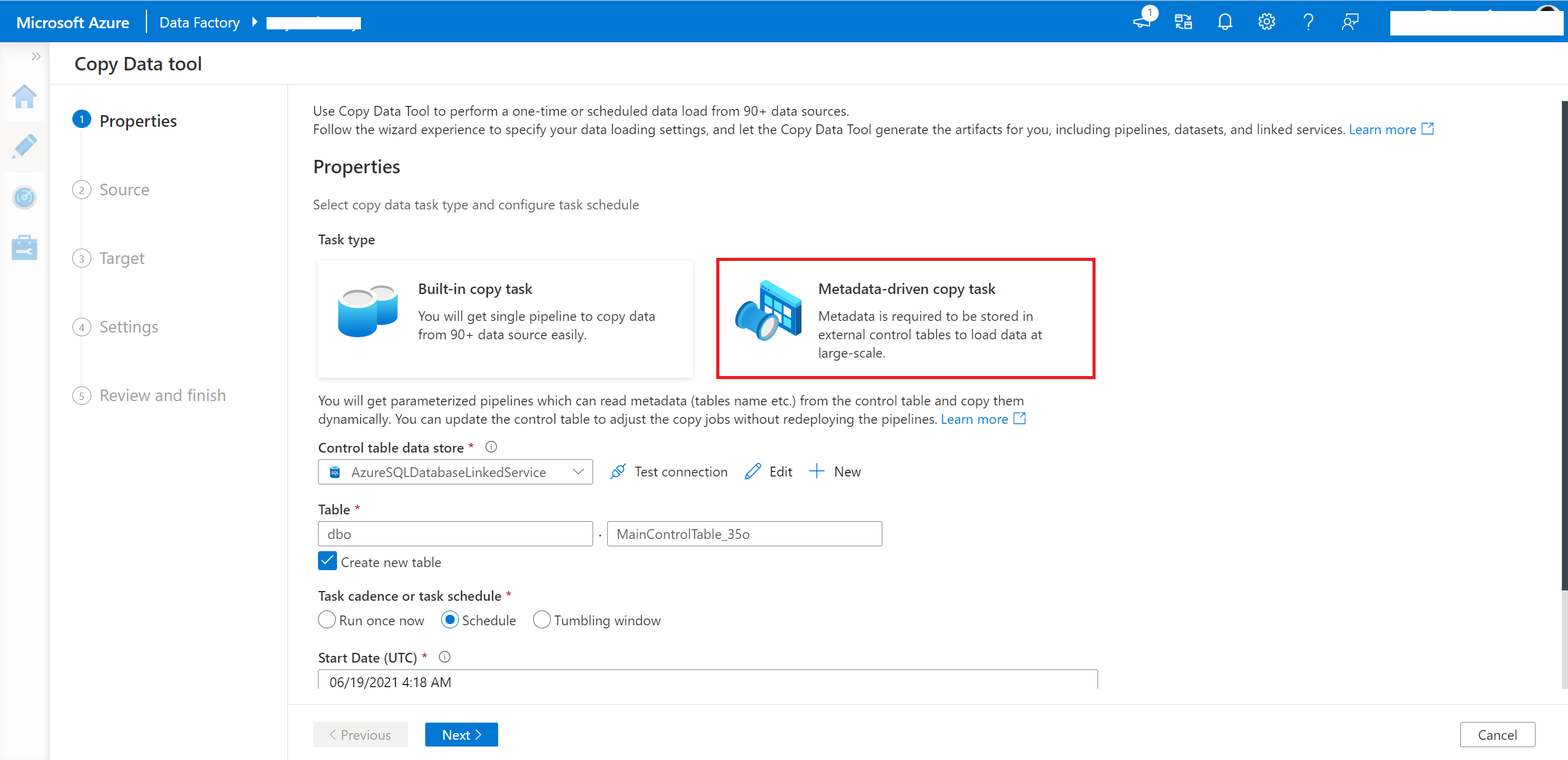
Selezionare l'attività di copia guidata dai metadati nello strumento copia dati.
È necessario immettere la connessione e il nome della tabella di controllo, in modo che la pipeline generata legga i metadati da tale tabella.
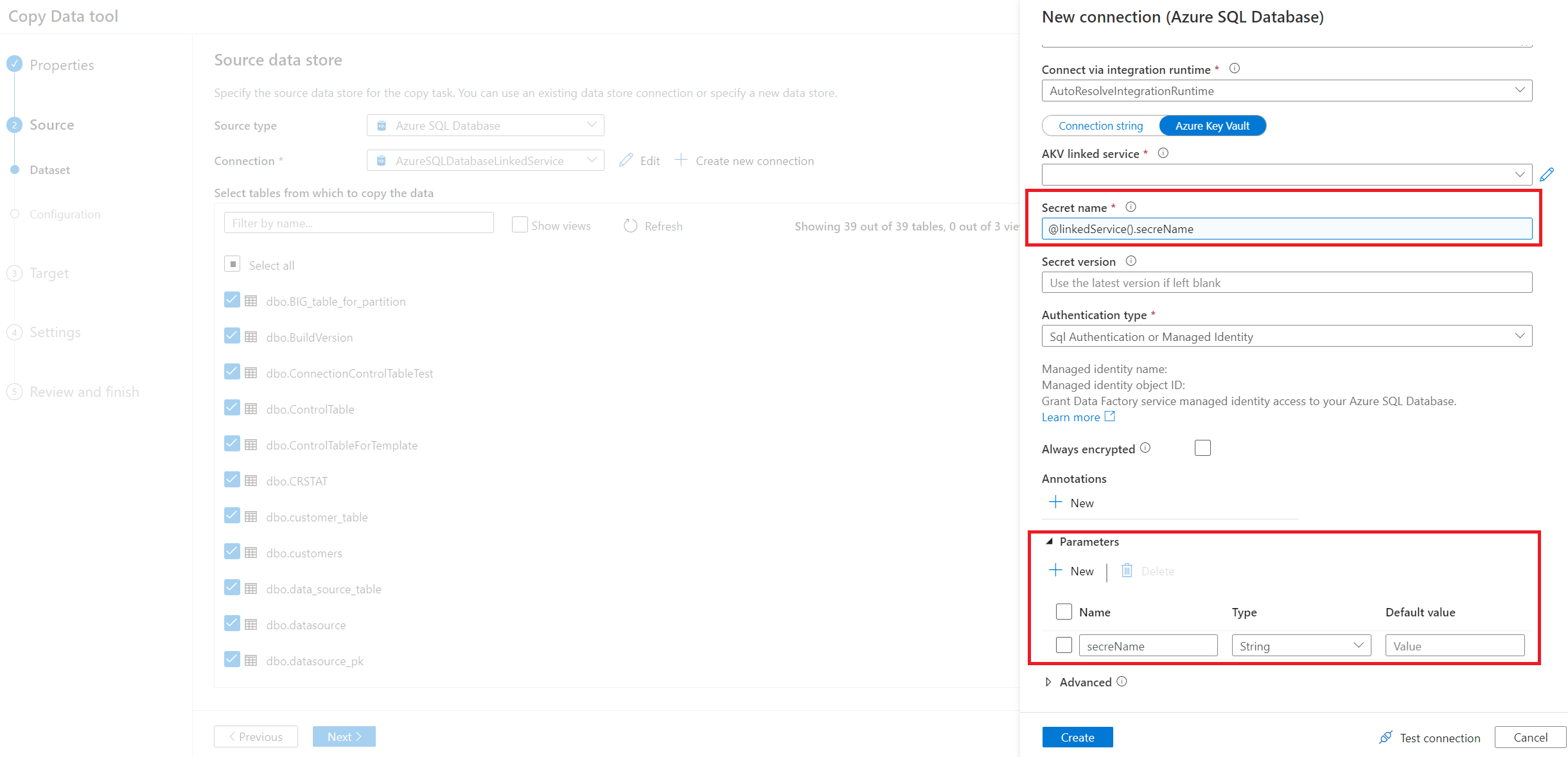
Immettere la connessione del database di origine. È anche possibile usare un servizio collegato con parametri.
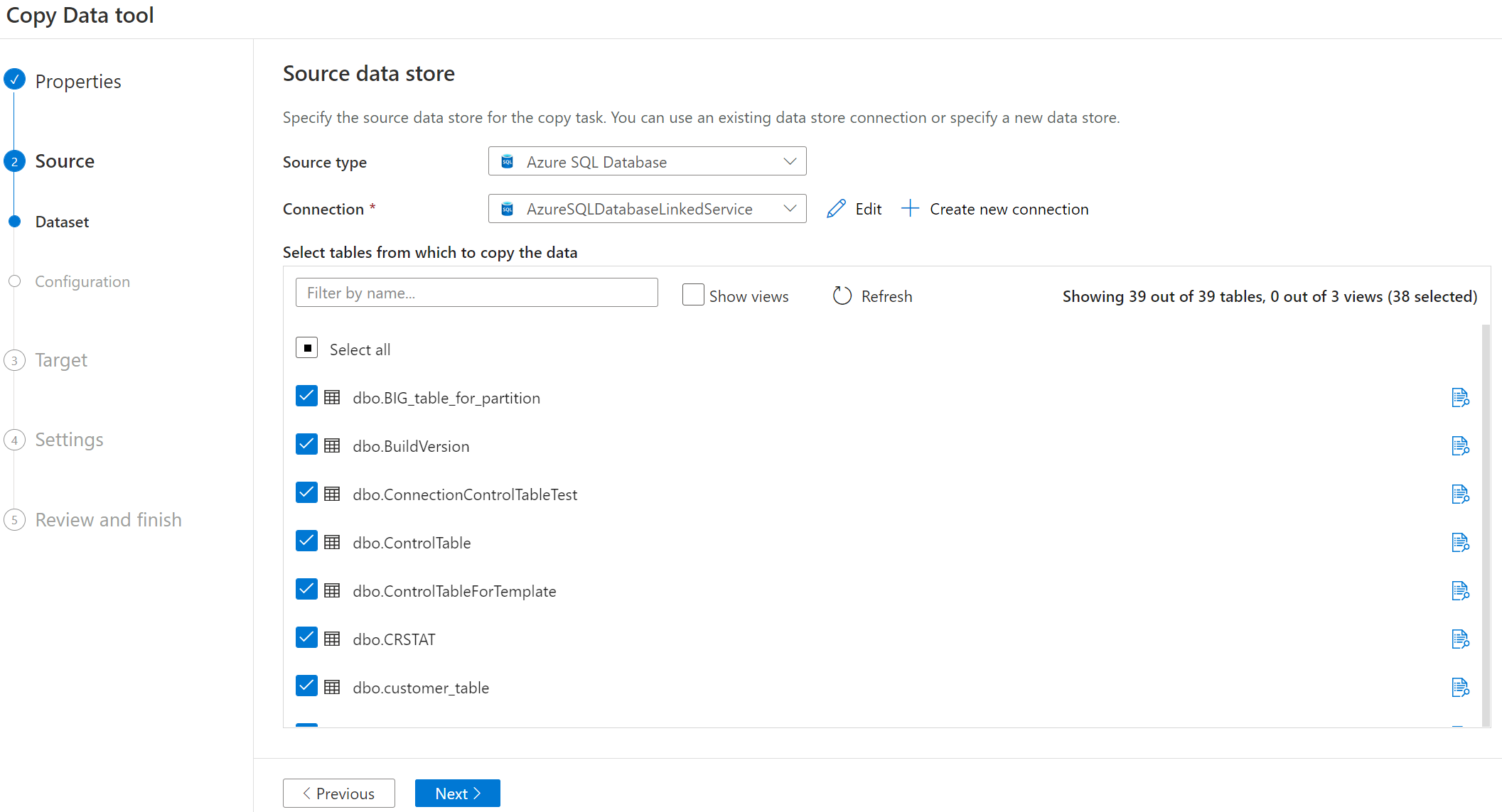
Selezionare il nome della tabella da copiare.
Nota
Se si seleziona l'archivio dati tabulare, sarà possibile selezionare ulteriormente il caricamento completo o il caricamento differenziale nella pagina successiva. Se si seleziona l'archivio di archiviazione, è possibile selezionare il caricamento completo solo nella pagina successiva. Il caricamento incrementale di nuovi file solo dall'archivio di archiviazione non è attualmente supportato.
Scegliere il comportamento di caricamento.
Suggerimento
Per eseguire la copia completa in tutte le tabelle, selezionare Caricamento completo di tutte le tabelle. Se si vuole eseguire la copia incrementale, è possibile selezionare configura per ogni tabella singolarmente e selezionare Carico differenziale, nonché nome colonna filigrana e valore da avviare per ogni tabella.
Selezionare Archivio dati di destinazione.
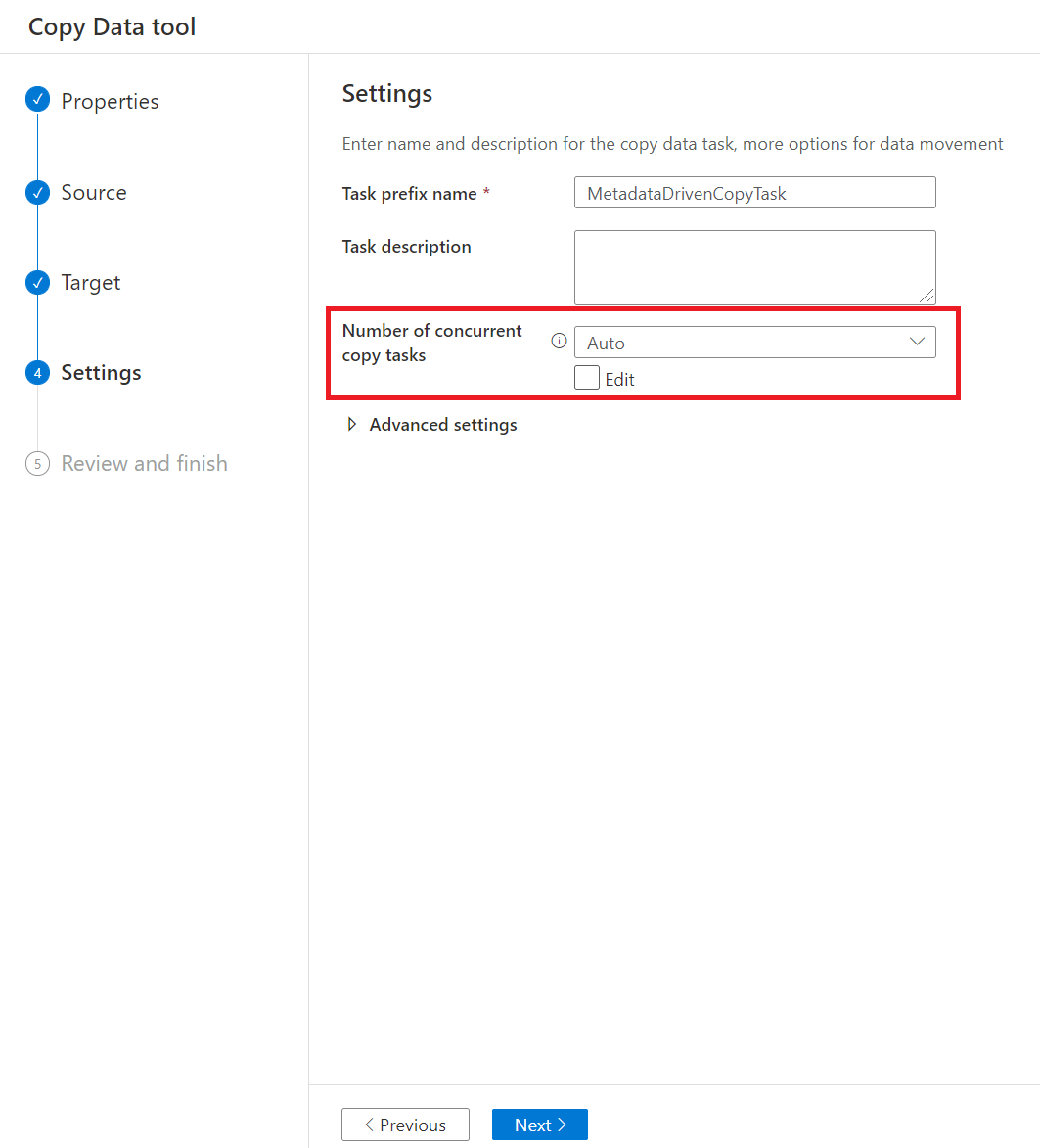
Nella pagina Impostazioni è possibile decidere il numero massimo di attività di copia da copiare i dati dall'archivio di origine contemporaneamente tramite Numero di attività di copia simultanee. Il valore predefinito è 20.
Dopo la distribuzione della pipeline, è possibile copiare o scaricare gli script SQL dall'interfaccia utente per creare una tabella di controllo e una procedura di archiviazione.
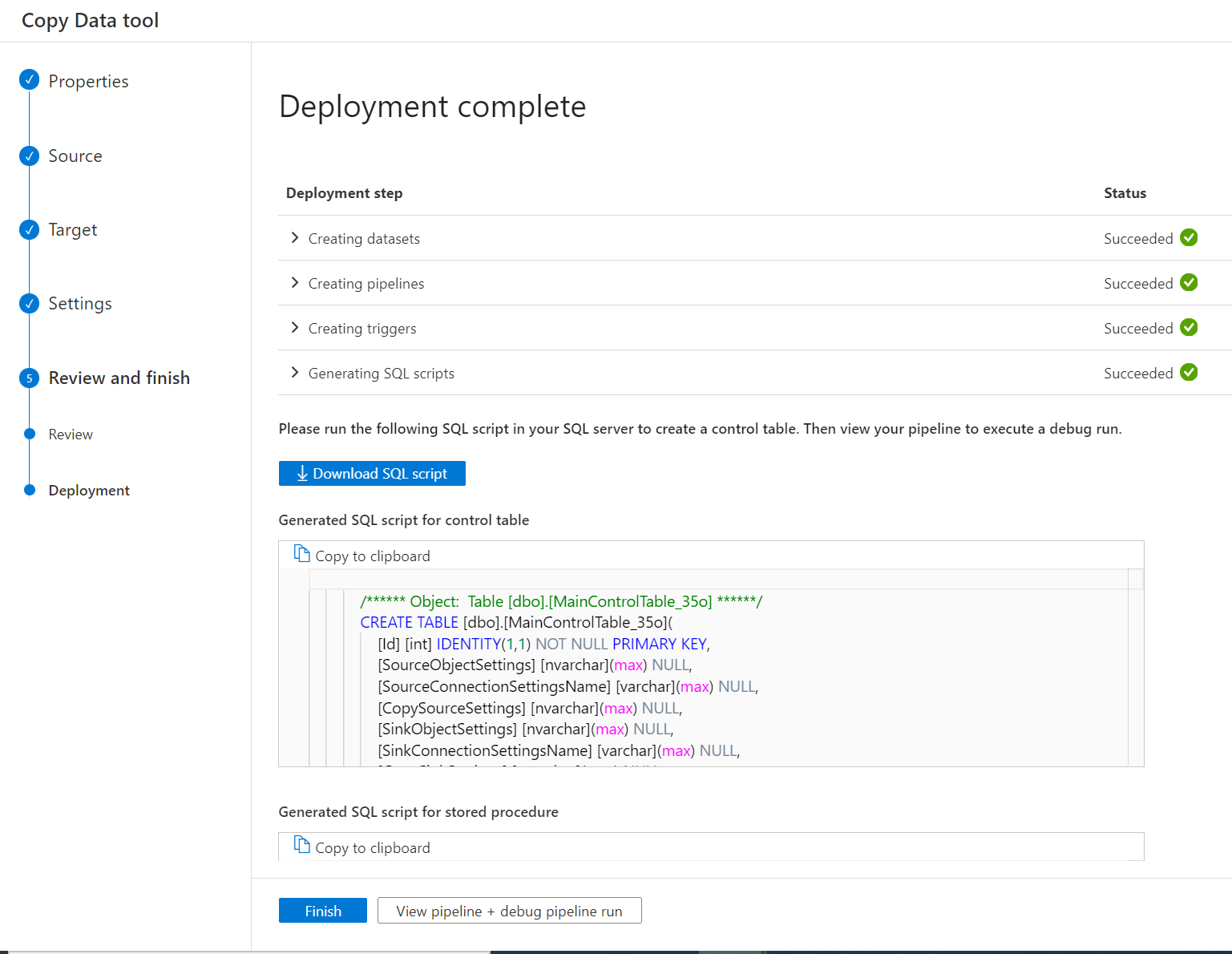
Verranno visualizzati due script SQL.
- Il primo script SQL viene usato per creare due tabelle di controllo. La tabella di controllo principale archivia l'elenco delle tabelle, il percorso del file o i comportamenti di copia. La tabella di controllo connessione archivia il valore di connessione dell'archivio dati se è stato usato un servizio collegato con parametri.
- Il secondo script SQL viene usato per creare una stored procedure. Viene usato per aggiornare il valore limite nella tabella di controllo principale quando i processi di copia incrementale vengono completati ogni volta.
Aprire SSMS per connettersi al server tabelle di controllo ed eseguire i due script SQL per creare tabelle di controllo e stored procedure.
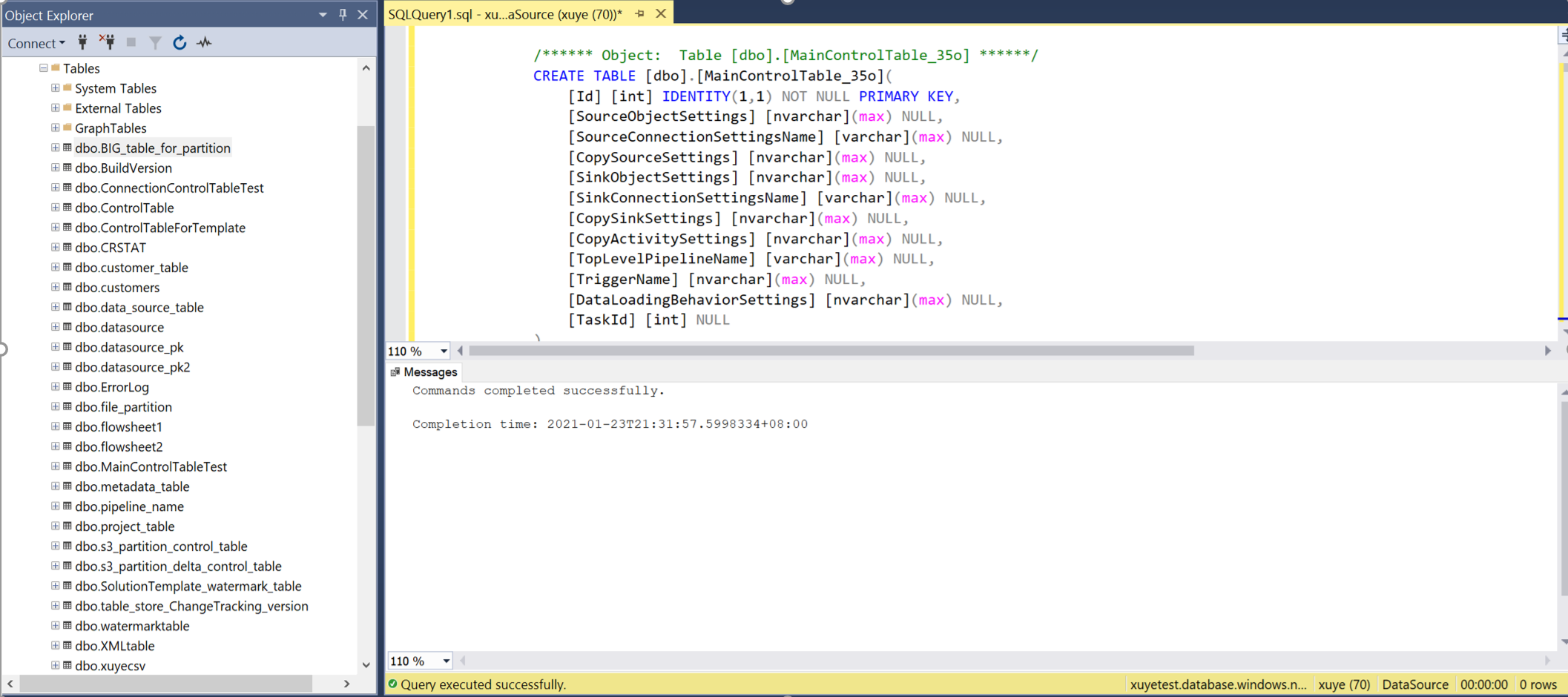
Eseguire una query sulla tabella di controllo principale e sulla tabella di controllo della connessione per esaminare i metadati in esso contenuti.
Tabella di controllo principale
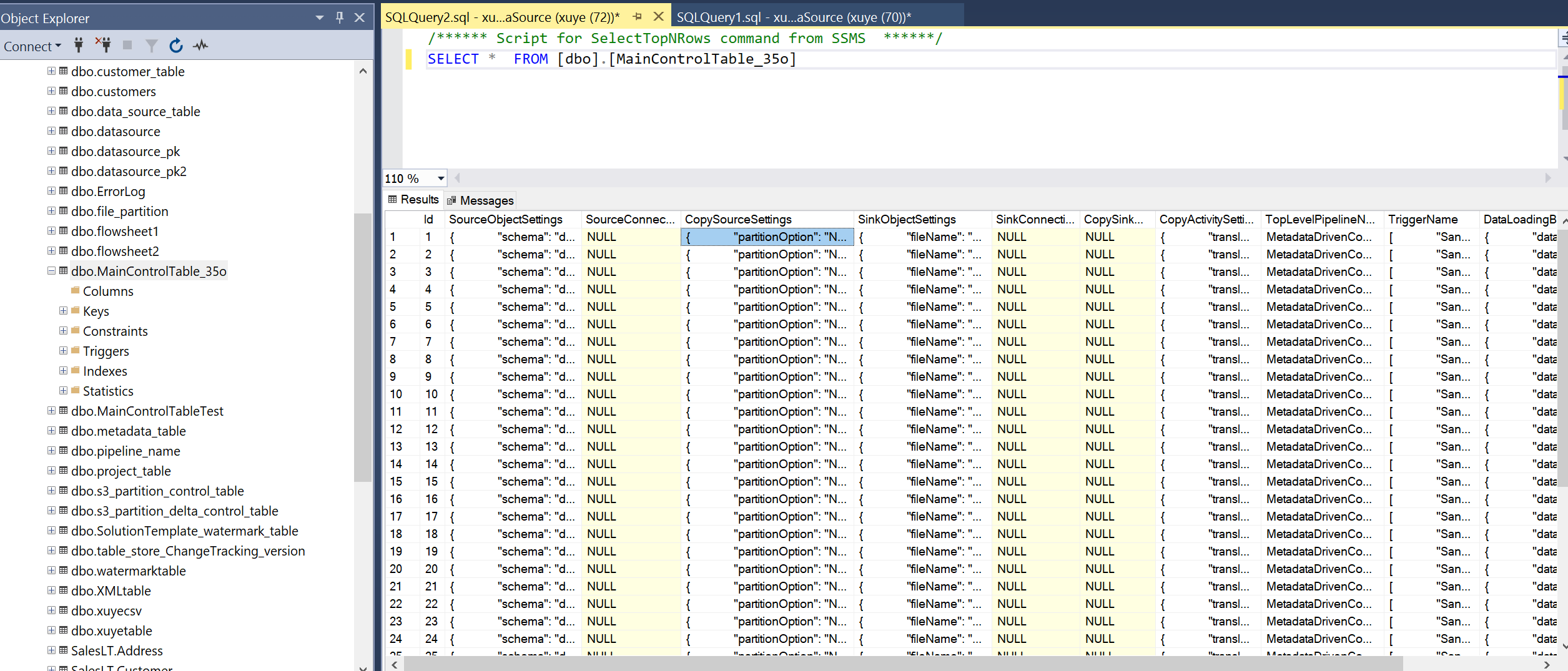
Tabella di controllo connessione

Tornare al portale di Azure Data Factory per visualizzare ed eseguire il debug delle pipeline. Verrà visualizzata una cartella creata assegnando un nome a "MetadataDrivenCopyTask_#########". Fare clic sulla denominazione della pipeline con "MetadataDrivenCopyTask###_TopLevel" e fare clic su Esegui debug.
È necessario immettere i parametri seguenti:
Nome dei parametri Descrizione MaxNumberOfConcurrentTasks È sempre possibile modificare il numero massimo di attività di copia simultanee eseguite prima dell'esecuzione della pipeline. Il valore predefinito sarà quello immesso nello strumento copia dati. MainControlTableName È sempre possibile modificare il nome della tabella di controllo principale, in modo che la pipeline ottenga i metadati da tale tabella prima dell'esecuzione. ConnectionControlTableName È sempre possibile modificare il nome della tabella del controllo connessione (facoltativo), in modo che la pipeline ottenga i metadati correlati alla connessione all'archivio dati prima dell'esecuzione. MaxNumberOfObjectsReturnedFromLookupActivity Per evitare di raggiungere il limite dell'attività di ricerca di output, è possibile definire il numero massimo di oggetti restituiti dall'attività di ricerca. Nella maggior parte dei casi, non è necessario modificare il valore predefinito. windowStart Quando si inserisce un valore dinamico (ad esempio, aaaa/mm/gg) come percorso della cartella, il parametro viene usato per passare il tempo di trigger corrente alla pipeline per riempire il percorso della cartella dinamica. Quando la pipeline viene attivata dal trigger di pianificazione o dal trigger di windows a cascata, gli utenti non devono immettere il valore di questo parametro. Valore di esempio: 2021-01-25T01:49:28Z Abilitare il trigger per rendere operative le pipeline.
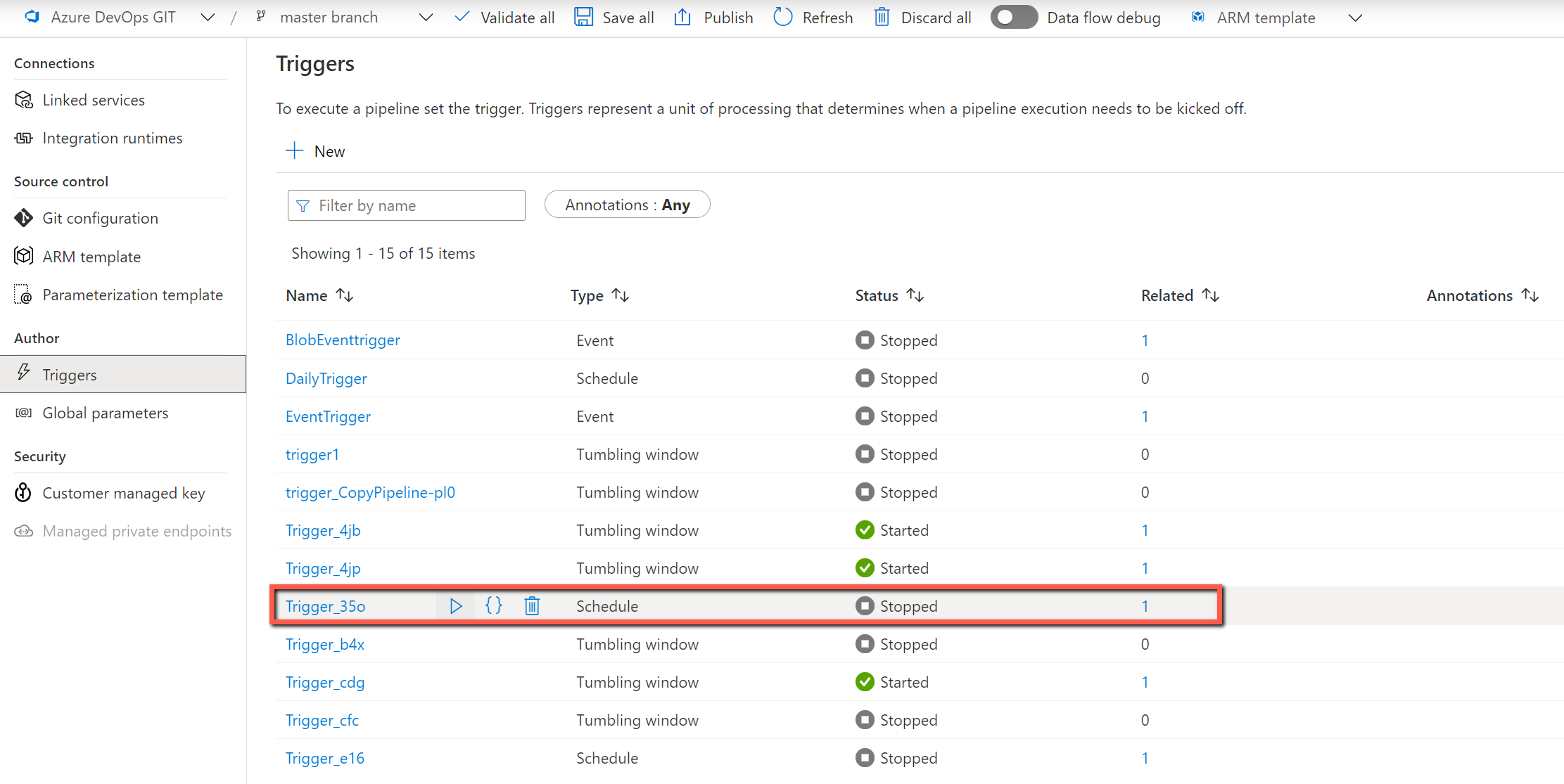
Aggiornare la tabella di controllo tramite lo strumento copia dati
È sempre possibile aggiornare direttamente la tabella di controllo aggiungendo o rimuovendo l'oggetto da copiare o modificando il comportamento di copia per ogni tabella. Creiamo anche l'esperienza dell'interfaccia utente nello strumento copia dati per semplificare il percorso di modifica della tabella di controllo.
Fare clic con il pulsante destro del mouse sulla pipeline di primo livello: MetadataDrivenCopyTask_xxx_TopLevel e quindi scegliere Modifica tabella di controllo.
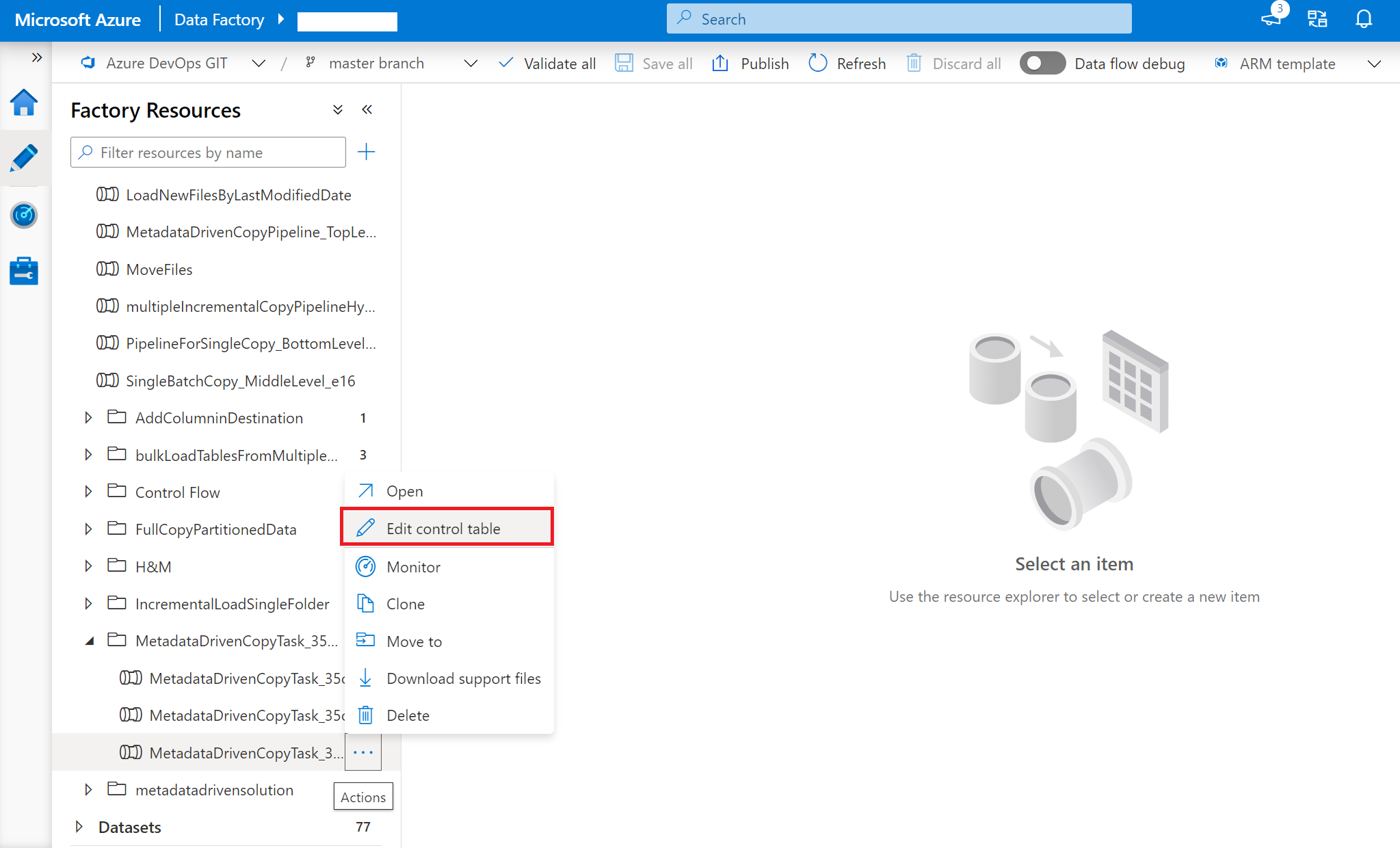
Selezionare le righe dalla tabella di controllo da modificare.
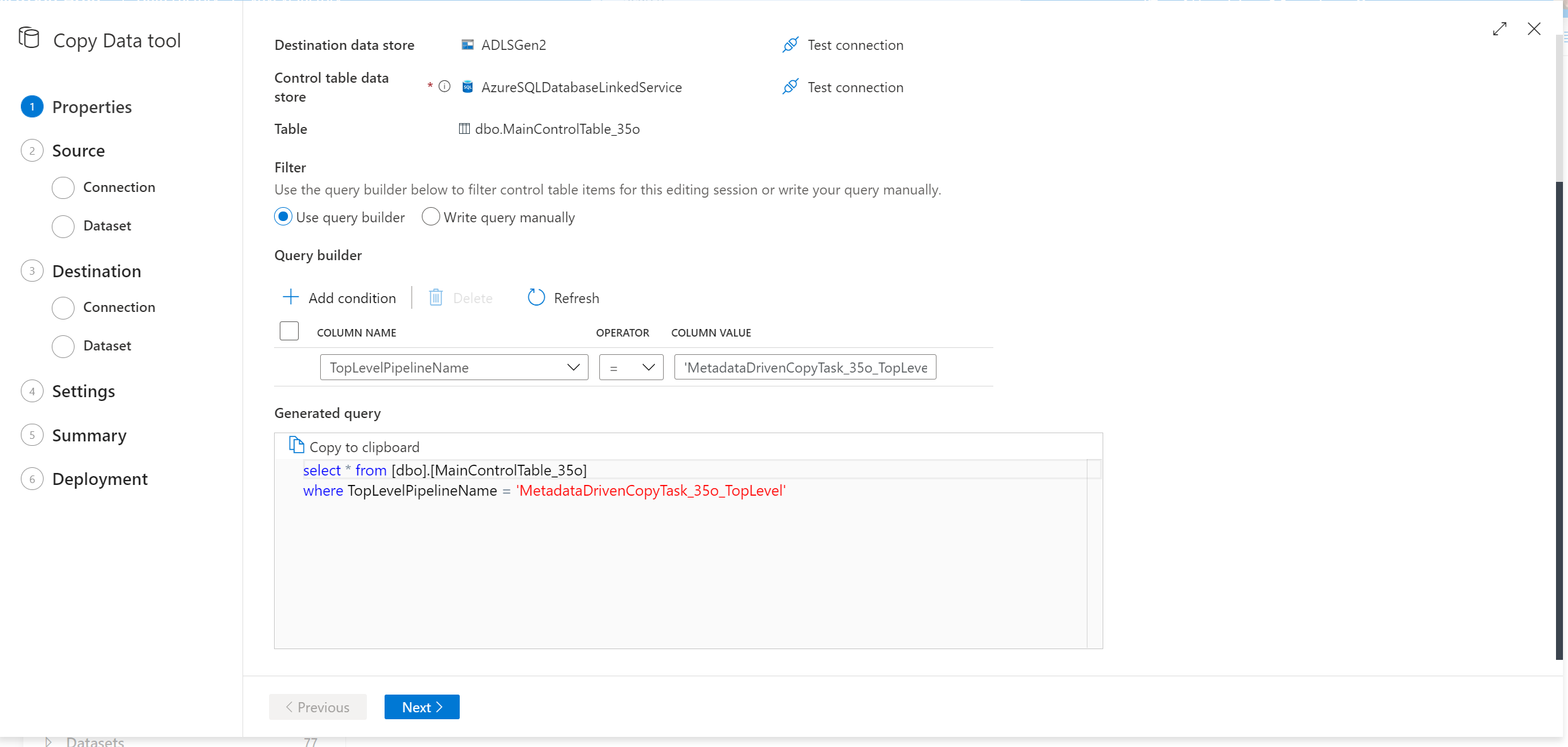
Passare alla velocità effettiva dello strumento di copia dei dati e verrà creato un nuovo script SQL. Eseguire di nuovo lo script SQL per aggiornare la tabella di controllo.
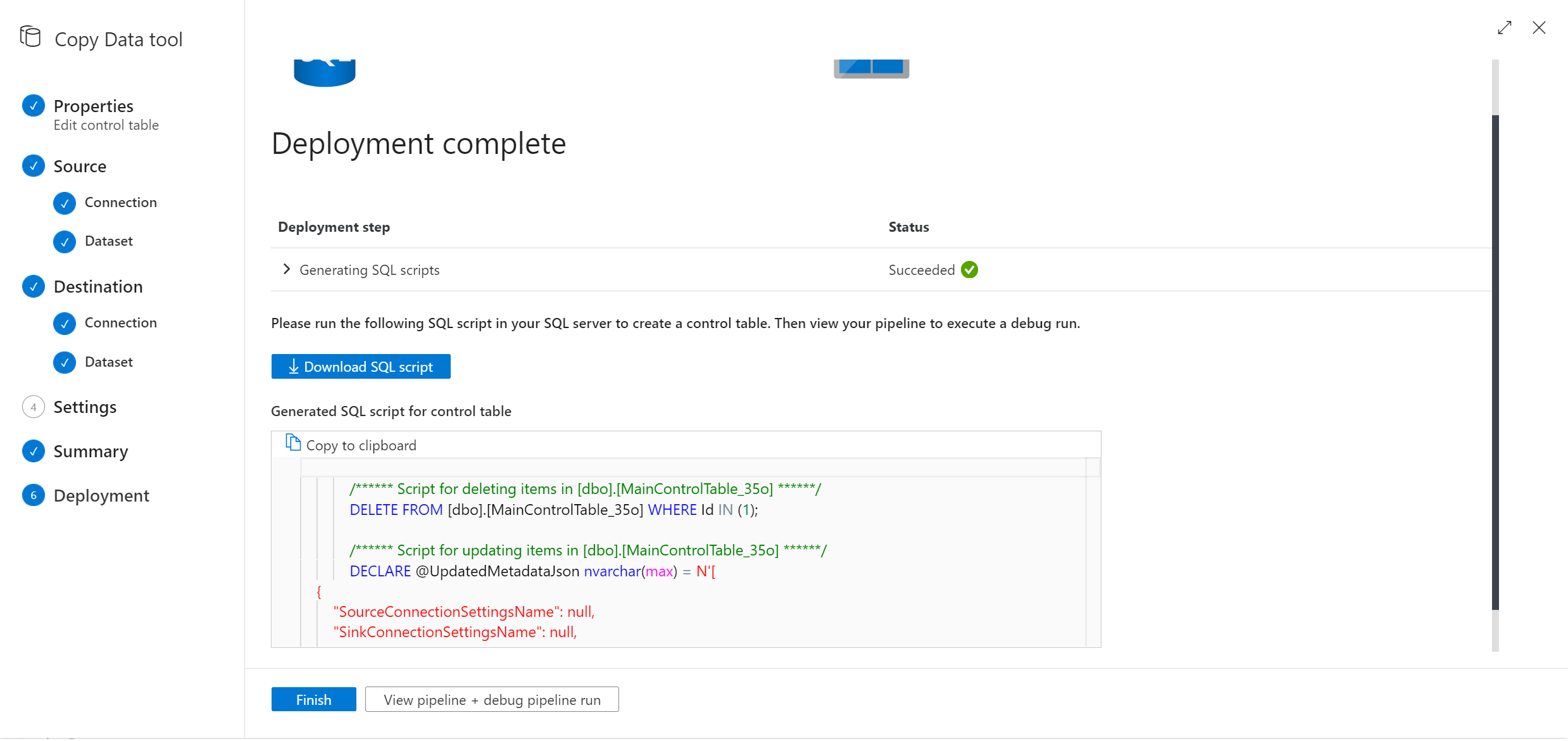
Nota
La pipeline non verrà ridistribuita. Il nuovo script SQL creato consente di aggiornare solo la tabella di controllo.
Tabelle di controllo
Tabella di controllo principale
Ogni riga della tabella di controllo contiene i metadati per un oggetto (ad esempio, una tabella) da copiare.
| Nome colonna | Descrizione |
|---|---|
| ID | ID univoco dell'oggetto da copiare. |
| SourceObjectSettings | Metadati del set di dati di origine. Può essere il nome dello schema, il nome della tabella e così via. Ecco un esempio. |
| SourceConnectionSettingsName | Nome dell'impostazione di connessione di origine nella tabella di controllo della connessione. Questo passaggio è facoltativo. |
| CopySourceSettings | Metadati della proprietà di origine nell'attività di copia. Può essere una query, partizioni e così via. Ecco un esempio. |
| SinkObjectSettings | Metadati del set di dati di destinazione. Può essere il nome file, il percorso della cartella, il nome della tabella e così via. Ecco un esempio. Se si specifica il percorso della cartella dinamica, il valore della variabile non verrà scritto qui nella tabella dei controlli. |
| SinkConnectionSettingsName | Nome dell'impostazione di connessione di destinazione nella tabella di controllo connessione. Questo passaggio è facoltativo. |
| CopySinkSettings | Metadati della proprietà sink nell'attività di copia. Può essere preCopyScript, tableOption e così via. Ecco un esempio. |
| CopyActivitySettings | Metadati della proprietà translator nell'attività di copia. Viene usato per definire il mapping delle colonne. |
| TopLevelPipelineName | Nome della pipeline principale, che può copiare questo oggetto. |
| TriggerName | Nome del trigger, che può attivare la pipeline per copiare questo oggetto. Se viene eseguito il debug, il nome è Sandbox. Se l'esecuzione manuale, il nome è Manuale. Se l'esecuzione pianificata è il nome del trigger associato. Può essere un input di più nomi. |
| DataLoadingBehaviorSettings | Caricamento completo e caricamento differenziale. |
| TaskId | Ordine degli oggetti da copiare dopo TaskId nella tabella di controllo (ORDER BY [TaskId] DESC). Se sono presenti enormi quantità di oggetti da copiare, ma solo un numero limitato di copie simultanee consentite, è possibile modificare l'Id attività per ogni oggetto per decidere quali oggetti possono essere copiati in precedenza. Il valore predefinito è 0. |
| CopyEnabled | Specificare se l'elemento è abilitato nel processo di inserimento dati. Valori consentiti: 1 (abilitato), 0 (disabilitato). Il valore predefinito è 1. |
Tabella di controllo connessione
Ogni riga nella tabella di controllo contiene un'impostazione di connessione per l'archivio dati.
| Nome colonna | Descrizione |
|---|---|
| Name | Nome della connessione con parametri nella tabella di controllo principale. |
| ConnectionSettings | Impostazioni di connessione. Può essere nome del database, nome del server e così via. |
Pipeline
Verranno visualizzati tre livelli di pipeline generati dallo strumento di copia dei dati.
MetadataDrivenCopyTask_xxx_TopLevel
Questa pipeline calcolerà il numero totale di oggetti (tabelle e così via) da copiare in questa esecuzione, verrà visualizzato il numero di batch sequenziali in base al numero massimo consentito di attività di copia simultanea consentita e quindi eseguirà un'altra pipeline per copiare batch diversi in sequenza.
Parametri
| Nome dei parametri | Descrizione |
|---|---|
| MaxNumberOfConcurrentTasks | È sempre possibile modificare il numero massimo di attività di copia simultanee eseguite prima dell'esecuzione della pipeline. Il valore predefinito sarà quello immesso nello strumento copia dati. |
| MainControlTableName | Nome della tabella di controllo principale. La pipeline otterrà i metadati da questa tabella prima dell'esecuzione |
| ConnectionControlTableName | Nome della tabella della tabella di controllo connessione (facoltativo). La pipeline otterrà i metadati correlati alla connessione all'archivio dati prima dell'esecuzione |
| MaxNumberOfObjectsReturnedFromLookupActivity | Per evitare di raggiungere il limite dell'attività di ricerca di output, è possibile definire il numero massimo di oggetti restituiti dall'attività di ricerca. Nella maggior parte dei casi, non è necessario modificare il valore predefinito. |
| windowStart | Quando si inserisce un valore dinamico (ad esempio, aaaa/mm/gg) come percorso della cartella, il parametro viene usato per passare il tempo di trigger corrente alla pipeline per riempire il percorso della cartella dinamica. Quando la pipeline viene attivata dal trigger di pianificazione o dal trigger di windows a cascata, gli utenti non devono immettere il valore di questo parametro. Valore di esempio: 2021-01-25T01:49:28Z |
Impegni
| Nome dell'attività | Tipo di impegno | Descrizione |
|---|---|---|
| GetSumOfObjectsToCopy | Ricerca | Calcolare il numero totale di oggetti (tabelle e così via) da copiare in questa esecuzione. |
| CopyBatchesOfObjectsSequentially | ForEach | Ottenere il numero di batch sequenziali in base al numero massimo consentito di attività di copia simultanee e quindi eseguire un'altra pipeline per copiare batch diversi in sequenza. |
| CopyObjectsInOneBtach | Esegui pipeline | Eseguire un'altra pipeline per copiare un batch di oggetti. Gli oggetti appartenenti a questo batch verranno copiati in parallelo. |
MetadataDrivenCopyTask_xxx_ MiddleLevel
Questa pipeline copierà un batch di oggetti. Gli oggetti appartenenti a questo batch verranno copiati in parallelo.
Parametri
| Nome dei parametri | Descrizione |
|---|---|
| MaxNumberOfObjectsReturnedFromLookupActivity | Per evitare di raggiungere il limite dell'attività di ricerca di output, è possibile definire il numero massimo di oggetti restituiti dall'attività di ricerca. Nella maggior parte dei casi, non è necessario modificare il valore predefinito. |
| TopLevelPipelineName | Nome della pipeline di livello superiore. |
| TriggerName | Nome del trigger. |
| CurrentSequentialNumberOfBatch | ID del batch sequenziale. |
| SumOfObjectsToCopy | Numero totale di oggetti da copiare. |
| SumOfObjectsToCopyForCurrentBatch | Numero di oggetti da copiare nel batch corrente. |
| MainControlTableName | Nome della tabella di controllo principale. |
| ConnectionControlTableName | Nome della tabella di controllo connessione. |
Impegni
| Nome dell'attività | Tipo di impegno | Descrizione |
|---|---|---|
| DivideOneBatchIntoMultipleGroups | ForEach | Dividere gli oggetti da un singolo batch in più gruppi paralleli per evitare di raggiungere il limite di output dell'attività di ricerca. |
| GetObjectsPerGroupToCopy | Ricerca | Ottenere oggetti (tabelle e così via) dalla tabella di controllo da copiare in questo gruppo. Ordine degli oggetti da copiare dopo TaskId nella tabella di controllo (ORDER BY [TaskId] DESC). |
| CopyObjectsInOneGroup | Esegui pipeline | Eseguire un'altra pipeline per copiare oggetti da un gruppo. Gli oggetti appartenenti a questo gruppo verranno copiati in parallelo. |
MetadataDrivenCopyTask_xxx_ BottomLevel
Questa pipeline copia gli oggetti da un gruppo. Gli oggetti appartenenti a questo gruppo verranno copiati in parallelo.
Parametri
| Nome dei parametri | Descrizione |
|---|---|
| ObjectsPerGroupToCopy | Numero di oggetti da copiare nel gruppo corrente. |
| ConnectionControlTableName | Nome della tabella di controllo connessione. |
| windowStart | Usato per passare il tempo di trigger corrente alla pipeline per riempire il percorso della cartella dinamica, se configurato dall'utente. |
Impegni
| Nome dell'attività | Tipo di impegno | Descrizione |
|---|---|---|
| ListObjectsFromOneGroup | ForEach | Elencare gli oggetti da un gruppo ed eseguire l'iterazione di ognuna di esse alle attività downstream. |
| RouteJobsBasedOnLoadingBehavior | Switch | Controllare il comportamento di caricamento per ogni oggetto. Se è un caso predefinito o FullLoad, eseguire il caricamento completo. Se si tratta di un caso DeltaLoad, eseguire il caricamento incrementale tramite la colonna filigrana per identificare le modifiche |
| FullLoadOneObject | Copia | Creare uno snapshot completo su questo oggetto e copiarlo nella destinazione. |
| DeltaLoadOneObject | Copia | Copiare i dati modificati solo dall'ultima volta confrontando il valore nella colonna filigrana per identificare le modifiche. |
| GetMaxWatermarkValue | Ricerca | Eseguire una query sull'oggetto di origine per ottenere il valore massimo dalla colonna filigrana. |
| UpdateWatermarkColumnValue | StoreProcedure | Eseguire il writeback del nuovo valore limite per controllare la tabella da usare la prossima volta. |
Limitazioni note
- Il nome del runtime di integrazione, il tipo di database, il tipo di formato file non possono essere parametrizzati in Azure Data Factory. Ad esempio, se si desidera inserire dati sia da Oracle Server che da SQL Server, saranno necessarie due pipeline con parametri diverse. Tuttavia, la singola tabella di controllo può essere condivisa da due set di pipeline.
- OPENJSON viene usato negli script SQL generati dallo strumento copia dati. Se si usa SQL Server per ospitare la tabella di controllo, deve essere SQL Server 2016 (13.x) e versioni successive per supportare la funzione OPENJSON.
Contenuto correlato
Provare a eseguire queste esercitazioni in cui viene usato lo strumento Copia dati: