Copiare dati da e verso Archiviazione tabelle di Azure usando Azure Data Factory o Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività di copia nelle pipeline di Azure Data Factory e Synapse Analytics per copiare dati da e verso Archiviazione tabelle di Azure. Si basa sull'articolo di panoramica dell'attività di copia che presenta informazioni generali sull'attività di copia.
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Funzionalità supportate
Questo connettore archiviazione tabelle di Azure è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR | Endpoint privato gestito |
|---|---|---|
| Attività di copia (origine/sink) | 7.3 | ✓ Escludere l'account di archiviazione V1 |
| Attività Lookup | 7.3 | ✓ Escludere l'account di archiviazione V1 |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
È possibile copiare dati da qualsiasi archivio di dati di origine supportato in Archiviazione tabelle. È anche possibile copiare dati da Archiviazione tabelle in qualsiasi archivio dati di sink supportato. Per un elenco degli archivi dati supportati come origini o sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
In particolare, il connettore Tabella di Azure supporta la copia dei dati usando sia l'autenticazione basata sulla chiave dell'account sia l'autenticazione basata sulla firma di accesso condiviso del servizio.
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato archiviazione tabelle di Azure usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato archiviazione tabelle di Azure nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Tabella di Azure e selezionare il connettore di archiviazione tabelle di Azure.
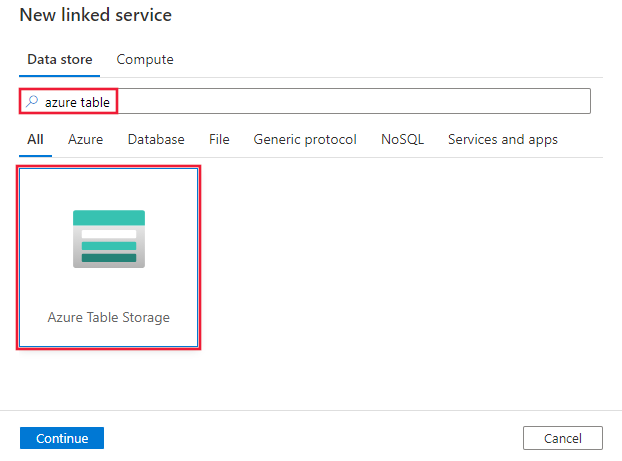
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
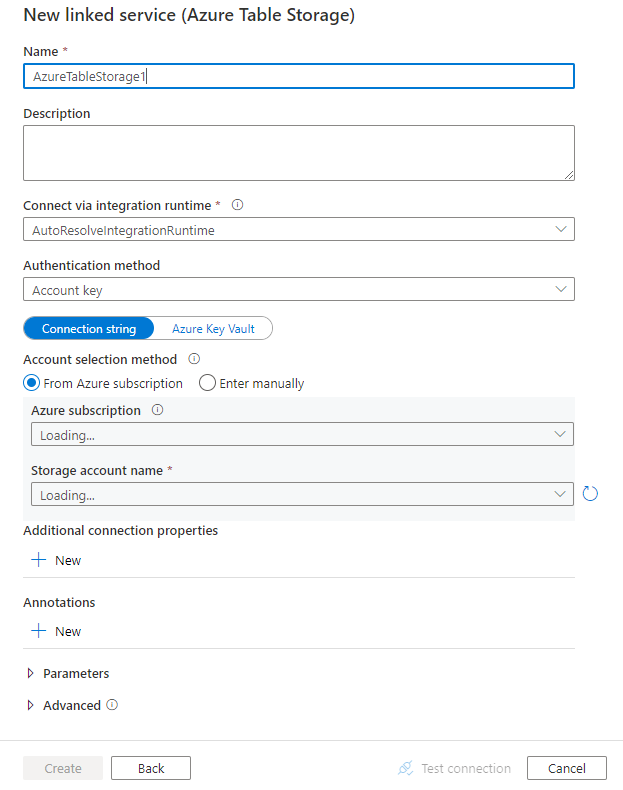
Dettagli di configurazione del connettore
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà usate per definire entità specifiche dell'archiviazione tabelle di Azure.
Proprietà del servizio collegato
Questo connettore di archiviazione tabelle supporta i tipi di autenticazione seguenti. Per informazioni dettagliate, vedere le sezioni corrispondenti.
- Autenticazione basata sulla chiave dell'account
- Autenticazione con firma di accesso condiviso
- Autenticazione dell'identità gestita assegnata dal sistema
- Autenticazione dell'identità gestita assegnata dall'utente
Autenticazione basata sulla chiave dell'account
È possibile creare un servizio collegato di Archiviazione di Azure usando la chiave dell'account, Fornisce al servizio l'accesso globale all'archiviazione. Sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su: AzureTableStorage. | Sì |
| connectionString | Specificare le informazioni necessarie per connettersi all'archiviazione per la proprietà connectionString. È anche possibile inserire la chiave dell'account in Azure Key Vault e rimuovere la configurazione di accountKey dalla stringa di connessione. Vedere gli esempi seguenti e l'articolo Archiviare le credenziali in Azure Key Vault per altri dettagli. |
Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare il runtime di integrazione di Azure o il runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Nota
L'uso di un servizio collegato di tipo "AzureStorage", è ancora supportato così com'è, tuttavia in futuro verrà consigliato di usare il nuovo tipo di servizio collegato "AzureTableStorage".
Esempio:
{
"name": "AzureTableStorageLinkedService",
"properties": {
"type": "AzureTableStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: archiviare la chiave dell'account in Azure Key Vault
{
"name": "AzureTableStorageLinkedService",
"properties": {
"type": "AzureTableStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione con firma di accesso condiviso
È anche possibile creare un servizio collegato di archiviazione tramite una firma di accesso condiviso. Consente al servizio di accede con restrizioni o limiti di tempo a tutte le risorse o a risorse specifiche nell'archiviazione.
Una firma di accesso condiviso fornisce accesso delegato controllato alle risorse dell'account di archiviazione. È possibile usarla per concedere a un client autorizzazioni limitate per gli oggetti nell'account di archiviazione per un periodo di tempo e con un set di autorizzazioni specificati. Non è necessario condividere le chiavi di accesso degli account. La firma di accesso condiviso è un URI che racchiude nei parametri di query tutte le informazioni necessarie per l'accesso autenticato a una risorsa di archiviazione. Per accedere alle risorse di archiviazione con la firma di accesso condiviso, il client deve solo passare la firma di accesso condiviso al costruttore o al metodo appropriato. Per altre informazioni sulle firme di accesso condiviso, vedere Uso delle firme di accesso condiviso.
Nota
Sia le firme di accesso condiviso del servizio che le firme di accesso condiviso dell'account non sono supportate. Per altre informazioni sulle firme di accesso condiviso, vedere Concedere accesso limitato alle risorse di archiviazione di Azure tramite firme di accesso condiviso.
Suggerimento
Per generare una firma di accesso condiviso del servizio per l'account di archiviazione, è possibile eseguire i comandi di PowerShell seguenti. Sostituire i segnaposto e concedere l'autorizzazione necessaria.
$context = New-AzStorageContext -StorageAccountName <accountName> -StorageAccountKey <accountKey>
New-AzStorageContainerSASToken -Name <containerName> -Context $context -Permission rwdl -StartTime <startTime> -ExpiryTime <endTime> -FullUri
Per usare l'autenticazione basata sulla firma di accesso condiviso, sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su: AzureTableStorage. | Sì |
| sasUri | Specificare l'URI SAS dell'URI della firma di accesso condiviso alla tabella. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro. È anche possibile inserire il token di firma di accesso condiviso in Azure Key Vault per sfruttare la rotazione automatica e rimuovere la parte del token. Vedere gli esempi seguenti e l'articolo Archiviare le credenziali in Azure Key Vault per altri dettagli. |
Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o il runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Nota
L'uso di un servizio collegato di tipo "AzureStorage", è ancora supportato così com'è, tuttavia in futuro verrà consigliato di usare il nuovo tipo di servizio collegato "AzureTableStorage".
Esempio:
{
"name": "AzureTableStorageLinkedService",
"properties": {
"type": "AzureTableStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<account>.table.core.windows.net/<table>?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: archiviare la chiave dell'account in Azure Key Vault
{
"name": "AzureTableStorageLinkedService",
"properties": {
"type": "AzureTableStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<account>.table.core.windows.net/<table>>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Quando si crea un URI di firma di accesso condiviso, tenere presente quanto segue:
- Impostare le autorizzazioni appropriate di lettura o scrittura per gli oggetti in base al modo in cui viene usato il servizio collegato (lettura, scrittura, lettura/scrittura).
- Impostare Ora di scadenza in modo appropriato. Assicurarsi che l'accesso agli oggetti di archiviazione non scada nel periodo attivo della pipeline.
- L'URI deve essere creato al giusto livello di tabella, in base alle necessità.
Autenticazione dell'identità gestita assegnata dal sistema
Una pipeline di data factory o di Synapse può essere associata a un'identità gestita assegnata dal sistema per risorse di Azure che rappresenta quella risorsa per l'autenticazione ad altri servizi di Azure. È possibile usare questa identità gestita assegnata dal sistema per l'autenticazione di Archiviazione tabelle di Azure. Per altre informazioni sulle identità gestite per le risorse di Azure, vedere Identità gestite per le risorse di Azure
Per usare l'autenticazione dell'identità gestita assegnata dal sistema, seguire questa procedura:
Recuperare le informazioni relative all'identità gestita assegnate dal sistema copiando il valore dell'ID oggetto identità gestito assegnato dal sistema generato insieme all'area di lavoro della factory o di Synapse.
Concedere l'autorizzazione per l'identità gestita in Archiviazione tabelle di Azure. Per altre informazioni sui ruoli, vedere questo articolo.
- Come origine in Controllo di accesso (IAM) concedere almeno il ruolo Lettore dei dati delle tabelle di archiviazione.
- Come sink, in Controllo di accesso (IAM), concedere almeno il ruolo Collaboratore dei dati delle tabelle di archiviazione.
Per un servizio collegato ad Archiviazione tabelle di Azure sono supportate queste proprietà:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureTableStorage. | Sì |
| serviceEndpoint | Specificare l'endpoint del servizio di Archiviazione tabelle di Azure con il criterio https://<accountName>.table.core.windows.net/. |
Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. Si può utilizzare Azure Integration Runtime. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Nota
L'autenticazione dell'identità gestita assegnata dal sistema è supportata solo da Azure Integration Runtime.
Esempio:
{
"name": "AzureTableStorageLinkedService",
"properties": {
"type": "AzureTableStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.table.core.windows.net/"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione dell'identità gestita assegnata dall'utente
Una data factory può essere assegnata con una o più identità gestite assegnate dall'utente. È possibile usare questa identità gestita assegnata dall'utente per l'autenticazione dell'archiviazione tabelle, che consente di accedere e copiare dati da o in Archiviazione tabelle di Azure. Per altre informazioni sulle identità gestite per le risorse di Azure, vedere Identità gestite per le risorse di Azure
Per usare l'autenticazione dell'identità gestita assegnata dall’utente, seguire questa procedura:
Creare una o più identità gestite assegnate dall'utente e concedere l'autorizzazione in Archiviazione tabelle di Azure. Per altre informazioni sui ruoli, vedere questo articolo.
- Come origine in Controllo di accesso (IAM) concedere almeno il ruolo Lettore dei dati delle tabelle di archiviazione.
- Come sink, in Controllo di accesso (IAM), concedere almeno il ruolo Collaboratore dei dati delle tabelle di archiviazione.
Assegnare una o più identità gestite assegnate dall'utente alla data factory e creare le credenziali per ogni identità gestita assegnata dall'utente.
Per un servizio collegato ad Archiviazione tabelle di Azure sono supportate queste proprietà:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureTableStorage. | Sì |
| serviceEndpoint | Specificare l'endpoint del servizio di Archiviazione tabelle di Azure con il criterio https://<accountName>.table.core.windows.net/. |
Sì |
| credentials | Specificare l'identità gestita assegnata dall'utente come oggetto credenziale. | Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o il runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio:
{
"name": "AzureTableStorageLinkedService",
"properties": {
"type": "AzureTableStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.table.core.windows.net/",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati Tabella di Azure.
Per copiare dati in e da Tabella di Azure, impostare la proprietà type del set di dati su AzureTable. Sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su AzureTable. | Sì |
| tableName | Nome della tabella nell'istanza del database di Archiviazione tabelle a cui fa riferimento il servizio collegato. | Sì |
Esempio:
{
"name": "AzureTableDataset",
"properties":
{
"type": "AzureTable",
"typeProperties": {
"tableName": "MyTable"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Table storage linked service name>",
"type": "LinkedServiceReference"
}
}
}
Inferenza dello schema dal servizio
Per gli archivi di dati privi di schema, ad esempio Tabella di Azure, il servizio deduce lo schema in uno dei modi seguenti:
- Se si specifica il mapping delle colonne nell'attività di copia, il servizio utilizza l'elenco di colonne sul lato di origine per recuperare i dati. In questo caso, se una riga non contiene un valore per una colonna, viene inserito un valore null.
- Se non si specifica il mapping delle colonne nell'attività di copia, il servizio deduce lo schema usando la prima riga dei dati. In questo caso, se la prima riga non contiene lo schema completo (ad es. alcune colonne hanno un valore null), alcune colonne risultano mancanti nel risultato dell'operazione di copia.
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine e dal sink Tabella di Azure.
Tabelle di Azure come tipo di origine
Per copiare dati da Tabella di Azure, impostare il tipo di origine nell'attività di copia su AzureTableSource. Nella sezione source dell'attività di copia sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su AzureTableSource. | Sì |
| AzureTableSourceQuery | Usare la query di Archiviazione tabelle personalizzata per leggere i dati. La query di origine è una mappa diretta dall'opzione di query $filter supportata da Archiviazione tabelle di Azure, altre informazioni sulla sintassi di questo documento e vedere gli esempi nella sezione seguente degli esempi di azureTableSourceQuery. |
No |
| azureTableSourceIgnoreTableNotFound | Indica se consentire l'eccezione di tabella non esistente. I valori consentiti sono True e False (predefinito). |
No |
esempi di azureTableSourceQuery
Nota
Il timeout dell'operazione di query di Tabella di Azure è di 30 secondi, secondo quanto applicato dal servizio tabelle di Azure. Per informazioni su come ottimizzare la query, vedere l'articolo Progettazione per le query.
Se invece si vuole filtrare i dati in base a una colonna di tipo Data/ora, fare riferimento a questo esempio:
"azureTableSourceQuery": "LastModifiedTime gt datetime'2017-10-01T00:00:00' and LastModifiedTime le datetime'2017-10-02T00:00:00'"
Se invece si vuole filtrare i dati in base a una colonna di tipo stringa, fare riferimento a questo esempio:
"azureTableSourceQuery": "LastModifiedTime ge '201710010000_0000' and LastModifiedTime le '201710010000_9999'"
Se si usa un parametro della pipeline, eseguire il cast del valore datetime al formato corretto come illustrato negli esempi precedenti.
Tabelle di Azure come tipo di sink
Per copiare dati in Tabella di Azure, impostare il tipo di sink nell'attività di copia su AzureTableSink. Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del sink dell'attività di copia deve essere impostata su AzureTableSink. | Sì |
| azureTableDefaultPartitionKeyValue | Valore predefinito della chiave di partizione che può essere usato dal sink. | No |
| azureTablePartitionKeyName | Specificare il nome della colonna i cui valori vengono usati come chiavi di partizione. Se non specificato, viene usato "AzureTableDefaultPartitionKeyValue" come chiave di partizione. | No |
| azureTableRowKeyName | Specificare il nome della colonna i cui valori vengono usati come chiave di riga. Se non specificato, usare un GUID per ogni riga. | No |
| azureTableInsertType | Modalità di inserimento dei dati in una tabella di Azure. Questa proprietà verifica se per le righe esistenti nella tabella di output con chiavi di partizione e di riga corrispondenti i valori vengono sostituiti o uniti. I valori consentiti sono: merge (predefinito) e replace. Questa impostazione si applica a livello di riga e non a livello di tabella. Nessuna delle due opzioni consente di eliminare righe nella tabella di output che non esistono nell'input. Per scoprire come funzionano le impostazioni merge e replace, vedereInsert or Merge Entity (Inserire o unire un'entità) e Insert or Replace Entity (Inserire o sostituire un'entità). |
No |
| writeBatchSize | Inserisce dati in Tabella di Azure quando viene raggiunto il valore di writeBatchSize o writeBatchTimeout. I valori consentiti sono integer (numero di righe). |
No (il valore predefinito è 10.000) |
| writeBatchTimeout | Inserisce dati in Tabella di Azure quando viene raggiunto il valore di writeBatchSize o writeBatchTimeout. I valori consentiti sono un intervallo di tempo. Ad esempio "00:20:00" (20 minuti). |
No (il valore predefinito è 90 secondi, il timeout predefinito del client di archiviazione) |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
Esempio:
"activities":[
{
"name": "CopyToAzureTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Table output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureTableSink",
"azureTablePartitionKeyName": "<column name>",
"azureTableRowKeyName": "<column name>"
}
}
}
]
azureTablePartitionKeyName
È necessario eseguire il mapping di una colonna di origine a una colonna di destinazione usando la proprietà translator prima di poter usare la colonna di destinazione come azureTablePartitionKeyName.
Nell'esempio seguente viene eseguito il mapping della colonna di origine DivisionID alla colonna di destinazione DivisionID:
"translator": {
"type": "TabularTranslator",
"columnMappings": "DivisionID: DivisionID, FirstName: FirstName, LastName: LastName"
}
"DivisionID" è specificato come chiave di partizione.
"sink": {
"type": "AzureTableSink",
"azureTablePartitionKeyName": "DivisionID"
}
Mapping dei tipi di dati per Tabella di Azure
Quando si copiano dati da e in Tabella di Azure, vengono usati i mapping seguenti tra i tipi di dati di Tabella di Azure e i tipi di dati provvisori usati internamente al servizio. Per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink, vedere Mapping dello schema e del tipo di dati.
Quando si spostano i dati da e verso Tabella di Azure, i seguenti mapping definiti da Tabella di Azure vengono usati dai tipi OData di Tabella di Azure al tipo .NET e viceversa.
| Tipo di dati di Tabella di Azure | Tipo di dati del servizio provvisorio | Dettagli |
|---|---|---|
| Edm.Binary | byte[] | Una matrice di byte di dimensioni fino a 64 KB. |
| Edm.Boolean | bool | Valore booleano. |
| Edm.DateTime | Data/Ora | Un valore a 64 bit espresso come Coordinated Universal Time (UTC). L'intervallo DateTime supportato inizia a mezzanotte del 1 gennaio 1601 D.C. (C.E.), UTC. L'intervallo termina il 31 dicembre 9999. |
| Edm.Double | double | Un valore a virgola mobile a 64 bit. |
| Edm.Guid | GUID | Un identificatore univoco globale a 128 bit. |
| Edm.Int32 | Int32 | Un valore integer a 32 bit. |
| Edm.Int64 | Int64 | Un valore integer a 64 bit. |
| Edm.String | String | Un valore con codifica UTF-16. I valori string possono avere dimensioni fino a 64 KB. |
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività di copia, vedere Archivi dati supportati.