Copiare e trasformare i dati in Microsoft Fabric Warehouse usando Azure Data Factory o Azure Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività Copy per copiare dati da e in Microsoft Fabric Warehouse. Per altre informazioni, leggere l'articolo introduttivo per Azure Data Factory o Azure Synapse Analytics.
Funzionalità supportate
Questo connettore Microsoft Fabric Warehouse è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR | Endpoint privato gestito |
|---|---|---|
| Attività di copia (origine/sink) | 7.3 | ✓ |
| Flusso di dati di mapping (origine/sink) | 1 | ✓ |
| Attività Lookup | 7.3 | ✓ |
| Attività GetMetadata | 7.3 | ✓ |
| Attività script | 7.3 | ✓ |
| Attività stored procedure | 7.3 | ✓ |
① Runtime di integrazione di Azure ② Runtime di integrazione self-hosted
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato Microsoft Fabric Warehouse usando l'interfaccia utente
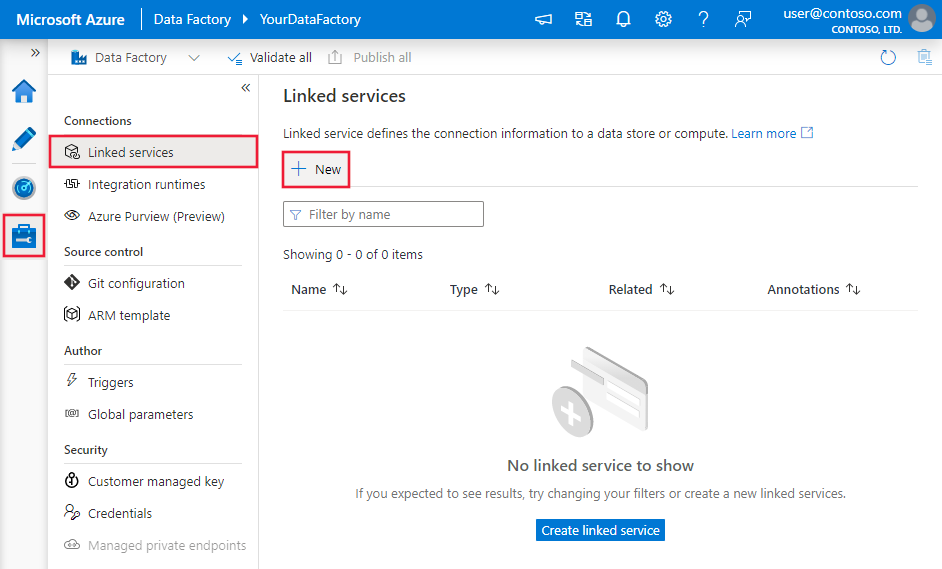
Usare la procedura seguente per creare un servizio collegato Microsoft Fabric Warehouse nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi selezionare Nuovo:
Cercare Warehouse e selezionare il connettore.
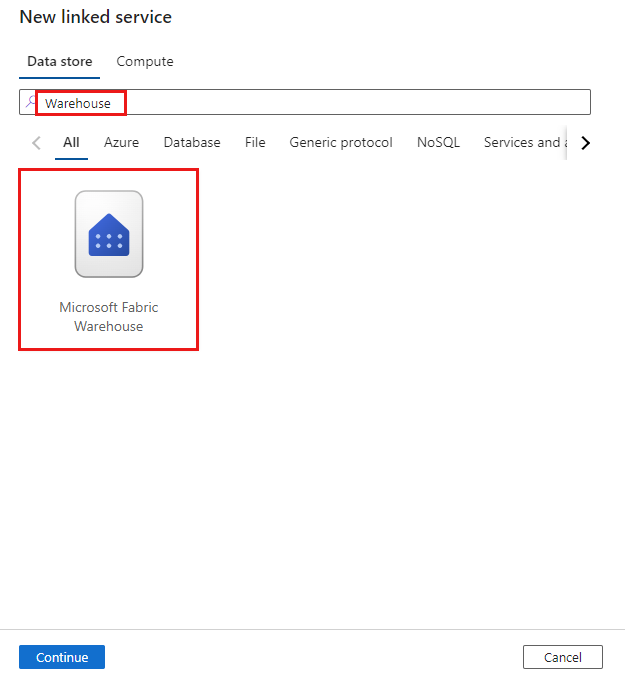
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
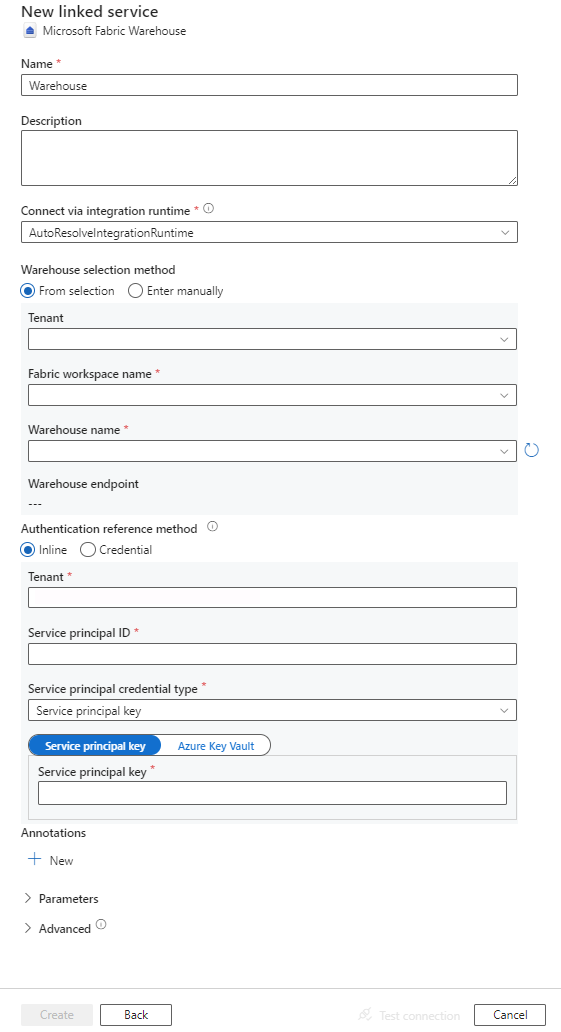
Dettagli di configurazione del connettore
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà usate per definire entità di Data Factory specifiche di Microsoft Fabric Warehouse.
Proprietà del servizio collegato
Il connettore Microsoft Fabric Warehouse supporta i tipi di autenticazione seguenti. Per informazioni dettagliate, vedere le sezioni corrispondenti:
Autenticazione dell'entità servizio
Per usare l'autenticazione basata sull'entità servizio, eseguire queste operazioni.
Registrare un'applicazione con Microsoft Identity Platform e aggiungere un segreto client. Successivamente, prendere nota di questi valori che si usano per definire il servizio collegato:
- ID applicazione (client), ovvero l'ID entità servizio nel servizio collegato.
- Valore del segreto client, ovvero la chiave dell'entità servizio nel servizio collegato.
- ID tenant
Concedere all'entità servizio almeno il ruolo Collaboratore nell'area di lavoro di Microsoft Fabric. Seguire questa procedura:
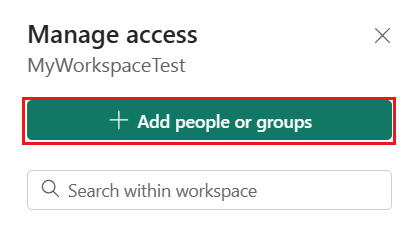
Andare all'area di lavoro di Microsoft Fabric, selezionare Gestisci accesso nella barra superiore. Successivamente, selezionare Aggiungi persone o gruppi.
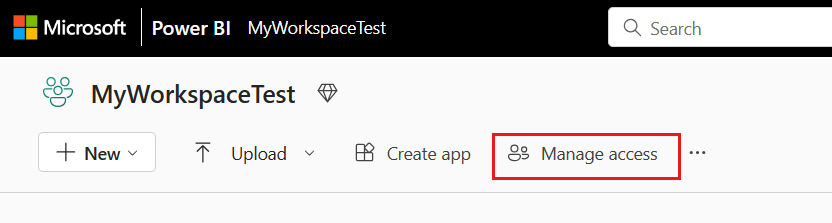
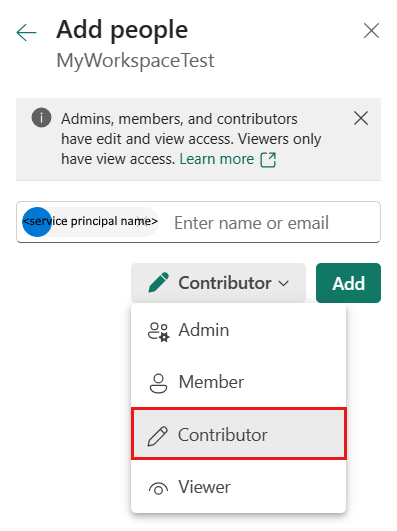
Nel riquadro Aggiungi persone immettere il nome dell'entità servizio e selezionare l'entità servizio dall'elenco a discesa.
Specificare il ruolo Collaboratore o superiore (Amministratore, Membro), quindi selezionare Aggiungi.
L'entità servizio viene visualizzata nel riquadro Gestisci accesso.
Queste sono le proprietà supportate dal servizio collegato:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su Warehouse. | Sì |
| endpoint | Endpoint del server Microsoft Fabric Warehouse. | Sì |
| workspaceId | ID dell'area di lavoro di Microsoft Fabric. | Sì |
| artifactId | ID oggetto Microsoft Fabric Warehouse. | Sì |
| tenant | Specificare le informazioni sul tenant (nome di dominio o ID tenant) in cui si trova l'applicazione. Recuperarlo passando il cursore del mouse sull'angolo superiore destro del portale di Azure. | Sì |
| servicePrincipalId | Specificare l'ID client dell'applicazione. | Sì |
| servicePrincipalCredentialType | Tipo di credenziale da usare per l'autenticazione dell'entità servizio. I valori consentiti sono ServicePrincipalKey e ServicePrincipalCert. | Sì |
| servicePrincipalCredential | Credenziali dell'entità servizio. Quando si usa ServicePrincipalKey come tipo di credenziale, specificare il valore del segreto client dell'applicazione. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro, oppure fare riferimento a un segreto archiviato in Azure Key Vault. Quando si usa ServicePrincipalCert come credenziale, fare riferimento a un certificato in Azure Key Vault e assicurarsi che il tipo di contenuto del certificato sia PKCS #12. |
Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio: usare l'autenticazione con chiave dell'entità servizio
È anche possibile archiviare la chiave dell'entità servizio in Azure Key Vault.
{
"name": "MicrosoftFabricWarehouseLinkedService",
"properties": {
"type": "Warehouse",
"typeProperties": {
"endpoint": "<Microsoft Fabric Warehouse server endpoint>",
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Warehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati.
Per il set di dati Microsoft Fabric Warehouse sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su WarehouseTable. | Sì |
| schema | Nome dello schema. | No per l'origine, Sì per il sink |
| table | Nome della tabella/vista. | No per l'origine, Sì per il sink |
Esempio di proprietà dei set di dati
{
"name": "FabricWarehouseTableDataset",
"properties": {
"type": "WarehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Warehouse linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring >
],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere Configurazioni dell'attività di copia e Pipeline e attività. Questa sezione presenta un elenco delle proprietà supportate dall'origine e dal sink Microsoft Fabric Warehouse.
Microsoft Fabric Warehouse come origine
Suggerimento
Per caricare i dati da Microsoft Fabric Warehouse in modo efficiente usando il partizionamento dei dati, vedere Copia parallela da Microsoft Fabric Warehouse.
Per copiare dati da Microsoft Fabric Warehouse, impostare la proprietà type nell'origine dell'attività Copy su WarehouseSource. Nella sezione source dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività Copy deve essere impostata su: CouchbaseSource. | Sì |
| sqlReaderQuery | Usare la query SQL personalizzata per leggere i dati. Esempio: select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Nome della stored procedure che legge i dati dalla tabella di origine. L'ultima istruzione SQL deve essere un'istruzione SELECT nella stored procedure. | No |
| storedProcedureParameters | Parametri per la stored procedure. I valori consentiti sono coppie nome-valore. I nomi e le maiuscole e minuscole dei parametri devono corrispondere ai nomi e alle maiuscole e minuscole dei parametri della stored procedure. |
No |
| queryTimeout | Specifica il timeout per l'esecuzione del comando di query. Il valore predefinito è 120 minuti. | No |
| isolationLevel | Specifica il comportamento di blocco della transazione per l'origine SQL. Il valore consentito è Snapshot. Se non è specificato, viene utilizzato il livello di isolamento predefinito del database. Per altre informazioni, vedere system.data.isolationlevel. | No |
| partitionOptions | Specifica le opzioni di partizionamento dei dati usate per caricare i dati da Microsoft Fabric Warehouse. I valori consentiti sono: Nessuno (impostazione predefinita) e DynamicRange. Quando un'opzione di partizione è abilitata (ovvero non None), il grado di parallelismo per caricare simultaneamente i dati da Microsoft Fabric Warehouse è controllato dall'impostazione parallelCopies nell'attività Copy. |
No |
| partitionSettings | Specifica il gruppo di impostazioni per il partizionamento dei dati. Applicare quando l'opzione di partizione non è None. |
No |
In partitionSettings: |
||
| partitionColumnName | Specificare il nome della colonna di origine nel tipo integer o data/datetime (int, smallint, bigint, date, datetime2) che verrà usato nel partizionamento per intervalli per la copia parallela. Se non specificato, l'indice o la chiave primaria della tabella vengono rilevati automaticamente e usati come colonna di partizione.Si applica quando l'opzione di partizione è DynamicRange. Se si usa una query per recuperare i dati di origine, associare ?DfDynamicRangePartitionCondition nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Microsoft Fabric Warehouse. |
No |
| partitionUpperBound | Valore massimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività Copy rileva automaticamente il valore. Si applica quando l'opzione di partizione è DynamicRange. Per un esempio, vedere la sezione Copia parallela da Microsoft Fabric Warehouse. |
No |
| partitionLowerBound | Valore minimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività Copy rileva automaticamente il valore. Si applica quando l'opzione di partizione è DynamicRange. Per un esempio, vedere la sezione Copia parallela da Microsoft Fabric Warehouse. |
No |
Nota
Quando si usa la stored procedure nell'origine per recuperare dati, tenere presente che se la stored procedure è progettata per restituire schemi diversi quando viene passato un valore di parametro diverso, è possibile che si verifichi un errore o un risultato imprevisto durante l'importazione dello schema dall'interfaccia utente o quando si copiano dati in Microsoft Fabric Warehouse con la creazione automatica della tabella.
Esempio: uso della query SQL
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Esempio: uso della stored procedure
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Stored procedure di esempio:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Microsoft Fabric Warehouse come tipo di sink
Le pipeline di Azure Data Factory e Synapse supportano l'istruzione Usa COPY per caricare i dati in Microsoft Fabric Warehouse.
Per copiare dati in Microsoft Fabric Warehouse, impostare il tipo di sink nell'attività Copy su WarehouseSink. Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del sink dell'attività Copy deve essere impostata su WarehouseSink. | Sì |
| allowCopyCommand | Indica se usare l'istruzione COPY per caricare i dati in Microsoft Fabric Warehouse. Per informazioni su vincoli e dettagli, vedere la sezione Usare l'istruzione COPY per caricare dati in Microsoft Fabric Warehouse. Il valore consentito è True. |
Sì |
| copyCommandSettings | Gruppo di proprietà che è possibile specificare quando la proprietà allowCopyCommand è impostata su TRUE. |
No |
| writeBatchTimeout | Questa proprietà specifica il tempo di attesa per il completamento dell'operazione insert, upsert e stored procedure prima del timeout. I valori consentiti sono relativi all'intervallo di tempo. Esempio: "00:30:00" per 30 minuti. Se non si specifica alcun valore, viene utilizzato il timeout predefinito: "00:30:00" |
No |
| preCopyScript | Specificare una query SQL per l'attività Copy da eseguire prima di scrivere i dati in Microsoft Fabric Warehouse ad ogni esecuzione. Usare questa proprietà per pulire i dati precaricati. | No |
| tableOption | Specifica se creare automaticamente la tabella sink, se non esistente, in base allo schema di origine. I valori consentiti sono: none (impostazione predefinita), autoCreate. |
No |
| disableMetricsCollection | Il servizio raccoglie le metriche per l'ottimizzazione delle prestazioni di copia e le raccomandazioni, che introducono l'accesso al database master aggiuntivo. Se questo comportamento non è desiderato, specificare true per disattivarlo. |
No (il valore predefinito è false) |
Esempio: sink di Microsoft Fabric Warehouse
"activities":[
{
"name": "CopyToMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Warehouse output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"tableOption": "autoCreate",
"disableMetricsCollection": false
}
}
}
]
Copia parallela da Microsoft Fabric Warehouse
Il connettore Microsoft Fabric Warehouse nell'attività Copy fornisce il partizionamento dei dati predefinito per copiare i dati in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella tabella Origine dell'attività di copia.
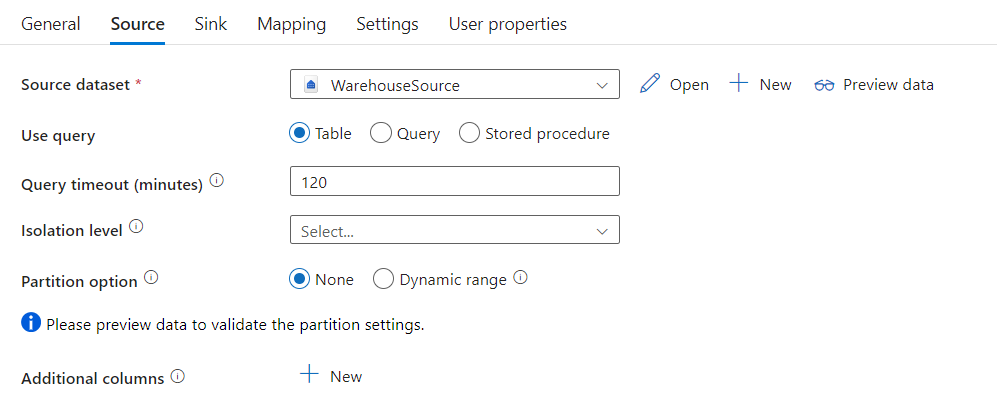
Quando si abilita la copia partizionata, l'attività Copy esegue query parallele sull'origine di Microsoft Fabric Warehouse per caricare i dati in base alle partizioni. Il grado di parallelismo è controllato dall'impostazione parallelCopies sull'attività di copia. Ad esempio, se si imposta parallelCopies su quattro, il servizio genera ed esegue simultaneamente quattro query in base all'opzione e alle impostazioni di partizione specificate e ogni query recupera una porzione di dati da Microsoft Fabric Warehouse.
Si consiglia di abilitare la copia parallela con il partizionamento dei dati, specialmente quando si caricano grandi quantità di dati dal database di Microsoft Fabric Warehouse. Di seguito sono riportate le configurazioni consigliate per i diversi scenari: Quando si copiano dati in un archivio dati basato su file, è consigliabile scrivere in una cartella come file multipli (specificare solo il nome della cartella); in tal caso, le prestazioni risultano migliori rispetto alla scrittura in un singolo file.
| Scenario | Impostazioni consigliate |
|---|---|
| Caricamento completo da una tabella di grandi dimensioni, mentre con una colonna integer o datetime per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Colonna partizione (facoltativo): specificare la colonna usata per il partizionamento dei dati. Se non specificato, viene utilizzata la colonna di indice o chiave primaria. Limite superiore partizione e limite inferiore partizione (facoltativo): specificare se si desidera determinare lo stride della partizione. Ciò non è utile a filtrare le righe nella tabella; tutte le righe della tabella verranno partizionate e copiate. Se non è specificato, l'attività di copia rileva automaticamente i valori. Ad esempio, se “ID” della colonna partizione include valori compresi tra 1 e 100 e si imposta come limite inferiore 20 e come limite superiore 80, con copia parallela 4, il servizio recupera i dati in base a 4 partizioni - ID nell'intervallo < = 20, [21, 50], [51, 80] e > = 81 rispettivamente. |
| Caricamento di notevoli quantità di dati utilizzando una query personalizzata, con una colonna integer o date/datetime per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. Limite superiore partizione e limite inferiore partizione (facoltativo): specificare se si desidera determinare lo stride della partizione. Ciò non è utile a filtrare le righe nella tabella; tutte le righe del risultato della query verranno partizionate e copiate. Se non specificato, l'attività Copy rileva automaticamente il valore. Ad esempio, se la colonna di partizione "ID" include valori compresi tra 1 e 100 e si imposta il limite inferiore su 20 e il limite superiore su 80, con copia parallela come 4 il servizio recupera i dati per 4 partizioni - ID nell'intervallo <=20, [21, 50], [51, 80], e >=81, rispettivamente. Di seguito sono riportate altre query di esempio per diversi scenari: 1. Eseguire una query sull'intera tabella: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Eseguire una query da una tabella con selezione colonne e filtri aggiuntivi per la clausola where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Query con sottoquery: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Query con partizione nella sottoquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Procedure consigliate per il caricamento di dati con opzione partizione:
- Scegliere una colonna distintiva come colonna partizione (ad esempio, chiave primaria o chiave univoca) per evitare l'asimmetria dei dati.
- Se si usa Azure Integration Runtime per copiare i dati, è possibile impostare "Unità di integrazione dati (DIU)" (>4) perché utilizzi più risorse di calcolo. Controllare gli scenari applicabili.
- “Grado di parallelismo copia” controlla i numeri partizione; impostando per questo numero un valore eccessivo, a volte le prestazioni si riducono. È preferibile impostare questo numero come (DIU o numero di nodi del runtime di integrazione self-hosted) * (2-4).
- Si noti che Microsoft Fabric Warehouse può eseguire un massimo di 32 query al momento, impostando "Grado di parallelismo di copia" troppo grande può causare un problema di limitazione del warehouse.
Esempio: query con partizione a intervalli dinamici
"source": {
"type": "WarehouseSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Usare l'istruzione COPY per caricare i dati in Microsoft Fabric Warehouse
L'uso dell'istruzione COPY è un modo semplice e flessibile per caricare i dati in Microsoft Fabric Warehouse con velocità effettiva elevata. Per altre informazioni, controllare caricamento bulk dei dati usando l'istruzione COPY
- Se i dati di origine si trovano in BLOB di Azure o Azure Data Lake Storage Gen2e il formato è compatibile con l'istruzione COPY, è possibile usare l'attività Copy per richiamare direttamente l'istruzione COPY per consentire a Microsoft Fabric Warehouse di estrarre i dati dall'origine. Per maggiori dettagli, vedere Copia diretta usando l’istruzione COPY.
- Se l'archivio dati di origine e il formato non sono originariamente supportati dall'istruzione COPY, usare invece la copia di staging usando la funzionalità istruzione COPY. La funzionalità copia di staging assicura inoltre una migliore velocità effettiva. Converte automaticamente i dati in un formato compatibile con l'istruzione COPY, archivia i dati nell'archivio BLOB di Azure e quindi chiama l'istruzione COPY per caricare i dati in Microsoft Fabric Warehouse.
Suggerimento
Quando si usa l'istruzione COPY con Azure Integration Runtime, le unità di integrazione dei dati (DIU) effettive sono sempre 2. L'ottimizzazione dell'unità di distribuzione non influisce sulle prestazioni.
Copia diretta tramite l'istruzione COPY
L'istruzione COPY di Microsoft Fabric Warehouse supporta direttamente BLOB di Azure, Azure Data Lake Storage Gen1 e Azure Data Lake Storage Gen2. Se i dati di origine soddisfano i criteri descritti in questa sezione, usare l’istruzione COPY per copiare direttamente dall'archivio dati di origine a Microsoft Fabric Warehouse. In caso contrario, usare Copia di staging usando l'istruzione COPY. Il servizio controlla le impostazioni e, se i criteri non vengono soddisfatti, l'esecuzione dell'attività di copia non riesce.
Il servizio collegato all'origine e il formato hanno i tipi e i metodi di autenticazione seguenti:
Tipo di archivio dati di origine supportato Formato supportato Tipo di autenticazione di origine supportato BLOB di Azure Testo delimitato Autenticazione della chiave dell'account, autenticazione con firma di accesso condiviso Parquet Autenticazione della chiave dell'account, autenticazione con firma di accesso condiviso Azure Data Lake Storage Gen2 Testo delimitato
ParquetAutenticazione della chiave dell'account, autenticazione con firma di accesso condiviso Le impostazioni del formato sono le seguenti:
- Per Parquet:
compressionpuò essere no compression, Snappy oGZip. - Per Testo delimitato:
rowDelimiterè impostato in modo esplicito come single character o "\r\n", il valore predefinito non è supportato.nullValueè impostato sul valore predefinito o su empty string ("").encodingNameè impostato sul valore predefinito o su utf-8 o utf-16.escapeChardeve essere uguale aquoteChare non è vuoto.skipLineCountè impostato sul valore predefinito o su 0.compressionpuò essere no compression oGZip.
- Per Parquet:
Se l'origine è una cartella,
recursivenell'attività di copia deve essere impostato su true ewildcardFilenamedeve essere*o*.*.wildcardFolderPath,wildcardFilename(diverso da*o*.*),modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscoveryandadditionalColumnsnon sono specificati.
Le impostazioni dell'istruzione COPY seguenti sono supportate in allowCopyCommand nell'attività di copia:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| defaultValues | Specifica i valori predefiniti per ogni colonna di destinazione in Microsoft Fabric Warehouse. I valori predefiniti nella proprietà sovrascrivono il vincolo DEFAULT impostato nel data warehouse e la colonna Identity non può avere un valore predefinito. | No |
| additionalOptions | Opzioni aggiuntive che verranno passate a un'istruzione COPY di Microsoft Fabric Warehouse direttamente nella clausola "With" nell'istruzione COPY. Racchiudere il valore tra virgolette come previsto dai requisiti dell'istruzione COPY. | No |
"activities":[
{
"name": "CopyFromAzureBlobToMicrosoftFabricWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Copia di staging tramite l'istruzione COPY
Quando i dati di origine non sono compatibili in modo nativo con l'istruzione COPY, abilitare la copia dei dati tramite un BLOB di Azure di staging provvisorio o Azure Data Lake Storage Gen2 (non può essere Archiviazione Premium di Azure). In questo caso, il servizio converte automaticamente i dati in modo da soddisfare i requisiti di formato dei dati dell'istruzione COPY. Richiama quindi l'istruzione COPY per caricare i dati in Microsoft Fabric Warehouse. Infine, pulisce i dati temporanei dall'archiviazione. Per informazioni dettagliate sulla copia dei dati tramite una gestione temporanea, vedere Copia di staging.
Per usare questa funzionalità, creare un servizio collegato di Archiviazione BLOB di Azure o un servizio collegato Azure Data Lake Storage Gen2 con chiave dell'account o l'autenticazione dell'identità gestita dal sistema che fa riferimento all'account di archiviazione di Azure come risorsa di archiviazione temporanea.
Importante
- Quando si usa l'autenticazione dell'identità gestita per il servizio collegato di staging, apprendere le configurazioni necessarie rispettivamente per BLOB di Azure e Azure Data Lake Storage Gen2.
- Se l'archiviazione di Azure di staging è configurata con l'endpoint del servizio di rete virtuale, è necessario usare l'autenticazione dell'identità gestita con "consenti il servizio Microsoft attendibile" abilitato nell'account di archiviazione, vedere Impatto sull'uso degli endpoint del servizio di rete virtuale con Archiviazione di Azure.
Importante
Se l'archiviazione di Azure di staging è configurata con l'endpoint privato gestito e il firewall di archiviazione è abilitato, è necessario usare l'autenticazione dell'identità gestita e concedere le autorizzazioni di lettura dei dati dei BLOB di archiviazione a Synapse SQL Server per assicurarsi che possa accedere ai file di gestione temporanea durante il caricamento dell'istruzione COPY.
"activities":[
{
"name": "CopyFromSQLServerToMicrosoftFabricWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Proprietà del flusso di dati per mapping
Durante la trasformazione dei dati in un flusso di dati per mapping è possibile leggere e scrivere in tabelle da/in Microsoft Fabric Warehouse. Per altre informazioni, vedere la trasformazione origine e la trasformazione sink nei flussi di dati per mapping.
Microsoft Fabric Warehouse come origine
Le impostazioni specifiche di Microsoft Fabric Warehouse sono disponibili nella scheda Opzioni origine della trasformazione origine.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Input | Selezionare se puntare l'origine verso una tabella (equivalente a Select* from tablename) oppure immettere una query SQL personalizzata o recuperare i dati da una stored procedure. Query: se si seleziona Query nel campo di input, immettere una query SQL per l'origine. Questa impostazione esegue l'override di qualsiasi tabella scelta nel set di dati. Le clausole Order By non sono supportate, ma è possibile impostare un'istruzione SELECT FROM completa. È possibile usare anche funzioni di tabella definite dall'utente. select * from udfGetData() è un UDF in SQL che restituisce una tabella. Questa query produrrà una tabella di origine che può essere usata nel flusso di dati. Anche l'uso di query è un ottimo modo per ridurre le righe per i test o le ricerche. Esempio SQL: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Sì | Tabella o query o stored procedure | formato: 'table' |
| Dimensioni del batch | Immettere una dimensione batch per suddividere dati di grandi dimensioni in letture. Nei flussi di dati, questa impostazione verrà usata per impostare la memorizzazione nella cache a colonne Spark. Se viene lasciato vuoto, questo campo di opzione userà le impostazioni predefinite di Spark. | No | Valori numerali | batchSize: 1234 |
| Livello di isolamento | Il valore predefinito per le origini SQL nel flusso di dati per mapping è Read Uncommitted. È possibile modificare il livello di isolamento in uno di questi valori:• Read Committed • Read Uncommitted • Repeatable Read Serializable •• None (ignora il livello di isolamento) | Sì | • Read Committed • Read Uncommitted • Repeatable Read • Serializable • None (ignora il livello di isolamento) | isolationLevel |
Nota
La lettura tramite staging non è supportata. Il supporto CDC per Microsoft Fabric Warehouse non è attualmente disponibile.
Microsoft Fabric Warehouse come sink
Le impostazioni specifiche di Microsoft Fabric Warehouse sono disponibili nella scheda Impostazioni della trasformazione sink.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Metodo di aggiornamento | determina le operazioni consentite nella destinazione del database. Per impostazione predefinita, sono consentiti solo gli inserimenti. Per eseguire operazioni di aggiornamento, upsert o eliminazione di righe, è necessaria una trasformazione alter-row che applichi alle righe i tag corrispondenti alle azioni. Per le operazioni di aggiornamento, upsert ed eliminazione è necessario impostare una o più colonne chiave per determinare quale riga modificare. | Sì | true o false | insertable deletable upsertable updateable |
| Azione Tabella | Determina se ricreare o rimuovere tutte le righe dalla tabella di destinazione prima della scrittura. None: non verrà eseguita alcuna azione sulla tabella. Ricrea: la tabella verrà eliminata e ricreata. Obbligatorio se si crea una nuova tabella in modo dinamico.• Tronca: tutte le righe della tabella di destinazione verranno rimosse. | No | Nessuno o Ricrea o Tronca | recreate: true truncate: true |
| Abilita staging | L'archiviazione di staging è configurata nell’attività Esegui flusso di dati. Quando si usa l'autenticazione dell'identità gestita per il servizio collegato di archiviazione, apprendere le configurazioni necessarie per BLOB di Azure e Azure Data Lake Storage Gen2 rispettivamente. Se Archiviazione di Azure è configurato con l'endpoint servizio della rete virtuale, è necessario usare l'autenticazione dell'identità gestita con "Consenti il servizio Microsoft attendibile" nell'account di archiviazione. Fare riferimento a Impatto sull'uso degli endpoint servizio della rete virtuale con Archiviazione di Azure. | No | true o false | staged: true |
| Dimensioni del batch | controlla il numero di righe scritte in ogni bucket. Dimensioni batch più grandi migliorano l'ottimizzazione della compressione e della memoria, ma rischiano di causare eccezioni di memoria insufficiente durante la memorizzazione nella cache dei dati. | No | Valori numerali | batchSize: 1234 |
| Usare lo schema sink | Per impostazione predefinita, verrà creata una tabella temporanea nello schema del sink come staging. In alternativa, è possibile deselezionare l’opzione Usa schema sink e, in Selezionare lo schema del database utente, specificare un nome di schema in cui Data Factory creerà una tabella di staging per caricare i dati upstream e pulirli automaticamente al completamento. Assicurarsi di disporre dell'autorizzazione create table nel database e di modificare l'autorizzazione per lo schema. | No | true o false | stagingSchemaName |
| Pre e post-script SQL | immettere script SQL a più righe che verranno eseguiti prima (pre-elaborazione) e dopo (post-elaborazione) la scrittura dei dati nel database sink. | No | Script SQL | preSQLs:['set IDENTITY_INSERT mytable ON'] postSQLs:['set IDENTITY_INSERT mytable OFF'], |
Gestione delle righe con errori
Per impostazione predefinita, un'esecuzione del flusso di dati avrà esito negativo al primo errore che riceve. È possibile scegliere Continua in caso di errore che consente il completamento del flusso di dati anche se le singole righe presentano errori. Il servizio offre diverse opzioni per gestire queste righe di errore.
Commit transazione: scegliere se i dati vengono scritti in una singola transazione o in batch. La singola transazione offrirà prestazioni migliori e nessun dato scritto sarà visibile ad altri fino al completamento della transazione. Le transazioni batch hanno prestazioni peggiori, ma possono funzionare per set di dati di grandi dimensioni.
Output dei dati rifiutati: se abilitata, è possibile restituire le righe di errore in un file CSV in Archiviazione BLOB di Azure o in un account Azure Data Lake Storage Gen2 scelto. Verranno scritte le righe di errore con tre colonne aggiuntive: l'operazione SQL, ad esempio INSERIMENTO o AGGIORNAMENTO, il codice di errore del flusso di dati e il messaggio di errore nella riga.
Segnala l'esito positivo dell'errore: se abilitato, il flusso di dati verrà contrassegnato come operazione riuscita anche se vengono trovate righe di errore.
Nota
Per il servizio collegato Microsoft Fabric Warehouse, il tipo di autenticazione supportato per l'entità servizio è 'Key'; L'autenticazione 'Certificate' non è supportata.
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Proprietà dell'attività GetMetadata
Per altre informazioni sulle proprietà, vedere Attività GetMetadata
Mapping dei tipi di dati per Microsoft Fabric Warehouse
Quando si copiano dati da Microsoft Fabric Warehouse, i mapping seguenti vengono usati dai tipi di dati di Microsoft Fabric Warehouse ai tipi di dati provvisori all'interno del servizio internamente. Per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink, vedere Mapping dello schema e del tipo di dati.
| Tipo di dati di Microsoft Fabric Warehouse | Tipo di dati provvisorio di Data Factory |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Booleano |
| char | String, Char[] |
| data | Data/Ora |
| datetime2 | Data/Ora |
| Decimale | Decimale |
| FILESTREAM attribute (varbinary(max)) | Byte[] |
| Float | Double |
| int | Int32 |
| numeric | Decimale |
| real | Singola |
| smallint | Int16 |
| Ora | TimeSpan |
| uniqueidentifier | GUID |
| varbinary | Byte[] |
| varchar | String, Char[] |
Passaggi successivi
Per un elenco degli archivi dati supportati come origini e sink dall'attività di copia, vedere Archivi dati supportati.