Copiare dati da o in MongoDB Atlas usando Azure Data Factory o Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività Copy in una pipeline di Azure Data Factory o Synapse Analytics per copiare dati da e in un database di MongoDB Atlas. Si basa sull'articolo di panoramica dell'attività di copia che presenta una panoramica generale sull'attività di copia.
Funzionalità supportate
Questo connettore MongoDB Atlas è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (origine/sink) | 7.3 |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini o sink, vedere la tabella Archivi dati supportati.
Prerequisiti
Se l'archivio dati si trova all'interno di una rete locale, una rete virtuale di Azure o un cloud privato virtuale di Amazon, è necessario configurare un runtime di integrazione self-hosted per connettersi.
Se l'archivio dati è un servizio dati del cloud gestito, è possibile usare Azure Integration Runtime. Se l'accesso è limitato solo agli indirizzi IP approvati nelle regole del firewall, è possibile aggiungere IP di Azure Integration Runtime nell'elenco Consentiti.
È anche possibile usare la funzionalitàruntime di integrazione della rete virtuale gestita in Azure Data Factory per accedere alla rete locale senza installare e configurare un runtime di integrazione self-hosted.
Per altre informazioni sui meccanismi di sicurezza di rete e sulle opzioni supportate da Data Factory, vedere strategie di accesso ai dati.
Introduzione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato a MongoDB Atlas usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a MongoDB Atlas nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare MongoDB Atlas e selezionare il connettore MongoDB Atlas.
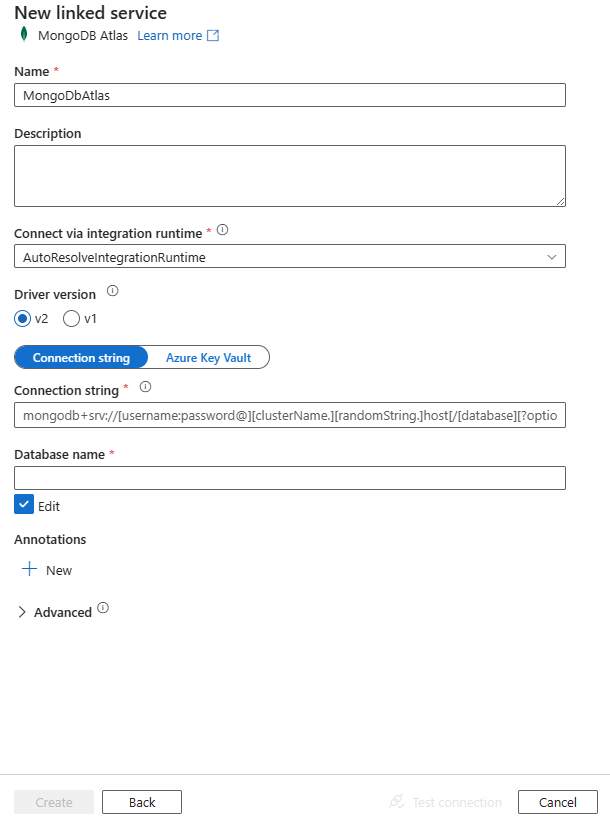
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà che vengono usate per definire entità di Data Factory specifiche per il connettore MongoDB Atlas.
Proprietà del servizio collegato
Per il servizio collegato di MongoDB Atlas sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su MongoDbAtlas | Sì |
| connectionString | Specificare la stringa di connessione di MongoDB Atlas, ad esempio mongodb+srv://<username>:<password>@<clustername>.<randomString>.<hostName>/<dbname>?<otherProperties>. È anche possibile inserire una stringa di connessione in Azure Key Vault. Per altri dettagli, vedere Archiviare le credenziali in Azure Key Vault. |
Sì |
| database | Nome del database a cui si vuole accedere. | Sì |
| driverVersion | Impostare la versione del driver su v2, che supporta MongoDB versione 3.6 e successive. Per altre informazioni, consultare questo articolo. | No |
| connectVia | Il runtime di integrazione da usare per la connessione all'archivio dati. Per altre informazioni, vedere la sezione Prerequisiti. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio:
{
"name": "MongoDbAtlasLinkedService",
"properties": {
"type": "MongoDbAtlas",
"typeProperties": {
"connectionString": "mongodb+srv://<username>:<password>@<clustername>.<randomString>.<hostName>/<dbname>?<otherProperties>",
"database": "myDatabase",
"driverVersion": "<driver version>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere Set di dati e servizi collegati. Per il set di dati MongoDB Atlas sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su: MongoDbAtlasCollection | Sì |
| collectionName | Nome della raccolta nel database MongoDB Atlas. | Sì |
Esempio:
{
"name": "MongoDbAtlasDataset",
"properties": {
"type": "MongoDbAtlasCollection",
"typeProperties": {
"collectionName": "<Collection name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<MongoDB Atlas linked service name>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine e dal sink MongoDB Atlas.
MongoDB Atlas come origine
Nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su: MongoDbAtlasSource | Sì |
| filter | Specifica il filtro di selezione usando gli operatori di query. Per restituire tutti i documenti in una raccolta, omettere questo parametro o passare un documento vuoto ({}). | No |
| cursorMethods.project | Specifica i campi da restituire nei documenti per la proiezione. Per restituire tutti i campi nei documenti corrispondenti, omettere questo parametro. | No |
| cursorMethods.sort | Specifica l'ordine in cui la query restituisce i documenti corrispondenti. Fare riferimento a cursor.sort(). | No |
| cursorMethods.limit | Specifica il numero massimo di documenti restituiti dal server. Fare riferimento a cursor.limit(). | No |
| cursorMethods.skip | Specifica il numero di documenti da ignorare e la posizione da cui MongoDB Atlas inizia a restituire i risultati. Fare riferimento a cursor.skip(). | No |
| batchSize | Specifica il numero di documenti da restituire in ogni batch di risposta dall'istanza di MongoDB Atlas. Nella maggior parte dei casi, la modifica della dimensione del batch non influisce sull'utente o sull'applicazione. Il limite massimo di Azure Cosmos DB per ogni batch è di 40 MB, che corrisponde alla somma delle dimensioni del numero di documenti definiti in batchSize. Diminuire questo valore se si hanno documenti di grandi dimensioni. | No (il valore predefinito è 100) |
Suggerimento
Il servizio supporta l'utilizzo del documento BSON in modalità strict. Assicurarsi che la query di filtro sia in modalità strict anziché in modalità shell. Per altre informazioni consultare il manuale di MongoDB.
Esempio:
"activities":[
{
"name": "CopyFromMongoDbAtlas",
"type": "Copy",
"inputs": [
{
"referenceName": "<MongoDB Atlas input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "MongoDbAtlasSource",
"filter": "{datetimeData: {$gte: ISODate(\"2018-12-11T00:00:00.000Z\"),$lt: ISODate(\"2018-12-12T00:00:00.000Z\")}, _id: ObjectId(\"5acd7c3d0000000000000000\") }",
"cursorMethods": {
"project": "{ _id : 1, name : 1, age: 1, datetimeData: 1 }",
"sort": "{ age : 1 }",
"skip": 3,
"limit": 3
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
MongoDB Atlas come sink
Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del sink dell'attività di copia deve essere impostata su MongoDbAtlasSink. | Sì |
| writeBehavior | Descrive come scrivere dati in MongoDB Atlas. Valori consentiti: insert e upsert. Il comportamento di upsert consiste nella sostituzione del documento se esiste già un documento con lo stesso _id. In caso contrario, il documento viene inserito.Nota: il servizio genera automaticamente un _id per un documento se non è specificato un _id nel documento originale o tramite il mapping di colonna. È quindi necessario assicurarsi che il documento contenga un ID in modo che upsert funzioni come previsto. |
No (il valore predefinito è insert) |
| writeBatchSize | La proprietà writeBatchSize controlla le dimensioni dei documenti da scrivere in ogni batch. È possibile provare ad aumentare il valore di writeBatchSize per migliorare le prestazioni e a ridurre il valore se le dimensioni dei documenti sono troppo grandi. | No (il valore predefinito è 10.000) |
| writeBatchTimeout | Tempo di attesa per il completamento dell'operazione di inserimento batch prima del timeout. Il valore consentito è timespan. | No (il valore predefinito è 00:30:00 - 30 minuti) |
Suggerimento
Per importare documenti JSON come sono, fare riferimento alla sezione Importare o esportare documenti JSON. Per copiare da dati in forma tabulare, fare riferimento a Mapping dello schema.
Esempio
"activities":[
{
"name": "CopyToMongoDBAtlas",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "MongoDbAtlasSink",
"writeBehavior": "upsert"
}
}
}
]
Importare ed esportare documenti JSON
È possibile usare questo connettore MongoDB Atlas per:
- Copiare i documenti tra due raccolte di MongoDB Atlas così come sono.
- Importare in MongoDB Atlas documenti JSON da varie origini, tra cui Azure Cosmos DB, Archiviazione BLOB di Azure, Azure Data Lake Store e altri archivi basati su file supportati.
- Esportare documenti JSON da una raccolta di MongoDB Atlas in diversi archivi basati su file.
Per ottenere una copia priva di schema, ignorare la sezione "structure" (chiamata anche schema) nel set di dati e il mapping dello schema nell'attività di copia.
Mapping dello schema
Per copiare dati dal MongoDB Atlas nel sink tabulare o viceversa, fare riferimento a Mapping dello schema.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività Copy, vedere Archivi dati supportati.