Copiare e trasformare i dati da e verso un endpoint REST usando Azure Data Factory
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo descrive come usare l'attività Copy in Azure Data Factory per copiare dati da e verso un endpoint REST. L'articolo è basato su Attività di copia in Azure Data Factory, dove viene presentata una panoramica generale dell'attività di copia.
La differenza tra questo connettore REST, il connettore HTTP e il connettore Tabella Web è la seguente:
- Il connettore REST supporta in modo specifico la copia dei dati dalle API RESTful.
- Il connettore HTTP è un connettore generico per recuperare i dati da qualsiasi endpoint HTTP, ad esempio, per scaricare file. Prima che il connettore REST diventi disponibile, può capitare di usare il connettore HTTP per copiare dati dalle API RESTful, operazione supportata ma meno funzionale rispetto all'uso del connettore REST.
- Il connettore Tabella Web estrae il contenuto della tabella da una pagina Web HTML.
Funzionalità supportate
Questo connettore HTTP è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (origine/sink) | (1) (2) |
| Flusso di dati per mapping (origine/sink) | (1) |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco di archivi dati supportati come origini/sink, vedere Archivi dati supportati.
In particolare, questo connettore REST generico supporta:
- Copia di dati da un endpoint REST usando i metodi di GET o POST e copia di dati in un endpoint REST usando i metodi POST, PUT o PATCH.
- Copia dei dati usando una delle autenticazioni seguenti: Anonimo, Basic, Entità servizio, Credenziale client OAuth2, Identità gestita assegnata dal sistema e Identità gestita assegnata dall'utente.
- La paginazione nelle API REST.
- Per REST come origine, copiare la risposta JSON REST così com'è o analizzarla usando mapping schema. È supportato solo il payload della risposta in JSON.
Suggerimento
Per testare una richiesta di recupero dei dati prima di configurare il connettore REST in Data Factory, fare riferimento alla specifica dell'API per i requisiti relativi a intestazione e corpo. È possibile usare strumenti come Visual Studio, Invoke-RestMethod di PowerShell o un Web browser per la convalida.
Prerequisiti
Se l'archivio dati si trova all'interno di una rete locale, una rete virtuale di Azure o un cloud privato virtuale di Amazon, è necessario configurare un runtime di integrazione self-hosted per connettersi.
Se l'archivio dati è un servizio dati del cloud gestito, è possibile usare Azure Integration Runtime. Se l'accesso è limitato solo agli indirizzi IP approvati nelle regole del firewall, è possibile aggiungere IP di Azure Integration Runtime nell'elenco Consentiti.
È anche possibile usare la funzionalitàruntime di integrazione della rete virtuale gestita in Azure Data Factory per accedere alla rete locale senza installare e configurare un runtime di integrazione self-hosted.
Per altre informazioni sui meccanismi di sicurezza di rete e sulle opzioni supportate da Data Factory, vedere strategie di accesso ai dati.
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato REST usando l’interfaccia utente
Usare la procedura seguente per creare un servizio collegato REST nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi selezionare Nuovo:
Cercare REST e selezionare il connettore REST.
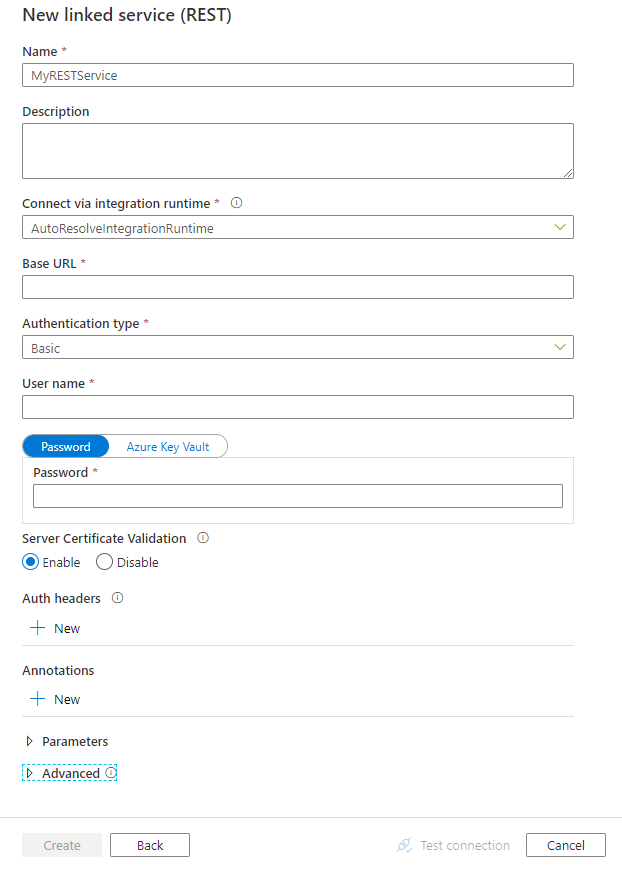
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti offrono informazioni dettagliate sulle proprietà che è possibile usare per definire entità di Data Factory specifiche del connettore REST.
Proprietà del servizio collegato
Per il servizio collegato REST sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà tipo deve essere impostata su RestService. | Sì |
| URL. | URL di base del servizio REST. | Sì |
| enableServerCertificateValidation | Specifica se convalidare il certificato TLS/SSL lato server durante la connessione all'endpoint. | No (il valore predefinito è true) |
| authenticationType | Tipo di autenticazione usato per connettersi al servizio REST. I valori consentiti sono Anonimo, Basic, AadServicePrincipal, OAuth2ClientCredential e ManagedServiceIdentity. È anche possibile configurare le intestazioni di autenticazione nella proprietà authHeaders. Per altre proprietà ed esempi su ogni valore, vedere le sezioni corrispondenti di seguito. |
Sì |
| authHeaders | Intestazioni della richiesta HTTP aggiuntive per l'autenticazione. Ad esempio, per usare l'autenticazione con chiave API, è possibile selezionare il tipo di autenticazione "Anonimo" e specificare la chiave API nell'intestazione. |
No |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. Per altre informazioni, vedere la sezione Prerequisiti. Se non è specificata, questa proprietà usa il tipo Azure Integration Runtime predefinito. | No |
Per tipi di autenticazione differenti, vedere le sezioni corrispondenti per informazioni dettagliate.
- Autenticazione di base
- Autenticazione tramite entità servizio
- Autenticazione tramite credenziale client OAuth2
- Autenticazione dell'identità gestita assegnata dal sistema
- Autenticazione dell'identità gestita assegnata dall'utente
- Autenticazione anonima
Usare l'autenticazione di base
Impostare la proprietà authenticationType su Basic. Oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| userName | Nome utente da usare per accedere all'endpoint REST. | Sì |
| password | Password per l'utente (valore di userName). Contrassegnare questo campo come di tipo SecureString per l'archiviazione sicura in Data Factory. È anche possibile fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
Esempio
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Usare l'autenticazione tramite entità servizio
Impostare la proprietà authenticationType su AadServicePrincipal. Oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| servicePrincipalId | Specificare l'ID client dell'applicazione Microsoft Entra. | Sì |
| servicePrincipalCredentialType | Specificare il tipo di credenziale da usare per l'autenticazione dell'entità servizio. I valori consentiti sono ServicePrincipalKey e ServicePrincipalCert. |
No |
| Per ServicePrincipalKey | ||
| servicePrincipalKey | Specificare la chiave dell'applicazione Microsoft Entra. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro in Data Factory oppure fare riferimento a un segreto archiviato in Azure Key Vault. | No |
| Per ServicePrincipalCert | ||
| servicePrincipalEmbeddedCert | Specificare il certificato con codifica Base64 dell'applicazione registrata in Microsoft Entra ID e assicurarsi che il tipo di contenuto del certificato sia PKCS #12. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a un segreto archiviato in Azure Key Vault. Passare a questa sezione per informazioni su come salvare il certificato in Azure Key Vault. | No |
| servicePrincipalEmbeddedCertPassword | Specificare la password del certificato se il certificato è protetto con una password. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a un segreto archiviato in Azure Key Vault. | No |
| tenant | Specificare le informazioni sul tenant (nome di dominio o ID tenant) in cui si trova l'applicazione. Recuperarle passando il cursore del mouse sull'angolo superiore destro del portale di Azure. | Sì |
| aadResourceId | Specificare la risorsa di Microsoft Entra richiesta per cui si richiede l'autorizzazione, ad esempio https://management.core.windows.net. |
Sì |
| azureCloudType | Per l'autenticazione tramite entità servizio, specificare il tipo di ambiente cloud di Azure in cui è registrata l'applicazione Microsoft Entra. I valori consentiti sono AzurePublic, AzureChina, AzureUsGovernment e AzureGermany. Per impostazione predefinita, viene usato l'ambiente cloud di Data Factory. |
No |
Esempio 1: Uso dell'autenticazione con chiave dell'entità servizio
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio 2: usare l'autenticazione con certificato dell'entità servizio
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Salvare il certificato dell'entità servizio in Azure Key Vault
Sono disponibili due opzioni per salvare il certificato dell'entità servizio in Azure Key Vault:
Opzione 1
Convertire il certificato dell'entità servizio in una stringa base64. Altre informazioni sono disponibili in questo articolo.
Salvare la stringa base64 come segreto in Azure Key Vault.
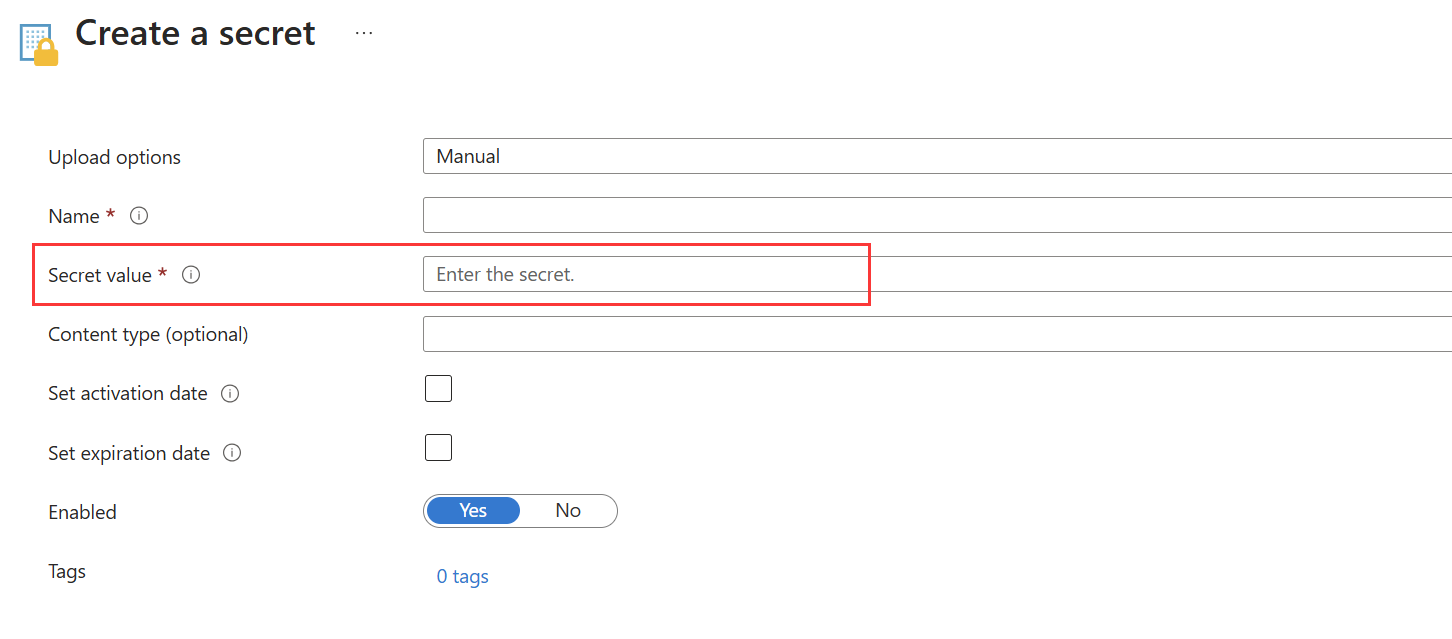
Opzione 2
Se non è possibile scaricare il certificato da Azure Key Vault, è possibile usare questo modello per salvare il certificato dell'entità servizio convertito come segreto in Azure Key Vault.

Usare l’autenticazione tramite credenziale client OAuth2
Impostare la proprietà authenticationType su OAuth2ClientCredential. Oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| tokenEndpoint | L’endpoint del token del server di autorizzazione per acquisire il token di accesso. | Sì |
| clientId | L’ID client associato all'applicazione. | Sì |
| clientSecret | Il segreto client associato all'applicazione. Contrassegnare questo campo come di tipo SecureString per l'archiviazione sicura in Data Factory. È anche possibile fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
| ambito | L’ambito dell'accesso richiesto. Descrive il tipo di accesso che verrà richiesto. | No |
| resource | Il servizio o la risorsa di destinazione a cui verrà richiesto l'accesso. | No |
Esempio
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
Autenticazione tramite identità gestita assegnata dal sistema
Impostare la proprietà authenticationType su ManagedServiceIdentity. Oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| aadResourceId | Specificare la risorsa di Microsoft Entra richiesta per cui si richiede l'autorizzazione, ad esempio https://management.core.windows.net. |
Sì |
Esempio
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione tramite identità gestita assegnata dall'utente
Impostare la proprietà authenticationType su ManagedServiceIdentity. Oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| aadResourceId | Specificare la risorsa di Microsoft Entra richiesta per cui si richiede l'autorizzazione, ad esempio https://management.core.windows.net. |
Sì |
| credentials | Specificare l'identità gestita assegnata dall'utente come oggetto credenziale. | Sì |
Esempio
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uso delle intestazioni di autenticazione
Inoltre, è possibile configurare le intestazioni delle richieste per l'autenticazione insieme ai tipi di autenticazione predefiniti.
Esempio: uso dell'autenticazione tramite chiave API
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Questa sezione contiene un elenco delle proprietà supportate dal set di dati REST.
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere Set di dati e servizi collegati.
Per copiare dati da REST, sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su RestResource. | Sì |
| relativeUrl | URL relativo della risorsa che contiene i dati. Quando questa proprietà non è specificata, viene usato solo l'URL indicato nella definizione del servizio collegato. Il connettore HTTP copia dati dall'URL combinato: [URL specified in linked service]/[relative URL specified in dataset]. |
No |
Se è stato impostato requestMethod, additionalHeaders, requestBody e paginationRules nel set di dati, è ancora supportato così com’è, mentre viene suggerito di usare il nuovo modello nell’attività in futuro.
Esempio:
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Questa sezione fornisce un elenco delle proprietà supportate dall'origine e dal sink REST.
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere Pipeline.
REST come origine
Nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su RestSource. | Sì |
| requestMethod | Metodo HTTP. I valori consentiti sono GET (predefinito) e POST. | No |
| additionalHeaders | Intestazioni richiesta HTTP aggiuntive. | No |
| requestBody | Corpo della richiesta HTTP. | No |
| paginationRules | Regole di paginazione per comporre le richieste di pagina successive. Per informazioni dettagliate, vedere la sezione Supporto della paginazione. | No |
| httpRequestTimeout | Timeout (valore di TimeSpan) durante il quale la richiesta HTTP attende una risposta. Si tratta del timeout per ottenere una risposta, non per leggere i dati della risposta. Il valore predefinito è 00:01:40. | No |
| requestInterval | Periodo di attesa prima di inviare la richiesta per la pagina successiva. Il valore predefinito è 00:00:01 | No |
Nota
Il connettore REST ignora qualunque intestazione "Accetta" specificata in additionalHeaders. Poiché il connettore REST supporta solo la risposta in JSON, genererà automaticamente un'intestazione di Accept: application/json.
La matrice dell’oggetto come corpo della risposta non è supportata nella paginazione.
Esempio 1: uso del metodo Get con paginazione
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Esempio 2: Uso del metodo POST
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST come sink
Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà tipo del sink dell’attività di copia deve essere impostata su RestSink. | Sì |
| requestMethod | Metodo HTTP. I valori consentiti sono POST (impostazione predefinita), PUT e PATCH. | No |
| additionalHeaders | Intestazioni richiesta HTTP aggiuntive. | No |
| httpRequestTimeout | Timeout (valore di TimeSpan) durante il quale la richiesta HTTP attende una risposta. Questo valore è il timeout per ottenere una risposta, non per scrivere i dati. Il valore predefinito è 00:01:40. | No |
| requestInterval | L’intervallo di tempo tra richieste diverse, in millisecondi. Il valore dell’intervallo tra le richieste deve essere un numero compreso tra [10, 60000]. | No |
| httpCompressionType | Tipo di compressione HTTP da usare durante l'invio di dati con livello di compressione ottimale. I valori consentiti sono nessuno e gzip. | No |
| writeBatchSize | Numero di record per scrivere nel sink REST per batch. Il valore predefinito è 10000. | No |
Il connettore REST come sink funziona con le API REST che accettano JSON. I dati verranno inviati in JSON con il modello seguente. In base alla necessità, è possibile usare l'attività Copy mapping schema per modellare i dati di origine in modo che siano conformi al payload previsto dall'API REST.
[
{ <data object> },
{ <data object> },
...
]
Esempio:
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
Proprietà del flusso di dati per mapping
REST è supportato nei flussi di dati sia per i set di dati di integrazione che per i set di dati inline.
Trasformazione origine
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| requestMethod | Metodo HTTP. I valori consentiti sono GET e POST. | Sì |
| relativeUrl | URL relativo della risorsa che contiene i dati. Quando questa proprietà non è specificata, viene usato solo l'URL indicato nella definizione del servizio collegato. Il connettore HTTP copia dati dall'URL combinato: [URL specified in linked service]/[relative URL specified in dataset]. |
No |
| additionalHeaders | Intestazioni richiesta HTTP aggiuntive. | No |
| httpRequestTimeout | Timeout (valore di TimeSpan) durante il quale la richiesta HTTP attende una risposta. Questo valore è il timeout per ottenere una risposta, non per scrivere i dati. Il valore predefinito è 00:01:40. | No |
| requestInterval | L’intervallo di tempo tra richieste diverse, in millisecondi. Il valore dell’intervallo tra le richieste deve essere un numero compreso tra [10, 60000]. | No |
| QueryParameters.parametro_query_richiesta o QueryParameters['parametro_query_richiesta'] | "request_query_parameter" è definito dall’utente e fa riferimento a un nome di un parametro di query nell'URL della richiesta HTTP successiva. | No |
Trasformazione sink
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| additionalHeaders | Intestazioni richiesta HTTP aggiuntive. | No |
| httpRequestTimeout | Timeout (valore di TimeSpan) durante il quale la richiesta HTTP attende una risposta. Questo valore è il timeout per ottenere una risposta, non per scrivere i dati. Il valore predefinito è 00:01:40. | No |
| requestInterval | L’intervallo di tempo tra richieste diverse, in millisecondi. Il valore dell’intervallo tra le richieste deve essere un numero compreso tra [10, 60000]. | No |
| httpCompressionType | Tipo di compressione HTTP da usare durante l'invio di dati con livello di compressione ottimale. I valori consentiti sono nessuno e gzip. | No |
| writeBatchSize | Numero di record per scrivere nel sink REST per batch. Il valore predefinito è 10000. | No |
È possibile impostare i metodi delete, insert, update e upsert, nonché i dati di riga relativi da inviare al sink REST per operazioni CRUD.
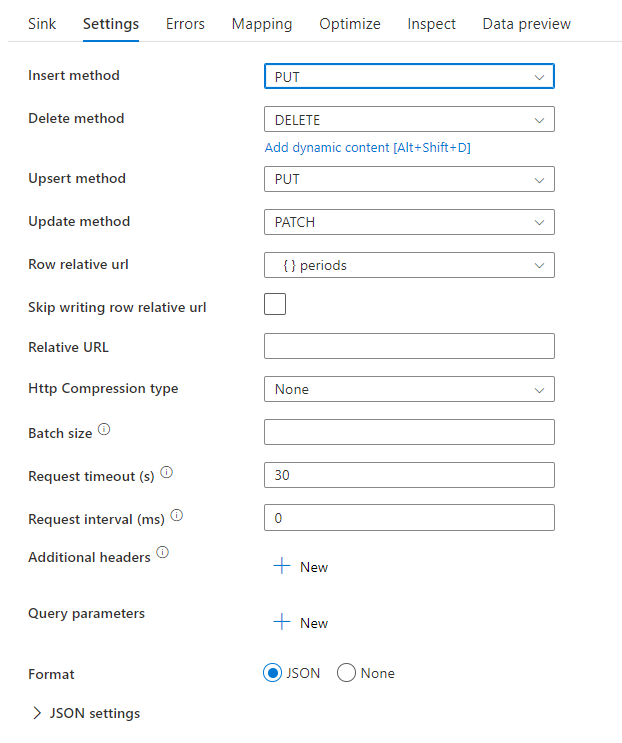
Script del flusso di dati di esempio
Si noti l'uso di una trasformazione alter row prima del sink per indicare ad ADF quale tipo di azione eseguire con il sink REST. Vale a dire: insert, update, upsert, delete.
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Supporto per l'impaginazione
Quando si copiano dati dalle API REST, normalmente l'API REST limita le dimensioni del payload della risposta di una singola richiesta in base a un numero ragionevole, mentre per restituire grandi quantità di dati suddivide il risultato in più pagine e richiede ai chiamanti di inviare richieste consecutive per ottenere la pagina successiva del risultato. In genere la richiesta di una sola pagina è dinamica ed è composta dalle informazioni restituite dalla risposta della pagina precedente.
Questo connettore REST generico supporta i modelli di paginazione seguenti:
- URL assoluto o relativo della richiesta successiva = valore della proprietà nel corpo della risposta corrente
- URL assoluto o relativo della richiesta successiva = valore dell'intestazione nelle intestazioni della risposta corrente
- Parametro di query della richiesta successiva = valore della proprietà nel corpo della risposta corrente
- Parametro di query della richiesta successiva = valore dell'intestazione nelle intestazioni della risposta corrente
- Intestazione della richiesta successiva = valore della proprietà nel corpo della risposta corrente
- Intestazione della richiesta successiva = valore dell'intestazione nelle intestazioni della risposta corrente
Le regole di paginazione sono definite come un dizionario nel set di dati, contenente una o più coppie chiave-valore con distinzione tra maiuscole e minuscole. La configurazione verrà usata per generare la richiesta a partire dalla seconda pagina. Il connettore interromperà l'iterazione quando otterrà il codice di stato HTTP 204 (Nessun contenuto) o quando una delle espressioni JSONPath in "paginationRules" restituisce null.
Chiavi supportate nelle regole di paginazione:
| Chiave | Descrizione |
|---|---|
| AbsoluteUrl | Indica l'URL per l'invio della richiesta successiva. Può essere l’URL assoluto o l’URL relativo. |
| QueryParameters.parametro_query_richiesta o QueryParameters['parametro_query_richiesta'] | "request_query_parameter" è definito dall’utente e fa riferimento a un nome di un parametro di query nell'URL della richiesta HTTP successiva. |
| Headers.intestazione_richiesta o Headers['intestazione_richiesta'] | "request_header" è definito dall'utente e fa riferimento a un nome di intestazione nella richiesta HTTP successiva. |
| EndCondition:end_condition | "end_condition" è definito dall'utente e indica la condizione che terminerà il ciclo di paginazione nella richiesta HTTP successiva. |
| MaxRequestNumber | Indica il numero massimo di richieste di paginazione. Se si lascia vuoto, non sarà previsto alcun limite. |
| SupportRFC5988 | Per impostazione predefinita, è impostato su true se non è definita alcuna regola di paginazione. È possibile disabilitare questa regola impostando supportRFC5988 su false o rimuovendo questa proprietà dallo script. |
Valori supportati nelle regole di paginazione:
| Valore | Descrizione |
|---|---|
| Headers.intestazione_risposta o Headers['intestazione_risposta'] | "response_header" è definito dall'utente e fa riferimento a un nome di intestazione nella risposta HTTP corrente, il cui valore verrà usato per emettere la richiesta successiva. |
| Espressione JSONPath che inizia con "$" (che rappresenta la radice del corpo della risposta) | Il corpo della risposta deve contenere un solo oggetto JSON e la matrice dell’oggetto, perché il corpo della risposta non è supportato. L'espressione JSONPath deve restituire un singolo valore primitivo, che verrà usato per inviare la richiesta successiva. |
Nota
Le regole di paginazione nei flussi di dati di mapping sono diverse nell'attività Copy negli aspetti seguenti:
- L'intervallo non è supportato in flussi di dati di mapping.
['']non è supportato in flussi di dati di mapping. Usare, invece,{}per eseguire l'escape di un carattere speciale. Ad esempio,body.{@odata.nextLink}, il cui nodo JSON@odata.nextLinkcontiene il carattere speciale..- La condizione finale è supportata in flussi di dati di mapping, ma la sintassi della condizione è diversa da quella nell'attività Copy.
bodyviene usato per indicare il corpo della risposta anziché$.headerviene usato per indicare l’intestazione della risposta anzichéheaders. Di seguito sono riportati due esempi che illustrano questa differenza:- Esempio 1:
Attività Copy: "EndCondition:$.data": "Empty"
Flussi di dati di mapping: "EndCondition:body.data": "Empty" - Esempio 2:
Attività Copy: "EndCondition:headers.complete": "Exist"
Flussi di dati di mapping: "EndCondition:header.complete": "Exist"
- Esempio 1:
Esempi di regole di paginazione
Questa sezione fornisce un elenco di esempi per le impostazioni delle regole di paginazione.
Esempio 1: variabili in QueryParameters
Questo esempio fornisce i passaggi di configurazione per inviare richieste multiple le cui variabili si trovano in QueryParameters.
Richieste multiple:
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
Passaggio 1: inserire sysparm_offset={offset} in URL base o URL relativo, come illustrato negli screenshot seguenti:
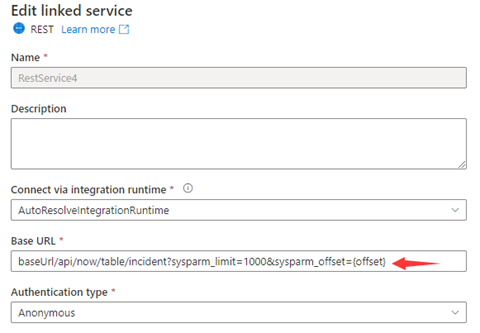
or
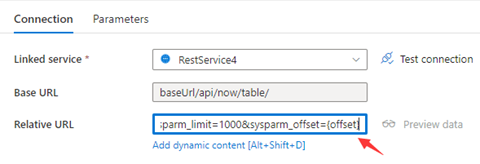
Passaggio 2: impostare Regole di paginazione come opzione 1 oppure opzione 2:
Opzione 1: "QueryParameters.{offset}" : "RANGE:0:10000:1000"
Opzione 2: "AbsoluteUrl.{offset}" : "RANGE:0:10000:1000"
Esempio 2: variabili in AbsoluteUrl
Questo esempio fornisce i passaggi di configurazione per inviare richieste multiple le cui variabili si trovano in AbsoluteUrl.
Richieste multiple:
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
BaseUrl/api/now/table/t100
Passaggio 1: inserire {id} in URL base nella pagina di configurazione del servizio collegato o URL relativo nel riquadro di connessione del set di dati.
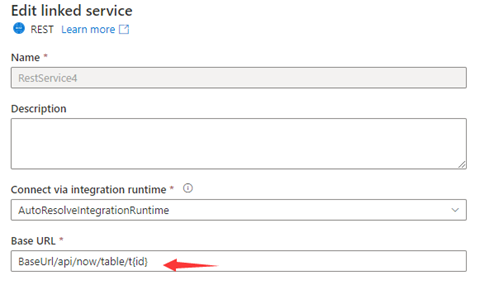
or
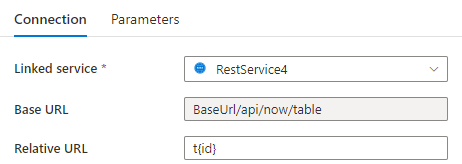
Passaggio 2: impostare Regole di paginazione come "AbsoluteUrl.{id}" :"RANGE:1:100:1".
Esempio 3: variabili in intestazioni
Questo esempio fornisce i passaggi di configurazione per inviare richieste multiple le cui variabili si trovano in intestazioni.
Richieste multiple:
RequestUrl: https://example/table
Richiesta 1: Header(id->0)
Richiesta 2: Header(id->10)
......
Richiesta 100: Header(id->100)
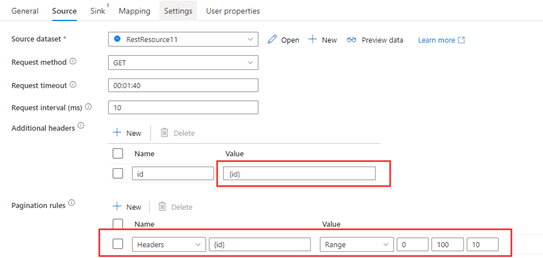
Passaggio 1: inserire {id} in Intestazioni aggiuntive.
Passaggio 2: impostare Regole di paginazione come "Headers.{id}" : "RANGE:0:100:10".
Esempio 4: le variabili si trovano in AbsoluteUrl/QueryParameters/Headers, la variabile finale non è predefinita e la condizione finale si basa sulla risposta
Questo esempio fornisce i passaggi di configurazione per inviare più richieste le cui variabili si trovano in AbsoluteUrl/QueryParameters/Headers, ma la variabile finale non è definita. Per risposte diverse, le impostazioni delle regole della condizione finale sono mostrate nell’esempio 4.1-4.6.
Richieste multiple:
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
Due risposte rilevate in questo esempio:
Risposta 1:
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
Risposta 2:
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
Passaggio 1: impostare l’intervallo di Regole di paginazione come Esempio 1 e lasciare vuota la fine dell’intervallo come "AbsoluteUrl.{offset}": "RANGE:0::1000".
Passaggio 2: impostare regole della condizione finale diverse in base alle ultime risposte diverse. Vedere gli esempi seguenti:
Esempio 4.1: la paginazione termina quando il valore del nodo specifico nella risposta è vuoto
L'API REST restituisce l'ultima risposta nella struttura seguente:
{ Data: [] }Impostare la regola della condizione finale come "EndCondition:$.data": "Empty" per terminare la paginazione quando il valore del nodo specifico nella risposta è vuoto.

Esempio 4.2: la paginazione termina quando il valore del nodo specifico nella risposta non esiste
L'API REST restituisce l'ultima risposta nella struttura seguente:
{}Impostare la regola della condizione finale come "EndCondition:$.data": "NonExist" per terminare la paginazione quando il valore del nodo specifico nella risposta non esiste.

Esempio 4.3: la paginazione termina quando il valore del nodo specifico nella risposta esiste
L'API REST restituisce l'ultima risposta nella struttura seguente:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Impostare la regola della condizione finale come "EndCondition:$.data": "Exist" per terminare la paginazione quando il valore del nodo specifico nella risposta esiste.

Esempio 4.4: la paginazione termina quando il valore del nodo specifico nella risposta è un valore const definito dall’utente
L'API REST restituisce la risposta nella struttura seguente:
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
E l’ultima risposta è nella struttura seguente:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Impostare la regola della condizione finale come "EndCondition:$.Complete": "Const:true" per terminare la paginazione quando il valore del nodo specifico nella risposta è un valore const definito dall’utente.

Esempio 4.5: la paginazione termina quando il valore della chiave dell’intestazione nella risposta è uguale a un valore const definito dall’utente
Le chiavi di intestazione nelle risposte dell'API REST sono illustrate nella struttura seguente:
Intestazione risposta 1:
header(Complete->0)
......
Intestazione ultima risposta:header(Complete->1)Impostare la regola della condizione finale come "EndCondition:$.Complete": "Const:1" per terminare la paginazione quando il valore della chiave dell’intestazione nella risposta è uguale a un valore const definito dall’utente.

esempio 4.6: la paginazione termina quando la chiave esiste nell'intestazione della risposta
Le chiavi di intestazione nelle risposte dell'API REST sono illustrate nella struttura seguente:
Intestazione risposta 1:
header()
......
Intestazione ultima risposta:header(CompleteTime->20220920)Impostare la regola della condizione finale come "EndCondition:headers.CompleteTime": "Exist" per terminare la paginazione quando la chiave esiste nell’intestazione della risposta.

Esempio 5: impostare la condizione di fine per evitare richieste infinite quando la regola dell’intervallo non è definita
Questo esempio fornisce i passaggi di configurazione per inviare richieste multiple quando la regola dell’intervallo non è usata. La condizione finale può essere impostata in modo da fare riferimento all'esempio 4.1-4.6 per evitare richieste infinite. L’API REST restituisce la risposta nella seguente struttura, caso in cui l’URL della pagina successiva è rappresentato in paging.next.
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
L’ultima risposta è:
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
Passaggio 1: impostare Regole di paginazione come "AbsoluteUrl": "$.paging.next".
Passaggio 2: se next nell'ultima risposta è sempre uguale all'URL dell'ultima richiesta e non è vuoto, verranno inviate richieste infinite. La condizione finale può essere usata per evitare richieste infinite. Impostare, quindi, la regola della condizione finale in modo da fare riferimento all'esempio 4.1-4.6.
Esempio 6: impostare il numero massimo di richieste per evitare richieste infinite
Impostare MaxRequestNumber per evitare richieste infinite, come illustrato nello screenshot seguente:

Esempio 7: la regola di paginazione RFC 5988 è supportata per impostazione predefinita
Il back-end otterrà automaticamente l'URL successivo in base ai collegamenti di stile RFC 5988 nell'intestazione.

Suggerimento
Se non si desidera abilitare questa regola di paginazione predefinita, è possibile impostare supportRFC5988 su false o semplicemente eliminarla nello script.
Esempio 8a: l'URL della richiesta successivo si trova nel corpo della risposta quando si usa la paginazione nei flussi di dati di mapping
Questo esempio indica come impostare la regola di paginazione e la regola della condizione finale nei flussi di dati di mapping quando l'URL della richiesta successiva proviene dal corpo della risposta.
Lo schema della risposta è mostrato di seguito:
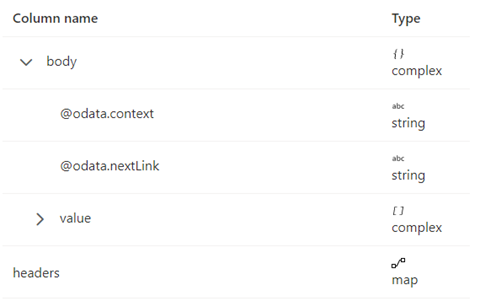
Le regole di paginazione devono essere impostate come indicato nello screenshot seguente:

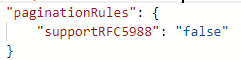
Per impostazione predefinita, la paginazione si interrompe quando il corpo {@odata.nextLink}** è null o vuoto.
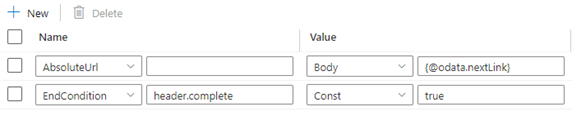
Tuttavia, se il valore di @odata.nextLink nel corpo dell’ultima risposta è uguale all'URL dell’ultima richiesta, si verificherà un ciclo infinito. Per evitare questa condizione, definire regole della condizione finale.
Se Valore nell'ultima risposta è Vuoto, la regola della condizione finale può essere impostata come indicato di seguito:

Se il valore della chiave completa nell'intestazione della risposta uguale a true indica la fine della paginazione, la regola della condizione finale può essere impostata come indicato di seguito:
Esempio 8b: l'URL della richiesta successiva si trova nel corpo della risposta quando si usa la paginazione nell'attività di copia
In questo esempio viene illustrato come impostare la regola di paginazione in un'attività di copia quando l'URL della richiesta successiva è contenuto all'interno del corpo della risposta.
Lo schema della risposta è mostrato di seguito:
Le regole di paginazione devono essere impostate come illustrato nello screenshot seguente:

Esempio 9: il formato della risposta è XML e l'URL della richiesta successiva proviene dal corpo della risposta quando si usa la paginazione in flussi di dati di mapping
Questo esempio indica come impostare la regola di paginazione in flussi di dati di mapping quando il formato della risposta è XML e l'URL della richiesta successiva proviene dal corpo della risposta. Come illustrato nello screenshot seguente, il primo URL è https://<user>.dfs.core.windows.NET/bugfix/test/movie_1.xml
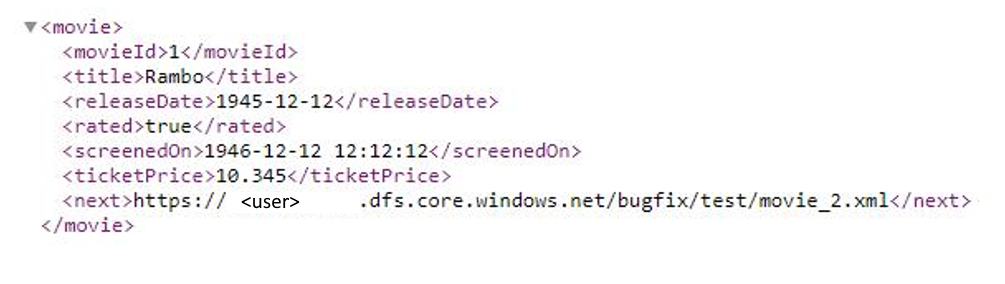
Lo schema della risposta è mostrato di seguito:
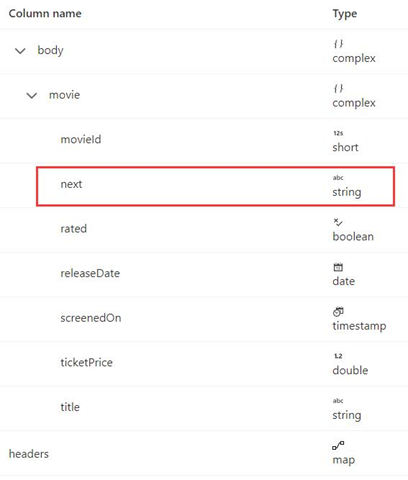
La sintassi della regola di paginazione è identica a quella dell'esempio 8 e deve essere impostata come indicato di seguito in questo esempio:

Esportare la risposta JSON così com'è
È possibile usare questo connettore REST per esportare la risposta JSON dell'API REST in vari archivi basati su file. Per ottenere una copia priva di schema, ignorare la sezione "structure" (chiamata anche schema) nel set di dati e il mapping dello schema nell'attività di copia.
Mapping dello schema
Per copiare dati dall'endpoint REST al sink in formato tabulare, vedere Mapping dello schema.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini o sink dall'attività di copia in Azure Data Factory, vedere Archivi dati e formati supportati.