Copiare dati da Spark usando Azure Data Factory o Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività di copia in una pipeline di Azure Data Factory o Synapse Analytics per copiare dati da Spark. Si basa sull'articolo di panoramica dell'attività di copia che presenta una panoramica generale sull'attività di copia.
Funzionalità supportate
Questo connettore Spark è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività Copy (origine/-) | (1) (2) |
| Attività Lookup | (1) (2) |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini/sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
Il servizio fornisce un driver predefinito per abilitare la connettività, pertanto non è necessario installare manualmente alcun driver usando questo connettore.
Prerequisiti
Se l'archivio dati si trova all'interno di una rete locale, una rete virtuale di Azure o un cloud privato virtuale di Amazon, è necessario configurare un runtime di integrazione self-hosted per connettersi.
Se l'archivio dati è un servizio dati del cloud gestito, è possibile usare Azure Integration Runtime. Se l'accesso è limitato solo agli indirizzi IP approvati nelle regole del firewall, è possibile aggiungere IP di Azure Integration Runtime nell'elenco Consentiti.
È anche possibile usare la funzionalitàruntime di integrazione della rete virtuale gestita in Azure Data Factory per accedere alla rete locale senza installare e configurare un runtime di integrazione self-hosted.
Per altre informazioni sui meccanismi di sicurezza di rete e sulle opzioni supportate da Data Factory, vedere strategie di accesso ai dati.
Introduzione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
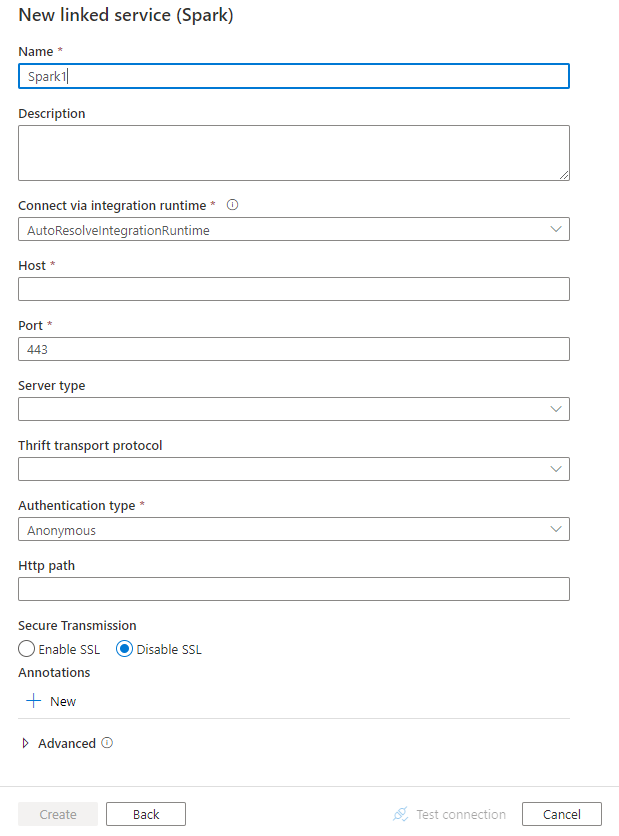
Creare un servizio collegato a Spark usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Spark nell'interfaccia utente di portale di Azure.
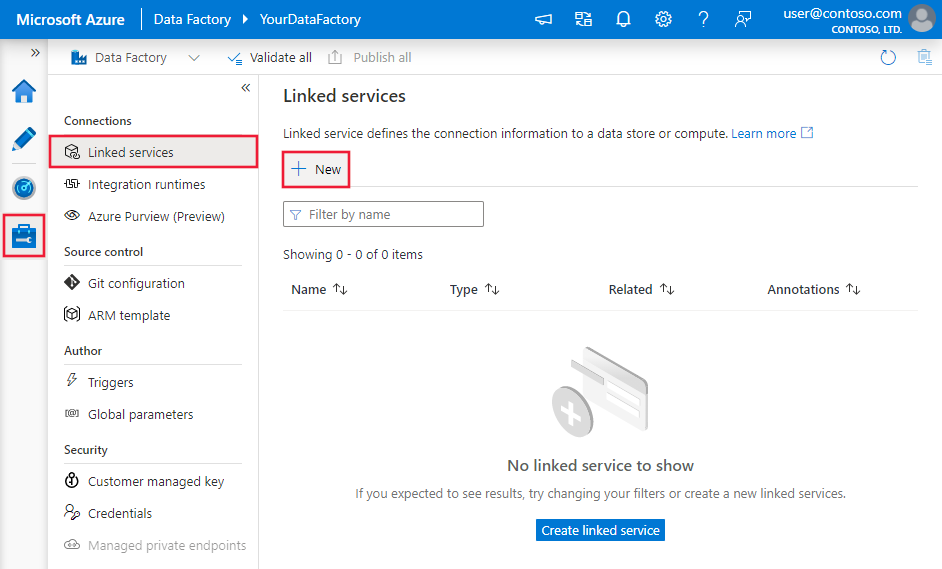
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Spark e selezionare il connettore Spark.

Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà che vengono usate per definire entità di Data Factory specifiche per il connettore Spark.
Proprietà del servizio collegato
Per il servizio collegato di Spark sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su Spark | Sì |
| host | Indirizzo IP o nome host del server Spark. | Sì |
| port | Porta TCP che il server Spark usa per l'ascolto delle connessioni client. Se ci si connette a Azure HDInsights, specificare la porta come 443. | Sì |
| serverType | Tipo del server Spark. I valori consentiti sono SharkServer, SharkServer2, SparkThriftServer |
No |
| thriftTransportProtocol | Protocollo di trasporto da usare nel livello Thrift. I valori consentiti sono Binary, SASL, HTTP |
No |
| authenticationType | Metodo di autenticazione usato per accedere al server Spark. I valori consentiti sono Anonymous, Username, UsernameAndPassword, WindowsAzureHDInsightService |
Sì |
| username | Nome utente usato per accedere al server Spark. | No |
| password | Password corrispondente all'utente. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a un segreto archiviato in Azure Key Vault. | No |
| httpPath | URL parziale corrispondente al server Spark. | No |
| enableSsl | Specifica se le connessioni al server vengono crittografate tramite TLS. Il valore predefinito è false. | No |
| trustedCertPath | Percorso completo del file .pem contenente certificati della CA attendibili per verificare il server durante la connessione tramite TLS. Questa proprietà può essere impostata solo quando si usa TLS in runtime di integrazione self-hosted. Il valore predefinito è il file cacerts.pem installato con il runtime di integrazione. | No |
| useSystemTrustStore | Specifica se usare o meno un certificato della CA dall'archivio di scopi consentiti o da un file .pem specificato. Il valore predefinito è false. | No |
| allowHostNameCNMismatch | Specifica se richiedere un nome di certificato TLS/SSL rilasciato dalla CA in modo che corrisponda al nome host del server durante la connessione tramite TLS. Il valore predefinito è false. | No |
| allowSelfSignedServerCert | Specifica se consentire o meno i certificati autofirmati dal server. Il valore predefinito è false. | No |
| connectVia | Il runtime di integrazione da usare per la connessione all'archivio dati. Per altre informazioni, vedere la sezione Prerequisiti. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione di set di dati, vedere l'articolo sui set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati Spark.
Per copiare dati da Spark, impostare la proprietà type del set di dati su SparkObject. Sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su: SparkObject | Sì |
| schema | Nome dello schema. | No (se nell'origine dell'attività è specificato "query") |
| table | Nome della tabella. | No (se nell'origine dell'attività è specificato "query") |
| tableName | Nome della tabella con schema. Questa proprietà è supportata per garantire la compatibilità con le versioni precedenti. Per i nuovi carichi di lavoro, usare schema e table. |
No (se nell'origine dell'attività è specificato "query") |
Esempio
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine Spark.
Spark come origine
Per copiare dati da Spark, impostare il tipo di origine nell'attività di copia su SparkSource. Nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su SparkSource | Sì |
| query | Usare la query SQL personalizzata per leggere i dati. Ad esempio: "SELECT * FROM MyTable". |
No (se nel set di dati è specificato "tableName") |
Esempio:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività Copy, vedere Archivi dati supportati.